扒一扒@Retryable注解,很优雅,有点意思!
作者:互联网
你好呀,我是歪歪。
前几天我 Review 代码的时候发现项目里面有一坨逻辑写的非常的不好,一眼望去简直就是丑陋之极。
我都不知道为什么会有这样的代码存在项目里面,于是我看了一眼提交记录准备叫对应的同事问问,为什么会写出这样的代码。
然后...
那一坨代码是我 2019 年的时候提交的。
我细细的思考了一下,当时好像由于对项目不熟悉,然后其他的项目里面又有一个类似的功能,我就直接 CV 大法搞过来了,里面的逻辑也没细看。
嗯,原来是历史原因,可以理解,可以理解。

代码里面主要就是一大坨重试的逻辑,各种硬编码,各种辣眼睛的补丁。
特别是针对重试的逻辑,到处都有。所以我决定用一个重试组件优化一波。
今天就带大家卷一下 Spring-retry 这个组件。

丑陋的代码
先简单的说一下丑陋的代码大概长什么样子吧。
给你一个场景,假设你负责支付服务,需要对接外部的一个渠道,调用他们的订单查询接口。
他们给你说:由于网络问题,如果我们之间交互超时了,你没有收到我的任何响应,那么按照约定你可以对这个接口发起三次重试,三次之后还是没有响应,那就应该是有问题了,你们按照异常流程处理就行。
假设你不知道 Spring-retry 这个组件,那么你大概率会写出这样的代码:
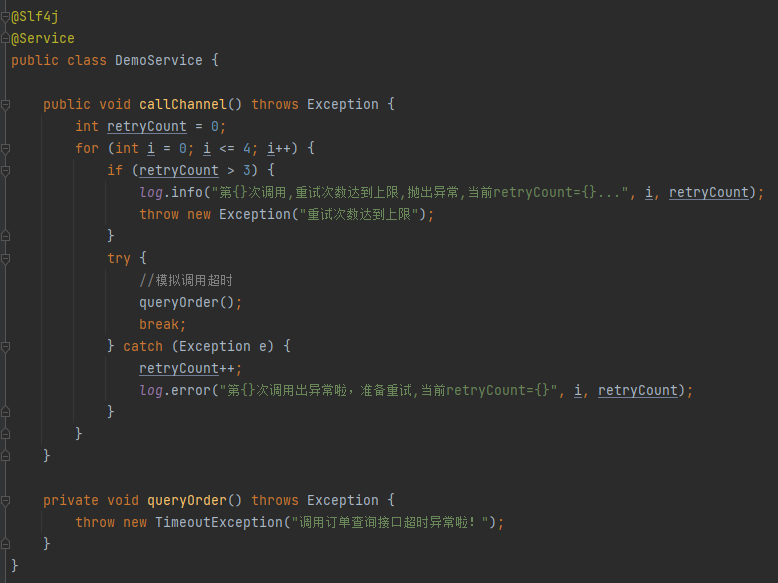
逻辑很简单嘛,就是搞个 for 循环,然后异常了就发起重试,并对重试次数进行检查。
然后搞个接口来调用一下:
发起调用之后,日志的输出是这样的,一目了然,非常清晰:
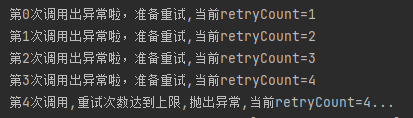
正常调用一次,重试三次,一共可以调用 4 次。在第五次调用的时候抛出异常。
完全符合需求,自测也完成了,可以直接提交代码,交给测试同学了。
非常完美,但是你有没有想过,这样的代码其实非常的不优雅。
你想,如果再来几个类似的“超时之后可以发起几次重试”需求。
那你这个 for 循环是不是得到处的搬来搬去。就像是这样似的,丑陋不堪:
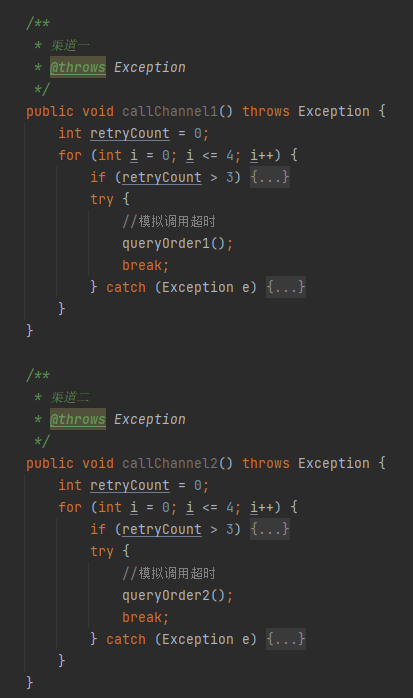
实话实说,我以前也写过这样的丑代码。

但是我现在是一个有代码洁癖的人,这样的代码肯定是不能忍的。
重试应该是一个工具类一样的通用方法,是可以抽离出来的,剥离到业务代码之外,开发的时候我们只需要关注业务代码写的巴巴适适就行了。
那么怎么抽离呢?
你说巧不巧,我今天给你分享这个的东西,就把重试功能抽离的非常的好:
https://github.com/spring-projects/spring-retry

用上 spring-retry 之后,我们上面的代码就变成了这样:

只是加上了一个 @Retryable 注解,这玩意简直简单到令人发指。
一眼望去,非常的优雅!

所以,我决定带大家扒一扒这个注解。看看别人是怎么把“重试”这个功能抽离成一个组件的,这比写业务代码有意思。
我这篇文章不会教大家怎么去使用 spring-retry,它的功能非常的丰富,写用法的文章已经非常多了。我想写的是,当我会使用它之后,我是怎么通过源码的方式去了解它的。
怎么把它从一个只会用的东西,变成简历上的那一句:翻阅过相关源码。

但是你要压根都不会用,都没听过这个组件怎么办呢?
没关系,我了解一个技术点的第一步,一定是先搭建出一个非常简单的 Demo。
没有跑过 Demo 的一律当做一无所知处理。
先搭 Demo
我最开始也是对这个注解一无所知的。
所以,对于这种情况,废话少说,先搞个 Demo 跑起来才是王道。
但是你记住搭建 Demo 也是有技巧的:直接去官网或者 github 上找就行了,那里面有最权威的、最简洁的 Demo。
比如 spring-retry 的 github 上的 Quick Start 就非常简洁易懂。

它分别提供了注解式开发和编程式开发的示例。
我们这里主要看它的注解式开发案例:
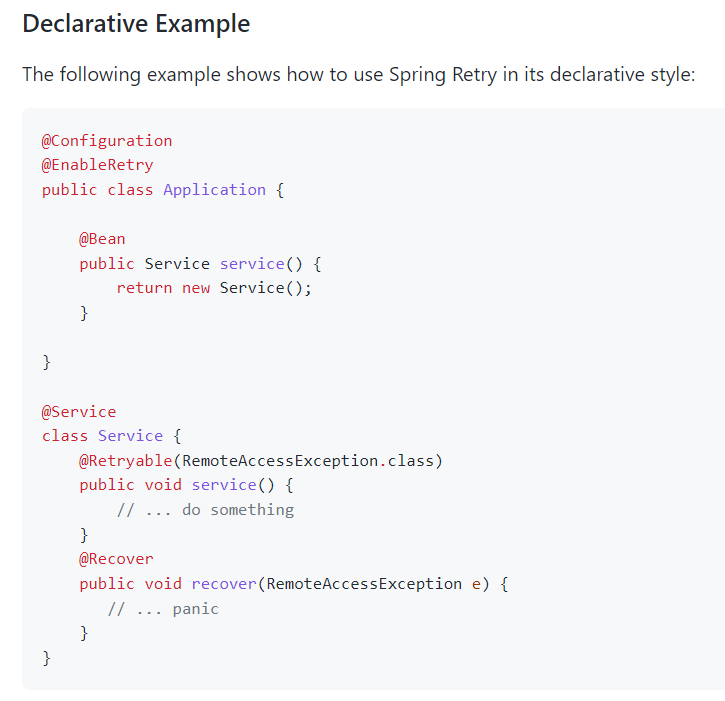
里面涉及到三个注解:
@EnableRetry:加在启动类上,表示支持重试功能。 @Retryable:加在方法上,就会给这个方法赋能,让它有用重试的功能。 @Recover:重试完成后还是不成功的情况下,会执行被这个注解修饰的方法。
看完 git 上的 Quick Start 之后,我很快就搭了一个 Demo 出来。
如果你之前不了解这个组件的使用方法的话,我强烈建议你也搭一个,非常的简单。
首先是引入 maven 依赖:
<dependency>
<groupId>org.springframework.retry</groupId>
<artifactId>spring-retry</artifactId>
<version>1.3.1</version>
</dependency>
由于该组件是依赖于 AOP 给你的,所以还需要引入这个依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
<version>2.6.1</version>
</dependency>
然后是代码,就这么一点,就够够的了:
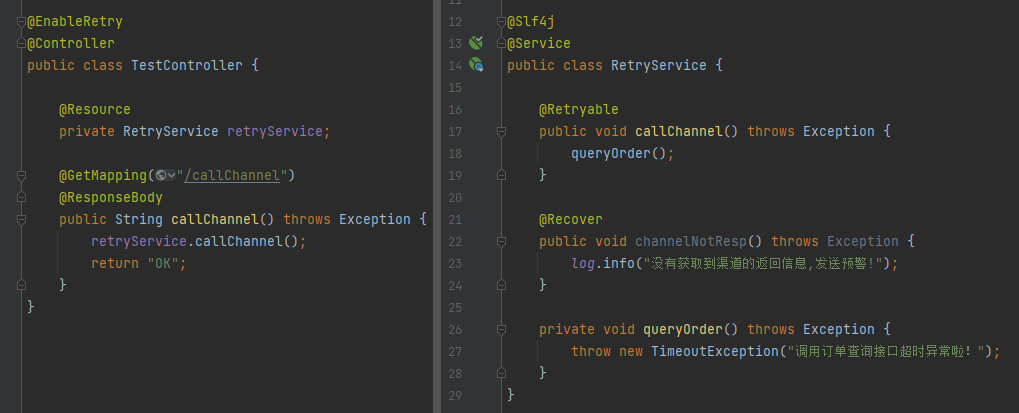
最后把项目跑起来,调用一笔,确实是生效了,执行了 @Recover 修饰的方法:
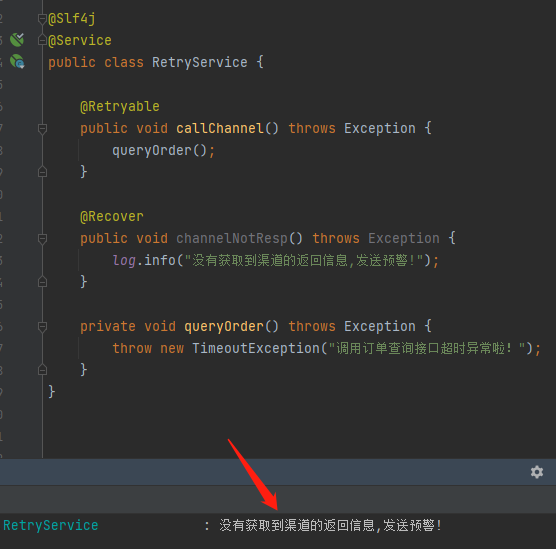
但是日志就只有一行,也没有看到重试的操作,未免有点太简陋了吧?
我以前觉得无所谓,迫不及待的冲到源码里面去一顿狂翻,左看右看。

