数仓中长跳转问题复现及解决方案
作者:互联网
摘要:本文将GaussDB(DWS)中长跳转引发的错误抽象为例子,讨论了C语言在长跳转下可能会出现的问题,最后简单给出了解决方法和验证。
本文分享自华为云社区《GaussDB(DWS)中长跳转可能出现的问题》,作者: 雷电与骤雨。
问题描述,在GaussDB(DWS)编码实践中,发现在debug未进行编译器优化的版本未发生问题,但是在release版本,发生了一些变量赋值后失效,仍为旧值的bug,本文将对此在两个角度下进行简单分析。
什么是长跳转?
在C语言中,goto语句常常实现程序执行中的近程跳转(local jump),longjmp()和setjmp()函数实现程序执行中的远程跳转(nonlocaljump,也叫farjump)。
主要相关的为两个函数的签名:
int setjmp(jmp_buf env); void longjmp(jmp_buf env, int value);
一般理解为:setjmp 函数把执行这个函数时的各种上下文信息保存起来,储存到jmp_buf中,主要就是当前栈的位置,寄存器状态。longjmp 函数跳转到参数 env 缓冲区中保存的上下文(快照)中去。并且也有人提出会与实现方式 implementation有关。
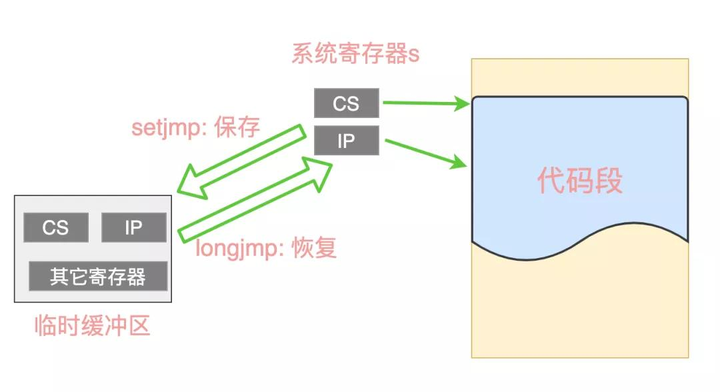
我觉得下面这句还是比较可信的:
The setjmp() function saves the contents of most of the general purpose registers, in the same way as they would be saved on any function entry. It also saves the stack pointer and the return address. All these are placed in the buffer. It then arranges for the function to return zero.
编译器优化问题
问题发生于debug版本和release版本出现了不同的结果,其中的差异主要是编译器在编译构建中的优化过程。一般编译器优化常用的方法有:将内存变量缓存到寄存器。
由于访问寄存器要比访问内存单元快的多,编译器在存取变量时,为提高存取速度,编译器优化有时会先把变量读取到一个寄存器中;以后再取变量值时就直接从寄存器中取值。但在很多情况下会读取到脏数据,严重影响程序的运行效果。
解决方法 C++ Volatile关键字
Volatile,词典上的解释为:易失的;易变的;易挥发的。个人理解就是在每次给该变量赋值后,需要将其放入内存,而非直接使用寄存器,此时可以避免因为jump和函数跳转带来的未写入内存导致赋值未成功(仍为旧值),或者编译器优化,将值直接放于寄存器(此值可能因为多次使用,避免从内存中来回多次读取)。
