ElasticSearch7集群+Keepalived
作者:互联网
ElasticSearch7集群+Keepalived
环境说明
- 三台centos7虚拟机
| 服务器 | 内存 |
|---|---|
| 192.168.1.153 | 内存10G |
| 192.168.1.154 | 内存10G |
| 192.168.1.164 | 内存10G |
-
安装好jdk环境
yum install -y java-11-openjdk java-11-openjdk-devel

- 关闭防火墙和SELinux
ES集群搭建
搭建
创建es运行用户
useradd elasticsearch
配置elasticsearch.yml文件内容
cluster.name: search-cluster
node.name: node-1
node.master: true
node.data: true
path.data: /data/elasticsearch/data
path.logs: /data/elasticsearch/logs
bootstrap.memory_lock: true
bootstrap.system_call_filter: false
network.host: 192.168.1.153
http.port: 9200
discovery.zen.minimum_master_nodes: 2
discovery.zen.ping_timeout: 10s
transport.port: 9300
cluster.initial_master_nodes: ["192.168.1.153","192.168.1.154","192.168.1.164"]
discovery.seed_hosts: ["192.168.1.153","192.168.1.154","192.168.1.164"]
xpack.ml.enabled: false
cluster.name: search-cluster
node.name: node-2
node.master: true
node.data: true
path.data: /data/elasticsearch/data
path.logs: /data/elasticsearch/logs
bootstrap.memory_lock: true
bootstrap.system_call_filter: false
network.host: 192.168.1.154
http.port: 9200
discovery.zen.minimum_master_nodes: 2
discovery.zen.ping_timeout: 10s
transport.port: 9300
