字符串的其他内置方法和列表的内置方法
作者:互联网
字符串的其他内置方法(非常重要)
这些内置是在我们写程序的时候会经常用到的,使用我们有必要全部记住,就算不能全部记住,我们也需要知道字符串有的内置函数。
1.移除字符串首尾的指定字符 我们可以选择移除的方向默认是两边全部,不填写指定字符就是移除空格。
str = '!!!!春游去动物园!!!'
print(str.strip('!')) # 春游去动物园
print(str.lstrip('!')) # 春游去动物园!!! 移除左边
print(str.rstrip('!')) # !!!!春游去动物园 移除右边
2.大小写
str2 = 'aBcD'
print(str2.lower()) # abcd 将所有的英文字母变为小写
print(str2.upper()) # ABCD 将所有的英文字母变为大写
print(str2.islower()) # False 判断字符串中所有的英文字母是否是纯小写 返回值是布尔值
print(str2.isupper()) # False 判断字符串中所有的英文字母是否是纯大写 返回值是布尔值
3.判断字符串的开头或者结尾是否是指定的字符
str3 = 'hello world'
print(str3.startswith('h')) # True
print(str3.startswith('hello')) # True
print(str3.startswith('world')) # False
print(str3.endswith('d')) # True
print(str3.endswith('world')) # True
print(str3.endswith('hello')) # False
4.格式化输出
第一种:和占位符用法一样,但是使用{}占位
print('I am {},hobby is {}'.format('春游去动物园','玩'))
第二种:根据索引取值 可以反复使用
print('I am {0} {0} {1},hobby is {1} {0}'.format('春游去动物园','玩'))
I am 春游去动物园 春游去动物园 玩,hobby is 玩 春游去动物园
第三种:根据指名道姓的方式取值
print('I am {name} {hobby},hobby is {name}{hobby}'.format(name = '春游去动物园',hobby = '玩'))
I am 春游去动物园 玩,hobby is 春游去动物园玩
第四种:直接使用已经出现过的变量
name = '春游去动物园'
hobby = '玩'
print(f'I am {name} {hobby},hobby is {hobby} {name}')
I am 春游去动物园 玩,hobby is 玩 春游去动物园
千万不要忘了在要格式化输出的字符串前加f!!!!!!
5.拼接字符串
str5 = '少壮不努力'
str5_1 = '老来靠吉言'
print(str5 + str5_1)#少壮不努力老来靠吉言
print(str5 * 5)#少壮不努力少壮不努力少壮不努力少壮不努力少壮不努力
print('|'.join(str5))#少|壮|不|努|力
print('*'.join(['1', '2', '3', '4', '5']))#1*2*3*4*5
join的元素必须都是字符串才可以 否则报错
6.替换字符串中指定的字符
str6 = 'hello hello hello world hero hello'
替换全部
print(str6.replace('hello', '111')) #111 111 111 world hero 111
替换指定的个数(从左往右)
print(str6.replace('hello', '111', 1)) #111 hello hello world hero hello
7.判断字符串中是否是纯数字
str7 = 'qwe123'
print(str7.isdigit()) # False
print('123'.isdigit()) # True
print('123.123'.isdigit()) # False
需要了解的操作
1.查找指定字符对应的索引值
s1 = 'jason justin kevin tony'
print(s1.find('s')) # 从左往右查找 查找一个就结束
print(s1.find('k', 1, 9)) # -1 意思是没有 找不到
print(s1.index('s'))
print(s1.index('k', 1, 9)) # 找不到直接报错 不推荐使用
2.文本位置改变
name = 'tony'
print(name.center(30, '-')) # -------------tony-------------
print(name.ljust(30, '*')) # tony**************************
print(name.rjust(30, '$')) # $$$$$$$$$$$$$$$$$$$$$$$$$$tony
print(name.zfill(50)) # zero 零 0000000000000000000000000000000000000000000000tony
3.特殊符号:斜杠与一些英文字母的组合会产生特殊的含义
print('ja\tson\nke\avin')
'''如果想取消它们的特殊含义 可以在字符串的前面加一个字母r'''
print(r'ja\tson\nke\avin')
4.capitalize,swapcase,title
4.1 captalize:首字母大写
message = 'hello everyone nice to meet you!'
message.capitalize()
Hello everyone nice to meet you!
4.2 swapcase:大小写翻转
message1 = 'Hi girl, I want make friends with you!'
message1.swapcase()
hI GIRL, i WANT MAKE FRIENDS WITH YOU!