问题复现
实例未优化,debug未优化版本
#include <stdio.h>
#include <stdlib.h>
#include <setjmp.h>
static jmp_buf env;
static void
doJump(int nvar, int rvar, int vvar)
{
printf("Inside doJump(): nvar=%d, rvar=%d, vvar=%d\n"
, nvar,rvar, vvar);
//死代码块
int nvar0 = nvar;
int rvar0 = rvar;
int vvar0 = vvar;
longjmp(env, 1);
}
int main(int argc, char** argv)
{
int nvar;
register int rvar;
volatile int vvar;
nvar = 111;
rvar = 222;
vvar = 333;
if(setjmp(env) == 0)
{
nvar = 777;
rvar = 888;
vvar = 999;
doJump(nvar, rvar, vvar);
}
else
{
int nvar1 = nvar;
int rvar1 = rvar;
int vvar1 = vvar;
printf("After longjmp(): nvar =%d, rvar=%d, vvar=%d\n", nvar, rvar, vvar);
}
exit(EXIT_SUCCESS);
}
程序运行结果
将程序通过gcc编译构建,其中不使用任何优化。将产生的二进制文件运行,可得到如下结果:

从中可以发现,寄存器变量rvar的值未受后面赋值的影响,仍为旧值222,与期望值不同,但是普通int型和volatile型值均正确。说明经过长跳转,寄存器变量在跳转之中重新赋值容易产生丢失的问题。
汇编角度观察
下图发现,在赋值的时候,rvar是直接放到了ESI寄存器中,而未覆盖掉之前内存中保存的222值,也就是888赋值到了寄存器,而内存中应该还为222,其余的777,999均进入内存中。
并且进入下个自定function函数时,三个变量均放入了寄存器中。进行传值。
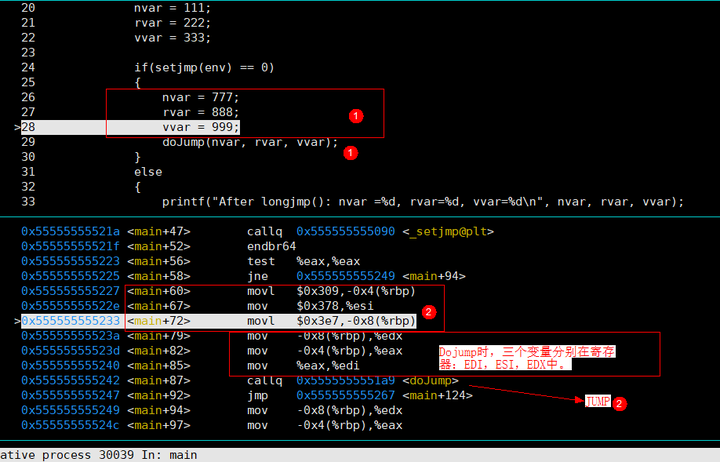
下图可以看出来,就是jump回来时,rvar的真实值(寄存器中的值888)已经丢失,寄存器的值被jump buffer缓存中值所冲掉,后面在打印变量值时,从内存中读取到旧的值。
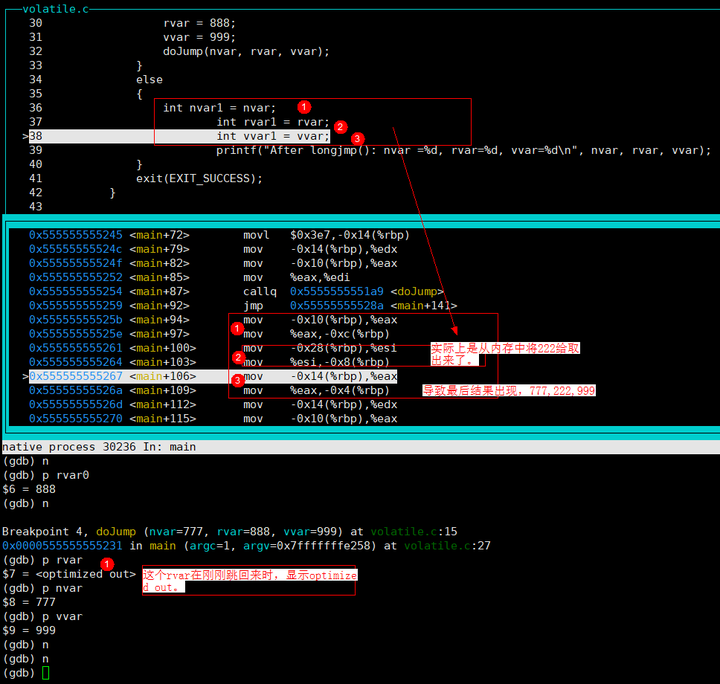
内存角度观察


上图是赋值完777,888,999,此时发现,这个888赋值给了寄存器(从汇编中可以看出),这里发现222未被覆盖。
