(详细)分层强化学习-Random Network Distillation(RND)
作者:互联网
原文链接:https://zhuanlan.zhihu.com/p/146309991
EXPLORATION BY RANDOM NETWORK DISTILLATION
RND这类文章是基于强化学习在解决Atari游戏中蒙德祖玛的复仇的困境提出的。由于在这类游戏中存在非常稀疏的奖励,Agent在探索利用上存在很大的问题。RND也是第一个使用与人类平等的RL算法在蒙特祖玛的复仇上获得人类水平成绩的算法。
为提升稀疏奖励情况下的探索利用,之前有很多类似Curiosity、count-based的方法,但问题是,这些方法很难在大规模环境下使用(或者高维连续状态或动作),因为对于绝大多数的状态,count都是1或者0。RND提出了一种只需要做前向传播就能很好计算得到的探索奖励。
一个容易理解的事实是,神经网络的输入和训练样本相似时,具有更小的error,这给了一个可以使用agent过去的经验的预测误差来估计新经验探索性的启发。但直接利用这发方法会导致agent更倾向于探索具有随机性的状态转移(例如有的状态转移是完全随机的事件例如投硬币等等)。为了解决这种倾向随机的问题,RND使用了一个确定的随机初始化的神经网络,来预测当前状态的输出,进而确定这个探索奖励。
定义总奖励值 ,其中
是环境本身给予的奖励,可能是非常稀疏的,
是exploration bonus,也是本文的核心。
RND使用两个神经网络:一个固定、随机初始化的target network和另一个使用数据训练的predictor network。target network是一个输入映射 ,predictor network
,predictor network使用梯度下降最小化MSE
来更新其参数
。这个过程使得一个随机初始化的网络蒸馏成为一个训练好的网络。根据上面的MSE,当输入的状态与之前相差越大,predictor network的error越大。文章中展示了使用这个方法在MNIST上的结果:predictor在含有大量0的数据中训练,并观察新样本分布不同(加入不同比例的0之外的数据)时MSE表现如下图:
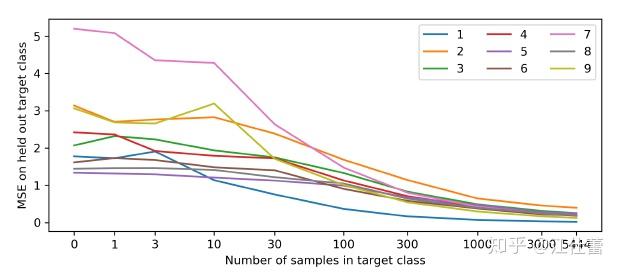
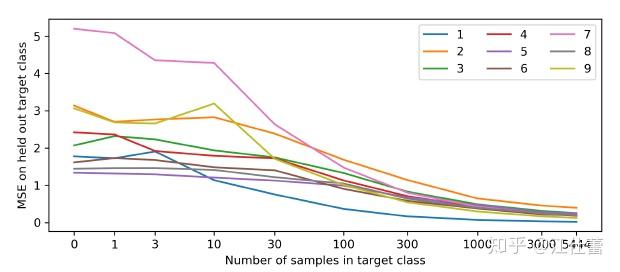
从上图能看到样本在训练数据中越新MSE越大。predictor可以理解为在向着“随机”的方向在优化。
进一步考虑在RL中使用这种方法模拟随机网络的MSE来源:
- 训练样本的分布;显然样本本身分布的变化,特别是之前很少见的样本会带来MSE增大;
- 随机的状态转移;类似上面我们提到过的一些状态下状态转移的随机性很强,与动作决策的相关性较差;这个问题也可以成为被局部熵陷阱吸引
- 模型的不确定性;不完全可观或观测不足;
- 模型学习的问题;优化器不能很好的模仿target network。
其实可以简单分一下:1是我们希望看到的结果;2是我们希望避免优化的方向;3是不可控的部分;4要么是可以通过改进优化器和参数避免,要么就是玄学问题。由于RND的target network是确定的,不会随着predictor的训练而受到数据或环境的局部熵影响,因此可以很好的避免2。