cluster.initial_master_nodes: ["192.168.1.153","192.168.1.154","192.168.1.164"]
discovery.seed_hosts: ["192.168.1.153","192.168.1.154","192.168.1.164"]
xpack.ml.enabled: false
cluster.name: search-cluster
node.name: node-3
node.master: true
node.data: true
path.data: /data/elasticsearch/data
path.logs: /data/elasticsearch/logs
bootstrap.memory_lock: true
network.host: 192.168.1.164
http.port: 9200
discovery.zen.minimum_master_nodes: 2
discovery.zen.ping_timeout: 10s
transport.port: 9300
cluster.initial_master_nodes: ["192.168.1.153","192.168.1.154","192.168.1.164"]
discovery.seed_hosts: ["192.168.1.153","192.168.1.154","192.168.1.164"]
xpack.ml.enabled: false
(1)cluster.name
集群名字,三台集群的集群名字都必须一致
(2)node.name
节点名字,三台ES节点字都必须不一样
(3)discovery.zen.minimum_master_nodes:2
表示集群最少的master数,如果集群的最少master数据少于指定的数,将无法启动,官方推荐node master数设置为集群数/2+1,我这里三台ES服务器,配置最少需要两台master,整个集群才可正常运行,
(4)node.master该节点是否有资格选举为master,如果上面设了两个mater_node 2,也就是最少两个master节点,则集群中必须有两台es服务器的配置为node.master: true的配置,配置了2个节点的话,如果主服务器宕机,整个集群会不可用,所以三台服务器,需要配置3个node.masdter为true,这样三个master,宕了一个主节点的话,他又会选举新的master,还有两个节点可以用,只要配了node master为true的ES服务器数正在运行的数量不少于master_node的配置数,则整个集群继续可用,我这里则配置三台es node.master都为true,也就是三个master,master服务器主要管理集群状态,负责元数据处理,比如索引增加删除分片分配等,数据存储和查询都不会走主节点,压力较小,jvm内存可分配较低一点