我是怎么去狂翻源码做呢?
就是直接看这个注解被调用的地方,就像是这样:
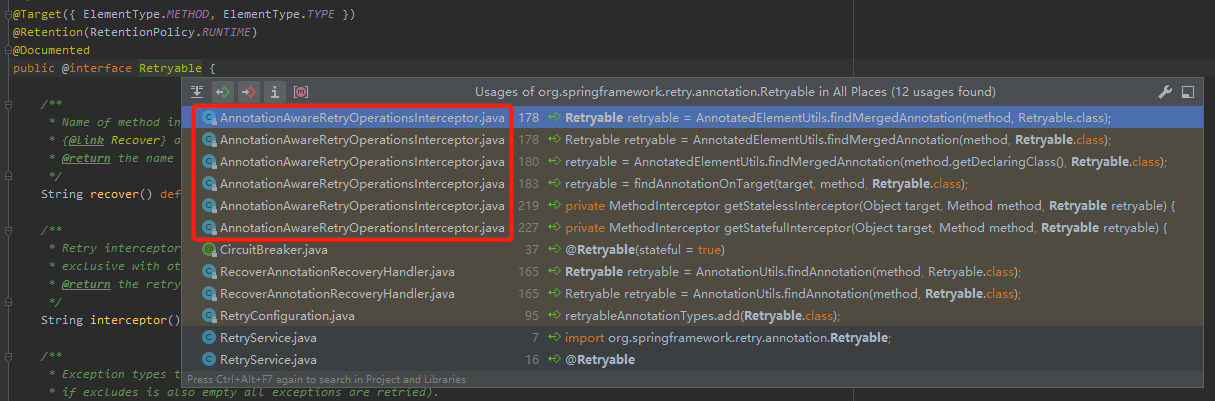
调用的地方不多,确实也很容易就定位到下面这个关键的类:
org.springframework.retry.annotation.AnnotationAwareRetryOperationsInterceptor
然后在相应的位置打上断点,开始跑程序,进行 debug:
但是我现在不会这么猴急了,作为一个老程序员,现在就成熟了很多,不会先急着去卷源码,会先多从日志里面挖掘一点东西出来。
我现在遇到这个问题的第一反应就是调整日志级别到 debug:
logging.level.root=debug
修改日志级别重启并再次调用之后,就能看到很多有价值的日志了:
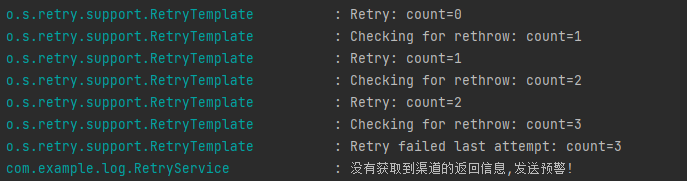
基于日志,可以直接找到这个地方:
org.springframework.retry.support.RetryTemplate#doExecute
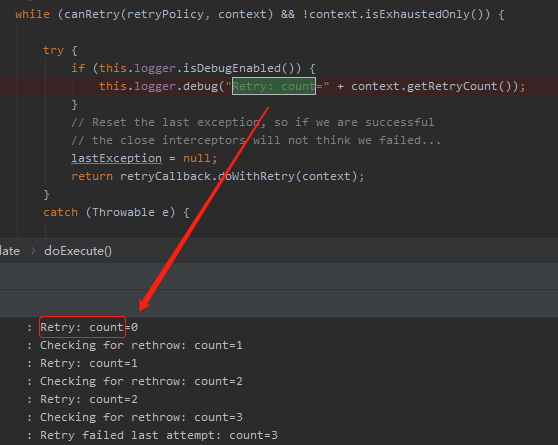
在这里打上断点进行调试,才是最合适的地方。
这也算是一个调试小技巧吧。以前我经常忽略日志里面的输出,感觉一大坨难得去看,其实仔细去分析日志之后你会发现这里面有非常多的有价值的东西,比你一头扎到源码里面有效多了。
你要是不信,你可以去试着看一下 Spring 事务相关的 debug 日志,我觉得那是一个非常好的案例,打印的那叫一个清晰。
从日志就能推动你不同隔离级别下的 debug 的过程,还能保持清晰的链路,不会有杂乱无序的感觉。
好了,不扯远了。
我们再看看这个日志,这个输出你不觉得很熟悉吗?
这不和刚刚我们前面出现的一张图片神似吗?
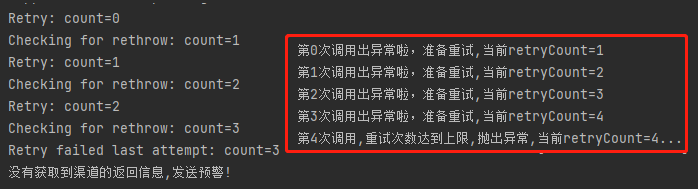
看到这里一丝笑容浮现在我的嘴角:小样,我盲猜你源码里面肯定也写了一个 for 循环。如果循环里面抛出异常,那么就检测是否满足重试条件,如果满足则继续重试。不满足,则执行 @Recover 的逻辑。
要是猜错了,我直接把电脑屏幕给吃了。
好,flag 先立在这里了,接下来我们去撸源码。
等等,先停一下。
如果说我们前面找到了 Debug 第一个断点打的位置,那么真正进入源码调试之前,还有一个非常关键的操作,那就是我之前一再强调的,一定要带着比较具体的问题去翻源码。
而我前面立下的 flag 其实就是我的问题:我先给出一个猜想,再去找它是不是这样实现的,具体到代码上是怎么实现。
所以再梳理了一下我的问题:
1.找到它的 for 循环在哪里。 2.它是怎么判断应该要重试的? 3.它是怎么执行到 @Recover 逻辑的?
现在可以开始发车了。
翻源码
源码之下无秘密。
首先我们看一下前面找到的 Debug 入口:
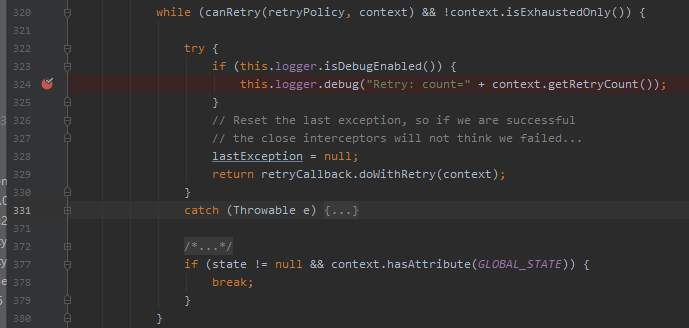
org.springframework.retry.support.RetryTemplate#doExecute
从日志里面可以直观的看出,这个方法里面肯定就包含我要找的 for 循环。
但是...
很遗憾,并不是 for 循环,而是一个 while 循环。问题不大,意思差不多:
打上断点,然后把项目跑起来,跑到断点的地方我最关心的是下面的调用堆栈:
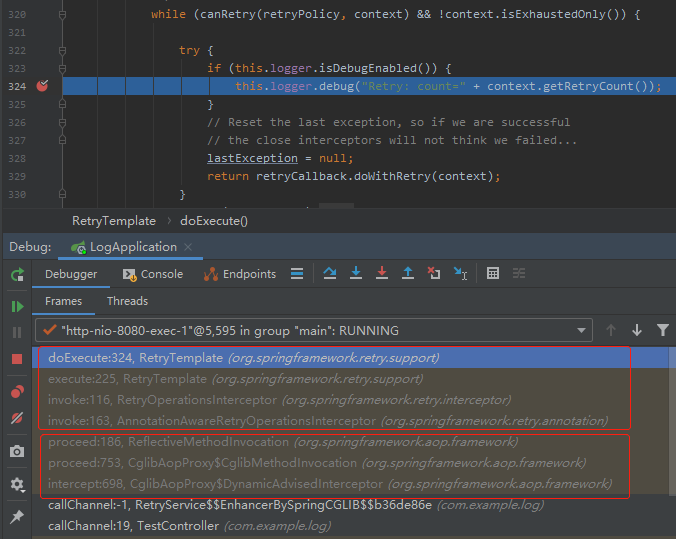
被框起来了两部分,一部分是 spring-aop 包里面的内容,一部分是 spring-retry。
然后我们看到 spring-retry 相关的第一个方法:
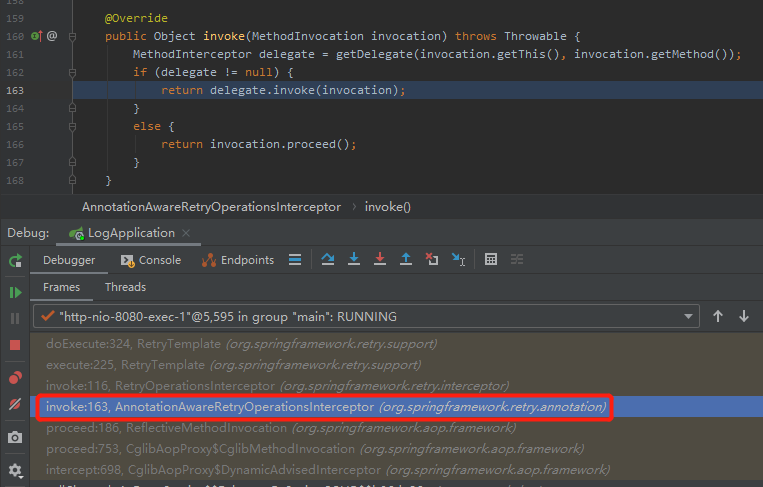
恭喜你,如果说前面通过日志找到了第一个打断点的位置,那么通过第一个断点的调用堆栈,我们找到了整个 retry 最开始的入口处,另外一个断点就应该打在下面这个方法的入口处:
org.springframework.retry.annotation.AnnotationAwareRetryOperationsInterceptor#invoke
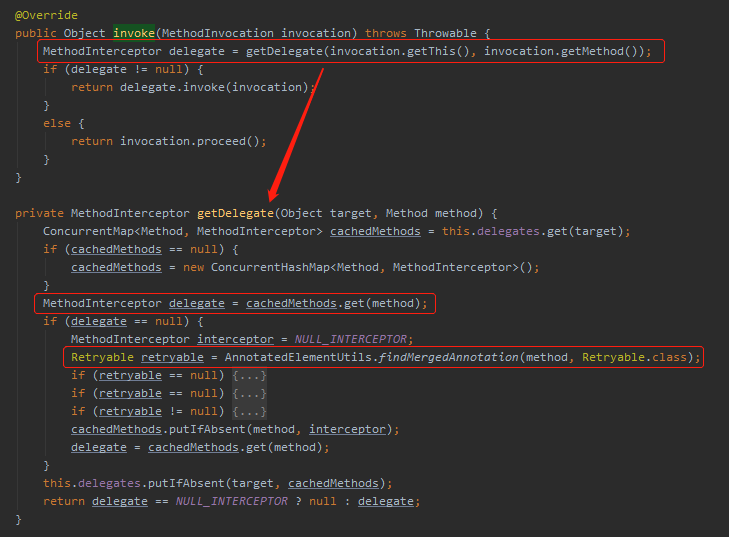
说真的,观察日志加调用栈这个最简单的组合拳用好了,调试绝大部分源码的过程中都不会感觉特别的乱。
找到了入口了,我们就从接口处接着看源码。
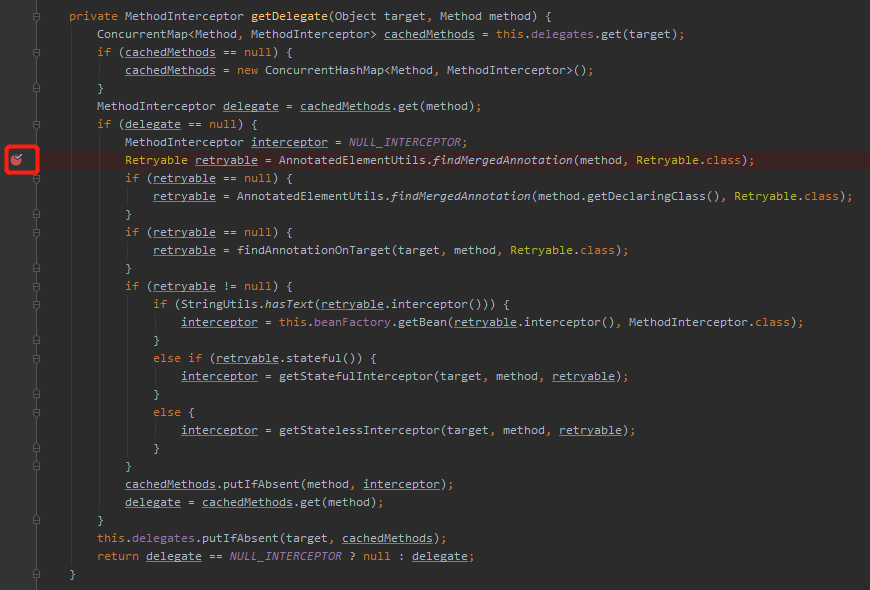
这个 invoke 方法一进来首先是试着从缓存中获取该方法是否之前被成功解析过,如果缓存中没有则解析当前调用的方法上是否有 @Retryable 注解。
如果是被 @Retryable 修饰的,返回的 delegate 对象则不会是 null。所以会走到 retry 包的代码逻辑中去。
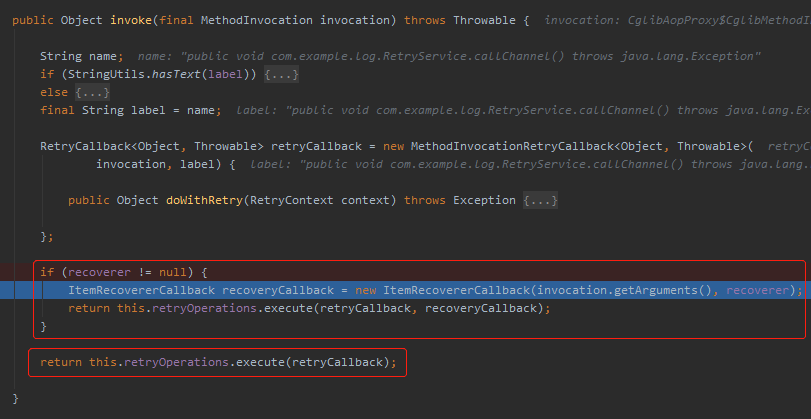
然后在 invoke 这里有个小细节,如果 recoverer 对象不为空,则执行带回调的。如果为空则执行没有 recoverCallback 对象方法。
我看到这几行代码的时候就大胆猜测: @Recover 注解并不是必须的。
于是我兴奋的把这个方法注解掉并再次运行项目,发现还真是,有点不一样了:
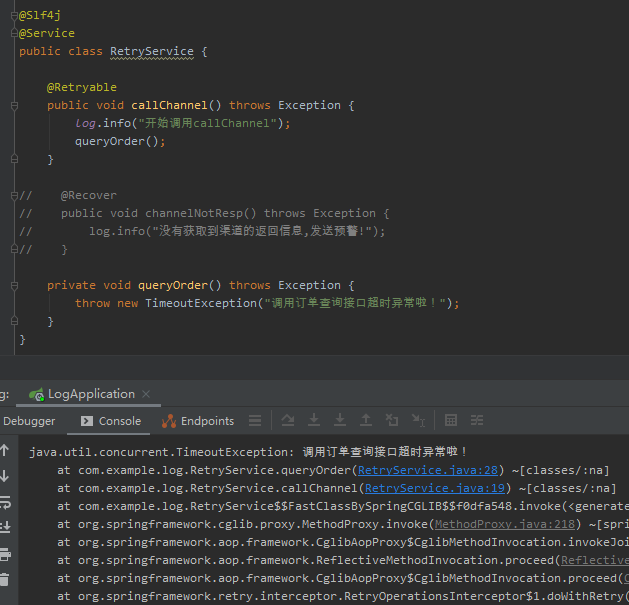
在我没有看其他文章、没有看官方介绍,仅通过一个简单的示例就发掘到他的一个用法之后,这属于意外收获,也是看源码的一点小乐趣。
其实源码并没有那么可怕的。

