LRU
作者:互联网
LRU算法
LRU(Least Recently used 最近最少使用)算法是一种缓存淘汰算法,算法会根据数据的历史访问记录来进行淘汰数据,最近最少使用的数据将被淘汰,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。
简单原理
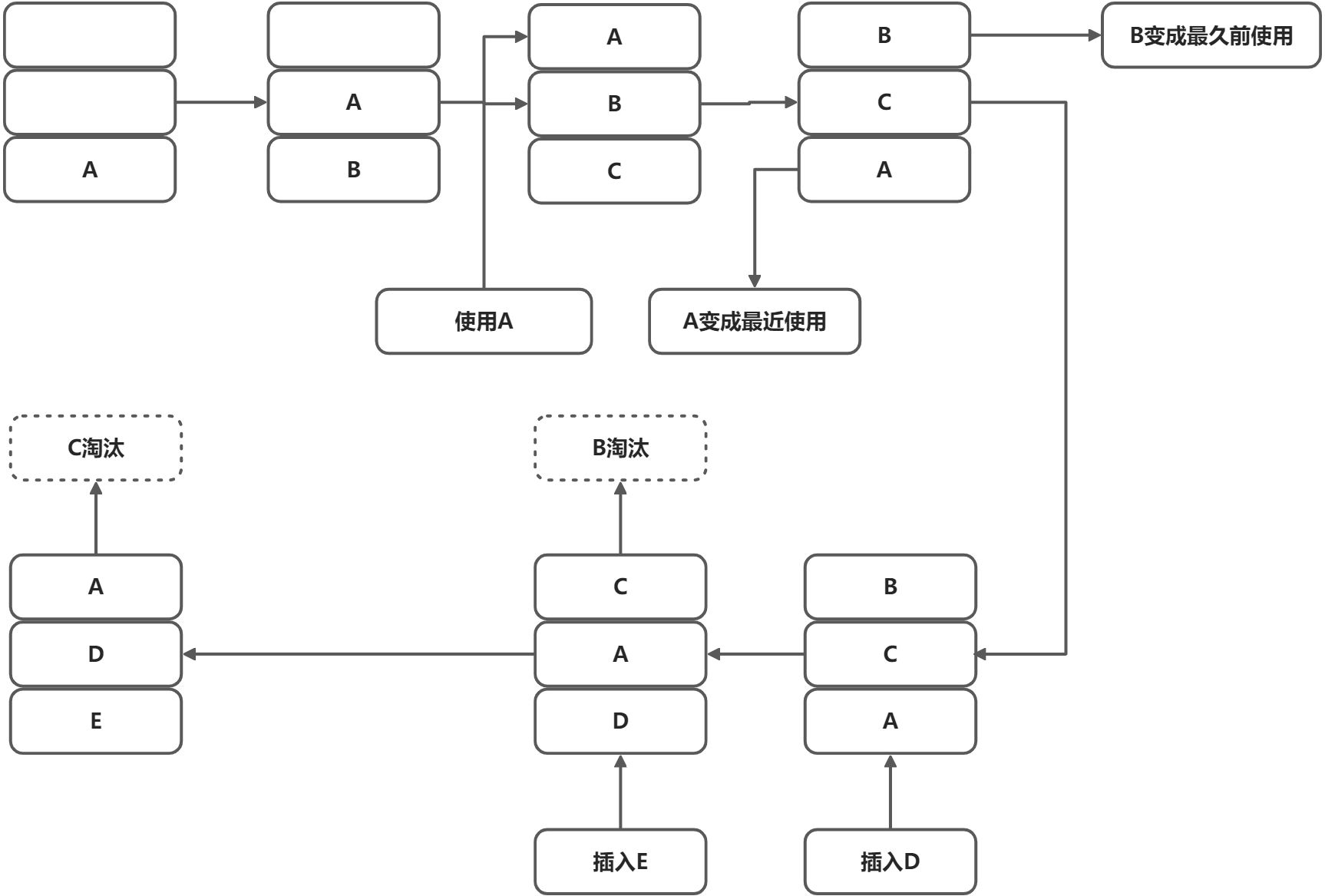
朴素的的LRU算法
- 基于数组
- 基于长度有限的双向链表
- 基于双向链表和哈希表
基于双向链表+哈希表实现LRU


import java.util.HashMap;
import java.util.Map;
public class LRUCache {
private int size; // 当前容量
private final int capacity; // 限制大小
private final Map<Integer, DoubleQueueNode> map; // 数据和链表中节点的映射
private final DoubleQueueNode head; // 头结点 避免null检查
private final DoubleQueueNode tail; // 尾结点 避免null检查
public LRUCache(int capacity) {
this.capacity = capacity;
this.map = new HashMap<>(capacity);
this.head = new DoubleQueueNode(0, 0);
this.tail = new DoubleQueueNode(0, 0);
this.head.next = tail;
}
public Integer get(Integer key) {
DoubleQueueNode node = map.get(key);
if (node == null) {
return null;
}
//数据在链表中,则移至链表头部
moveToHead(node);
return node.val;
}
public Integer put(Integer key, Integer value) {
Integer oldValue;
DoubleQueueNode node = map.get(key);
//数据不存在
if (null == node) {
//插入前先淘汰下数据
eliminate();
//数据不在链表中,插入数据至头部
DoubleQueueNode newNode = new DoubleQueueNode(key, value);
DoubleQueueNode headNextTemp = head.next;
headNextTemp.pre = newNode;
newNode.next = headNextTemp;
newNode.pre = head;
head.next = newNode;
map.put(key, newNode);
size++;
oldValue = null;
