为什么我建议需要定期重建数据量大但是性能关键的表
作者:互联网
个人创作公约:本人声明创作的所有文章皆为自己原创,如果有参考任何文章的地方,会标注出来,如果有疏漏,欢迎大家批判。如果大家发现网上有抄袭本文章的,欢迎举报,并且积极向这个 github 仓库 提交 issue,谢谢支持~
本文是“为什么我建议”系列第三篇,本系列中会针对一些在高并发场景下,我对于组内后台开发的一些开发建议以及开发规范的要求进行说明和分析解读,相信能让各位在面对高并发业务的时候避开一些坑。
往期回顾:
一般现在对于业务要查询的数据量以及要保持的并发量高于一定配置的单实例 MySQL 的极限的情况,都会采取分库分表的方案解决。当然,现在也有很多 new SQL 的分布式数据库的解决方案,如果你用的是 MySQL,那么你可以考虑 TiDB(实现了 MySQL 协议,兼容 MySQL 客户端以及 SQL 语句)。如果你用的是的 PgSQL,那么你可以考虑使用 YugaByteDB(实现了 PgSQL 协议,兼容 PgSQL 客户端以及 SQL 语句),他们目前都有自己的云部署解决方案,你可以试试:
但是对于传统分库分表的项目,底层的数据库还是基于 MySQL 以及 PgSQL 这样的传统关系型数据库。一般在业务刚开始的时候,会考虑按照某个分片键多分一些表,例如订单表,我们估计用户直接要查的订单记录是最近一年内的。如果是一年前的,提供其他入口去查,这时候查的就不是有业务数据库了,而是归档数据库,例如 HBase 这样的。例如我们估计一年内用户订单,最多不会超过 10 亿,更新的并发 TPS (非查询 QPS)不会超过 10 万/s。那么我们可以考虑分成 64 张表(个数最好是 2^n,因为 2^n 取余数 = 对 2^n - 1 取与运算,减少分片键运算量)。然后我们还会定时的归档掉一年前的数据,使用类似于 delete from table 这样的语句进行“彻底删除”(注意这里是引号的删除)。这样保证业务表的数据量级一直维持在
然而,日久天长以后,会发现,某些带分片键(这里就是用户 id)的普通查询,也会有些慢,有些走错本地索引。
查询越来越慢的原因
例如这个 SQL:
select * from t_pay_record
WHERE
((
user_id = 'user_id1'
AND is_del = 0
))
ORDER BY
id DESC
LIMIT 20
这个表的分片键就是 user_id
一方面,正如我在“为什么我建议在复杂但是性能关键的表上所有查询都加上 force index”中说的,数据量可能有些超出我们的预期,导致某些分片表大于一定界限,导致 MySQL 对于索引的随机采样越来越不准,由于统计数据不是实时更新,而是更新的行数超过一定比例才会开始更新。并且统计数据不是全量统计,是抽样统计。所以在表的数据量很大的时候,这个统计数据很难非常准确。依靠表本身自动刷新数据机制,参数比较难以调整(主要是 STATS_SAMPLE_PAGES 这个参数,STATS_PERSISTENT 我们一般不会改,我们不会能接受在内存中保存,这样万一数据库重启,表就要重新分析,这样减慢启动时间,STATS_AUTO_RECALC 我们也不会关闭,这样会导致优化器分析的越来越不准确),很难预测出到底调整到什么数值最合适。并且业务的增长,用户的行为导致的数据的倾斜,也是很难预测的。通过 Alter Table 修改某个表的 STATS_SAMPLE_PAGES 的时候,会导致和 Analyze 这个 Table 一样的效果,会在表上加读锁,会阻塞表上的更新以及事务。所以不能在这种在线业务关键表上面使用。所以最好一开始就能估计出大表的量级,但是这个很难。