(5)node.data
存储索引数据,三台都设为true即可
(6)bootstrap.memory_lock: true
锁住物理内存,不使用swap内存,有swap内存的可以开启此项
(7)discovery.zen.ping_timeout: 10s
自动发现拼其他节点超时时间
(8)cluster.initial_master_nodes: ["192.168.1.153","192.168.1.154","192.168.1.164"] 设置集群的初始节点列表
(9)discovery.seed_hosts: 此处填各个节点的hostname
(10)xpack.ml.enabled: false 启动报错,根据提示,关闭机器学习的功能
设置用户及新建目录
mkdir -p /data/elasticsearch/data
mkdir -p /data/elasticsearch/logs
cd /data/elasticsearch/
chown elasticsearch:elasticsearch data/ -R
chown elasticsearch:elasticsearch logs/ -R
cd /home/elasticsearch/
chown elasticsearch:elasticsearch elasticsearch-7.16.3/ -R
操作系统调优
具体可以参考:https://www.elastic.co/guide/en/elasticsearch/reference/7.16/system-config.html
【1】内存优化
在/etc/sysctl.conf添加如下内容
fs.file-max=655360
vm.max_map_count=655360
sysctl -p生效
【2】修改vim /etc/security/limits.conf
elasticsearch hard nofile 65536
elasticsearch soft nofile 65536
elasticsearch soft memlock unlimited
elasticsearch hard memlock unlimited
【3】修改/etc/security/limits.d/20-nproc.conf
elasticsearch soft nproc unlimited
【4】关闭swap
swapoff -a
vi /etc/fstab 注释掉所有包含swap单词的行

启动es集群
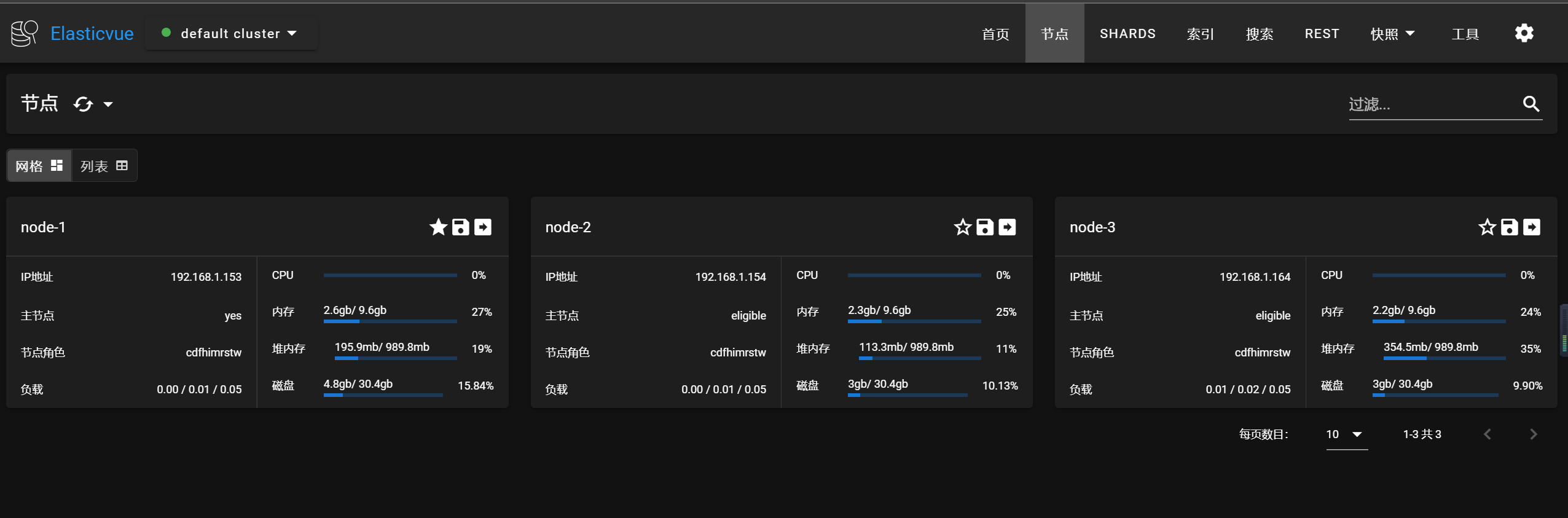
三台虚拟机,用elasticsearch用户,切换到es的目录下,执行下面目录,启动成功,集群状态为绿色
./bin/elasticsearch -d