} else {
//数据在链表中,则移至链表头部
moveToHead(node);
oldValue = node.val;
node.val = value;
}
return oldValue;
}
public Integer remove(Integer key) {
DoubleQueueNode doubleQueueNode = map.get(key);
if (doubleQueueNode == null) {
return null;
}
doubleQueueNode.pre.next = doubleQueueNode.next;
doubleQueueNode.next.pre = doubleQueueNode.pre;
map.remove(key);
return doubleQueueNode.val;
}
// 将节点插入至头部节点
private void moveToHead(DoubleQueueNode node) {
node.pre.next = node.next;
node.next.pre = node.pre;
DoubleQueueNode headNextTemp = head.next;
head.next = node;
node.next = headNextTemp;
node.pre = head;
headNextTemp.pre = node;
}
private void eliminate() {
if (size < capacity) {
return;
}
//将链表中最后一个节点去除
DoubleQueueNode last = tail.pre;
map.remove(last.key);
last.pre.next = tail;
tail.pre = last.pre;
size--;
last = null;
}
static class DoubleQueueNode {
int key;
int val;
DoubleQueueNode pre;
DoubleQueueNode next;
public DoubleQueueNode(int key, int val) {
this.key = key;
this.val = val;
}
}
public static void main(String[] args) {
LRUCache lruCache = new LRUCache(3);
lruCache.put(1, 110);
lruCache.put(2, 120);
lruCache.put(3, 130);
System.out.println(lruCache);
Integer integer = lruCache.get(1);
System.out.println(integer);
System.out.println(lruCache);
lruCache.put(4, 140);
System.out.println(lruCache);
}
@Override
public String toString() {