但是看到这里的时候另外一个问题就随之而来了:
这个 recoverer 对象看起来就是我写的 channelNotResp 方法,但是它是在什么时候解析到的呢?
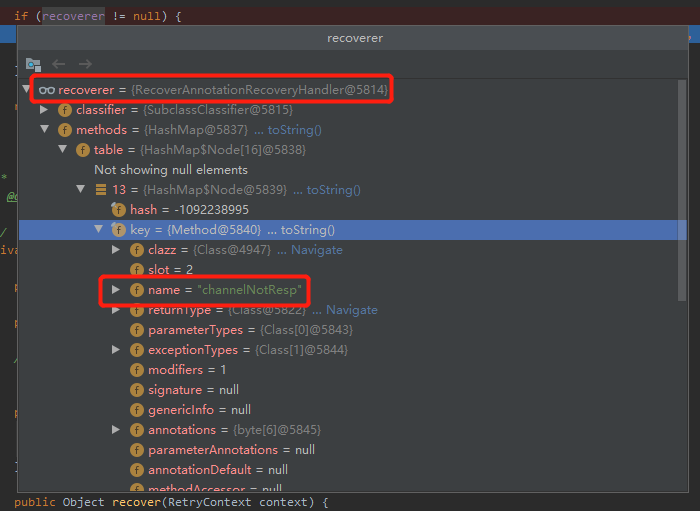
按下不表,后面再说,当务之急是找到重试的地方。
在当前的这个方法中再往下走几步,很快就能到我前面说的 while 循环中来:
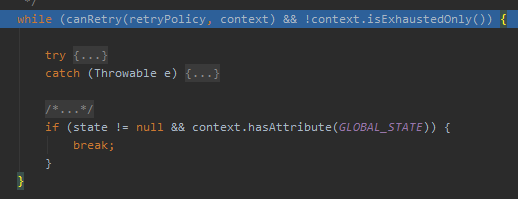
主要关注这个 canRetry 方法:
org.springframework.retry.RetryPolicy#canRetry
点进去之后,发现是一个接口,拥有多个实现:
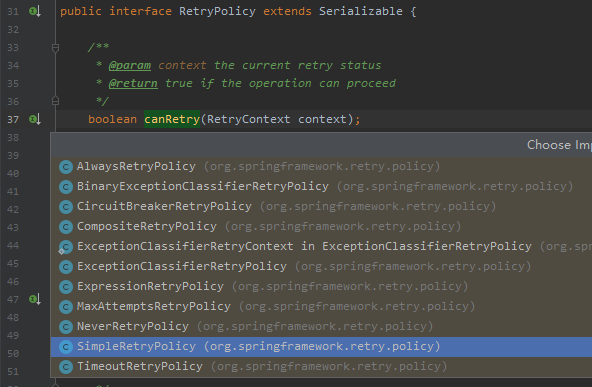
简单的介绍一下其中的几种含义是啥:
AlwaysRetryPolicy:允许无限重试,直到成功,此方式逻辑不当会导致死循环 NeverRetryPolicy:只允许调用RetryCallback一次,不允许重试 SimpleRetryPolicy:固定次数重试策略,默认重试最大次数为3次,RetryTemplate默认使用的策略 TimeoutRetryPolicy:超时时间重试策略,默认超时时间为1秒,在指定的超时时间内允许重试 ExceptionClassifierRetryPolicy:设置不同异常的重试策略,类似组合重试策略,区别在于这里只区分不同异常的重试 CircuitBreakerRetryPolicy:有熔断功能的重试策略,需设置3个参数openTimeout、resetTimeout和delegate CompositeRetryPolicy:组合重试策略,有两种组合方式,乐观组合重试策略是指只要有一个策略允许即可以重试,悲观组合重试策略是指只要有一个策略不允许即不可以重试,但不管哪种组合方式,组合中的每一个策略都会执行
那么这里问题又来了,我们调试源码的时候这么有多实现,我怎么知道应该进入哪个方法呢?
记住了,接口的方法上也是可以打断点的。你不知道会用哪个实现,但是 idea 知道:
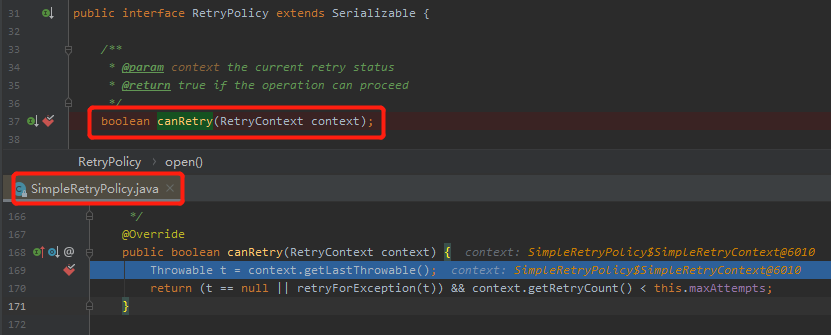
这里就是用的 SimpleRetryPolicy 策略,即这个策略是 Spring-retry 的默认重试策略。
t == null || retryForException(t)) && context.getRetryCount() < this.maxAttempts
这个策略的逻辑也非常简单:
1.如果有异常,则执行 retryForException 方法,判断该异常是否可以进行重试。 2.判断当前已重试次数是否超过最大次数。
在这里,我们找到了控制重试逻辑的地方。
上面的第二点很好理解,第一点说明这个注解和事务注解 @Transaction 一样,是可以对指定异常进行处理的,可以看一眼它支持的选项:
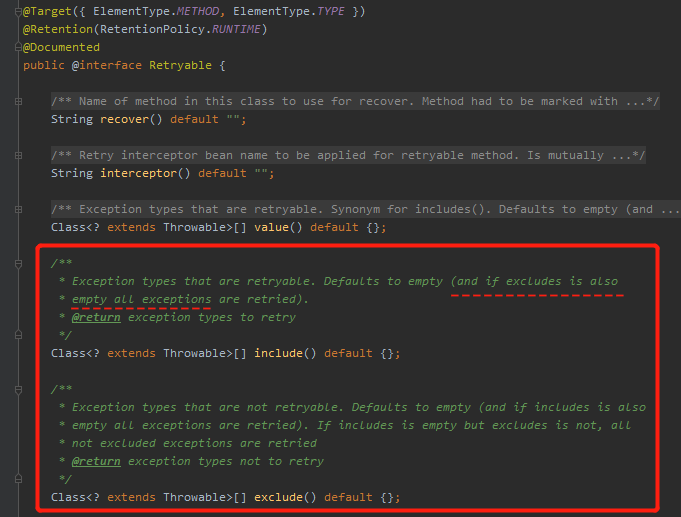
注意 include 里面有句话我标注了起来,意思是说,这个值默认为空。且当 exclude 也为空时,默认是所有异常。
所以 Demo 里面虽然什么都没配,但是抛出 TimeoutException 也会触发重试逻辑。
又是一个通过翻源码挖掘到的知识点,这玩意就像是探索彩蛋似的,舒服。
看完判断是否能进行重试调用的逻辑之后,我们接着看一下真正执行业务方法的地方:
org.springframework.retry.RetryCallback#doWithRetry
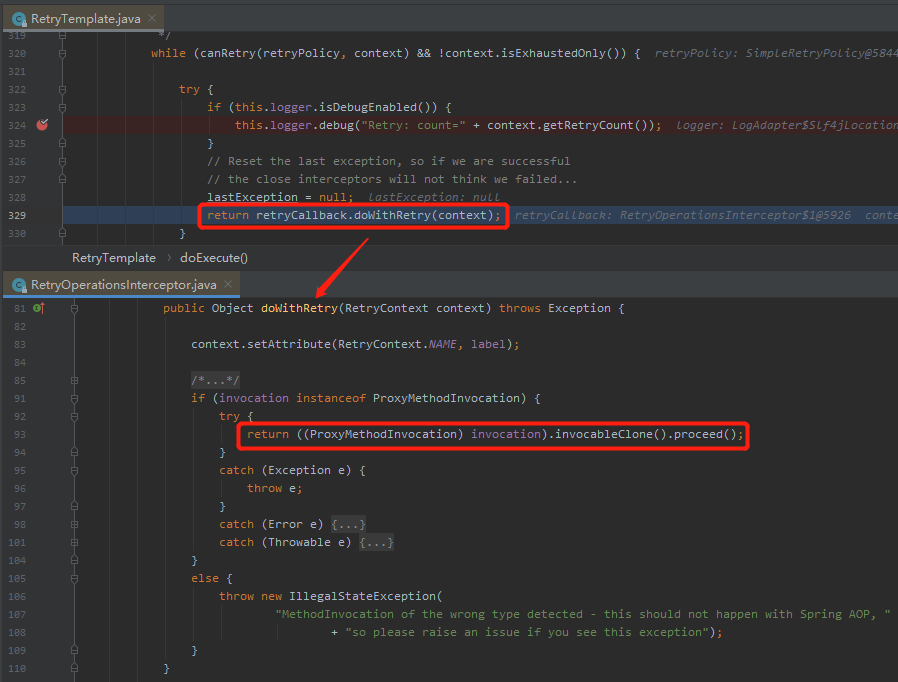
一眼就能看出来了,这里面就是应该非常熟悉的动态代理机制,这里的 invocation 就是我们的 callChannel 方法:
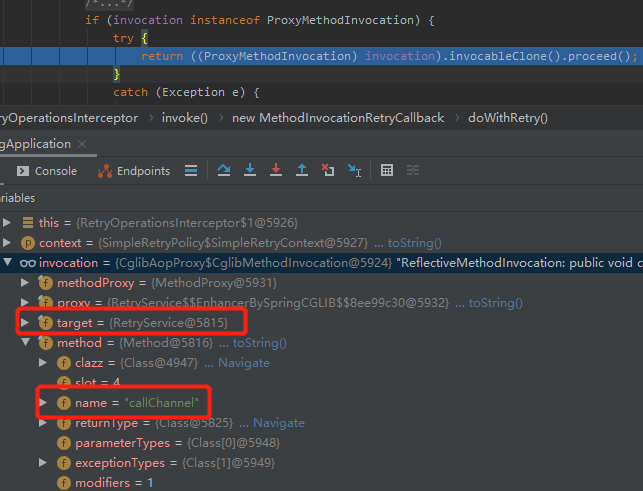
从代码我们知道,callChannel 方法抛出的异常,在 doWithRetry 方法里面会进行捕获,然后直接扔出去:
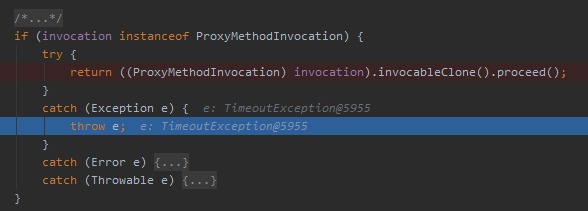
这里其实也很好理解的,因为需要抛出异常来触发下一次的重试。
但是这里也暴露了一个 Spring-retry 的弊端,就是必须要通过抛出异常的方式来触发相关业务。
听着好像也是没有毛病,但是你想想一下,假设渠道方说如果我给你返回一个 500 的 ErrorCode,那么你也可以进行重试。
这样的业务场景应该也是比较多的。
如果你要用 Spring-retry 会怎么做?
是不是得写出这样的代码:
if(errorCode==500){
throw new Exception("手动抛出异常");
}
意思就是通过抛出异常的方式来触发重试逻辑,算是一个不是特别优雅的设计吧。
其实根据返回对象中的某个属性来判断是否需要重试对于这个框架来说扩展起来也不算很难的事情。
你想,它这里本来就能拿到返回。只需要提供一个配置的入口,让我们告诉它当哪个对象的哪个字段为某个值的时候也应该进行重试。
当然了,大佬肯定有自己的想法,我这里都是一些不成熟的拙见而已。其实另外的一个重试框架 Guava-Retry,它就支持根据返回值进行重试。
不是本文重点就不扩展了。
接着往下看 while 循环中捕获异常的部分。
里面的逻辑也不复杂,但是下面框起来的部分可以注意一下:
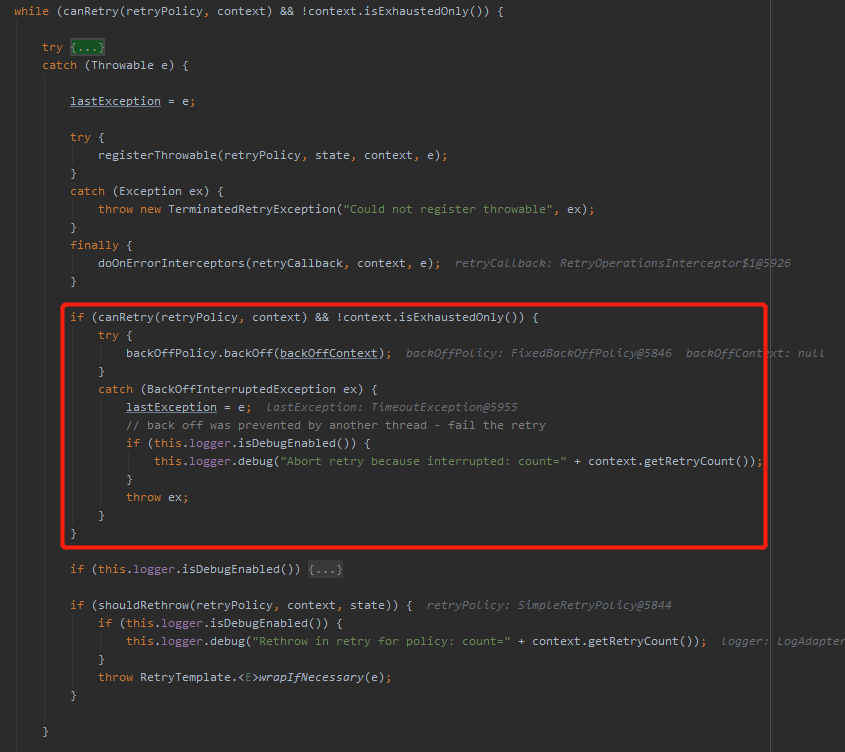
这里又判断了一次是否可以重试,是干啥呢?
是为了执行这行代码:
backOffPolicy.backOff(backOffContext);
它是干啥的?
我也不知道,debug 看一眼,最后会走到这个地方:
org.springframework.retry.backoff.ThreadWaitSleeper#sleep
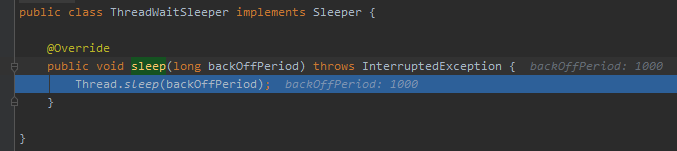
在这里执行睡眠 1000ms 的操作。
我一下就懂了,这玩意在这里给你留了个抓手,你可以设置重试间隔时间的抓手。然后默认给你赋能 1000ms 后重试的功能。

