A ConvNet for the 2020论文阅读笔记
作者:互联网
ConvNeXt
摘要
文章介绍道,视觉识别的 "Roaring 20s"始于ViT的引入,其迅速取代了卷积网络成为了最先进的图像分类模型。但最基本的ViT模型仅是被设计用来进行图像分类,难以应用于其他任务。而Swin Transformer的出现使得Transformer可以作为通用的骨干网络。然后作者介绍道,这种效果主要归功于Transformer的内在优势。因此作者对ResNet进行了现代化魔改,在取得了显著效果的同时相比于Swin Transformer而言保持了简单性与高效性。
介绍
作者首先介绍了10年开始卷积神经网络的复兴以及发展历程,之后说到卷积网络取得这样的地位并非偶然。滑动窗口使得处理高分辨率图像时变得有效,同时卷积网络有几个内置的归纳偏置,使得其非常适合应用于视觉领域。同时,在NLP领域,Transformer取代了RNN占据了主导地位。ViT的引入改变了视觉方面传统的网络架构的设计面貌。ViT没有引入关于图像的归纳偏置,仅仅是对Transformer做了最小的改动。之后,Swin Transformer的提出解决了图像高分辨率带来的问题, 其成功表明卷积的特性仍然起着很大的作用。因此,作者想要试探纯粹的C卷积网络的极限,对ResNet-50进行了改造得到了ConvNeXt全家桶,为CNN续了一波。下面这张放在首页的图表明魔改的CNN仍然是你大爷。
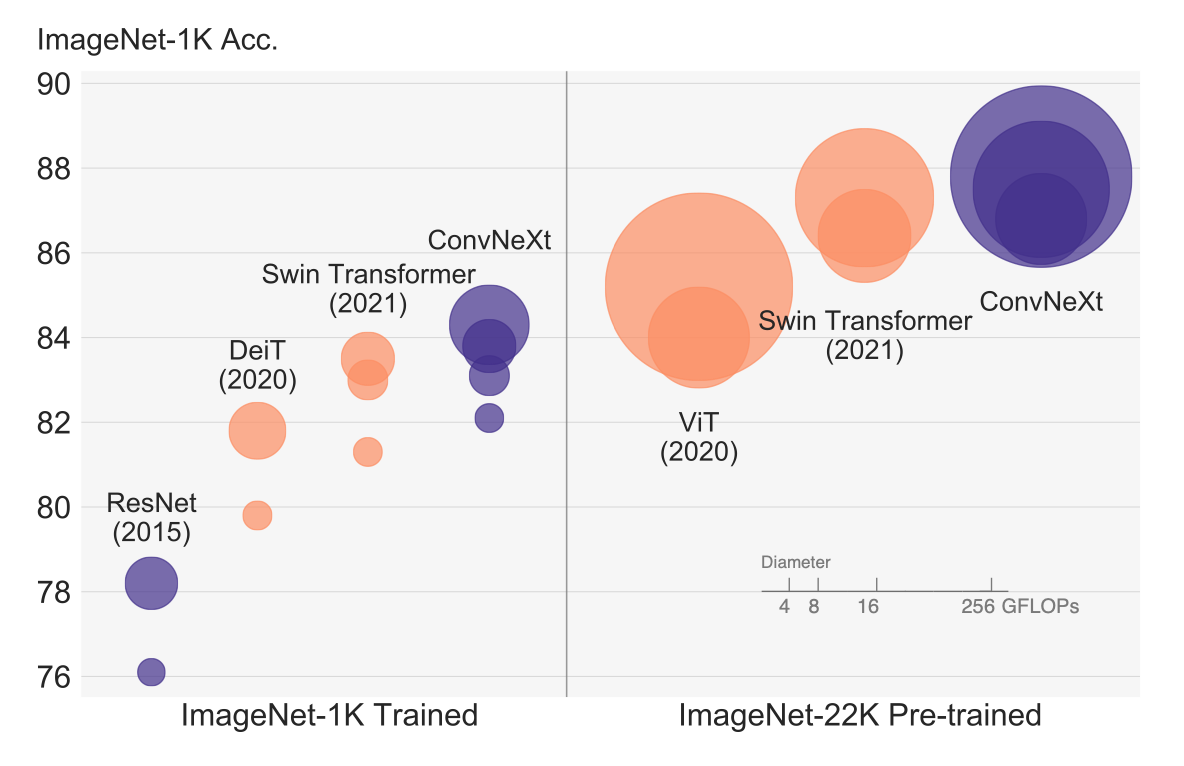
对卷积网络进行现代化改造
论文的思路是对于原始的ResNet-50进行改造,借鉴Swin Transformer的思路一步一步对模型进行改进。
下图是每一步改造对于结果的影响(在ImageNet-1K进行测试),可以看到使用了若干Transformer的trick以后ConvneXt最终的准确率已经超过了Swin Transformer
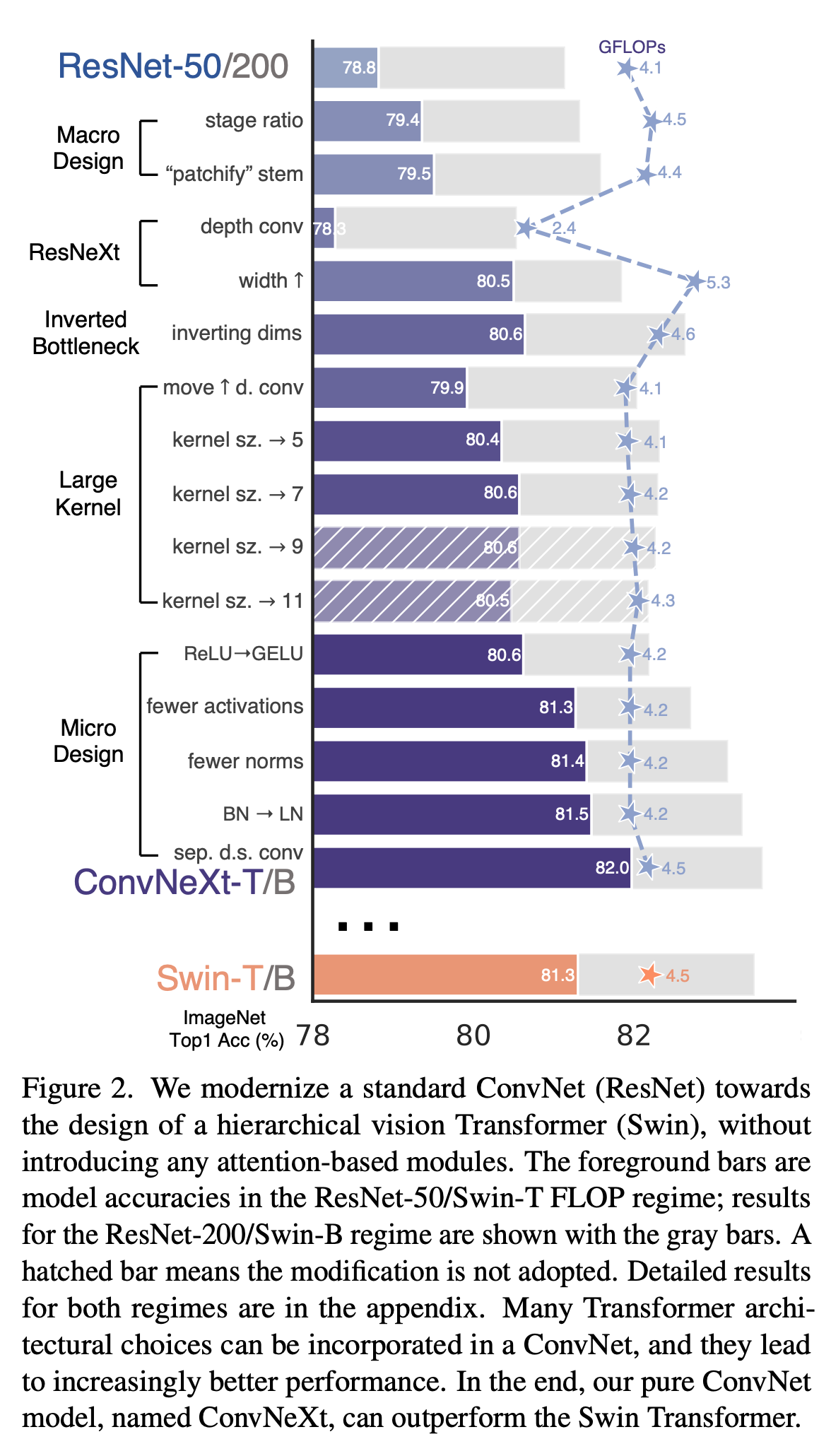
Training Techniques
作者表明训练的过程对最终的结果也有影响。因此在实验中,选择将原本的90个epoch扩展到300个epoch,且使用AdamW作为optimizer,使用如Mixup等数据增强技术以及Stochas- tic Depth等正则化方法,最终效果提升了2.7个点。
Macro Design
这一方面作者主要从两个角度入手进行分析:
1. Changing stage compute ratio.
ResNet中各阶段的计算分布的设计主要是经验性的,为了适应下游任务,conv4_x(stage 3)堆叠的次数是最多的,比例为3:4:6:3。而Swin Transformer比例为1:1:3:1(Swin-L)。因此作者将ResNet中堆叠次数改为3:3:9:3,准确率从78.8%提升到了79.4%。
2. Changing stem to “Patchify”.
由于自然图像的冗余性,需要对其进行下采样。ResNet-50的下采样模块包含一个\(7\times 7\)的stride为2的卷积层以及一个最大池化层,下采样的倍率为4。而在ViT中,下采样的卷积层的卷积核非常大,且相邻窗口之间不重叠。Swin Transformer中选择kernel_size = (4, 4), stride = 4的卷积层进行下采样,因此作者将ResNet-50的stem也换成了这个,替换后提升了0.1个点。
注:最初的下采样模块称为stem
3. ResNeXt-ify
这一部分,作者借鉴了ResNeXt这个工作的主要思想,其核心就是分组卷积,通过对通道进行分组从而减少计算量。分组卷积相关知识这篇文章写的比较好:https://zhuanlan.zhihu.com/p/65377955
在本文中,作者使用的是分组卷积的特殊情况:depthwise 卷积(深度可分离卷积),组数和通道数相同。这样做的原因作者进行了简单解释:注意到深度可分离卷积与自注意力中的加权和运算类似,后者是在每个通道的基础上操作的,即只混合空间维度的信息。这可以有效降低FLOPS,但同时也损失了精度。作者遵循ResNeXt的准则将通道数由64调整到96,与Swin Transformer保持一致。
4. Inverted Bottleneck
作者注意到Transformer中MLP块的隐层维度比输入维度宽四倍,这与MobileNetV2的inverted bottleneck类似,如下图:
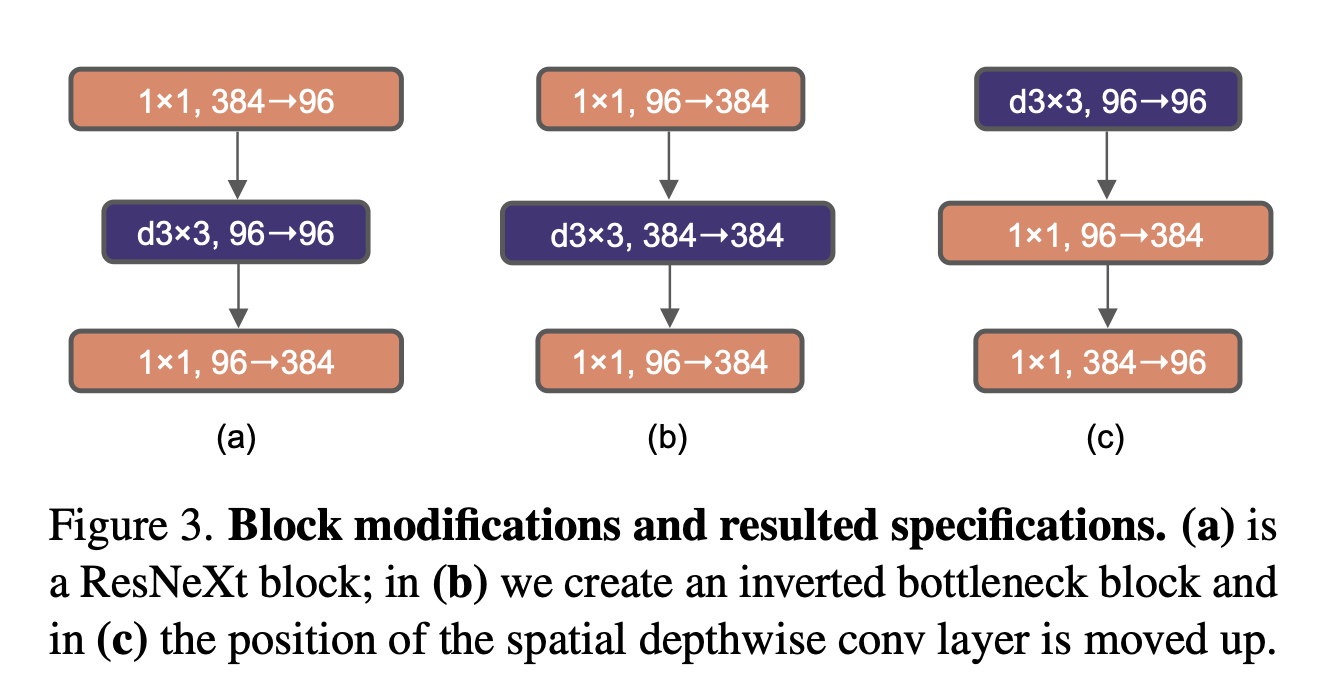
Inverted bottleneck顾名思义,和两头大中间小的bottleneck相反,是中间大两头小。