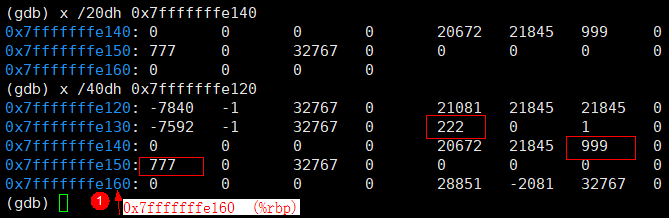
最后通过jump返回,读取值,这时候读取是从内存中读取出来,发现读出了777,222,999,程序发生了意外情况。其中下图展示了内存地址中的值,222在-0x28 + 0x7fffffffe160地址位。
实例优化O2,release版本
程序运行结果
编译中加入O2编译器优化,并运行程序。此时结果发现,nvar和rvar的值均发生了变化,并未存入我们预想中的777和888,而是old值未被改变。
因为存在编译器的优化问题,变量nvar和rvar在跳转中,其改写值放入了寄存器中,jump之后,寄存器的值被冲刷,到致出现此类问题。而变量vvar的值放入了内存中,jump之后,仍可以通过寄存器指针调取。

下面就对程序运行过程进行检查和对结果进行分析。
汇编角度观察
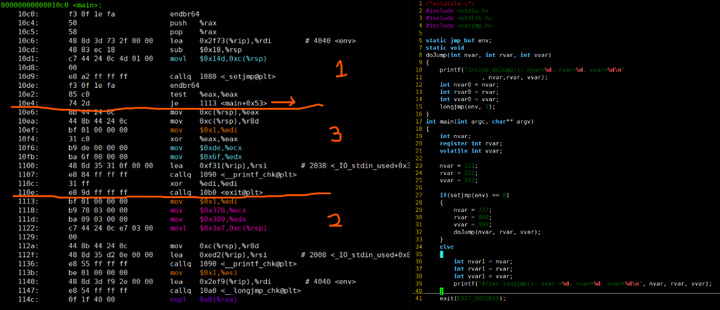
通过objdump -d volatile_og可以查看编译后文件的反汇编代码。我们主要观察main函数,其从10c0开始,上图根据判断env是否等于0为界限,分为了3块,方便理解阅读。
发现汇编中不存在对函数Dojump的调用(callq指令后未出现Dojump),猜测是由于编译器优化为内联函数。同时此函数中变量nvar0,rvar0,vvar0的初始化为死代码块,在优化过程中也进行了移除。
下图可以说明,仅有使用关键字volatile的vvar其值再栈内存中可以找到,其余的变量均不为lvalue。
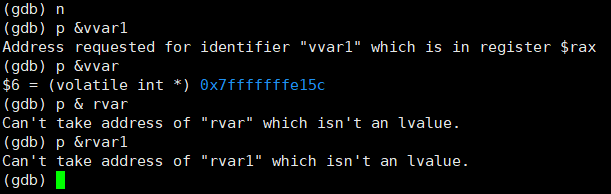
内存角度观察
可以通过查看jump前后的内存中的值,进行查看到底在jump中发生了什么:
下图一为在jump之前,寄存器中的值,只有333进入到内存中了。亦可以通过图二方式查询,发现rvar和nvar并非可以通过内存地址访问到。

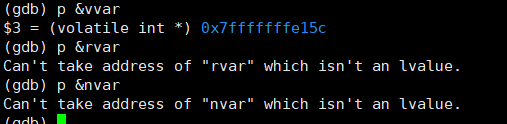
在jump之后,内存e15c中的值改为999。
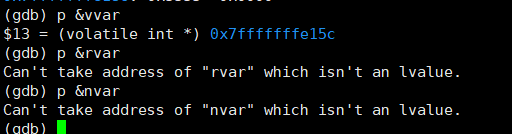
Jump之后,栈内存的空间如下图所示:

下图中,此时只有vvar可以取地址操作。
附录
参考资料
- 什么是内存屏障? Why Memory Barriers ?
- why-do-we-use-volatile-keyword
- intro.races-13
- Linux 汇编语言开发指南 Intel 格式--AT&T 格式
- setjmp()与longjmp()详细分析
- 利用C语言中的Setjmp和Longjmp,来实现异常捕获和协程
- Exactly what “program state” does setjmp save?