密码设置
生成CA证书
bin/elasticsearch-certutil ca (将产生新文件 elastic-stack-ca.p12)
在Elasticsearch集群中验证证书真实性的推荐方法是信任签署证书的证书颁发机构(CA)。这样,只需要使用由同一CA签名的证书,即可自动允许该节点加入集群。另外证书中可以包含与节点的IP地址和DNS名称相对应的主题备用名称,以便可以执行主机名验证。
为集群中的某个节点生成证书
bin/elasticsearch-certutil cert --ca elastic-stack-ca.p12 ----将产生新文件 elastic-certificates.p12
mv elastic-certificates.p12 config/
默认情况下 elasticsearch-certutil 生成没有主机名信息的证书,这意味着你可以将证书用于集群中的每个节点,另外要关闭主机名验证。
将 elastic-certificates.p12 文件复制到集群中的每个节点
无需将 elastic-stack-ca.p12 文件复制config目录下。
配置集群每个节点以使用其签名证书标识自身并启用TLS
(1)开启安全认证
xpack.security.enabled: true
xpack.license.self_generated.type: basic
(2)开启ssl
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
(3)生成ca证书
xpack.security.transport.ssl.keystore.path: /home/elasticsearch/elasticsearch-7.16.3/config/elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: /home/elasticsearch/elasticsearch-7.16.3/config/elastic-certificates.p12
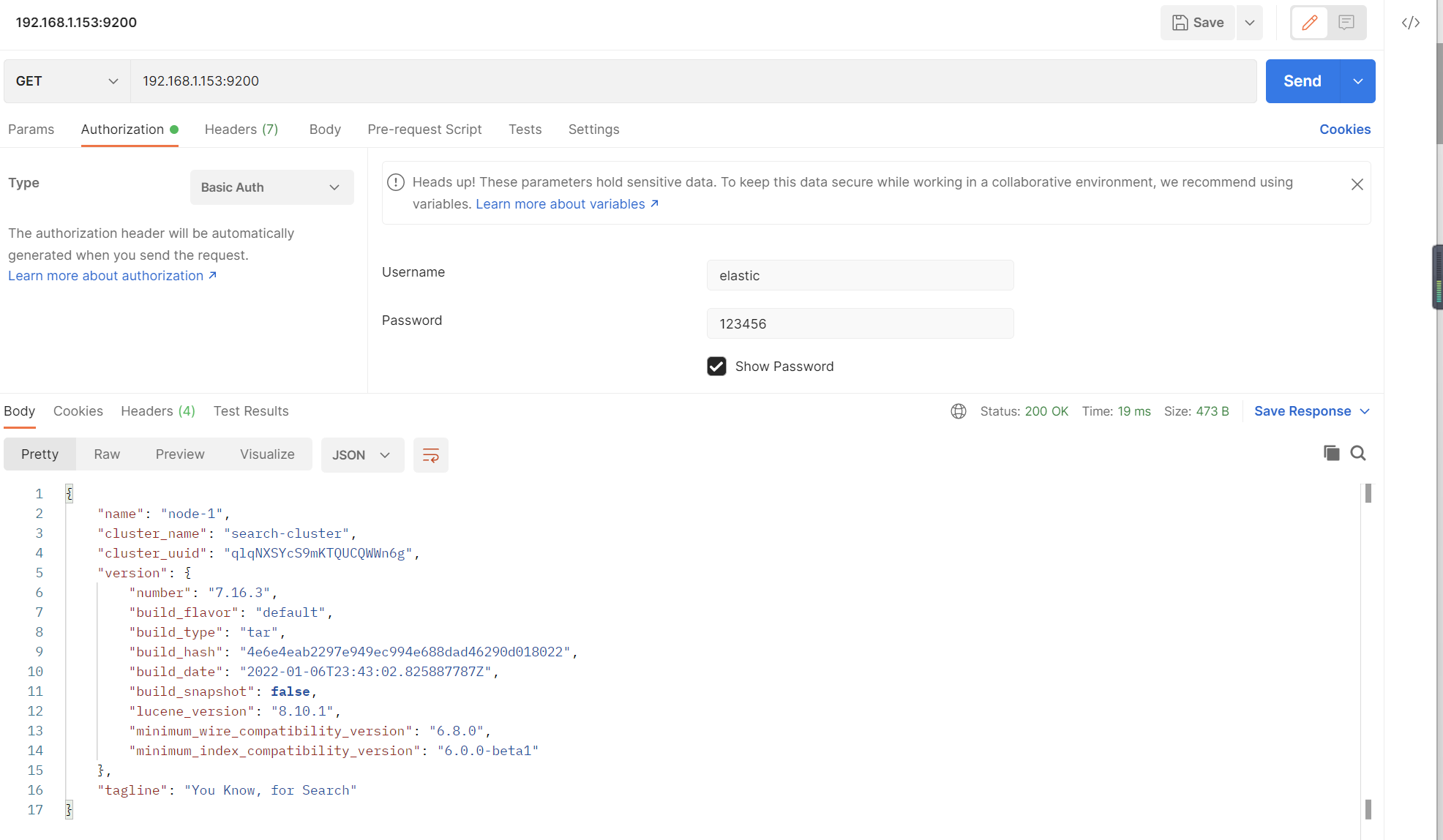
为用户名设置密码
./elasticsearch-setup-passwords interactive
一直回车即可
测试
添加账号密码后可以访问
Keepalived
安装
(1)三台虚拟机,使用yum命令进行安装
yum install keepalived -y
(2)安装之后,在etc里面生成目录keepalived,有文件keepalived.conf

(3)修改keepalived.conf的配置文件
global_defs {
notification_email {
acassen@firewall.loc
failover@firewall.loc
