数据预处理ETL
作者:互联网
数据预处理ETL
数据的质量直接决定数据分析结果的好坏,真实的数据可能由于记录失败、数据损坏等原因产生缺失值,或由于噪声、人工录入错误产生的异常点。这会使得后续的数据分析非常困难,分析结果不可靠;数据预处理的目的就是改善数据质量,提升分析可靠性。
数据预处理的主要过程有数据抽取(Extraction)、数据转换(Transformation)和数据加载(Loading),也称为ETL
其主要步骤包括以下几个部分
1. 数据清洗
通过缺失值处理、光滑噪声数据,平滑或删除离群点,并解决数据的不一致性来“清洗”数据。
1.1 缺失值处理
一般用?,null 空格表示
1.1.1 单变量填充方法
-
删除变量
变量缺失率较高,可直接将变量删除
该方法以损失信息为代价,因此不能对重要的变量使用
-
默认值填充
-
统计量填充
缺失率较低,可根据数据分布填充
-
数据均匀或者符合正态分布,可使用均值填充
-
数据分布存在倾斜,应使用中位数填充

-
-
众数填充
对于字符串、整数等离散变量,应采用众数

-
哑变量填充
变量为离散型,且不同值较少,可转换成哑变量
例如sex变量,存在male,famale,NA三个值,可将该列转换成is_male,is_female,is_na三列
若某个变量存在大量不同的值,可根据每个值的频数,将频数较小的值合并为一类
other,在降低维度的同时尽可能保留变量的信息
1.1.2 多变量填充方法
-
插值法填充
随机差值,多重差补法,热卡填充,拉格朗日差值,牛顿差值等
-
模型填充
最近邻,逻辑回归,随机森林对缺失值进行预测
1.1.3 缺失值处理方法汇总

1.2 异常值处理
3∂原则
正态分布函数公式如下:
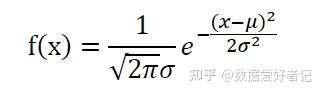
σ代表标准差,μ代表均值
样本数据服从正态分布的情况下:
数值分布在(μ-σ,μ+σ)中的概率为0.6826
数值分布在(μ-2σ,μ+2σ)中的概率为0.9544
数值分布在(μ-3σ,μ+3σ)中的概率为0.9974
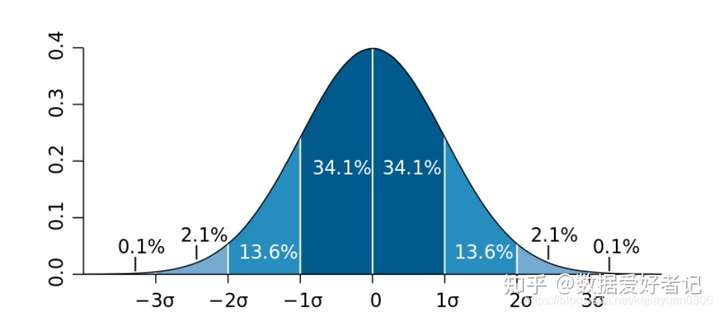
如果数据服从正态分布,在3σ原则下,异常值被定义为一组测定值中与平均值的偏差超过三倍标准差的值。在正态分布下,距离平均值3σ之外的值出现的概率为 P(|x-μ|>3σ)<=0.003,属于极个别的小概率^事件。
Z-score
用远离平均值的多少倍标准差来描述,公式为