StringBuilder res = new StringBuilder();
DoubleQueueNode pre = tail;
while (pre != null) {
res.append(" [").append(pre.key).append("=").append(pre.val).append("] ");
pre = pre.pre;
}
return res.toString();
}
}
View Code
put()和get()操作的时间复杂度都是O(1),空间复杂度为O(N)。
基于LinkedHashMap实现的LRU
import java.util.LinkedHashMap;
import java.util.Map;
public class LinkedHashMapLRUCache extends LinkedHashMap {
private final int capacity;
public LinkedHashMapLRUCache(int capacity) {
//将LinkedHashMap的accessOrder设为true
super(16, 0.75f, true);
this.capacity = capacity;
}
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
return super.size() >= capacity;
}
public static void main(String[] args) {
LinkedHashMapLRUCache lruCache = new LinkedHashMapLRUCache(4);
lruCache.put(1,110);
lruCache.put(2,120);
lruCache.put(3,130);
System.out.println(lruCache);
Object obj = lruCache.get(1);
System.out.println(obj);
System.out.println(lruCache);
lruCache.put(4,140);
System.out.println(lruCache);
}
}
View Code
默认LinkedHashMap并不会淘汰数据,所以重写它的removeEldestEntry()方法,当数据数量达到预设上限后,淘汰数据,accessOrder设为true意为按照访问的顺序排序。
LRU算法优化
LRU-K
相比LRU,LRU-K需要多维护一个队列,用于记录所有缓存数据被访问的历史。只有当数据的访问次数到达了K的时候,才将数据放进缓存。当需要淘汰数据时,LRU-K会淘汰第K次访问时间距离当前时间最大的数据。
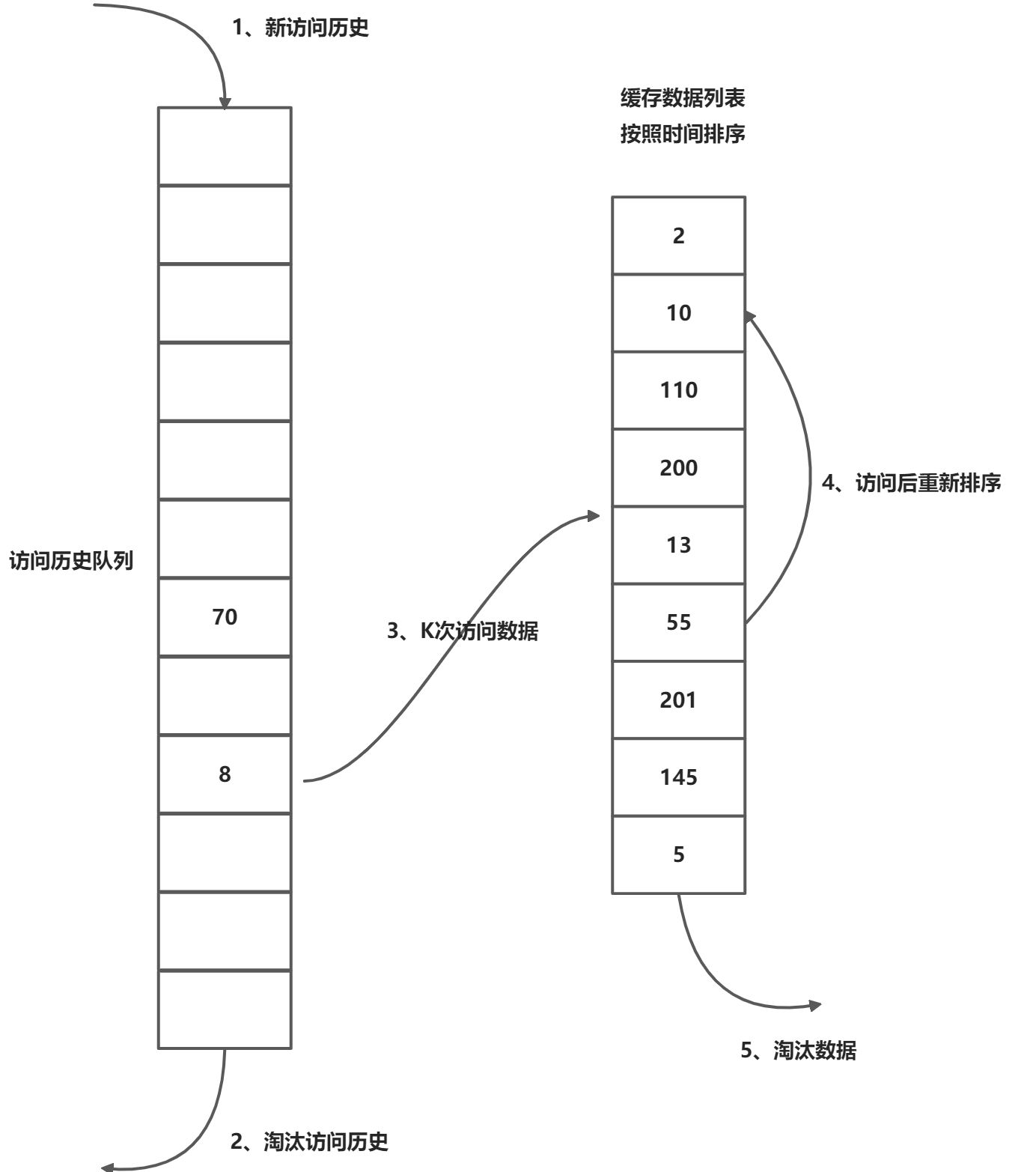
- 数据第一次访问,加入访问历史列表
- 如果数据存在访问历史列表里后没有达到K次访问,按照一定的规则(FIFO,LRU)淘汰