所以,我们考虑对于数据量比较大的表,最好能提前通过分库分表控制每个表的数据量,但是业务增长与产品需求都是不断在迭代并且变复杂的。很难保证不会出现大并且索引比较复杂的表。这种情况下需要我们,在适当调高 STATS_SAMPLE_PAGES 的前提下,对于一些用户触发的关键查询 SQL,使用 force index 引导它走正确的索引。
但是,有时候即使索引走对了,查询依然有点慢。具体去看这个 SQL 扫描的数据行数的时候,发现并没有很多。
+----+-------------+--------------+------------+-------+-----------------------------------------------------------------------------------------+-------------+---------+------+-------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------------+------------+-------+-----------------------------------------------------------------------------------------+-------------+---------+------+-------+----------+-------------+
| 1 | SIMPLE | t_pay_record | NULL | index | idx_user_id,idx_user_status_pay,idx_user_id_trade_code_status_amount_create_time_is_del | idx_user_id | 32 | NULL | 16 | 0.01 | Using where |
+----+-------------+--------------+------------+-------+-----------------------------------------------------------------------------------------+-------------+---------+------+-------+----------+-------------+
可能还是会有偶现的这样的慢 SQL,并且随着时间推移越来越多,这个就和 MySQL InnoDB 里面的删除机制有关系了。目前大部分业务表都用的 InnoDB 引擎,并且都用的默认的行格式 Dynamic,在这种行格式下我们在插入一条数据的时候,其结构大概如下所示:

记录头中,有删除标记:

当发生导致记录长度变化的更新时,例如变长字段实际数据变得更长这种,会将原来的记录标记为删除,然后在末尾创建更新后的记录。当删除一条记录的时候,也是只是标记记录头的删除标记。
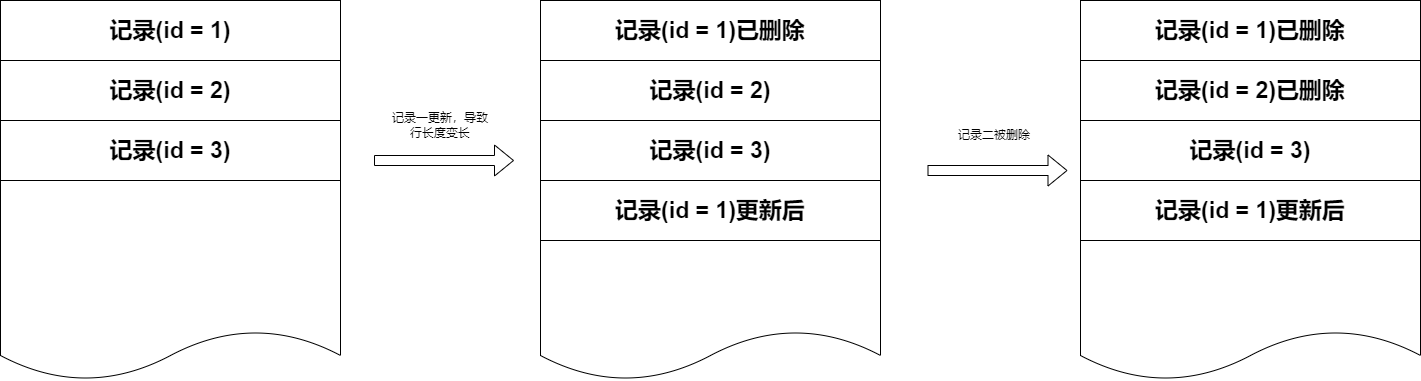
对于这种可能的碎片化,MySQL InnoDB 也是有期望并且措施的,即每个页面 InnoDB 引擎只会存储占用 93% 空间的数据,剩下的就是为了能让长度变化的更新不会导致数据跑到其他页面。但是相对的,如果 Delete 就相当于完全浪费了存储空间了。
一般情况下这种不会造成太大的性能损耗,因为删除一般是删的老的数据,更新一般集中在最近的数据。例如订单发生更新,一般是时间最近的订单才会更新,很少会有很久前的订单基本不会更新,并且归档删除的一般也是很久之前的订单。但是随着业务越来越复杂,归档逻辑也越来越复杂,比如不同类型的订单时效不一样,可能出现一年前还有未结算的预购订单不能归档。久而久之,你的数据可能会变成这样:
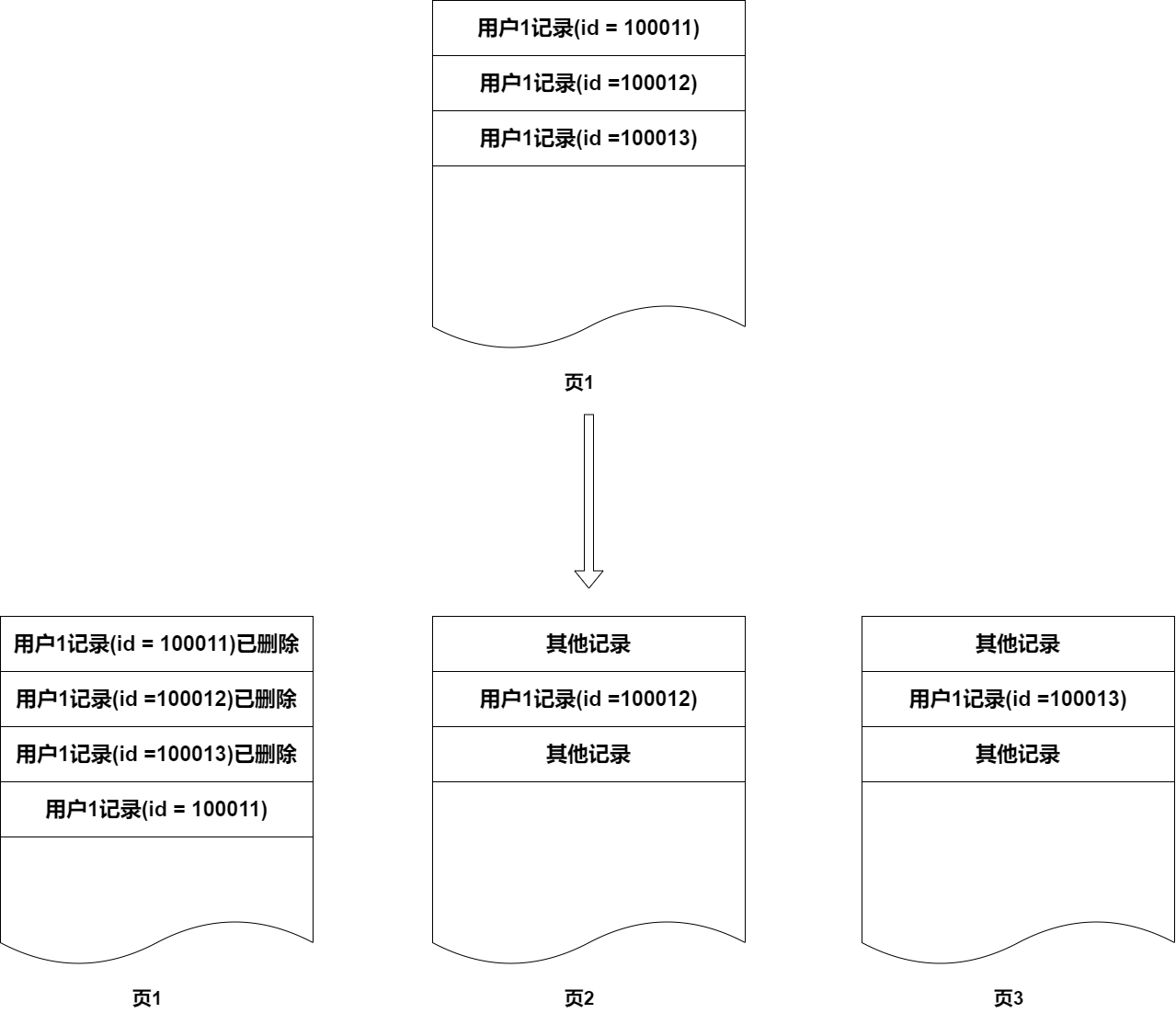
这样导致,原来你需要扫描很少页的数据,随着时间的推移,碎片越来越多,要扫描的页越来越多,这样 SQL 执行会越来越慢。
以上是对于表本身数据存储的影响,对于二级索引,由于 MVCC 机制的存在,导致频繁更新索引字段会对索引也造成很多空洞。参考文档:https://dev.mysql.com/doc/refman/8.0/en/innodb-multi-versioning.html
InnoDB multiversion concurrency control (MVCC) treats secondary indexes differently than clustered indexes. Records in a clustered index are updated in-place, and their hidden system columns point undo log entries from which earlier versions of records can be reconstructed. Unlike clustered index records, secondary index records do not contain hidden system columns nor are they updated in-place.
我们知道,MySQL InnoDB 对于聚簇索引是在索引原始位置上进行更新,对于二级索引,如果二级索引列发生更新则是在原始记录上打上删除标记,然后在新的地方记录。这样和之前一样,会造成很多存储碎片。
综上所述:
- MySQL InnoDB 的会改变记录长度的 Dynamic 行格式记录 Update,以及 Delete 语句,其实是原有记录的删除标记打标记。虽然 MySQL InnoDB 对于这个有做预留空间的优化,但是日积月累,随着归档删除数据的增多,会有很多内存碎片降低扫描效率。
- MVCC 机制对于二级索引列的更新,是在原始记录上打上删除标记,然后在新的地方记录,导致二级索引的扫描效率也随着时间积累而变慢。
解决方案 - 重建表
对于这种情况,我们可以通过重建表的方式解决。重建表其实是一举两得的行为:第一可以优化这种存储碎片,减少要扫描的行数;第二可以重新 analyze 让 SQL 优化器采集数据更准确。
在 MySQL 5.6.17 之前,我们需要借助外部工具 pt-online-schema-change 来帮助我们完成表的重建,pt-online-schema-change 工具的原理其实就是内部新建表,在原表上加好触发器同步更新到新建的表,并且同时复制数据到新建的表中,完成后,获取全局锁修改新建的表名字为原来的表名字,之后删除原始表。MySQL 5.6.17 之后,Optimize table 命令变成了 Online DDL,仅仅在准备阶段以及最后的提交阶段,需要获取锁,中间的执行阶段,是不需要锁的,也就是不会阻塞业务的更新 DML。参考官网文档:https://dev.mysql.com/doc/refman/5.6/en/optimize-table.html
Prior to Mysql 5.6.17, OPTIMIZE TABLE does not use online DDL. Consequently, concurrent DML (INSERT, UPDATE, DELETE) is not permitted on a table while OPTIMIZE TABLE is running, and secondary indexes are not created as efficiently.
