Hadoop安装与常用操作命令
作者:互联网
一、大纲
1、HDFS集群环境搭建
2、常见问题
3、HDFS Shell命令使用
二、集群环境搭建
下载地址: https://hadoop.apache.org/releases.html

1、初始化目录
在/bigdata/hadoop-3.2.2/下创建目录
mkdir logs secret hadoop_data hadoop_data/tmp hadoop_data/namenode hadoop_data/datanode
2、设置默认认证用户
vi hadoop-http-auth-signature-secret
root
使用simple伪安全配置,需要设置访问用户,具体见core-site.xml。如果需要更安全的认证可以使用kerberos。在hadoop web访问地址后面加 ?user.name=root
比如:http://yuxuan01:8088/cluster?user.name=root
3、修改所有服务器环境变量
vim /etc/profile
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.302.b08-0.el7_9.x86_64/jre
export HADOOP_HOME=/bigdata/hadoop-3.2.2
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
4、配置env环境
1)分别在httpfs-env.sh、mapred-env.sh、yarn-env.sh文件前添加JAVA_HOME环境变量
目录:$HADOOP_HOME/etc/hadoop
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.302.b08-0.el7_9.x86_64/jre
2) 在hadoop-env.sh文件中添加JAVA_HOME和HADOOP_HOME
目录:$HADOOP_HOME/etc/hadoop
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.302.b08-0.el7_9.x86_64/jre
export HADOOP_HOME=/bigdata/hadoop-3.2.2
5、配置用户
在start-dfs.sh和stop-dfs.sh头部配置
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=root
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
YARN_RESOURCEMANAGER_USER=root
YARN_NODEMANAGER_USER=root
在start-yarn.sh和stop-yarn.sh头部配置
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
6、core-site.xml 配置
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://yuxuan01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/bigdata/hadoop-3.2.2/hadoop_data/tmp</value>
</property>
<property>
<name>io.compression.codecs</name>
<value>org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.DefaultCodec,com.hadoop.compression.lzo.LzoCodec,com.hadoop.compression.lzo.LzopCodec,org.apache.hadoop.io.compress.BZip2Codec</value>
</property>
<property>
<name>io.compression.codec.lzo.class</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>
<property>
<name>hadoop.http.filter.initializers</name>
<value>org.apache.hadoop.security.AuthenticationFilterInitializer</value>
<description></description>
</property>
<property>
<name>hadoop.http.authentication.type</name>
<value>simple</value>
</property>
<property>
<name>hadoop.http.authentication.signature.secret.file</name>
<value>/bigdata/hadoop-3.2.2/secret/hadoop-http-auth-signature-secret</value>
<description></description>
</property>
<property>
<name>hadoop.http.authentication.simple.anonymous.allowed</name>
<value>false</value>
<description></description>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>hadoop.proxyuser.jack.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.jack.groups</name>
<value>*</value>
</property>
<!-- -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
<description></description>
</property>
<property>
<name>fs.trash.checkpoint.interval</name>
<value>1440</value>
</property>
</configuration>
7、hdfs-site.xml配置
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/bigdata/hadoop-3.2.2/hadoop_data/namenode</value>
<description></description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/bigdata/hadoop-3.2.2/hadoop_data/datanode</value>
<description></description>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
<description></description>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>yuxuan02:9001</value>
<description></description>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
8、mapred-site.xml配置
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/bigdata/hadoop-3.2.2/etc/hadoop:/bigdata/hadoop-3.2.2/share/hadoop/common/lib/*:/bigdata/hadoop-3.2.2/share/hadoop/common/*:/bigdata/hadoop-3.2.2/share/hadoop/hdfs:/bigdata/hadoop-3.2.2/share/hadoop/hdfs/lib/*:/bigdata/hadoop-3.2.2/share/hadoop/hdfs/*:/bigdata/hadoop-3.2.2/share/hadoop/mapreduce/*:/bigdata/hadoop-3.2.2/share/hadoop/yarn:/bigdata/hadoop-3.2.2/share/hadoop/yarn/lib/*:/bigdata/hadoop-3.2.2/share/hadoop/yarn/*</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/bigdata/hadoop-3.2.2/etc/hadoop:/bigdata/hadoop-3.2.2/share/hadoop/common/lib/*:/bigdata/hadoop-3.2.2/share/hadoop/common/*:/bigdata/hadoop-3.2.2/share/hadoop/hdfs:/bigdata/hadoop-3.2.2/share/hadoop/hdfs/lib/*:/bigdata/hadoop-3.2.2/share/hadoop/hdfs/*:/bigdata/hadoop-3.2.2/share/hadoop/mapreduce/*:/bigdata/hadoop-3.2.2/share/hadoop/yarn:/bigdata/hadoop-3.2.2/share/hadoop/yarn/lib/*:/bigdata/hadoop-3.2.2/share/hadoop/yarn/*</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/bigdata/hadoop-3.2.2/etc/hadoop:/bigdata/hadoop-3.2.2/share/hadoop/common/lib/*:/bigdata/hadoop-3.2.2/share/hadoop/common/*:/bigdata/hadoop-3.2.2/share/hadoop/hdfs:/bigdata/hadoop-3.2.2/share/hadoop/hdfs/lib/*:/bigdata/hadoop-3.2.2/share/hadoop/hdfs/*:/bigdata/hadoop-3.2.2/share/hadoop/mapreduce/*:/bigdata/hadoop-3.2.2/share/hadoop/yarn:/bigdata/hadoop-3.2.2/share/hadoop/yarn/lib/*:/bigdata/hadoop-3.2.2/share/hadoop/yarn/*</value>
</property>
<property>
<name>mapred.map.output.compression.codec</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>
<property>
<name>mapred.child.env</name>
<value>LD_LIBRARY_PATH=/usr/local/hadoop/lzo/lib</value>
</property>
<property>
<name>mapred.child.java.opts</name>
<value>-Xmx1048m</value>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx1310m</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx2620m</value>
</property>
<property>
<name>mapreduce.job.counters.limit</name>
<value>20000</value>
<description>Limit on the number of counters allowed per job. The default value is 200.</description>
</property>
</configuration>
9、yarn-site.xml配置
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>yuxuan01</value>
</property>
<property>
<description>Amount of physical memory, in MB, that can be allocated for containers.</description>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>7192</value>
</property>
<property>
<description>The minimum allocation for every container request at the RM,in MBs.