sysadmin@firewall.loc
}
notification_email_from Alexandre.Cassen@firewall.loc
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id LVS_DEVEL
vrrp_skip_check_adv_addr
vrrp_strict
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_script check_elasticsearch{
script "/etc/keepalived/check_elasticsearch.sh" # keepalived 监测 elasticsearch 的监本路径和名称
interval 2
weight 2
}
vrrp_instance VI_1 {
state MASTER # 服务器状态,MASTER 代表主服务器, BACKUP 是备份服务器
interface ens192 # 通信端口,通过 ifconfig 命令可以看到,根据自己的机器配置
virtual_router_id 51 # 虚拟路由 ID ,主实例和副本实例保持一致
priority 100 # 权重比,主服务器的 priority 比副本服务器大即可
advert_int 1 # 心跳间隔,单位秒, keepalived 多机器集群通过心跳检测,如果发送心跳没反应,就立刻接管
authentication {
auth_type PASS
auth_pass 1111
}
track_script { # keepalived 的监测脚本,与 vrrp_script 定义的名称一致
check_elasticsearch
}
virtual_ipaddress {
192.168.1.188
}
}
配置说明:
global_defs: 为全局配置,定义邮件配置,route_id,vrrp配置,多播地址等,此处为原配置,暂不修改。
vrrp_script: 执行检测的脚本
vrrp_instance: 定义每个vrrp虚拟路由器
此配置为153的配置,设置其keepalived为Master,154和164的配置,就state和priority不一样,为BACKUP和低一些的权重比。
(4)检测es脚本
#!/bin/bash
# elasticsearch 挂掉之后, keepalived 重新启动 elasticsearch ,若不能启动 则关闭当前 keepalived
status=`ps -ef|grep -w /home/elasticsearch/elasticsearch-7.16.3 |grep -v grep|wc -l`
echo ${status}
if [ ${status} -eq 0 ]; then