As of MySQL 5.6.17, OPTIMIZE TABLE uses online DDL for regular and partitioned InnoDB tables, which reduces downtime for concurrent DML operations. The table rebuild triggered by OPTIMIZE TABLE is completed in place. An exclusive table lock is only taken briefly during the prepare phase and the commit phase of the operation. During the prepare phase, metadata is updated and an intermediate table is created. During the commit phase, table metadata changes are committed.
针对 InnoDB 表使用 Optimize Table 命令需要注意的一些点:
1.针对大部分 InnoDB 表的 Optimize Table,其实等价于重建表 + Analyze命令(等价于语句 ALTER TABLE ... FORCE),但是与 Analyze 命令不同的是, Optimize Table 是 online DDL 并且优化了机制,只会在准备阶段和最后的提交阶段获取表锁,这样大大减少了业务 DML 阻塞时间,也就是说,这是一个可以考虑在线执行的优化语句(针对 MySQL 5.6.17之后是这样)
mysql> OPTIMIZE TABLE foo;
+----------+----------+----------+-------------------------------------------------------------------+
| Table | Op | Msg_type | Msg_text |
+----------+----------+----------+-------------------------------------------------------------------+
| test.foo | optimize | note | Table does not support optimize, doing recreate + analyze instead |
| test.foo | optimize | status | OK |
+----------+----------+----------+-------------------------------------------------------------------+
2.虽然如此,还是要选择在业务低峰的时候执行 Optimize Table,因为和执行其他的 Online DDL 一样,会创建并记录临时日志文件,该文件记录了DDL操作期间所有 DML 插入、更新、删除的数据,如果是在业务高峰的时候执行,很可能会造成日志过大,超过innodb_online_alter_log_max_size 的限制:
mysql> OPTIMIZE TABLE foo;
+----------+----------+----------+----------------------------------------------------------------------------------------------------------------------------+
| Table | Op | Msg_type | Msg_text |
+----------+----------+----------+----------------------------------------------------------------------------------------------------------------------------+
| test.foo | optimize | note | Table does not support optimize, doing recreate + analyze instead |
| test.foo | optimize | error | Creating index 'PRIMARY' required more than 'innodb_online_alter_log_max_size' bytes of modification log. Please try again.|
| test.foo | optimize | status | OK |
+----------+----------+----------+----------------------------------------------------------------------------------------------------------------------------+
3.对于这种情况,如果我们已经处于业务低峰时段,但还是报这个错误,我们可以稍微调大 innodb_online_alter_log_max_size 的大小,但是不能调太大,建议每次调大 128 MB(默认是 128 MB)。如果这个过大,会可能有两个问题:(1)最后的提交阶段,由于日志太大,提交耗时过长,导致锁时间过长。(2)由于业务压力导致一直不断地写入这个临时文件,但是一直赶不上,导致业务高峰到得时候这个语句还在执行。
4.建议在执行的时候,如果要评估这个对于线上业务的影响,可以针对锁 wait/synch/sxlock/innodb/dict_sys_lock 和 wait/synch/sxlock/innodb/dict_operation_lock 这两个锁进行监控,如果这两个锁相关锁事件太多,并且线上有明显的慢 SQL,建立还是 kill 掉选其他时间执行 Optimize table 语句。
select thread_id,event_id,event_name,timer_wait from events_waits_history where event_name Like "%dict%" order by thread_id;
SELECT event_name,COUNT_STAR FROM events_waits_summary_global_by_event_name
where event_name Like "%dict%" ORDER BY COUNT_STAR DESC;
微信搜索“干货满满张哈希”关注公众号,加作者微信,每日一刷,轻松提升技术,斩获各种offer:
我会经常发一些很好的各种框架的官方社区的新闻视频资料并加上个人翻译字幕到如下地址(也包括上面的公众号),欢迎关注:

标签:更新,索引,定期,InnoDB,数据量,MySQL,table,id,重建 来源: https://www.cnblogs.com/zhxdick/p/16215117.html