Memory requests lower than this won't take effect,and the specified value will get allocated at minimum.</description>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1024</value>
</property>
<property>
<description>The maximum allocation for every container request at the RM,in MBs.
Memory requests higher than this won't take effect, and will get capped to this value.</description>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>7192</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.app.mapreduce.am.command-opts</name>
<value>-Xmx2457m</value>
</property>
</configuration>
10、配置works
设置datanode的服务器,之前文件名是slaves,hadoop3之后改为workers了。目录:$HADOOP_HOME/etc/hadoop

11、同步到其他服务器目录
scp -r /bigdata/hadoop-3.2.2/ root@yuxuan02:/bigdata/
scp -r /bigdata/hadoop-3.2.3/ root@yuxuan03:/bigdata/
12、格式化hadoop
hdfs namenode -format
13、启动
./bin/start-all.sh
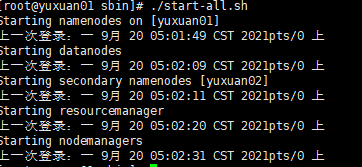
jps
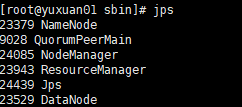
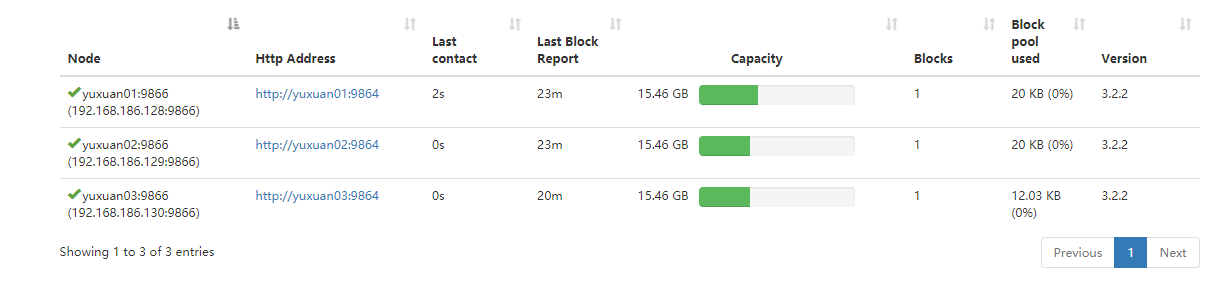
14、web页面查看
-
首次访问(由于设置了simple安全策略):http://yuxuan01:9870?user.name=root
-
Job查看:http://yuxuan01:8088/cluster?user.name=root
三、常见问题
1、启动Namenode失败
查看 /bigdata/hadoop-3.2.2/hadoop_data/namenode目录是否存在
工具初始化: ./bin/hadoop namenode -format
2、启动datanode失败
第一种方法:
每次格式化前,要先关闭
./stop-all.sh
然后再格式化
./hdfs namenode -format
最后启动
./start-all.sh
第二种方法:
进入/bigdata/hadoop-3.2.2/hadoop_data/namenode目录(此目录为namenode的dfs.name.dir配置的路径)
rm -rf /bigdata/hadoop-3.2.2/hadoop_data/namenode
然后再格式化
./hdfs namenode -format
最后启动
./start-all.sh
四、HDFS常用Shell命令
http://hadoop.apache.org/docs/r1.2.1/commands-manual.html
用户命令和管理员命令
./hadoop 查看所有命令
./hadoop fs -put hadoop / 假设上传hadoop文件 到/目录
./hadoop fs -lsr /
./hadoop fs -du / 查看文件大小
./hadoop fs -rm /hadoop 删除文件
./hadoop fs -rmr /hadoop 删除文件夹下所有文件
./hadoop fs -mkdir /louis 创建目录
./hadoop dfsadmin -report 报告文件信息和统计信息
./hadoop dfsadmin -safemode enter 只读模式
/hadoop dfsadmin -safemode leave 离开模式
./hadoop fsck /louis -files -blocks 检查文件是否健康
fsck作用
1) 检查文件系统的健康状态
2)查看文件所在的数据块
3)删除一个坏块
4)查找一个缺失的块
hadoop balancer 磁盘均衡器
hadoop archive 文件归档,小文件合并在一起
./hadoop archive -archiveName pack.har -p /loris hadoop arichivdDir 生成归档包
./hadoop fs -lsr /user/louris/arichiveDirpack.har
./hadoop fs -cat /user/louis/archiveDir/pack.har/_index 查看归档包文件
标签:操作命令,share,bigdata,yarn,Hadoop,3.2,HOME,hadoop,安装 来源: https://www.cnblogs.com/binfirechen/p/16180485.html