如果统计数据量足够多,Z-score数据分布满足,68%的数据分布在“-1”与“1”之间,95%的数据分布在“-2”与“2”之间,99%的数据分布在“-3”与“3之间”
-
通常把远离标准差3倍距离以上的数据点视为离群点,也就是说,把Z-score大于3的数据点视作离群点
-
另外Z-score也是一种标准化方法
-
计算方法
import pandas as pd import numpy as np import scipy.stats as stats data = np.array([4,5,6,6,6,7,8,12,13,13,14,1008]) stats.zscore(data)array([-0.31794266, -0.31432282, -0.31070298, -0.31070298, -0.31070298,
-0.30708314, -0.30346329, -0.28898393, -0.28536409, -0.28536409,
-0.28174425, 3.3163772 ])可以看到最后一个值1008对应的z-score为
3.3163772,因此该值为异常值
箱线图 --- IQR方法
箱线图是一种基于五个统计数字(“minimum”, first quartile (Q1), median, third quartile (Q3), and “maximum”)来展示数据分布非标准化方法
计算Q1,Q2,Q3分位数的方法有很多种,这里展示的是"np"方法
(1)确定四分位数的位置。Qi所在位置np=(i*n)/4,其中i=1,2,3。n表示序列中包含的项数。
(2)如果np不为整数,Qi=X[np+1]
(3)如果np为整数,Qi=(X[np]+X[np+1])/2
-
Q2: 中位数
-
Q1: 下四分位数
-
Q3: 上四分位数
-
IQR:interquartile range(四分位距)指的是在第75个百分点Q3与第25个百分点Q1的差值,或者说,上、下四分位数之间的差$ IQR = Q3 − Q1 $
-
“maximum”: Q3 + 1.5*IQR
-
“minimum”:Q1 -1.5*IQR
IQR是统计分散程度的一个度量,分散程度通过需要借助箱线图来观察,通常把小于 Q1 - 1.5 * IQR 或者大于 Q3 + 1.5 * IQR的数据点视作离群点,探测离群点的公式是:
outliers = value < ( Q1 - 1.5 * IQR ) or value > ( Q3 + 1.5 * IQR )

可以看到,“最大”和“最小”值之间的范围覆盖了$ 2.698\sigma $, 涵盖了99.3%的数据,异常值的出现的概率仅为0.7%,因此可通过该方式计算离群点
2. 数据集成
将多个数据源中的数据结合起来进行统一存储,如建立数据仓库。
3. 数据变换
包括对数据进行标准化、离散化、稀疏化处理,达到适用于挖掘的目的;
3.1 标准化
数据中不同特征的量纲可能不一致导致数值间的值域差别大,不进行处理可能会影响到数据分析的结果
3.1.1 原因
- 值域跨度小的变量需要更大的模型权重,基于梯度下降求解的算法(如逻辑回归、神经网络等)需要更长的训练时间;
- 线性模型中,量纲不一致使得其权重的相对大小无法直接比较,导致可解释性降低;
- 涉及距离计算的算法如最近邻,支持向量机等会被值域跨度大的变量主导,导致对其他变量的利用不充分;
因此,需要对值域差别大的各变量按照一定比例进行缩放,使他们拥有大致相等的值域,以便于下游分析。

3.1.2 方法
-
最大-最小规范化
公式为
$$
x_{new}=\frac{x-x_{min}}{x_{max}-x_{min}}
$$
最大最小值异常会导致不恰当的缩放比例 -
Z-score标准化
标准化后各特征值域不相同,但是对异常值更鲁棒

3.2 离散化
数据离散化是指将连续的数据进行分段,使其变为一段段离散化的区间
3.2.1 原因
-
模型要求:C4.5、朴素贝叶斯、Apriori等模型要求离散输入;
-
缓解异常值:异常值经过离散化会落在固定区间,消除了幅度的影响,使模型对其更加鲁棒。
-
提升精度:离散化可以引入非线性,增强预测力;同时可以避免模型对数值变量的过拟合;离散化也能使数值特征参与特征交叉;
例如年龄的数字化表示离散为中年,青年,老年,幼年,性别为男女,那么就可以进行交叉,中年男子,老年女子
【拓展】:特征交叉的意义:组合两个(或更多个)特征是使用线性模型来学习非线性关系的一种聪明做法。
3.2.2 方法
-
等宽法
每个箱的宽度相等
如下图所示,红色曲线为原数据分布的概率直方图,蓝色虚线表示分箱的边界。一对相邻的蓝色虚线表示一个箱,所有属于该范围内的变量都会离散化为相同的数值;

-
等频法
每个箱中曲线下面积相等

-
聚类法
箱的范围由聚类算法运行结果决定

3.3 数据变换总结

4. 数据规约
数据归约技术可以用来得到数据集的归约表示,它的规模小得多,但仍可以近似地保持原数据的完整性;在归约后的数据集上挖掘将更有效,并产生相同(或几乎相同)的分析结果。
参考文章
- 数据分析基础 | 微课 | Huawei iLearning
- 数据清洗之异常值处理的常用方法 - 知乎 (zhihu.com)
- How to Calculate Z-Scores in Python - Statology
- 【统计】Z-score - 望着小月亮 - 博客园 (cnblogs.com)
- Understanding Boxplots
标签:变量,填充,IQR,离散,np,数据,预处理,ETL 来源: https://www.cnblogs.com/zlbingo/p/15899823.html