- 当访问历史队列中的数据访问次数到达K次后,将数据索引从历史队列删除,将数据移到缓存队列中,并缓存此数据,缓存队列重新按照时间排序
- 缓存数据队列被再次访问后,重新排序
- 需要淘汰数据时,淘汰缓存队列中排在末尾的数据,即:淘汰倒数第K次访问离现在最久的数据
public class LRUKCache extends LRUCache {
private int k; // 进入缓存队列的评判标准
private final LRUCache historyList; // 访问数据历史记录
public LRUKCache(int capacity, int historyCapacity, int k) {
super(capacity);
this.k = k;
this.historyList = new LRUCache(historyCapacity);
}
@Override
public Integer get(Integer key) {
//记录数据访问次数
Integer historyCount = historyList.get(key);
historyCount = null == historyCount ? 0 : historyCount;
historyList.put(key, ++historyCount);
return super.get(key);
}
@Override
public Integer put(Integer key, Integer value) {
if (value == null) {
return null;
}
if (super.get(key) != null) {
return super.put(key, value);
}
// 如果已经在缓存里则直接返回缓存中的数据
Integer historyCount = historyList.get(key);
historyCount = null == historyCount ? 0 : historyCount;
if (historyCount >= k) {
//移除访问历史记录
historyList.remove(key);
return super.put(key, value);
}
return null;
}
@Override
public String toString() {
return "LRUKCache{" +
"k=" + k +
", historyList=" + historyList +
"}LRUCache{" + super.toString() + "}";
}
public static void main(String[] args) {
LRUKCache lrukCache = new LRUKCache(4, 5, 3);
System.out.println(lrukCache);
Integer integer = lrukCache.get(1);
lrukCache.get(1);
lrukCache.get(1);
lrukCache.get(2);
lrukCache.get(2);
