[原创] 路由树
作者:互联网
路由是相对比较难的一个模块,这篇文章定位是协助理解。
确保先看这篇文档,https://beego.vip/docs/mvc/controller/router.md
(除了beego之外,还有gin等都用了类似的路由原理)
能运用之后,再看源码如果觉得绕不能理解,就可以参考本篇
路由树
路由树是Tree结点连接组成的一棵树。每个Tree结点包含四个项,分别为
- prefix //前缀
- fixrouters //[ ]固定(静态)路由
- wildcard //通配符(树)
- leaves //[ ] 叶子结点
其中fixrouters和wildcard又是一个Tree,这样就是递归往复。
叶子结点是一个leafinfo的结构。
说起来很抽象,下面从调试结果来看将会一目了然
匹配样式
变化1:通配在末端
后端路由:
/user/get
/user/get/?:id:int
/user/get/?:id:string
调试结果
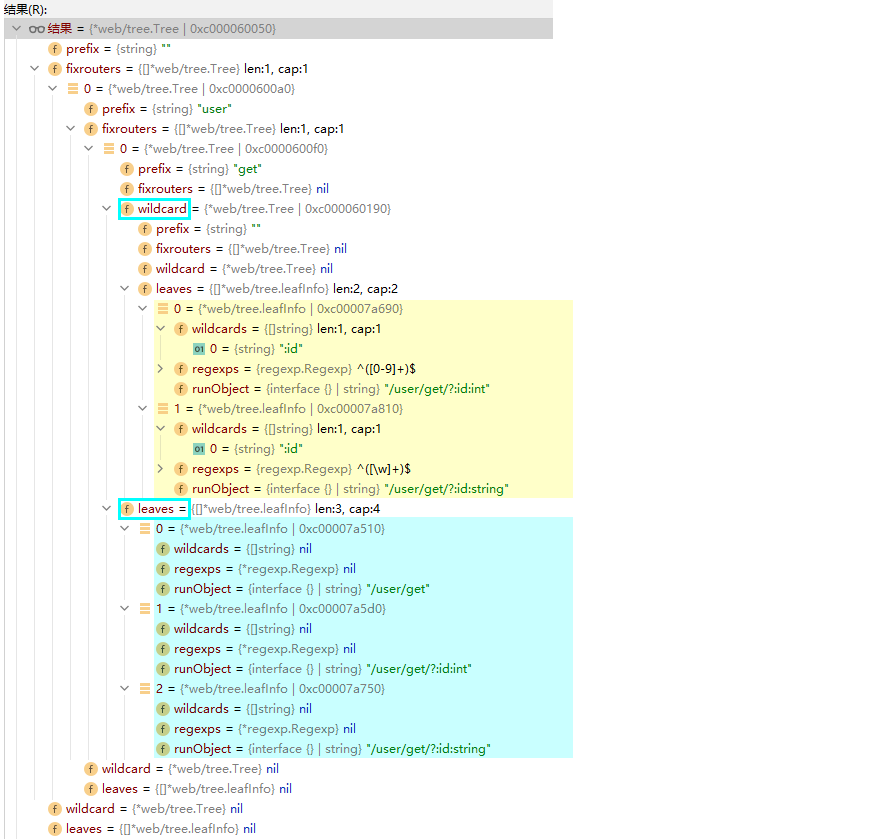
这个图清晰说明了思路,对于get结点来说,它的通配符wildcard有两个孩子。
叶子结点有三个孩子,原因是:
- /user/get本身就已经没有后续了,因此有一个叶子
- /user/get/?xx,?表示有或没有,由于它具有"没有"这个属性,因此也归为叶子。而在本段代码中,有两个?的路由,所以都划进来了。
变化2:通配在中间
这种形式应该说不太合规范,只从原理上看个结果
/user/:id/get
变化一是常规,也是最正常的形式,如果是/user/:id/get这种样式怎么办?也就是不确定的匹配在中间掺杂,这里不考虑实际,而是从纯理论上来看,是有这种可能
打印结果如下:
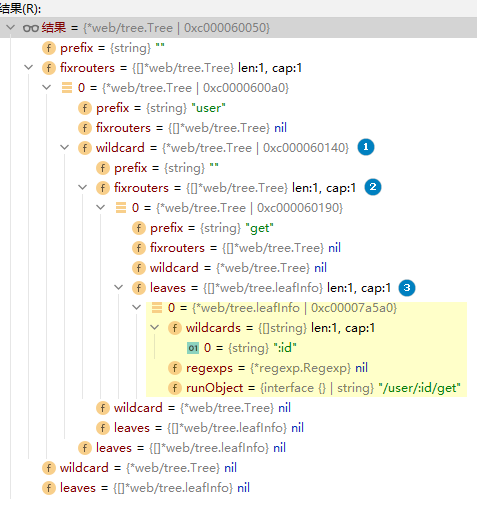
符合推测结果,get被挂到user的通配符树下,这也说明,通配树和静态树两者可以互相嵌套对挂。
/user/?:id/get

由于?:id具有"有"或"没有"的两层含义,因此产生两种变化。路由算法将第一种变化直接归为静态路由,完全正确。
/user/?:id:int/get
打印结果如下:

与变化三相比,唯一多的就是一个正则匹配项,原因是这里限定了:int类型,
匹配符 *.*
匹配符*.*一般都放在尾端,如果非要放在中间,比如:
/download/*.*/api
那就当没说...
