深入理解JVM(十一)—— 类加载与字节码技术(五)
作者:互联网
深入理解JVM(十一)—— 类加载与字节码技术(五)
文章目录
6、运行期优化
分层编译
JVM 将执行状态分成了 5 个层次:
- 0层:解释执行,用解释器将字节码翻译为机器码
- 1层:使用 C1 即时编译器编译执行(不带 profiling)
- 2层:使用 C1 即时编译器编译执行(带基本的profiling)
- 3层:使用 C1 即时编译器编译执行(带完全的profiling)
- 4层:使用 C2 即时编译器编译执行
profiling 是指在运行过程中收集一些程序执行状态的数据,例如【方法的调用次数】,【循环的 回边次数】等
即时编译器(JIT)与解释器的区别
- 解释器
- 将字节码解释为机器码,下次即使遇到相同的字节码,仍会执行重复的解释
- 是将字节码解释为针对所有平台都通用的机器码
- 即时编译器
- 将一些字节码编译为机器码,并存入 Code Cache,下次遇到相同的代码,直接执行,无需再编译
- 根据平台类型,生成平台特定的机器码
对于大部分的不常用的代码,我们无需耗费时间将其编译成机器码,而是采取解释执行的方式运行;另一方面,对于仅占据小部分的热点代码,我们则可以将其编译成机器码,以达到理想的运行速度。 执行效率上简单比较一下 Interpreter < C1 < C2,总的目标是发现热点代码(hotspot名称的由 来),并优化这些热点代码
逃逸分析
逃逸分析(Escape Analysis)简单来讲就是,Java Hotspot 虚拟机可以分析新创建对象的使用范围,并决定是否在 Java 堆上分配内存的一项技术
逃逸分析的 JVM 参数如下:
- 开启逃逸分析:-XX:+DoEscapeAnalysis
- 关闭逃逸分析:-XX:-DoEscapeAnalysis
- 显示分析结果:-XX:+PrintEscapeAnalysis
逃逸分析技术在 Java SE 6u23+ 开始支持,并默认设置为启用状态,可以不用额外加这个参数
对象逃逸状态
全局逃逸(GlobalEscape)
- 即一个对象的作用范围逃出了当前方法或者当前线程,有以下几种场景:
- 对象是一个静态变量
- 对象是一个已经发生逃逸的对象
- 对象作为当前方法的返回值
参数逃逸(ArgEscape)
- 即一个对象被作为方法参数传递或者被参数引用,但在调用过程中不会发生全局逃逸,这个状态是通过被调方法的字节码确定的
没有逃逸
- 即方法中的对象没有发生逃逸
逃逸分析优化
针对上面第三点,当一个对象没有逃逸时,可以得到以下几个虚拟机的优化
锁消除
我们知道线程同步锁是非常牺牲性能的,当编译器确定当前对象只有当前线程使用,那么就会移除该对象的同步锁
例如,StringBuffer 和 Vector 都是用 synchronized 修饰线程安全的,但大部分情况下,它们都只是在当前线程中用到,这样编译器就会优化移除掉这些锁操作
锁消除的 JVM 参数如下:
- 开启锁消除:-XX:+EliminateLocks
- 关闭锁消除:-XX:-EliminateLocks
锁消除在 JDK8 中都是默认开启的,并且锁消除都要建立在逃逸分析的基础上
标量替换
首先要明白标量和聚合量,基础类型和对象的引用可以理解为标量,它们不能被进一步分解。而能被进一步分解的量就是聚合量,比如:对象
对象是聚合量,它又可以被进一步分解成标量,将其成员变量分解为分散的变量,这就叫做标量替换。
这样,如果一个对象没有发生逃逸,那压根就不用创建它,只会在栈或者寄存器上创建它用到的成员标量,节省了内存空间,也提升了应用程序性能
标量替换的 JVM 参数如下:
- 开启标量替换:-XX:+EliminateAllocations
- 关闭标量替换:-XX:-EliminateAllocations
- 显示标量替换详情:-XX:+PrintEliminateAllocations
标量替换同样在 JDK8 中都是默认开启的,并且都要建立在逃逸分析的基础上
栈上分配
当对象没有发生逃逸时,该对象就可以通过标量替换分解成成员标量分配在栈内存中,和方法的生命周期一致,随着栈帧出栈时销毁,减少了 GC 压力,提高了应用程序性能
方法内联
内联函数
内联函数就是在程序编译时,编译器将程序中出现的内联函数的调用表达式用内联函数的函数体来直接进行替换
JVM内联函数
C++是否为内联函数由自己决定,Java由编译器决定。Java不支持直接声明为内联函数的,如果想让他内联,你只能够向编译器提出请求: 关键字final修饰 用来指明那个函数是希望被JVM内联的,如
public final void doSomething() {
// to do something
}
总的来说,一般的函数都不会被当做内联函数,只有声明了final后,编译器才会考虑是不是要把你的函数变成内联函数
JVM内建有许多运行时优化。首先短方法更利于JVM推断。流程更明显,作用域更短,副作用也更明显。如果是长方法JVM可能直接就跪了。
第二个原因则更重要:方法内联
如果JVM监测到一些小方法被频繁的执行,它会把方法的调用替换成方法体本身,如:
private int add4(int x1, int x2, int x3, int x4) {
//这里调用了add2方法
return add2(x1, x2) + add2(x3, x4);
}
private int add2(int x1, int x2) {
return x1 + x2;
}
方法调用被替换后
private int add4(int x1, int x2, int x3, int x4) {
//被替换为了方法本身
return x1 + x2 + x3 + x4;
}
反射优化
public class Reflect1 {