systemctl stop keepalived
fi
注:脚本中也可以检测es不存在时,先去重启es,在睡眠20s后,如果还启动失败,再去停用keepalived,此处不演示。
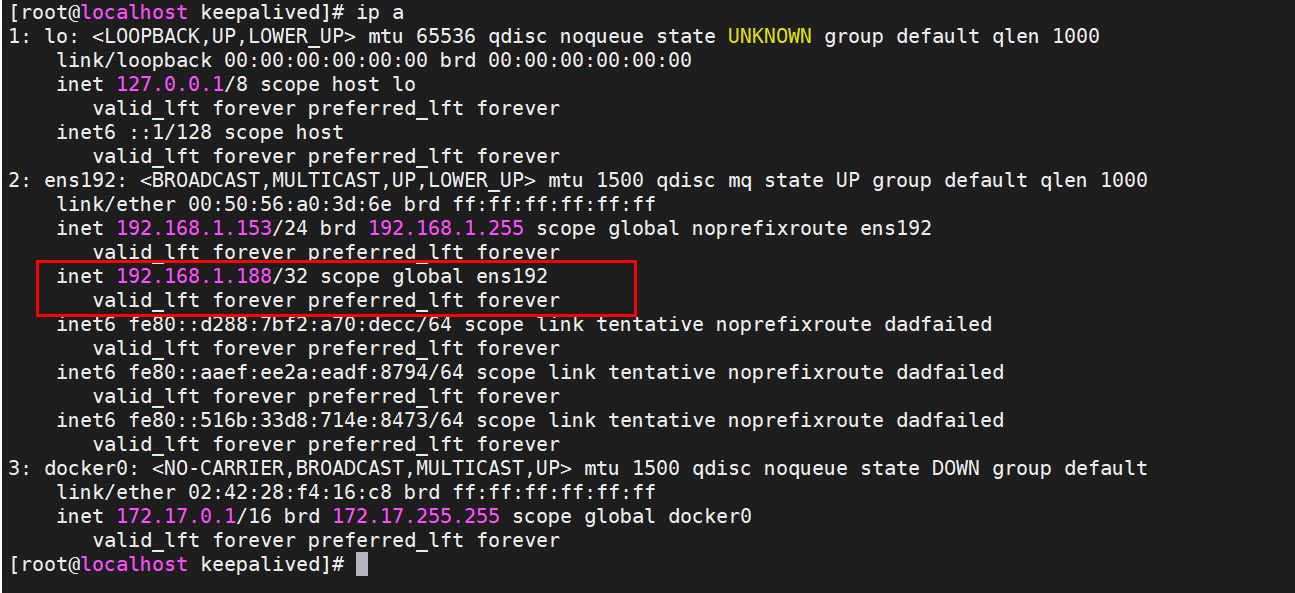
(5)启动keepalived
systemctl start keepalived
由于153设置的为Master,查看有没有虚拟ip生成
测试
排查问题
3个节点起来后,发现无法通过虚拟ip访问到es集群,随即在153安装一个nginx,进行测试,排查是es集群的问题还是keepalived的问题。
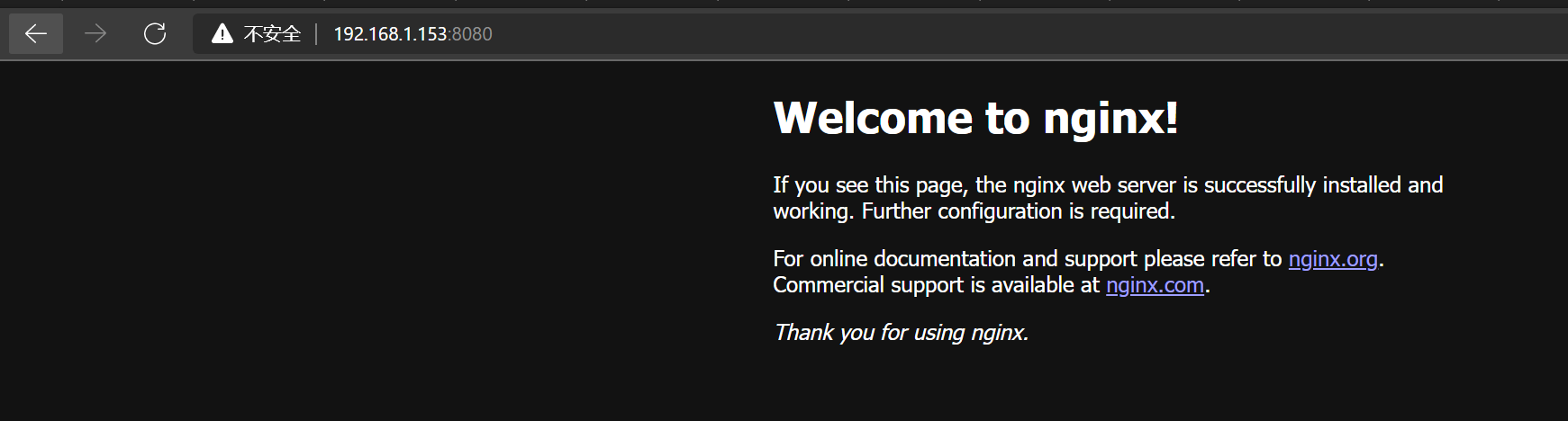
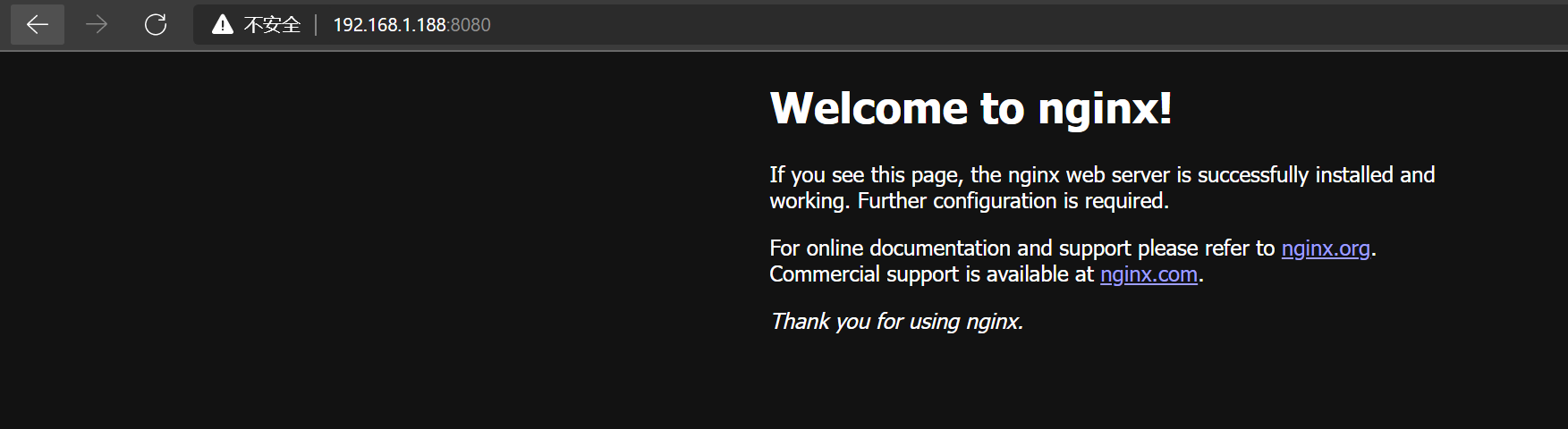
发现是可以通过vip访问nginx的,随即又快速运行了单节点的mysql和es,结果发现都可以访问,暂时基本确认keepalived和es集群不通,可能被拦截了,但是环境准备期间,已经把防火墙都关闭了,随即打算看一下虚拟机的iptables
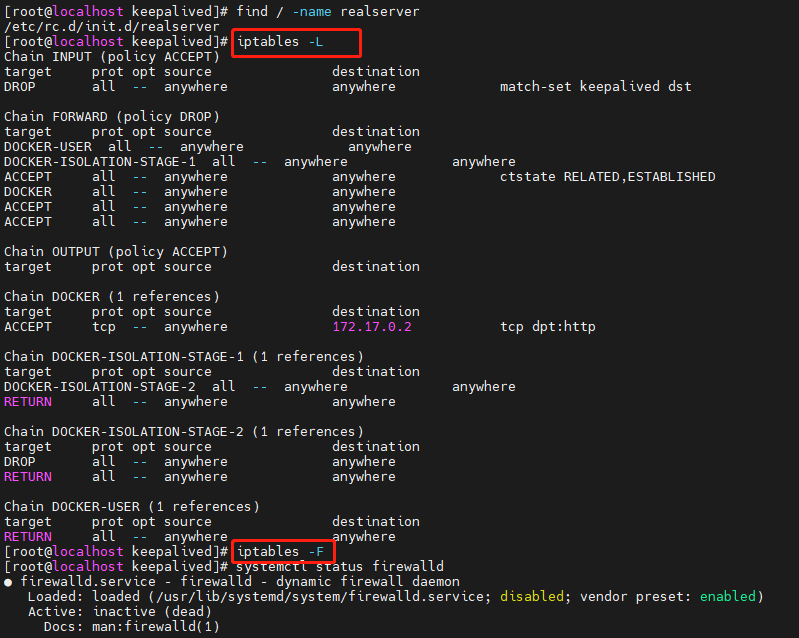
发现有很多的路由策略,先清空所有的策略,在测试一下看看,结果生效了。
解决问题
上述基本可以确定,启动了keepalived会有很多的路由策略,清空后可以访问,但是重启后,又会生成,应该是配置文件少了什么,参考这篇博客:https://blog.csdn.net/u010864567/article/details/122379595
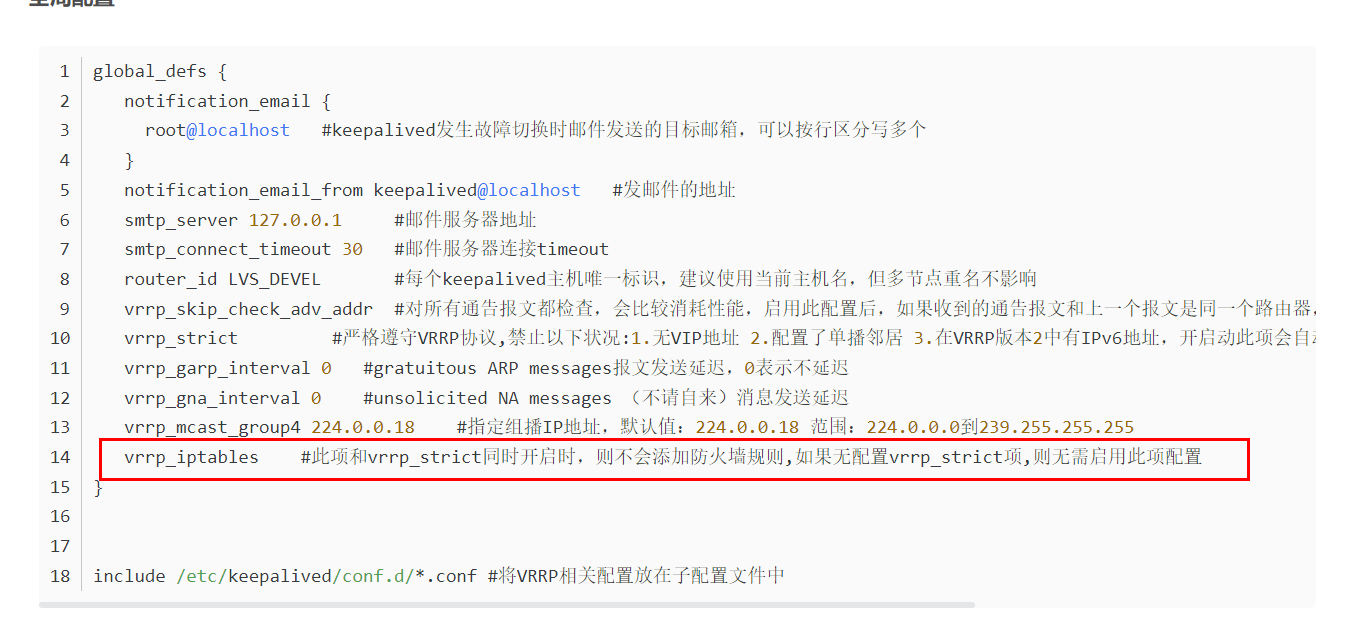
在全局配置加上这个配置后,重启后就可以了。
故障演练
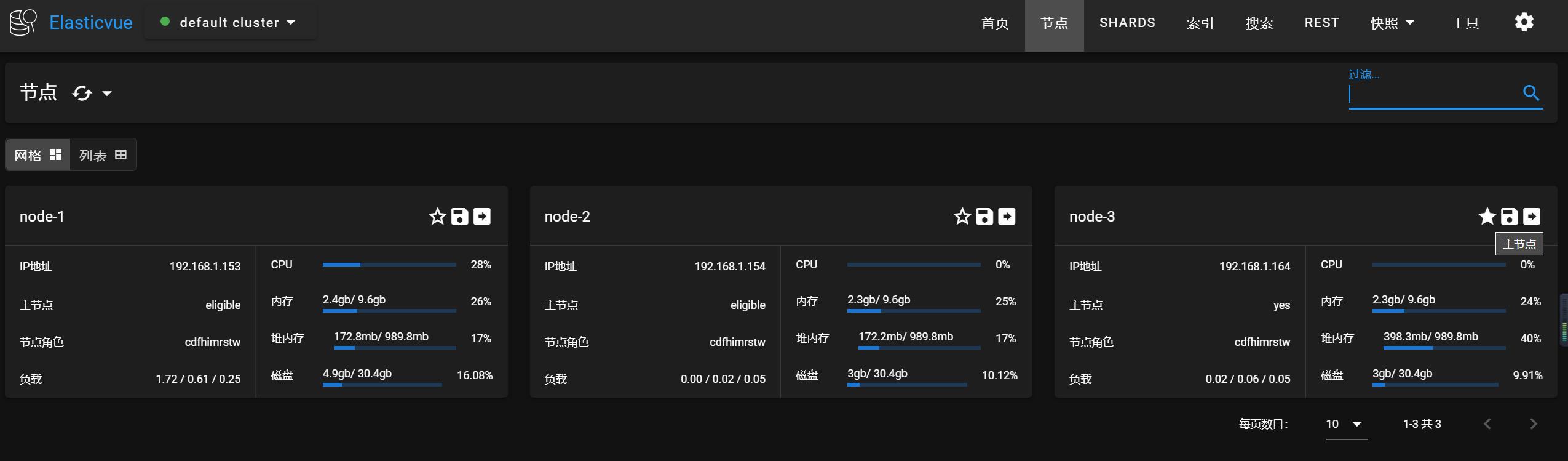
现在es主节点在164环境,keepalived的现在也在164
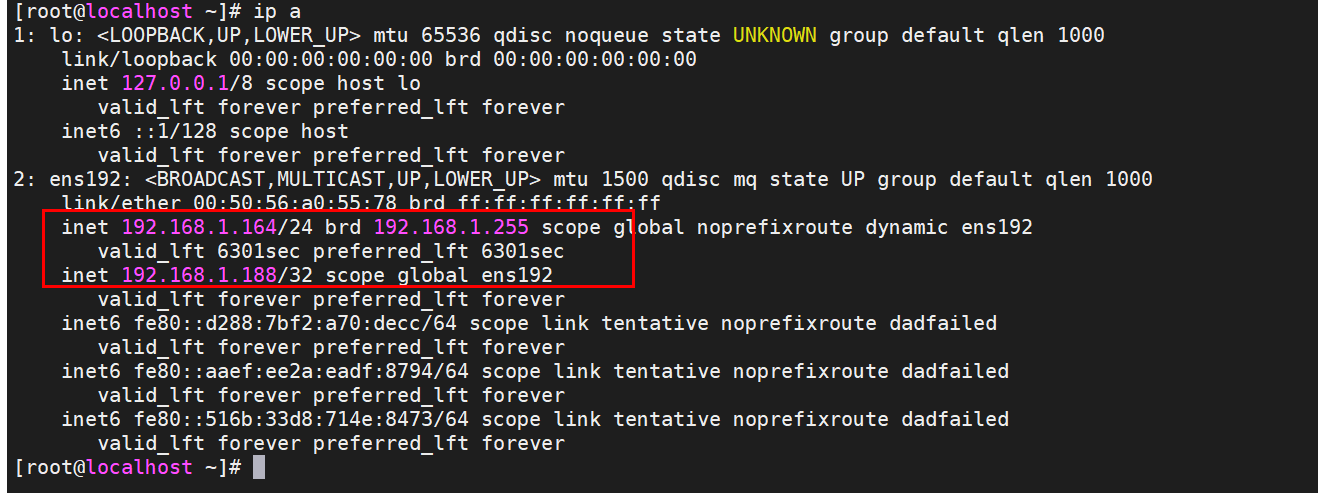
[root@localhost ~]# netstat -nltp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1097/sshd
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 1475/master
tcp6 0 0 :::22 :::* LISTEN 1097/sshd
tcp6 0 0 ::1:25 :::* LISTEN 1475/master
tcp6 0 0 192.168.1.164:9200 :::* LISTEN 9668/java
tcp6 0 0 192.168.1.164:9300 :::* LISTEN 9668/java