理论上是可以,但是没有实际意义
*.*被解释为通配符
路由定义:/download/*.*
打印结果
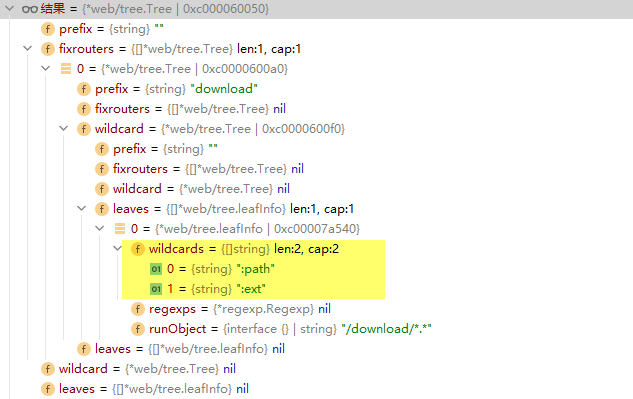
情形一
请求路由:/download/file/js/api.xml
- 通配符被组合成
["file","js","api.xml"] - 最后一个值
"api.xml"被取出并做分割得到扩展名.xml
- 路径再组通配符值组合得到:
"file/js/api"
总结来说,从第一个通配符起始到末尾整个被匹配

其中,最后一项当做文件名
源码如下
匹配符 *
打印结果如下:
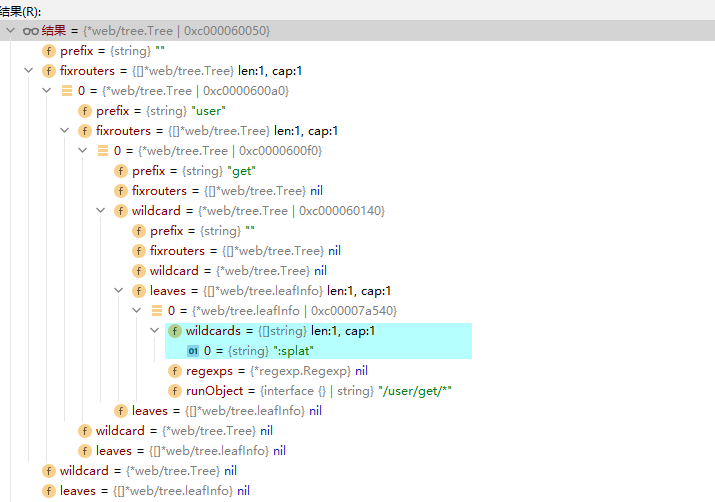
说明:
*号:从结果来看,*被解释为【通配符】,并在wildcards里面固定添加了一个":splat"。
下面记下一个匹配过程,比如有下面请求:
后端路由定义:/user/get/*
前端请求路由:/user/get/20/id/query
(这个路由只是为了举例说明)
匹配到20的时候,由于get之下已经没有静态路由,于是转到通配符树继续匹配。
转到之后发现此通配符树既没有静态,也没有子通配符树,因此,最终来到最后一步,用leaves来匹配。
在这一步中,先将所有的通配内容组装在一块,也就是说20/id/query,被一一拆分又被组装到wildcardValues中。
源码如下:
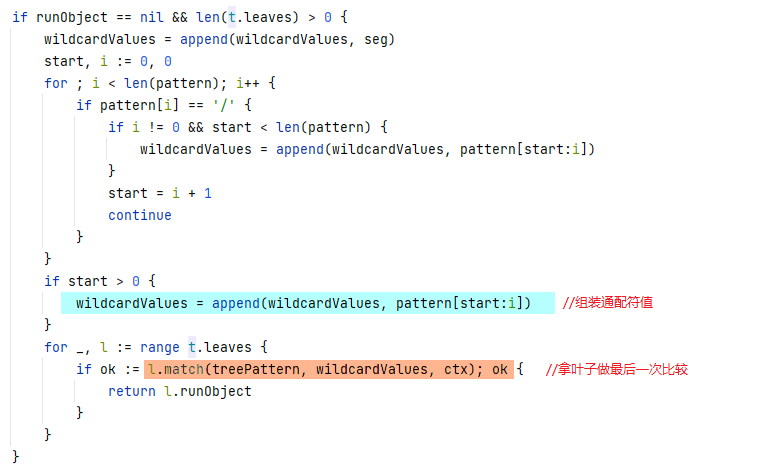
由于*的匹配能力太强大,这里就被接盘了。
正则自定义 cms_:id([0-9]+)_:page([0-9]+).html
打印结果
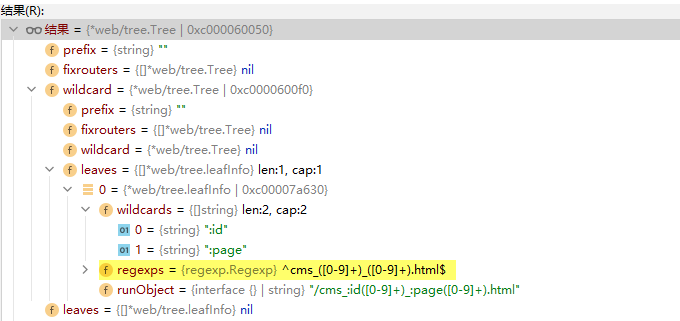
匹配策略
有很多东西用语言描述似乎很困难,真是只可意会,不可言转,尤其对于递归
首先看一张概念图(如果看图理解了,语言就是多余的:)-)

这个概念图主要表明几点:
- 路由首先尽可能努力的往下匹配,匹配路径依次为:静态路由,通配符,叶子结点。
具体说就是,先匹配静态路由,一直到失败或静态路由为0。接着在当前失败节点下再尝试通配符树匹配,再不行,做最后一次努力,用叶子结点尝试匹配。 - 如果步骤1失败,那么递归回滚到倒数第二个结点,再看它的通配符和叶子节点行不行。如果再失败,回滚到倒数第三个结点(往顶点方向前进),以此类推。
