kali和web
作者:互联网
burpsuite 在kali的安装与使用
免费的burpsuite真不好用,所以。。。
0x01 先把免费的burpsuite删了(不删也行随你)
sudo apt remove burpsuite
0x02 准备好新版本的burpsuite和jdk
Burp_Suite_Pro_v1.7.37_Loader_Keygen 下载连接:https://wwa.lanzous.com/iJmSJkavl2j
jdk-8u261-linux-x64.tar 下载连接:https://www.oracle.com/java/technologies/javase/javase8u211-later-archive-downloads.html

官网下载jdk需要一个账号,可以在网上搜,有很多好心人分享了

下好了,放桌面
0x03 解压安装
1.先安装jdk1.8
解压出来移动到/opt目录下
tar -xzvf jdk-8u261-linux-x64.tar.gz sudo mv jdk1.8.0_261 /opt cd /opt/jdk1.8.0_261

执行 mousepad ~/.bashrc 并在其末端添加以下内容,然后保存退出:
#install JAVA JDK
export JAVA_HOME=/opt/jdk1.8.0_261
export CLASSPATH=.:${JAVA_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH

source ~/.bashrc
安装


sudo update-alternatives --install /usr/bin/java java /opt/jdk1.8.0_261/bin/java 1 sudo update-alternatives --install /usr/bin/javac javac /opt/jdk1.8.0_261/bin/javac 1 sudo update-alternatives --set java /opt/jdk1.8.0_261/bin/java sudo update-alternatives --set javac /opt/jdk1.8.0_261/bin/javac

然后看看java版本对不对
java -version
2.安装burpsuite
先解压
unzip Burp_Suite_Pro_v1.7.37_Loader_Keygen.zip

打开Burp解压包把两个.jar文件剪切到/usr/bin目录里,然后Java -jar 启动burp激活软件
sudo mv burp-loader-keygen.jar burpsuite_pro_v1.7.37.jar /usr/bin
cd /usr/bin
java -jar burp-loader-keygen.jar
点击run






ok 先退出

把注册机也关了
0x04 配置快捷方式:在/usr/bin下创建burpsuite(如果有先删除再创建)
sudo mousepad burpsuite
添加以下内容
#!/bin/sh java -Xbootclasspath/p:/usr/bin/burp-loader-keygen.jar -jar /usr/bin/burpsuite_pro_v1.7.37.jar

增加执行权限chmod +x burpsuite 进入/usr/share/applications,创建并编辑burpsuite的快捷方式
sudo chmod +x burpsuite cd /usr/share/applications/ sudo mousepad burpsuite.desktop

[Desktop Entry] Name=burpsuite Encoding=UTF-8 Exec=sh -c "/usr/bin/burpsuite" Icon=kali-burpsuite StartupNotify=false Terminal=false Type=Application Categories=03-webapp-analysisc;03-06-web-application-proxies; X-Kali-Package=burpsuite
然后去菜单看看,点击打开


ok
hattack
打开Kali之后,我们需要用到工具httrack。由于Kali本身不自带该工具,所以我们需要安装它,下面我一步一步来操作!
一、打开Kali,安装httrack
首先我们更新一下列表:
apt-get update
安装httrack:
apt-get install httrack
完成安装!
二、开始使用httrack爬取信息
首先我们可以创建一个目录用于存放爬取的信息。

接着我就拿我的个人网站来爬取一下信息:
httrack URL
上图显示正在爬取,将网站信息保存到本地。
完成之后,就如下图所示:

接着我们查看一下爬取的信息:

因为我个人网站没有动态页面,所以不会产生cookies.txt文件,等一下我将列出爬取的信息都包含什么。
我们先来看一下http://orgloft.com目录,这里存放的是网站源码、图片等信息。


要注意的是,蓝色字体的都是目录,即这些目录下包含的有文件,白色字体的是文件,可以直接使用vim打开。
我们打开一个源码文件看一下:

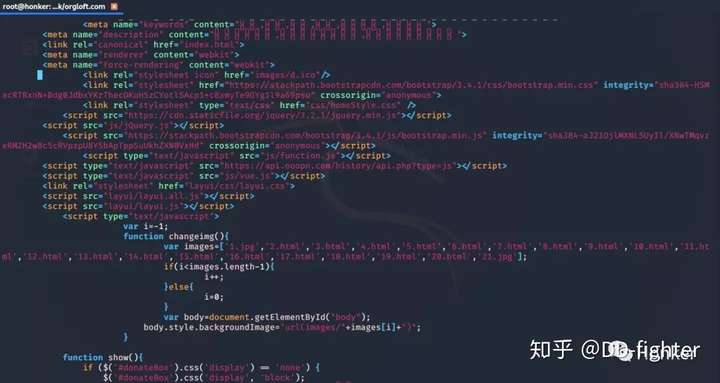
满满的源码展示在你眼前!
使用httrack爬取网站,我们能得到以下信息:
- 网页源码
- 网站所有图片
- 所有下载文件
- cookies.txt文件,包含用于下载站点的cookie信息
- hts-cache目录包含由爬虫检测到的文件列表,这是httrack所处理的文件列表
- hts-log.txt文件包含错误、警告和其他在爬取站点时的信息
除此之外,httrack还有许多其它选项可以使用,让我们自定义它的行为来完成我们的需求:
- -rN : 将爬取的链接深度设置为N
- -%eN: 设置外部链接的深度界限
- -F[user-agent]: 用于下载站点的UA即浏览器标识符
三、除httrack之外的wget
我们已经知道,httrack可以爬取网站的信息。httrack直接将网站的所有内容都可以爬取到本地,但是我们只需要部分信息的时候呢?该怎么办?
这时候就需要wget,wget是kali自带的一种工具,所以你无需安装,直接打开终端使用即可。
下面还是以我个人网站为事例:
wget http://orgloft.com/看这种情况和刚才的httrack有什么不同之处。