lrukCache.put(1, 111);
lrukCache.put(2, 122);
lrukCache.put(3, 133);
System.out.println(integer);
System.out.println(lrukCache);
lrukCache.put(4, 144);
System.out.println(lrukCache);
}
}
View Code
当K的值越大,则缓存的命中率越高,但是也会使得缓存难以被淘汰。综合来说,使用LRU-2的性能最优。
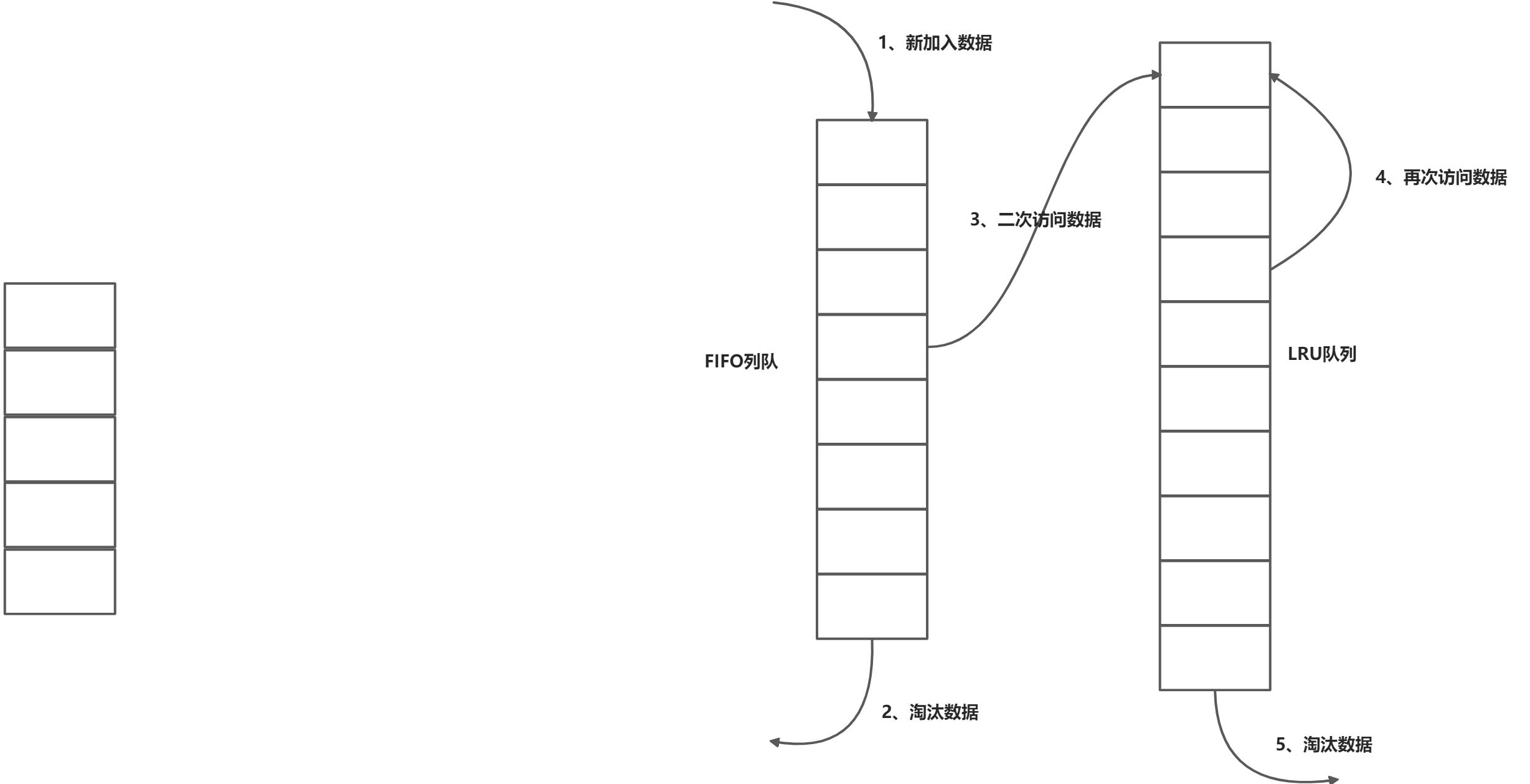
Two Queue
Two Queue可以说是LRU-2的一种变种,将数据访问历史改为FIFO队列。好处的明显的,FIFO更简易,耗用资源更少,但是相比LRU-2会降低缓存命中率。
import java.util.LinkedHashMap;
import java.util.Map;
public class TwoQueueCache extends LinkedHashMap<Integer, Integer> {
private final int k;
private final int historyCapacity;
private final LRUCache lruCache;
public TwoQueueCache(int cacheSize, int historyCapacity, int k) {
// 这里设置LinkedHashMap的accessOrder为false,默认不设置就是false
super();
this.k = k;
this.historyCapacity = historyCapacity;
this.lruCache = new LRUCache(cacheSize);
}
@Override
protected boolean removeEldestEntry(Map.Entry<Integer, Integer> eldest) {
return super.size() >= historyCapacity;
}
public Integer get(Integer key) {
// 记录访问记录
Integer historyCount = super.get(key);
historyCount = historyCount == null ? 0 : historyCount;
super.put(key, ++historyCount);
return lruCache.get(key);
}
public Integer put(Integer key, Integer value) {
if (value == null) {
return null;
}
// 如果已经在缓存里则直接返回缓存中的数据
if (lruCache.get(key) != null) {
return lruCache.put(key, value);
}