[root@localhost ~]# kill -9 9668
[root@localhost ~]# systemctl status keepalived
● keepalived.service - LVS and VRRP High Availability Monitor
Loaded: loaded (/usr/lib/systemd/system/keepalived.service; disabled; vendor preset: disabled)
Active: inactive (dead)
4月 17 14:59:01 localhost.localdomain Keepalived_vrrp[10826]: Sending gratuitous ARP on ens192 for 192.168.1.188
4月 17 15:02:59 localhost.localdomain Keepalived[10824]: Stopping
4月 17 15:02:59 localhost.localdomain systemd[1]: Stopping LVS and VRRP High Availability Monitor...
4月 17 15:02:59 localhost.localdomain Keepalived_healthcheckers[10825]: Stopped
4月 17 15:02:59 localhost.localdomain Keepalived_vrrp[10826]: VRRP_Instance(VI_1) sent 0 priority
4月 17 15:02:59 localhost.localdomain Keepalived_vrrp[10826]: VRRP_Instance(VI_1) removing protocol VIPs.
4月 17 15:02:59 localhost.localdomain Keepalived_vrrp[10826]: VRRP_Instance(VI_1) removing protocol iptable drop rule
4月 17 15:03:00 localhost.localdomain Keepalived_vrrp[10826]: Stopped
4月 17 15:03:00 localhost.localdomain Keepalived[10824]: Stopped Keepalived v1.3.5 (03/19,2017), git commit v1.3.5-6-g6fa32f2
4月 17 15:03:00 localhost.localdomain systemd[1]: Stopped LVS and VRRP High Availability Monitor.