仔细看,在url最后我加了 / ,这是一个很重要的符号,有了 / ,就代表只需要爬取当前的页面信息,而不是全站点信息!

这时候你很容易发现跟刚才的httrack有着很大的区别,这时候就只爬取了主页面一个文件 index.html。
依据此原理,你可以转到其他页面后面加一个 / 。这时就只爬取该一页内容。如果没有 / ,那么爬取的将是所有内容。
注意:在使用wget时,它会自动将爬取的内容存放在当前目录下。当然,你也可以指定目录
wget -P 目录/ URL这里参数 -P 就代表着允许设置目录并且文件存放在该目录里。
wget的另外一些参数:
- -r : 该参数是将站点所有信息遍历爬取到本地。
- -l : 在该参数后面我们可以加上遍历深度值,以便让其爬取有个界限
- -k : 该参数能够指向本地文件,将你爬取的站点信息在本地浏览
- -p : 爬取该站点所有图像
原文链接:比Python更狠毒的一种爬虫! - 知乎 (zhihu.com)
我在下载的时候发现无法连接源站,正在考虑怎么办
补充:我最终发现 -y 是需要放在apt 之后的,有些命令的-y 由于放在全部命令之后导致无法连接源站下载
httrack的基础使用
作用:减少与目标系统的交互(镜像复制网站)从而减少被发现的可能。
具体流程:
打开httrack
输入本次工程的名字
输入本次工程文件的储存位置
侦查的链接或IP
查找选项(一般情况下,采用1或者2模式)
httrack可以选择查找特殊文件类型
另外还可以选择其它选项,具体选项直接查找帮助文件
【注意】本工具支持代理。
burp 的爬虫

火狐设置中文
!!!!
网上很多教程不够用,会连接不到源站
可以发现一些问题
kali中的Firefox浏览器默认为英文,为了方便还是改为中文。
1、打开终端,输入 apt -y install firefox-esr-l10n-zh-cn ,回车 (下载安装语言包)

打开火狐浏览器
安装谷歌输入法

firefox添加代理

dirbuster:扫描工具(还有个namp不知高下)
目录扫描工具DirBuster支持全部的Web目录扫描方式。它既支持网页爬虫方式扫描,也支持基于字典暴力扫描,还支持纯暴力扫描。该工具使用Java语言编写,提供命令行(Headless)和图形界面(GUI)两种模式。其中,图形界面模式功能更为强大。用户不仅可以指定纯暴力扫描的字符规则,还可以设置以URL模糊方式构建网页路径。同时,用户还对网页解析方式进行各种定制,提高网址解析效率。

具体看这个
Kali—Dirbuster工具用法 - 简书 (jianshu.com)
kali sublist3r子域名收集
sublist3r 是类似扫后台的东西,基本直接等于dirsearch,功能可能少一些
简写 长表 描述
-d - 域 用于枚举子域的域名
-b --bruteforce 启用subbrute bruteforce模块
-p --ports 根据特定的TCP端口扫描找到的子域
-v --verbose 启用详细模式并实时显示结果
-t --threads subbrute bruteforce使用的线程数
-e - 引擎 指定以逗号分隔的搜索引擎列表
-o --output 将结果保存到文本文件
-H - 帮助信息 显示帮助消息并退出
用法:sublist3r [-h] -d DOMAIN [-b [BRUTEFORCE]] [-p PORTS] [-v [VERBOSE]] [-t THREADS] [-e ENGINES] [ - o OUTPUT]

具体下载和使用:https://blog.csdn.net/zsw15841822890/article/details/107556319
kali'菜刀——
Weevely
由于相应的操作太难,也很少去用菜刀,先留个底,之后再搞
(55条消息) Weevely(Linux中的菜刀)_WHOAMIAnony的博客-CSDN博客_weevely
标签:bin,web,kali,sudo,httrack,爬取,burpsuite,usr 来源: https://www.cnblogs.com/nishihundun/p/15930060.html