Yarn资源调度过程详细(TEZ)
作者:互联网
在MapReduce1.0中,我们都知道也存在和HDFS一样的单点故障问题,主要是JobTracker既负责资源管理,又负责任务分配。
Yarn中可以添加多种计算框架,Hadoop,Spark,MapReduce,不同的计算框架在处理不同的任务时,资源利用率可能处于互补阶段,有利于提高整个集群的资源利用率。
同时Yarn提供了一种共享集群的模式,随着数据量的暴增,跨集群间的数据移动,需要花费更长的时间,且硬件成本会增大,共享集群模式可以让多种框架共享数据和硬件资源。
Yarn基本架构
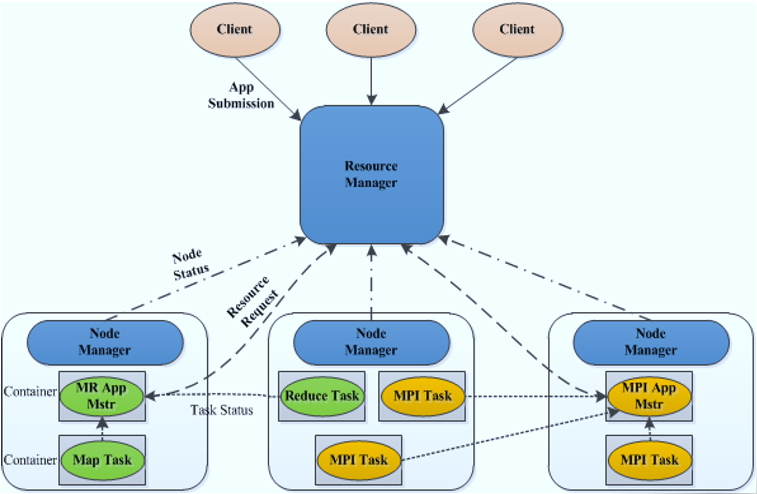
整个的调度流程为:
1.应用程序通client类向ResourceManager提交程序,Application运行所需要的入口类,出口类,运行的命令,运行所需要的cpu资源和内存资源,jar包资源。
2.ResourceManager通过内部的调度器,去集群中寻找资源,找到资源后与NodeManager进行通信,去启动相应的ApplicationMaster,AM会按照事先的规划将任务切分为许多的task任务。
3.ApplicationMaster之后向ResourceManager进行申请资源,RM会将资源进行动态的分配。
4.ApplicationMaster获得资源后会再将资源进一步分配给内部的task.
5.之后,ApplicationMaster会向NodeManager进行请求,让NM给启动起来Task,NM会把Task封装到Container中允许。
ResourceManager
整个集群只有一个,负责集群资源的统一管理和调度
处理客户端请求
启动监控ApplicationMaster
监控NodeManager
资源分配与调度
NodeManager
整个集群存在多个,负责单节点资源管理与使用
处理来自ResourceManager的命令
处理来自ApplicationMaster的命令
ApplicationMaster
每一个应用有一个,负责应用程序的管理
数据切分,申请资源,任务监控,任务容错
Container
对任务环境的抽象
Yarn的容错性
ResourceManager存在单点故障,基于Zookeeper实现HA,通常任务失败后,RM将失败的任务告诉AM,RM负责任务的重启,AM来决定如何处理失败的任务。RMAppMaster会保存已经运行完成的Task,重启后无需重新运行。
Yarn资源调度框架与调度器
Yarn采用的双层调度框架,RM将资源分配给AM,AM再将资源进一步分配给Task,资源不够时会为TASK预留,直到资源充足。在Hadoop1.0中我们分配资源通过slot实现,但是在Yarn中,直接分配资源。
资源调度器有:FIFO,Fair scheduler,Capacity scheduler
Yarn支持CPU和内存两种资源隔离,内存时决定生死的资源,CPU时影响快满的资源,内存隔离采用的是基于线程监控和基于Cgroup的方案。
Tez
Tez俗称DAG计算,多个计算作业之间存在依赖关系,并形成一个依赖关系的有向图。
Tez是运行在Yarn上的DAG,动态的生成计算的关系流。

如上图左所示的Top K问题,第一个Mapreduce实现wordcount的功能,第二个Mapreduce只用使用Reduce实现排序的问题,但是在Mapreduce中必须创建两个MapReduce任务,但是在Tez优化后,可以直接再第一个reduce后,不进行输出,直接输出到第二个reduce中,优化了Mapreduce.
上图中右为一个HiveQL实现的MapReduce,mapreduce为其创建了4个mapreduce任务,使用Tez可以只使用一个Mapreduce任务。
Tez on Yarn和,mapreduce on Yarn上的作业的流程基本一样。
Tez的优化技术
产生一个Mapreduce任务就提交,影响任务的效率,Tez的优化策略是创建一个ApplicationMaster的缓存池,作业提交到AMppplserver中,预先启动若干ApplicationMaster形成AM缓冲池。
同时ApplicationMaster启动的时候也可以预先启动几个container,做为容器的缓冲池。
此外ApplicationMaster运行完成后,不会马上注销其下的container,而是将其预先分配给正要运行的任务。
Tez的好处就是避免产生较多的Mapreduce任务,产生不必要的网络和磁盘IO.
Strom
Strom是实时处理永不停止的任务,像流水一样不断的处理任务。
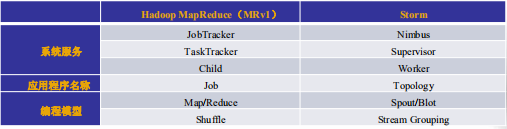
Strom非常类似与MapReduce1.0的架构,如上图所示。

但是其任务的调度的流程与Mapreduce的不一样。
主要的区别是Strom client可以直接操作 Strom ApplicationMaster
Spark
spark克服了MapReduce在迭代式计算和交互式计算方面的不足。
spark中引入了RDD,可以并行计算的数据集合,能够被缓存到能存和硬盘中。
spark on Yarn 和MapReduce on Yarn 基本上类似
MapReduce2.0和Yarn
MR运行需要进行任务管理和资源管理调度,Yarn只是负责资源管理调度。Mapreduce只是运行在Yarn上的应用。
MapReduce2.0包括Yarn 和MRMapreduce,所以说Yarn是从MapReudce中独立出来的一个模块。但是现在Yarn已经成为多种计算框架的资源管理器。
MapReduce1.0与MapReduce2.0的区别
MapReduce1.0是可以直接运行的linux系统上的,因为其自带了JobTracker服务和TaskTracker服务,它们可以自己进行资源管理与任务的分配。
MapReduce2.0中mapreduce是只有任务管理,所以其必须运行在Yarn上进行资源的调度。
标签:ApplicationMaster,Mapreduce,TEZ,Yarn,调度,任务,资源 来源: https://www.cnblogs.com/coco2015/p/15852484.html