然后我在 @Retryable 注解里面找到了这个东西:
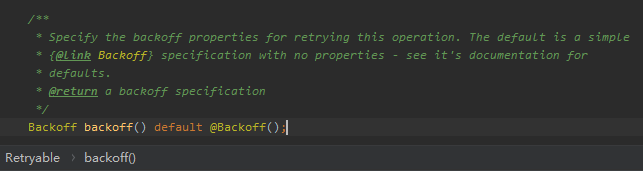
这玩意一眼看不懂是怎么配置的,但是它上面的注解叫我看看 Backoff 这个玩意。
它长这样:
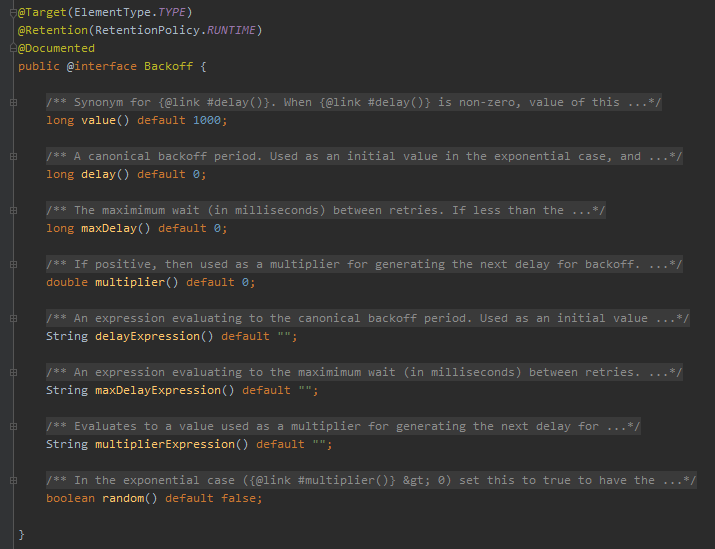
这东西看起来就好理解多了,先不管其他的参数吧,至少我看到了 value 的默认值是 1000。
我怀疑就是这个参数控制的指定重试间隔,所以我试了一下:
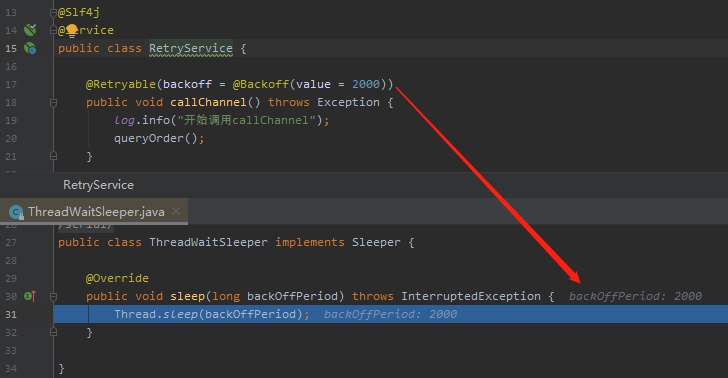
果然是你小子,又让我挖到一个彩蛋。
在 @Backoff 里面,除了 value 参数,还有很多其他的参数,他们的含义分别是这样的:
delay:重试之间的等待时间(以毫秒为单位) maxDelay:重试之间的最大等待时间(以毫秒为单位) multiplier:指定延迟的倍数 delayExpression:重试之间的等待时间表达式 maxDelayExpression:重试之间的最大等待时间表达式 multiplierExpression:指定延迟的倍数表达式 random:随机指定延迟时间
就不一一给你演示了,有兴趣自己玩去吧。
因为丰富的重试时间配置策略,所以也根据不同的策略写了不同的实现:
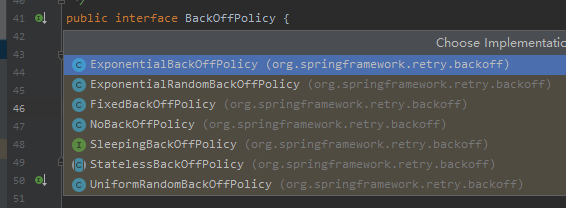
通过 Debug 我知道了默认的实现是 FixedBackOffPolicy。
其他的实现就不去细研究了,我主要是抓主要链路,先把整个流程打通,之后自己玩的时候再去看这些枝干的部分。
在 Demo 的场景下,等待一秒钟之后再次发起重试,就又会再次走一遍 while 循环,重试的主链路就这样梳理清楚了。
其实我把代码折叠一下,你可以看到就是在 while 循环里面套了一个 try-catch 代码块而已:
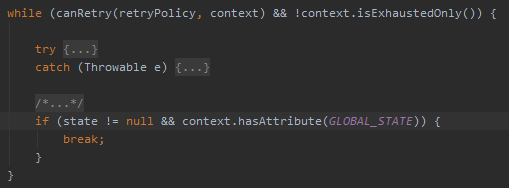
这和我们之前写的丑代码的骨架是一样的,只是 Spring-retry 把这部分代码进行扩充并且藏起来了,只给你提供一个注解。
当你只拿到这个注解的时候,你把它当做一个黑盒用的时候会惊呼:这玩意真牛啊。
但是现在当你抽丝剥茧的翻一下源码之后,你就会说:就这?不过如此,我觉得也能写出来啊。