Integer historyCount = super.get(key);
historyCount = historyCount == null ? 0 : historyCount;
if (historyCount >= k) {
lruCache.put(key, value);
return lruCache.get(key);
}
return null;
}
@Override
public String toString() {
return "TwoQueueCache{" +
"k=" + k +
", historyCapacity=" + historyCapacity +
", lruCache=" + lruCache +
'}' + super.toString();
}
public static void main(String[] args) {
TwoQueueCache twoQueueCache = new TwoQueueCache(4, 5, 3);
Integer integer = twoQueueCache.get(1);
twoQueueCache.get(1);
twoQueueCache.get(1);
twoQueueCache.get(2);
twoQueueCache.get(2);
twoQueueCache.put(1, 111);
twoQueueCache.put(2, 122);
twoQueueCache.put(3, 133);
System.out.println(integer);
System.out.println(twoQueueCache);
twoQueueCache.put(4, 144);
System.out.println(twoQueueCache);
}
}
View Code
FIFO队列直接使用继承LinkedHashMap,并且accessOrder默认为false,按照插入顺序排序,通过重写removeEldestEntry()方法来自动淘汰最早插入的数据。
Multi Queue
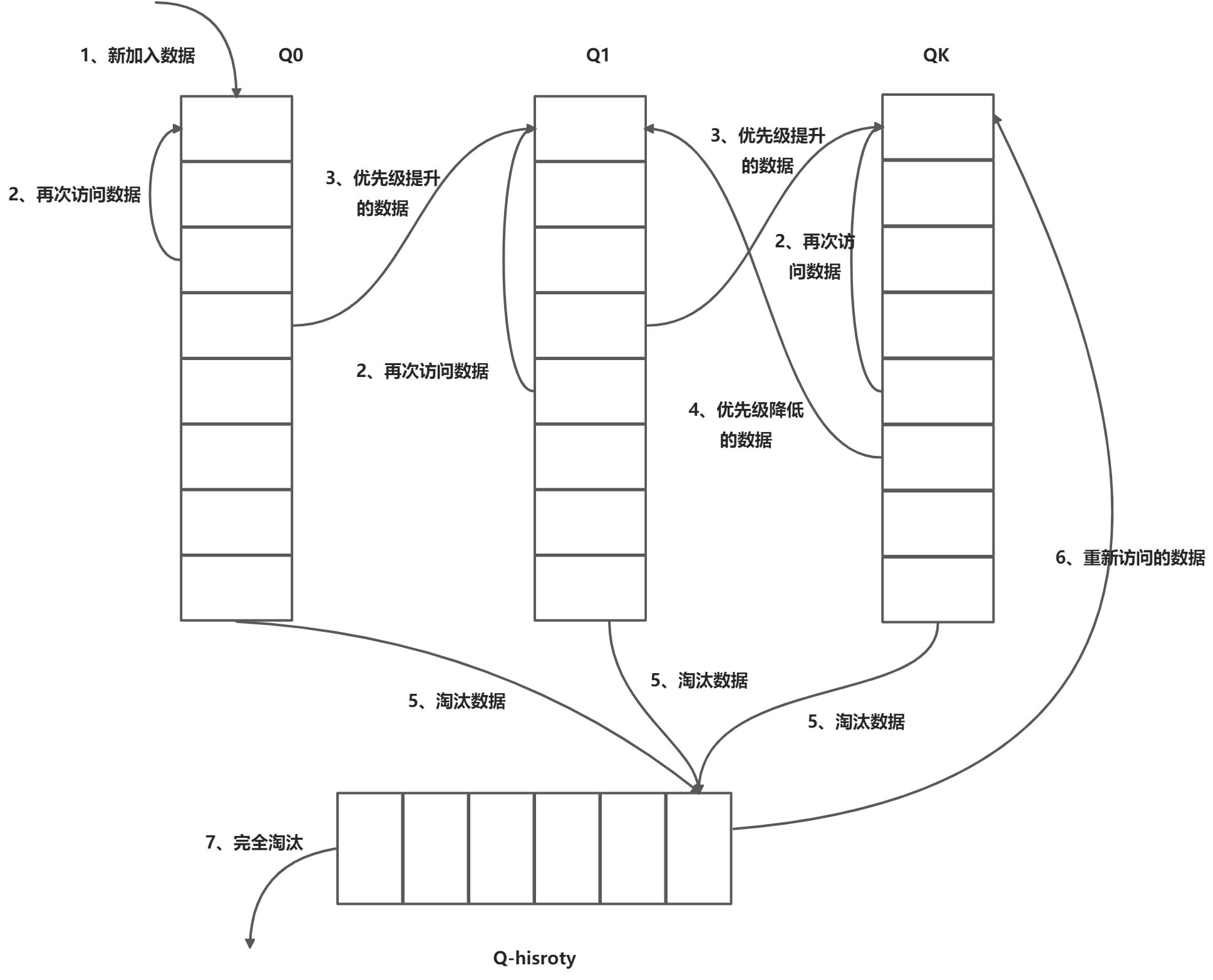
- 数据插入和访问:当数据首次插入时,会放入到优先级最低的Q0队列。当再次访问时,根据LRU的规则,会移至队列头部。当根据访问次数计算的优先级提升后,会将该数据移至更高优先级的队列的头部,并删除原队列的该数据。同样的,当该数据的优先级降低时,会移至低优先级的队列中。
- 数据淘汰:数据淘汰总是从最低优先级的队列的末尾数据进行,并将它加入到Q-history队列的头部。如果数据在Q-history数据中被访问,则重新计算该数据的优先级,并将它加入到相应优先级的队列中。否则就是按照LRU算法完全淘汰。
LRU应用场景
- 底层的内存管理,页面置换算法
- 一般的缓存服务,memcache\redis之类
- 部分业务场景
标签:get,LRU,key,put,Integer,public,lruCache 来源: https://www.cnblogs.com/sustan/p/15828338.html