4.3 title:每个单词的首字母大写
msg = 'dear my friend i miss you very much'
msg.title()
Dear My Friend I Miss You Very Much
列表内置方法
1.类型转化
print(list('春游去动物园')) # ['春', '游', '去', '动', '物', '园']
print(list({'name': '春游去动物园', 'password': 123})) # ['name', 'password']
print(list((11, 22, 33, 44, 55))) # [11, 22, 33, 44, 55]
print(list({1, 2, 3, 4, 5})) # [1, 2, 3, 4, 5]
"""
list可以转换支持for循环的数据类型
可以被for循环的数据类型
字符串 列表 字典 元组 集合
"""
2.常见操作
data = ['春', '游', '去', '动', '物', '园']
1.索引取值
print(data[0]) # 春
2.切片操作
print(data[1:3]) # ['游', '去']
print(data[-1::-1]) # ['园', '物', '动', '去', '游', '春']
3.间隔
print(data[1:5:2]) # ['游', '动']
4.统计列表中元素的个数
print(len(data)) # 6
5.成员运算 最小判断单位是元素不是元素里面的单个字符
print('春' in data) # True
print('111' in data) # False
6.列表添加元素的方式
1.尾部追加'单个'元素
data.append('去')
print(data) # ['春', '游', '去', '动', '物', '园', '去']
data.append(['游乐园'])
print(data) # ['春', '游', '去', '动', '物', '园', '去', ['游乐园']]
2.指定位置插入'单个'元素
data.insert(0, '我')
print(data) # ['我', '春', '游', '去', '动', '物', '园']
data.insert(4, '去哪')
print(data) # ['我', '春', '游', '去', '去哪', '动', '物', '园']
3.合并列表
data.extend([11, 22, 33, 44, 55])
print(data) # ['春', '游', '去', '动', '物', '园', 11, 22, 33, 44, 55]
'''extend其实可以看成是for循环+append'''
data += [11,22,33,44] # 加号的效率不高
7.删除
1.通用的删除方式
del data[0]
print(data)#['游', '去', '动', '物', '园']
2.指名道姓的直接删除某个元素
data.remove('去')
print(data) # ['春', '游', '动', '物', '园']
3.延迟删除
data.pop() # 默认是尾部弹出
print(data) # ['春', '游', '去', '动', '物']
data.pop(1)
print(data) # ['春', '去', '动', '物', '园']
data.pop(0)
print(data) # ['游', '去', '动', '物', '园']
8.修改列表元素
data[0] = '秋'
print(data) # ['秋', '游', '去', '动', '物', '园']
9.排序
data_number = [1, 5, 3, 6, 8, 0, 66]
data_number.sort() # 默认是升序
print(data_number) # [0, 1, 3, 5, 6, 8, 66]
data_number.sort(reverse=True) #降序
print(data_number) # [66, 8, 6, 5, 3, 1, 0]
10.反转
data.reverse() #顺序颠倒,(前面的到后面去)
11.比较运算
s1 = [11, 22, 33]
s2 = [1, 2, 3, 4, 5, 6, 7, 8]
print(s1 > s2) # True
"""列表在做比较的时候 其实比的是对应索引位置上的元素"""
s1 = ['A', 'B', 'C'] # A>>>65
s2 = ['a'] # a>>>97
print(s1 > s2) # False
"""如果比较的2个是字母,将会根据字母的ASCII码值来进行比较。"""
12.统计列表中某个元素出现的次数
l1 = [11, 22, 33, 44, 33, 22, 11, 22, 11, 22, 33, 22, 33, 44, 55, 44, 33]
print(l1.count(11)) # 统计元素11出现的次数
l1.clear() # 清空列表
可变类型和不可变类型
可变数据类型:列表list和字典dict;不可变数据类型:整型int、浮点型float、字符串型string和元组tuple。
"""
可变类型与不可变类型
可变类型 列表
值改变 内存地址不变 修改的是本身
不可变类型 字符串
值改变 内存地址肯定遍 修改过程产生了新的值
如何查看变量的'内存地址'
id(变量名)
"""
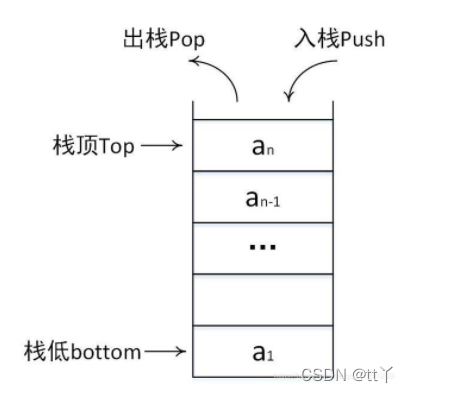
队列和堆栈
Stack(栈):数据先进后出,类比放盘子,最先放的盘子最后拿出;最后放的盘子最先拿出
进栈:向一个栈插入新元素,它是把新元素放到栈顶元素的上面,变成新的栈顶元素;
出栈:从一个栈删除元素,它是把栈顶元素删除掉,使其相邻的元素成为新的栈顶元素。
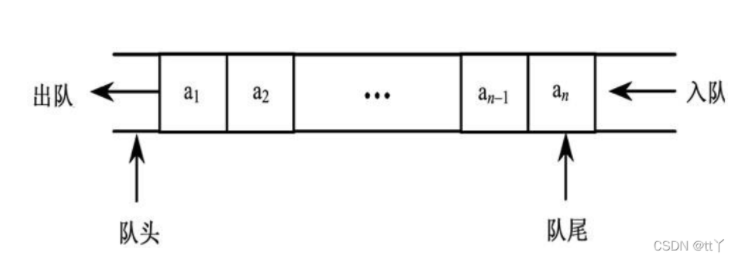
(2)在队尾添加元素,在队头删除元素。
标签:内置,name,方法,列表,春游,print,hobby,data,hello 来源: https://www.cnblogs.com/chunyouqudongwuyuan/p/15986473.html