到这里前面抛出的问题中的前两个已经比较清晰了:
问题一:找到它的 for 循环在哪里。
没有 for 循环,但是有个 while 循环,其中有一个 try-catch。
问题二:它是怎么判断应该要重试的?
判断要触发重试机制的逻辑还是非常简单的,就是通过抛出异常的方式触发。
但是真的要不要执行重试,才是一个需要仔细分析的重点。
Spring-retry 有非常多的重试策略,默认是 SimpleRetryPolicy,重试次数为 3 次。
但是需要特别注意的是它这个“3次”是总调用次数为三次。而不是第一次调用失败后再调用三次,这样就共计 4 次了。关于到底调用几次的问题,还是得分清楚才行。
而且也不一定是抛出了异常就肯定会重试,因为 Spring-retry 是支持对指定异常进行处理或者不处理的。
可配置化,这是一个组件应该具备的基础能力。
还是剩下最后一个问题:它是怎么执行到 @Recover 逻辑的?
接着怼源码吧。
Recover逻辑
首先要说明的是 @Recover 注解并不是一个必须要有的东西,前面我们也分析了,就不再赘述。
但是这个功能用起来确实是不错的,绝大部分异常都应该有对应的兜底措施。
这个东西,就是来执行兜底的动作的。
它的源码也非常容易找到,就紧跟在重试逻辑之后:
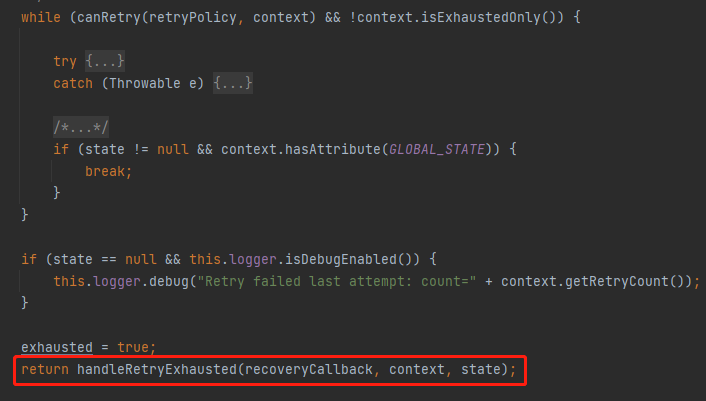
往下 Debug 几步你就会走到这个地方来:
org.springframework.retry.annotation.RecoverAnnotationRecoveryHandler#recover
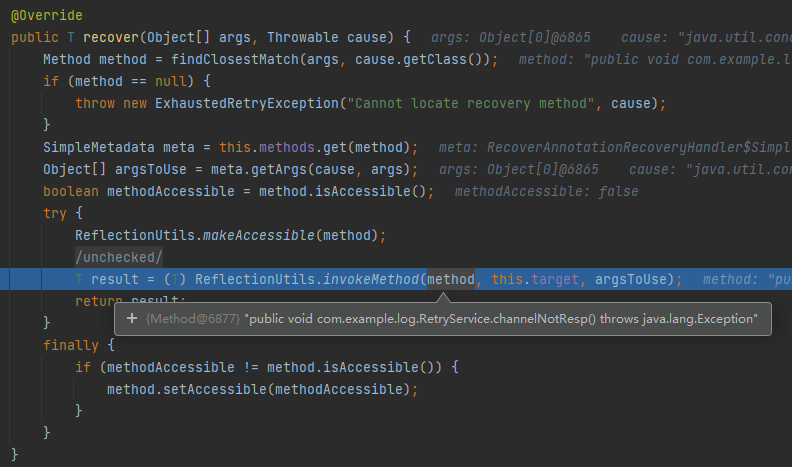
又是一个反射调用,这里的 method 已经是 channelNotResp 方法了。
那么问题就来了:Spring-retry 是怎么知道我的重试方法就是 channelNotResp 的呢?
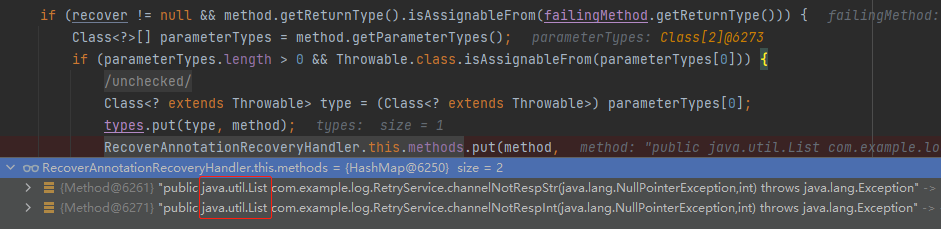
仔细看上面的截图中的 method 对象,不难发现它是方法的第一行代码产生的:
Method method = findClosestMatch(args, cause.getClass());
这个方法从名字和返回值上看叫做找一个最相近的方法。但是具体不太明白啥意思。
跟进去看一眼它在干啥:
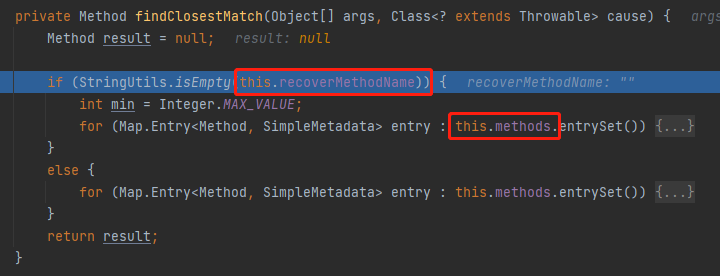
这个里面有两个关键的信息,一个叫做 recoverMethodName,当这个值为空和不为空的时候走的是两个不同的分支。
还有一个参数是 methods,这是一个 HashMap:
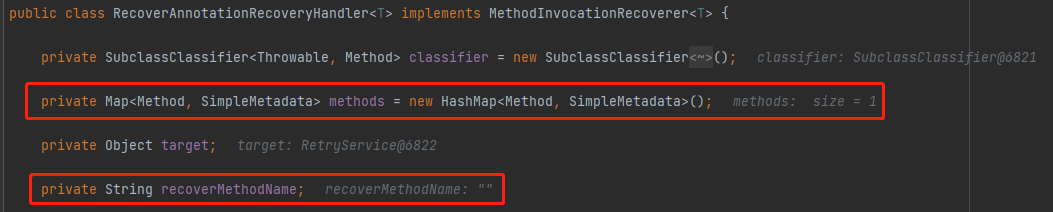
这个 Map 里面放的就是我们的兜底方法 channelNotResp:

而这个 Map 不论是走哪个分支都是需要进行遍历的。
这个 Map 里面的 channelNotResp 是什么时候放进去的呢?
很简单,看一下这个 Map 的 put 方法调用的地方就完事了:
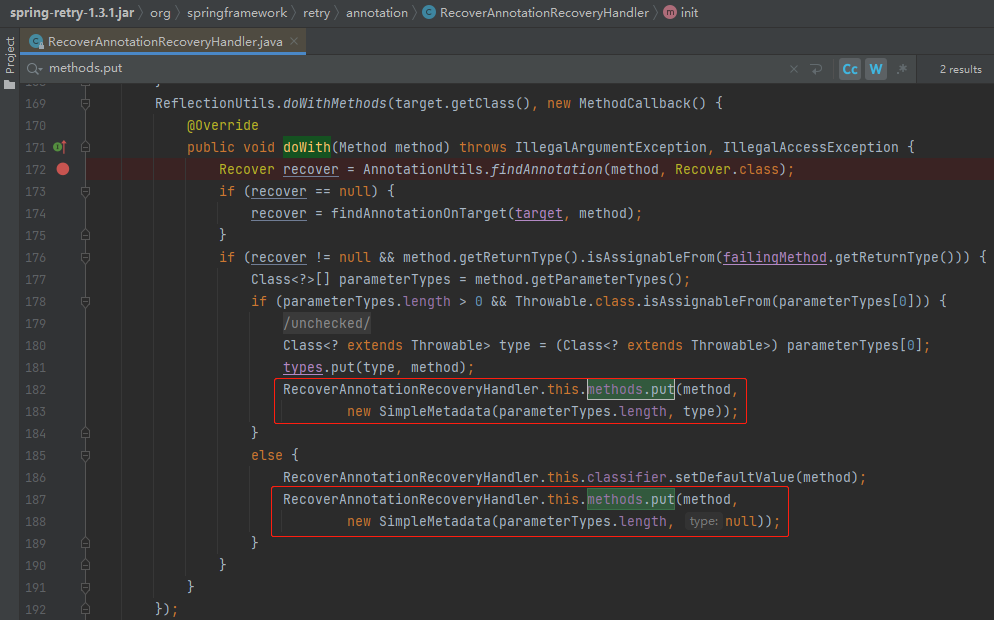
就这两个 put 的地方,源码位于下面这个方法中:
org.springframework.retry.annotation.RecoverAnnotationRecoveryHandler#init
从截图中可以看出,这里是在找 class 里面有没有被 @Recover 注解修饰的方法。
我在第 172 行打上断点,调试一下看一下具体的信息,你就知道这里是在干什么了。
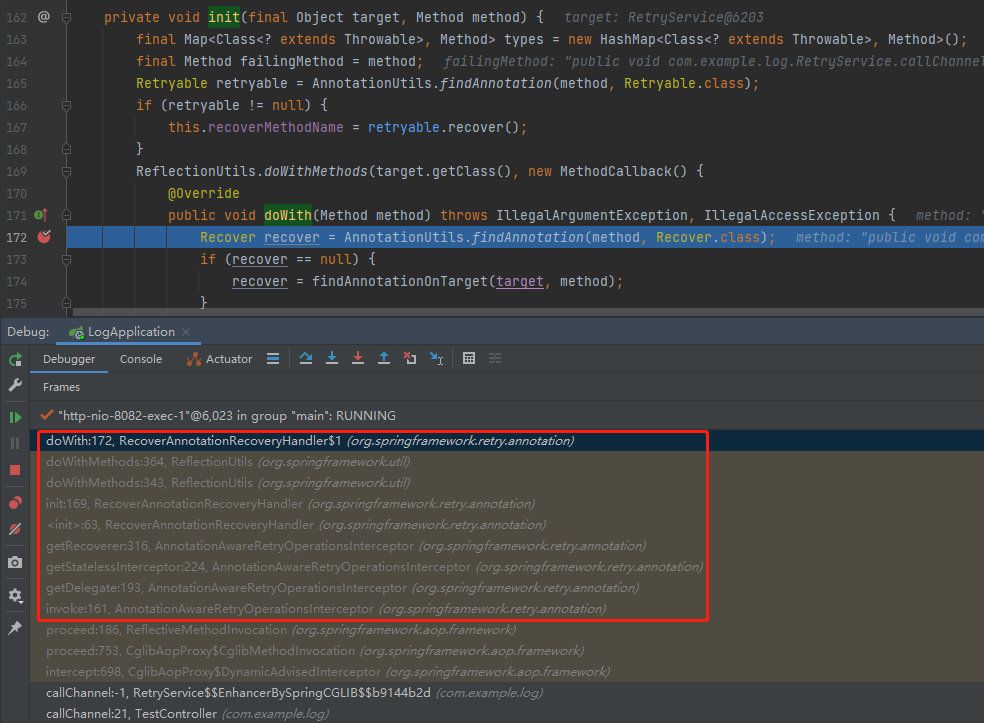
在你发起调用之后,程序会在断点处停下,至于是怎么走到这里的,前面说过,看调用堆栈,就不再赘述了。
关于这个 doWith 方法,我们把调用堆栈往上看一步,就知道这里是在解析我们的 RetryService 类里面的所有方法:
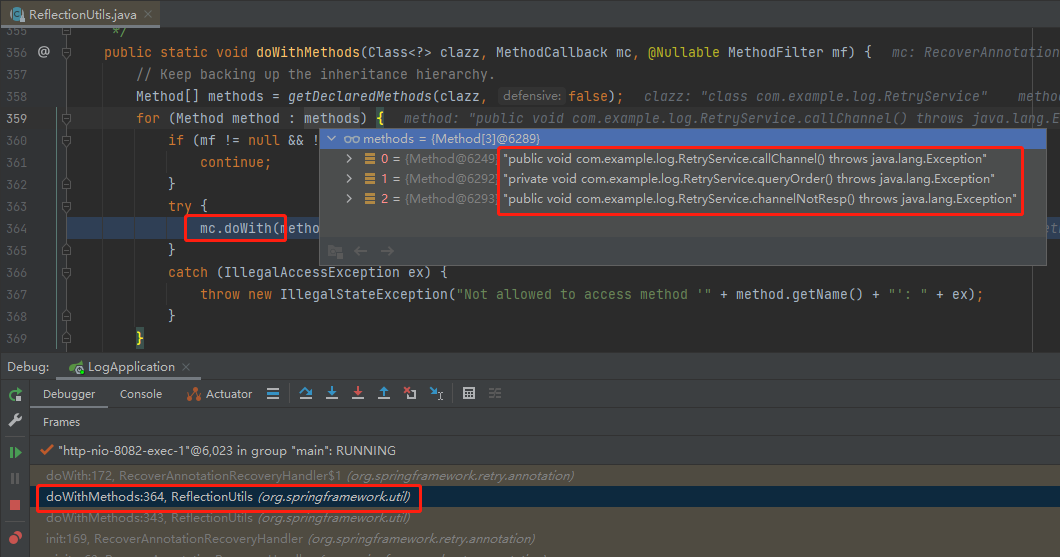
当解析到 channelNotResp 方法的时候,会识别出该方法上标注了 @Recover 注解。
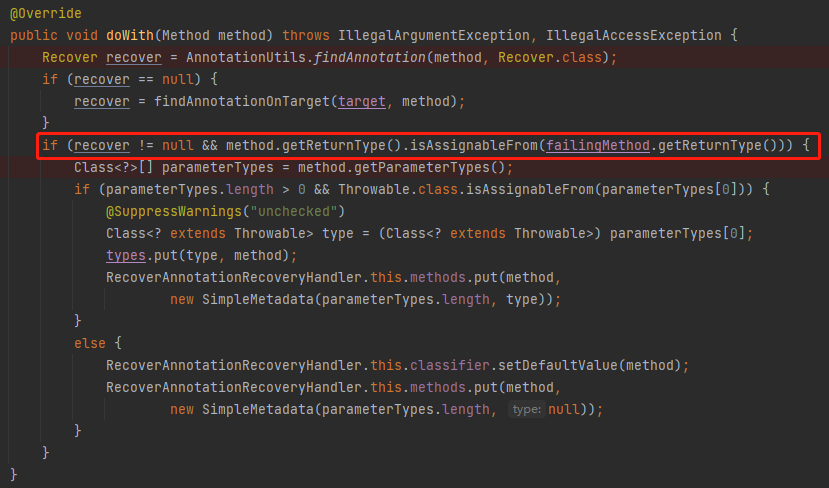
但从源码上看,要进行进一步解析,要满足 if 条件。而 if 条件除了要有 Recover 之外,还需要满足这个东西:
method.getReturnType().isAssignableFrom(failingMethod.getReturnType())
isAssignableFrom 方法是判断是否为某个类的父类。
就是的 method 和 failingMethod 分别如下:
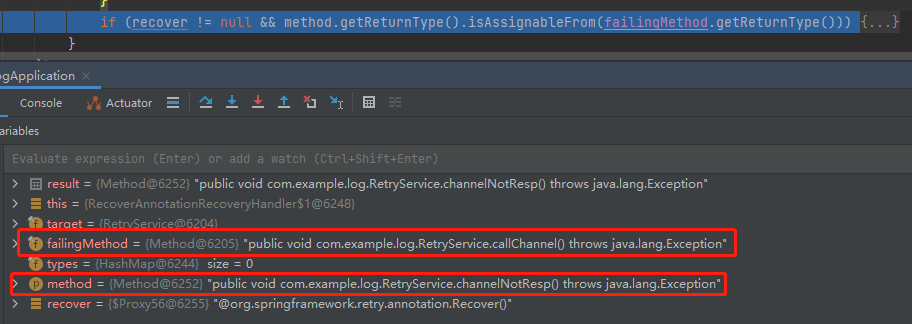
这是在检查被 @Retryable 标注的方法和被 @Recover 标注的方法的返回值是否匹配,只有返回值匹配才说明这是一对,应该进行解析。
比如,我把源码改成这样:

当它解析到 channelNotRespStr 方法的时候,会发现虽然被 @Recover 注解修饰了,但是返回值并不一致,从而知道它并不是目标方法 callChannel 的兜底方法。
源码里面的常规套路罢了。
再加入一个 callChannelSrt 方法,在上面的源码中 Spring-retry 就能帮你解析出谁和谁是一对:
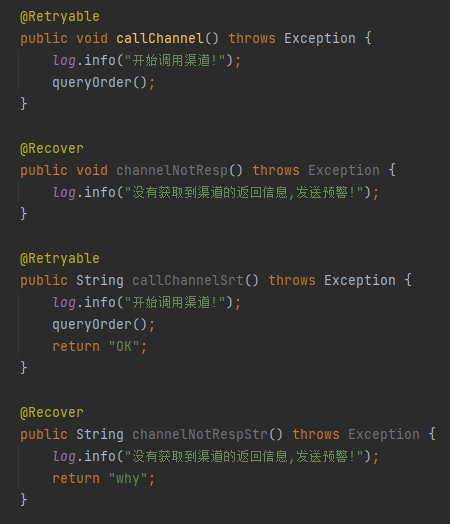
接着看一下如果满足条件,匹配上了,if 里面在干啥呢?
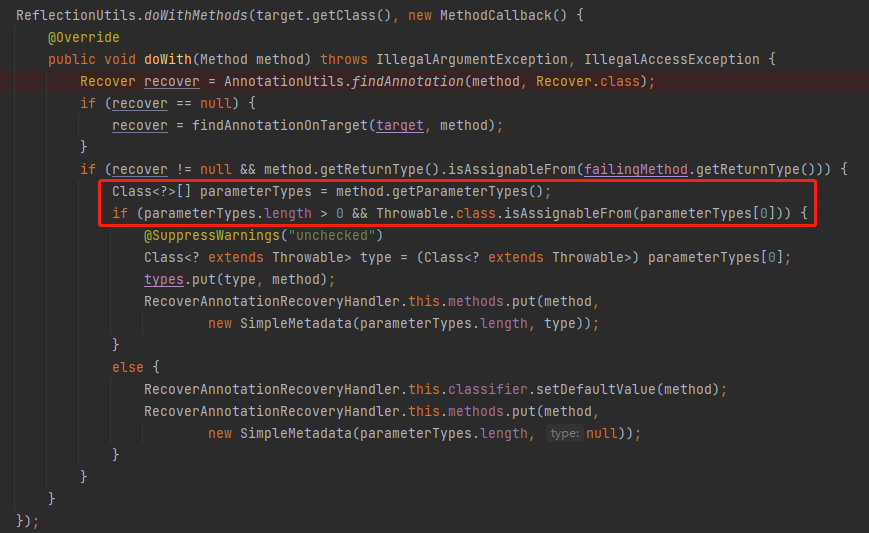
这是在获取方法上的入参呀,但是仔细一看,也只是为了获取第一个参数,且这个参数要满足一个条件:
Throwable.class.isAssignableFrom(parameterTypes[0])
必须是 Throwable 的子类,也就说说它必须是一个异常。用 type 字段来承接,然后下面会把它给存起来。
第一次看的时候肯定没看懂这是在干啥,没关系,我看了几次看明白了,给你分享一下,这里是为了这一小节最开始出现的这个方法服务的:
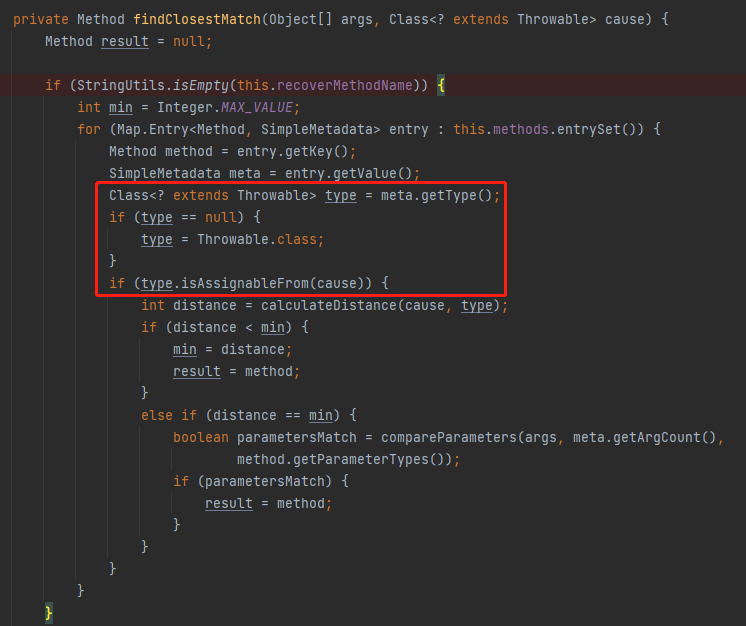
在这里面获取了这个 type,判断如果 type 为 null 则默认为 Throwable.class。
如果有值,就判断这里的 type 是不是当前程序抛出的这个 cause 的同类或者父类。
再强调一遍,从这个方法从名字和返回值上看,我们知道是要找一个最相近的方法,前面我说具体不太明白啥意思都是为了给你铺垫了一大堆 methods 这个 Map 是怎么来的。
其实我心里明镜儿似的,早就想扯下它的面纱了。