图B第三行应该是384->96?作者貌似画反了~
使用了这个模块后,在小模型上提高了0.1个点的准确率,如果换为ResNet-200 / Swin-B则能由81.9%提高到82.6%。
5. Large Kernel Sizes
ViT中最显著的特点是其全局自注意力。之前主流的卷积神经网络大都使用的是\(3\times 3\)的小窗口。VGG表明多个\(3\times 3\)的小卷积层可以替代大的卷积层从而降低参数量。虽然Swin Transformer在自注意力模块中引入了局部窗口,但窗口大小仍至少为\(7\times 7\)。因此,作者提出如下两个方面:
Moving up depthwise conv layer.
即上图C的方式,将depthwise层移动到两个\(1\times 1\)卷积层的最上方。这样处理的原因是在Transformer中多头自注意力模块是放在MLP的前面的。这样修改后FLOPs下降到4.1G,同时准确率掉到了79.9%。
**Increasing the kernel size. **
作者表示增大卷积核的好处是显著的。当将\(3\times 3\)的卷积核换成\(7\times 7\)的卷积核时,准确度从79.9%提升到80.6%,且大卷积核的优势到了\(7\times 7\)的时候就饱和了。
6. Micro Design
自此开始,作者着重研究微观上的差异(基于网络层)。
Replacing ReLU with GELU
即使用GELU(高斯误差线性单元)替换ReLU,它被用于最新的这些Transformer模型。作者将其与ResNet-50中的ReLU替换后发现准确率没有发生变化。
Fewer activation functions
作者注意到Transformer中并非像CNN那样每个卷积层/FC层后面都跟一个激活函数,例如MLP模块中只有一个激活函数。因此,作者进行了如下图的改造,ConvNeXt中仅在两个\(1\times 1\)卷积层中间保留一个GELU。浙江准确率提高了0.7%。
不是很懂这么做能涨点的原理~~
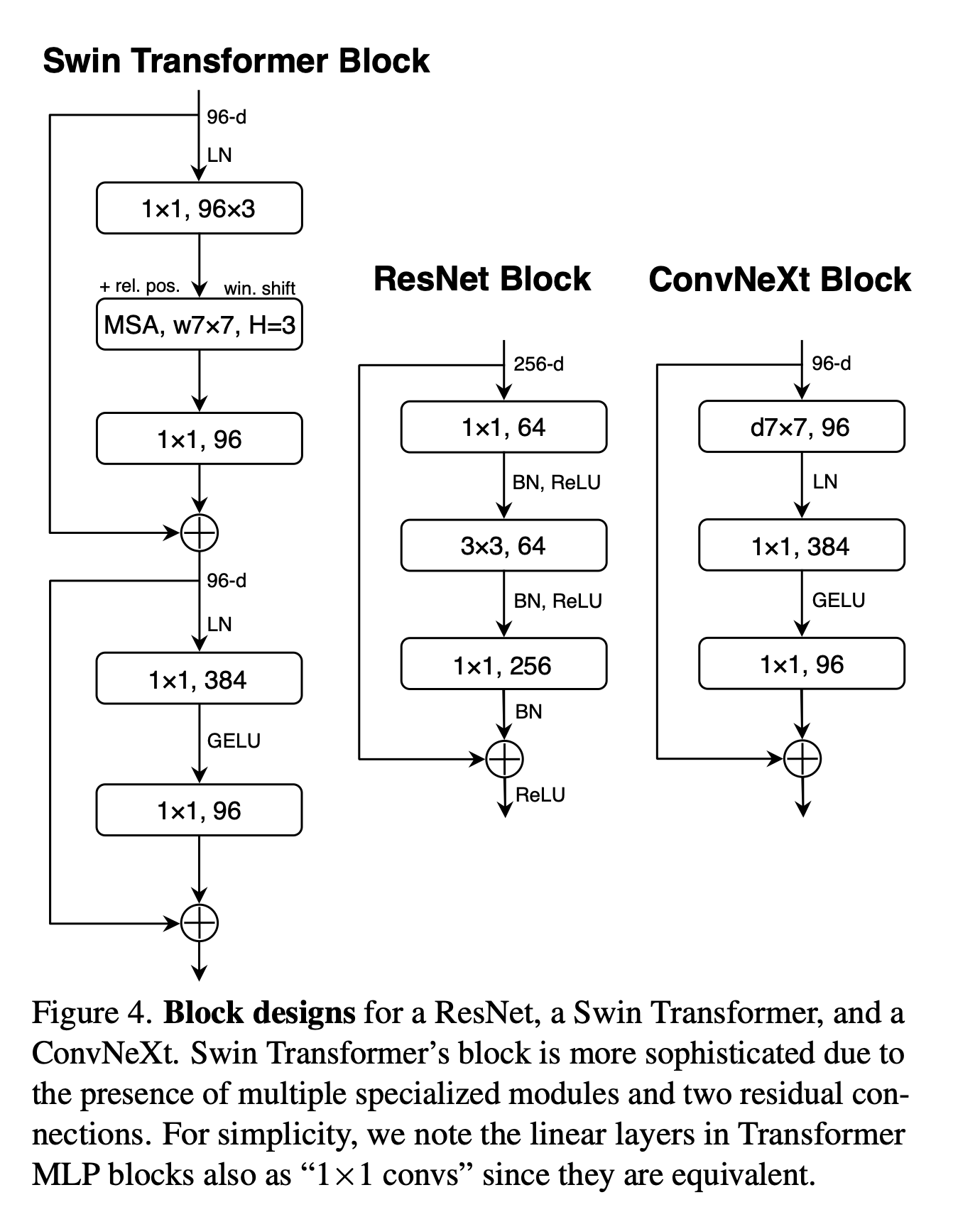