public static void foo() {
System.out.println("foo...");
}
public static void main(String[] args) throws NoSuchMethodException, InvocationTargetException, IllegalAccessException {
Method foo = Demo3.class.getMethod("foo");
for(int i = 0; i<=16; i++) {
foo.invoke(null);
}
}
}
foo.invoke 前面 0 ~ 15 次调用使用的是 MethodAccessor 的 NativeMethodAccessorImpl 实现
invoke方法源码
@CallerSensitive
public Object invoke(Object obj, Object... args)
throws IllegalAccessException, IllegalArgumentException,
InvocationTargetException
{
if (!override) {
if (!Reflection.quickCheckMemberAccess(clazz, modifiers)) {
Class<?> caller = Reflection.getCallerClass();
checkAccess(caller, clazz, obj, modifiers);
}
}
//MethodAccessor是一个接口,有3个实现类,其中有一个是抽象类
MethodAccessor ma = methodAccessor; // read volatile
if (ma == null) {
ma = acquireMethodAccessor();
}
return ma.invoke(obj, args);
}
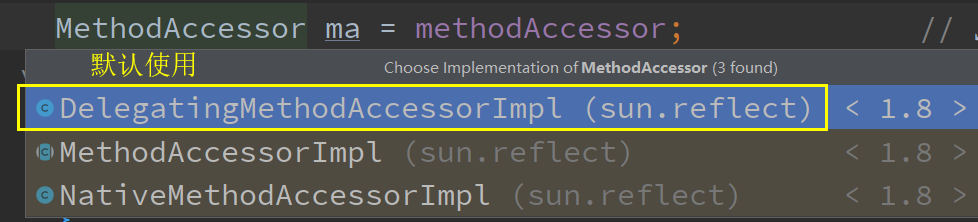
会由DelegatingMehodAccessorImpl去调用NativeMethodAccessorImpl
NativeMethodAccessorImpl源码
class NativeMethodAccessorImpl extends MethodAccessorImpl {
private final Method method;
private DelegatingMethodAccessorImpl parent;
private int numInvocations;
NativeMethodAccessorImpl(Method var1) {
this.method = var1;
}
//每次进行反射调用,会让numInvocation与ReflectionFactory.inflationThreshold的值(15)进行比较,并使使得numInvocation的值加一
//如果numInvocation>ReflectionFactory.inflationThreshold,则会调用本地方法invoke0方法
public Object invoke(Object var1, Object[] var2) throws IllegalArgumentException, InvocationTargetException {
if (++this.numInvocations > ReflectionFactory.inflationThreshold() && !ReflectUtil.isVMAnonymousClass(this.method.getDeclaringClass())) {
MethodAccessorImpl var3 = (MethodAccessorImpl)(new MethodAccessorGenerator()).generateMethod(this.method.getDeclaringClass(), this.method.getName(), this.method.getParameterTypes(), this.method.getReturnType(), this.method.getExceptionTypes(), this.method.getModifiers());
this.parent.setDelegate(var3);
}
return invoke0(this.method, var1, var2);
}
void setParent(DelegatingMethodAccessorImpl var1) {
this.parent = var1;
}
private static native Object invoke0(Method var0, Object var1, Object[] var2);
}
//ReflectionFactory.inflationThreshold()方法的返回值
private static int inflationThreshold = 15;
- 一开始if条件不满足,就会调用本地方法invoke0
- 随着numInvocation的增大,当它大于ReflectionFactory.inflationThreshold的值16时,就会本地方法访问器替换为一个运行时动态生成的访问器,来提高效率
- 这时会从反射调用变为正常调用,即直接调用 Reflect1.foo()

标签:字节,int,编译器,逃逸,JVM,标量,内联,加载 来源: https://blog.csdn.net/lizefeng1998/article/details/123034906