文章还讨论了RND网络蒸馏方法和不确定度量化之间的关系。假设我们的回归问题的数据集是 。根据贝叶斯我们首先通过一个映射
得到一个先验概率
,并随着观测不断更新后验
。
用 来表示
上的一个分布,其中
来自于
,
来自于最小化预测误差期望(映射
即RND中的predictor,
即target network):
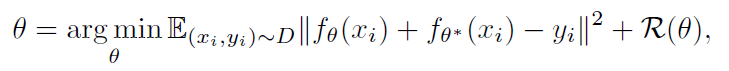
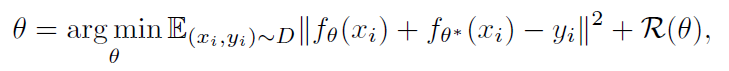
其中, 是优先级概率带来的正则项(与贝叶斯线性回归类似,为了校正分布
本身不是真实分布而是依据后验概率得到的)。
当回归目标 为0时,得到的表达形式就可以理解为从先验概率中蒸馏一个随机的映射方程。从这个角度看,对于predictor和target的每一对输出,都相当于是
的一个元素,MSE相当于在估计
的方差。因此这样的方法可以用于不确定度量化。
回到RND本身上来,由于在环境本身奖励 上加入了
,那么两者结合之后怎么给
呢?之前的部分,我们只讨论了
影响agent的情况,使用探索奖励来进行RL文章认为是在模拟环境中探索或者人类玩游戏的一个比较合理的模式。例如在玩游戏的时候遇到一个很可能会失败导致游戏重开的高难度BOSS,而只有通过这个BOSS才能进入下一关,当只使用环境奖励时,Agent会大概率避险,而实际人类玩游戏时,打BOSS失败的成本要低于游戏重开的成本,会不断重复尝试去打BOSS,因此这个循环过程是没有环境奖励的,只有探索BOSS不同招式带来的
。
但是,只依赖 的问题是,环境是不会因为
结束的,只要agent还在探索新的空间,因此必须把原始的环境奖励
加进来。一个最简单的想法以某个线性权重加和即
。对此,我们也将值函数
表示为两部分,
,分别用两个网络去估计,然后再将它们加和得到用于更新策略网络的
值。(文中也提到这个方法也可以用来估计不同折扣
的奖励的加和,在这里,即
和
可以使用不同的折扣系数)
对于target network,由于未进行训练,因此很难适应新样本的规模和分布,因此,对输入target network和predictor的状态进行了归一化(减均值除以标准差,一般会让agent先随便跑几步得到一个简单的均值和标准差结果就行);同时,为了让 的分布更容易被agent学习,对
也进行归一化(除以标准差)。但是不需要对策略网络的输入进行归一化。
效果:在蒙特祖玛的复仇上还是非常显著的
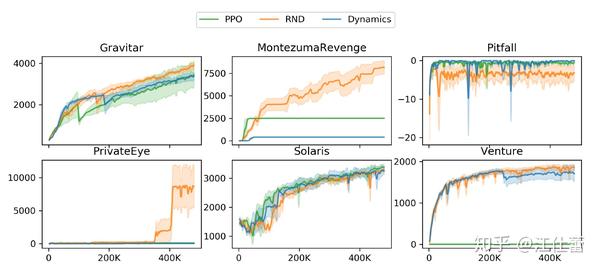
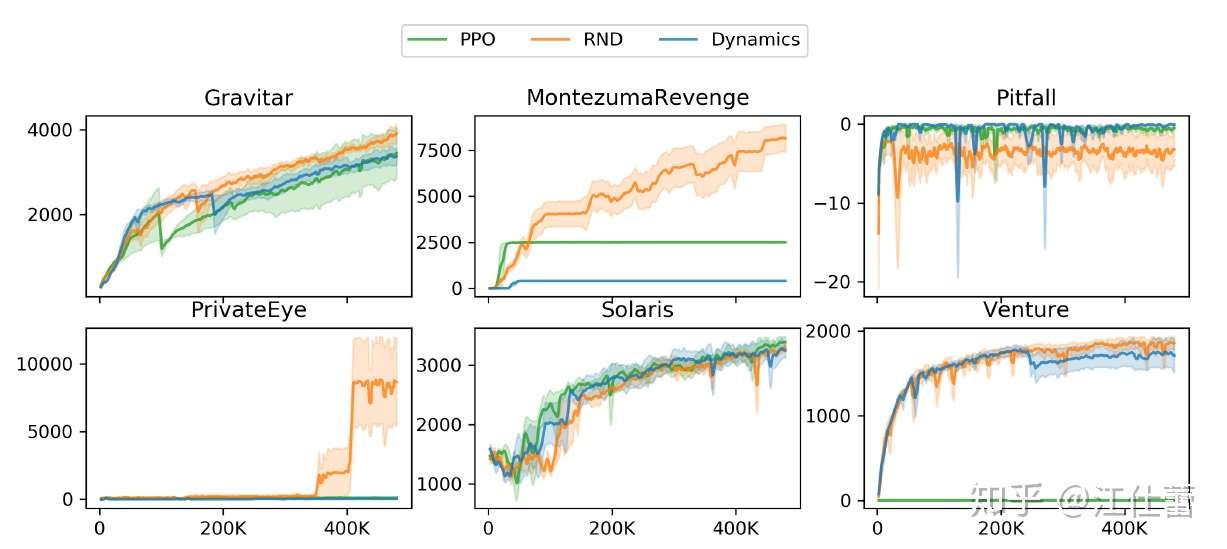
RND的伪码:


除了归一化参数的部分外,主要的差别就是使用了distillation network来作为值函数的估计网络,并用探索奖励和环境奖励合并,来求优势函数更新策略网络。
标签:Network,Random,Distillation,RND,奖励,target,MSE,predictor,network 来源: https://blog.csdn.net/qq_43703185/article/details/122718999