可能涉及到的具体优化参数
- l -fforce-mem:在做算术操作前,强制将内存数据copy到寄存器中以后再执行。这会使所有的内存引用潜在的共同表达式,进而产出更高效的代码,当没有共同的子表达式时,指令合并将排出个别的寄存器载入。这种优化对于只涉及单一指令的变量, 这样也许不会有很大的优化效果. 但是对于再很多指令(必须数学操作)中都涉及到的变量来说, 这会时很显著的优化, 因为和访问内存中的值相比 ,处理器访问寄存器中的值要快的多。
- l -fregmove:编译器试图重新分配move指令或者其他类似操作数等简单指令的寄存器数目,以便最大化的捆绑寄存器的数目。这种优化尤其对双操作数指令的机器帮助较大。
- l -fschedule-insns:编译器尝试重新排列指令,用以消除由于等待未准备好的数据而产生的延迟。这种优化将对慢浮点运算的机器以及需要load memory的指令的执行有所帮助,因为此时允许其他指令执行,直到load memory的指令完成,或浮点运算的指令再次需要cpu。其允许数据处理时先完成其他的指令。
总结:
-fforce-mem有可能导致内存与寄存器之间的数据产生类似脏数据的不一致等。对于某些依赖内存操作顺序而进行的逻辑,需要做严格的处理后才能进行优化。例如,采用volatile关键字限制变量的操作方式,或者利用barrier迫使cpu严格按照指令序执行的。
内存屏障 Memory Barriers
Cache 一致性问题的根源是因为存在多个处理器独占的 Cache,而不是多个处理器。它的限制条件比较多:多核,独占 Cache,Cache 写策略。
当其中任一个条件不满足时便不存在cache一致性问题。
针对CPU的多级Cache和存储读写一致性 :
CPU中为提高指令执行,增加了两个缓冲区 store buffer, invalidate queue。
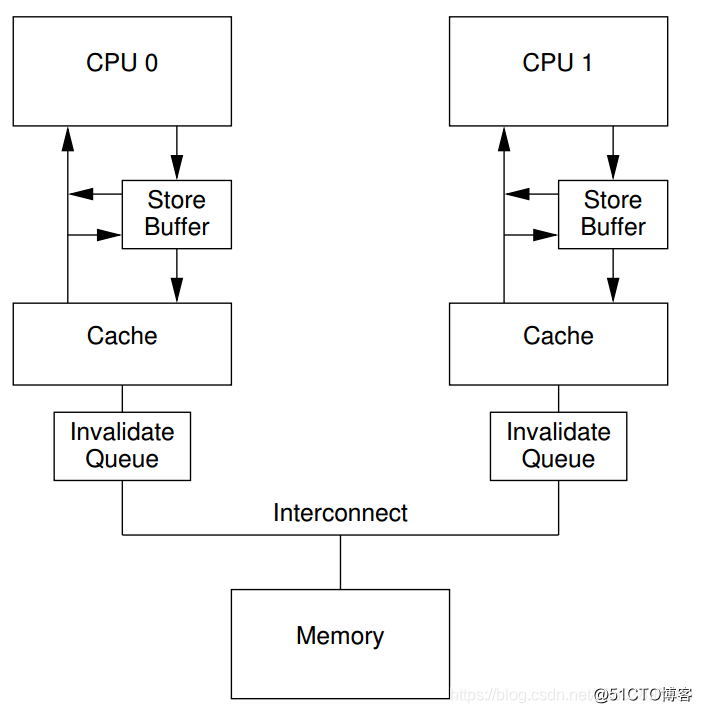
Store Buffer:
好处:store是为了CPU0和1之间读写,不需要等待从另外一个CPU的Cache中调取数据。(提高速度)。
坏处(问题描述):CPU0修改值,但是其发送的“读使无效”晚于CPU1真正读的时间,导致晚了一步,数据错了。
冲突问题的解决:
- 硬件上:store forwarding。如果本地Store Buffer有数据,直接先读本队Store Buffer。
- 软件上:硬件设计者提供了memory barrier指令,让软件来告诉CPU这类关系。
失效队列:
store buffer一般很小,所以CPU执行几个store操作就会填满, 这时候CPU必须等待invalidation ACK消息(得到invalidation ACK消息后会将storebuffer中的数据存储到cache中,然后将其从store buffer中移除),来释放store buffer缓冲区空间。
好处:CPU1可能在重负荷下,执行大量失效命令会有更重的复合。提高了速度;
坏处(问题描述):可能本身值已无效,但是队列未执行到。(又是晚了)。
解决:仍然是加屏障可以解决。
标签:数仓,vvar,int,nvar,跳转,rvar,复现,寄存器,内存 来源: https://www.cnblogs.com/huaweiyun/p/15954108.html