独立小样本两个总体均值差的估计
作者:互联网
独立小样本两个总体均值只差的估计
小样本:或
条件:总体服从正态分布,随机样本是从两个总体独立选取的。
如果: 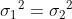

自由度=
:总体1 -方差,
:总体2 -方差
:样本1 -均值,
:样本2 -均值
:样本1 -样本数量,
:样本2 -样本数量
:样本1 -样本方差,
:样本2 -样本方差
:t分布值,若取95%置信区间,则
为0.05.
沥青含量3% 和 7%混凝土水渗透性测量数据
3%含量 7%含量 1189 853 840 900 1020 733 980 785
方差既可以使用numpy函数,也可以使用pandas函数。
numpy 中计算的方差就是样本方差本身:
使用场景为:拥有所有数据的情况下,计算所有数据的标准差时使用,即最终除以n,而非n-1
pandas 中计算的方差为无偏样本方差:使用场景为:只有部分数据但需要求得总体的标准差时使用,当只有部分数据时,根据统计规律,除以n时计算的标准差往往偏小,因此需要除以n-1,即n-ddof。
由于是用于样本数据,所以采用pandas的方差函数。
import numpy as np
from scipy.stats import t
import pandas as pd
y1 = [1189, 840, 1020, 980] # 抽样1数据
y2 = [853, 900, 733, 785] # 抽样2数据
# 方差
arr1 = pd.Series(y1) # 样本1 生成Series
arr2 = pd.Series(y2) # 样本2 生成Series
arr_var1=arr1.var() # 取得样本1 方差 20636.91
arr_var2=arr2.var() # 取得样本2 方差 5420.916计算
- 样本均值:
=arr_mean1&arr_mean2,
- t分布分位点:
- 样本数量:n=n1&n2
# 均值
arr_mean1 = np.mean(y1) # 样本1 均值 1007
arr_mean2 = np.mean(y2) # 样本2 均值 817.8
# t分布值
n1 = len(y1) # 抽样2数据个数 4
n2 = len(y2) # 抽样1数据个数 4
variance = (n1 + n2 - 2) # 自由度 6
b = 0.95 # 定义置信系数95%
a = 1 - b # 定义
t_v = t(variance) # 定义一个自由度为6:(n1 + n2 - 2)的 t分布
t_value = t_v.isf(a / 2) # 取t分布单侧右分位点 ;stats.t.ppf(a,df)/左分位点;stats.t.isf(a,df)/右分位点;stats.t.interval(1-a,df)/双侧分位点计算
=sp_2
sp_2 = (((n1 - 1) * arr_var1) + ((n2 - 1) * arr_var2)) / variance
a = arr_mean1 - arr_mean2
b = t_value * ((sp_2 * ((1 / n1) + (1 / n2))) ** 0.5)
# 上区间
up = a - b
# 下区间
dn = a + b
print([up, dn])输出结果:
[-7.995624947727066, 386.99562494772704]
如果: 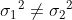
条件:总体服从正态分布,随机样本是从两个总体独立选取的。

自由度:
s1=arr_var1 #样本1 方差 20636.91
s2=arr_var2 # 样本2 方差 5420.916
v=((s1/n1+s2/n2)**2)/((((s1/n1)**2)/(n1-1))+(((s2/n2)**2)/(n2-1))) #自由度为4
v=round(v,0)
t_value2 = t.isf((a / 2),v) # 取t分布单侧右分位点
c = t_value * ( ((s1 / n1) + (s2 / n2)) ** 0.5)
# 上区间
up = a - c
# 下区间
dn = a + c
print([up, dn])[-7.995624947727066, 386.99562494772704]
标签:总体,arr,样本,方差,均值,n1,n2,位点 来源: https://blog.csdn.net/Zohn_Sun/article/details/122835360