举个例子来说,路由定义为:
/user/get/aa/bb/cc/
/user/get/*
/user/*
请求的路由为:/user/get/aa/dd,先尽可能努力往下匹配,一直到aa/bb时,由于静态路由不等,因此开始用当前失败结点aa的通配符树匹配,失败,再用叶子结点匹配,继续失败,此时当前结点已经尝试匹配完全了,递归代码开始往回滚,....一直到get这个结点时,发现它有一个强大的*通配符,因此这个点接盘,完成了路由匹配。(假如这个点还不成功,一直回滚到/user,如果到了原点还是没有匹配的,那么路由匹配彻底失败)
总结就是:A->B->C->D->E...,先努力往后匹配,如果不成功就倒回来D->C->B->A...,在每个结点内部再按着通配符、叶子结点的顺序挨个的匹配。非常类似于DOM的冒泡机制。
- 通过步骤1,2可以看出,当前路由匹配失败并不一定会失败,可能在前部的某个节点中接盘。从侧面也说明,路由的定义要谨慎。因为定义太多,说不定哪个地方就会出现漏洞。
匹配优先级
理解了原理,自然就会想到这个问题
比如,后端打算的路由是这样的:
/user/get/:id:int
意思是匹配:/user/get/整数
结果,某个同事在不知情的情况下又在前面加了一个路由:
/user/get/*
这样整个路由的排列顺序为:
/user/get/*
/user/get/:id:int
现在前端无论发送什么样的/user/get/xx都被/user/get/*匹配了,显然这不是想要的结果
因此,路由在定义时务必很小心。
路由示例一览表
|
样式 |
后端路由定义 |
匹配的路由 |
||
|
静态路由 |
/user/get /aa/bb/cc/dd |
=> /user/get => /aa/bb/cc/dd |
||
|
尾端变化 |
/user/get/:id /user/get/?:id /user/get/:id:int /user/get/?:id:int /user/get/?:id:string |
|||
标签:匹配,get,通配符,user,原创,id,路由 来源: https://www.cnblogs.com/tinaluo/p/15820734.html