Fewer normalization layers
同样是模仿Transformer,作者只保留了depthwise conv层后面的Normalization层,将性能提高到81.4%。同时作者指出,在区块的开始添加一个额外的BN层并不能提高性能。
Substituting BN with LN
虽然BN在CNN中已经广泛使用(可以加快收敛、减少过拟合),但Transformer用的则是LN(这么做的原因网上可以查到很多解释)。因此作者将BN全部换为LN,发现性能小幅度提升到了81.5%。
Separate downsampling layers
在ResNet中是通过主分支上\(3\times 3\)的卷积层stride设置为2,short cut分支上\(1\times 1\)的卷积层stride设置成2进行下采样,而在Swin Transformer中是通过Patch Merging实现的(虽然采用这个实现也是为了像CNN中的池化层看齐),因此作者也单独设置了下采样层(LN+kernel size为(2,2) stride为2的卷积层)。这样可以将准确率进一步提升到82.0%。
经过这样的修改之后就得到了ConvNeXt网络模型。之后作者在各个数据集上进行了详尽的对比实验,这里就不继续分析了~感兴趣可以看一下原文。注意作者在开源的代码里还加上了Layer Scale,这是ICCV2021提出来的一个新科技。具体到代码中就是:
self.gamma = nn.Parameter(layer_scale_init_value * torch.ones((dim)),
requires_grad=True) if layer_scale_init_value > 0 else None
以及前向传播过程中:
if self.gamma is not None:
x = self.gamma * x
其中dim就是通道维度的大小,gamma也是可以学习的。相当于在通道维度对数据进行了缩放。
标签:Transformer,Swin,ConvNet,卷积,ResNet,笔记,times,作者,2020 来源: https://www.cnblogs.com/lipoicyclic/p/15866186.html