[root@localhost ~]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens192: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:50:56:a0:55:78 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.164/24 brd 192.168.1.255 scope global noprefixroute dynamic ens192
valid_lft 6266sec preferred_lft 6266sec
inet6 fe80::d288:7bf2:a70:decc/64 scope link tentative noprefixroute dadfailed
valid_lft forever preferred_lft forever
inet6 fe80::aaef:ee2a:eadf:8794/64 scope link tentative noprefixroute dadfailed
valid_lft forever preferred_lft forever
inet6 fe80::516b:33d8:714e:8473/64 scope link tentative noprefixroute dadfailed
valid_lft forever preferred_lft forever
[root@localhost ~]#
此时停掉es后,发现keepalived也停止运行,master漂移在了154上。
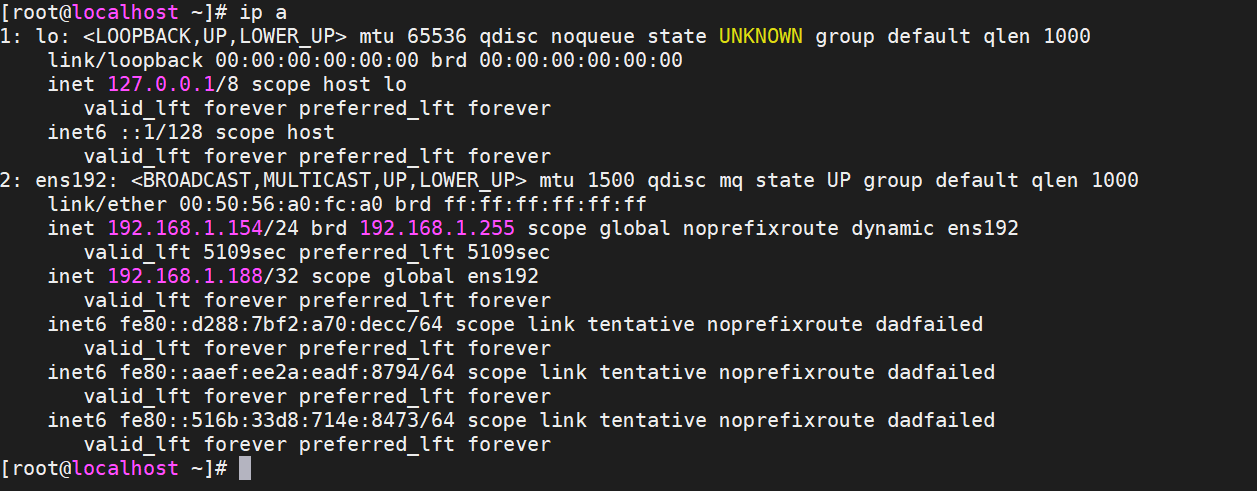
这个时候es集群的状态如下:
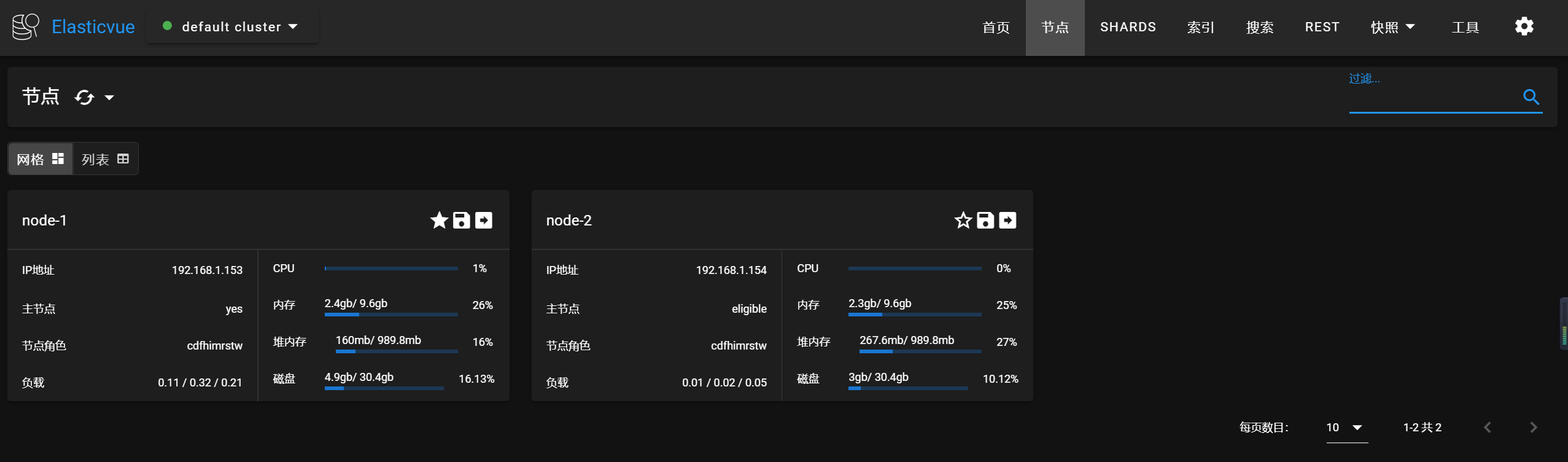
测试能否通过vip访问es的集群,结果如下

建议
keepalived是一种借助lvs实现的的高可用方案,在物理机环境下是很好实施的。但是在云环境,因为keepalived要绑定一个vip,由于vpc网络的安全限制,是无法直接部署的,就需要云厂商的havip的功能了,具体可以参考:https://www.coder4.com/archives/7366
标签:node,keepalived,Keepalived,192.168,ElasticSearch7,集群,master,elasticsearch,data 来源: https://www.cnblogs.com/dalianpai/p/16178573.html