来,跟着我的思路马上就能看到葫芦里到底卖的是什么酒了。
你想,findClosestMatch,这个 Closest 是 Close 的最高级,表示最接近的意思。
既然有最接近,那么肯定是有几个东西放在一起,这里面只有一个是最符合要求的。
在源码中,这个要求就是“cause”,就是当前抛出的异常。
而“几个东西”指的就是这个 methods 装的东西里面的 type 属性。
还是有点晕,对不对,别慌,下面这张图片一出来,马上就不晕了:
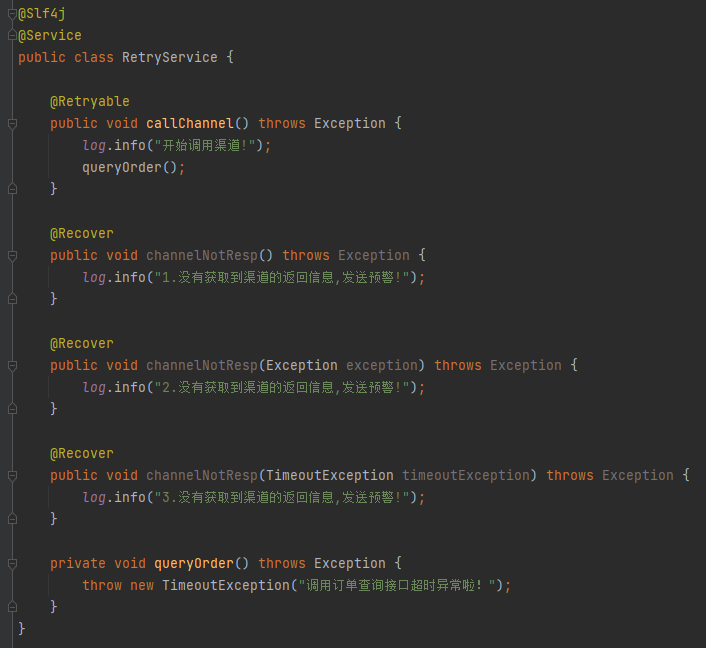
拿这个代码去套“Closest”这个玩意。
首先,cause 就是抛出的 TimeoutException。
而 methods 这个 Map 里面装的就是三个被 @Recover 注解修饰的方法。
为什么有三个?
好问题,说明我前面写的很烂,导致你看的不太明白。没事,我再给你看看往 methods 里面 put 东西的部分的代码:
这三个方法都满足被 @Recover 注解的条件,且同时也满足返回值和目标方法 callChannel 的返回值一致的条件。那就都得往 methods 里面 put,所以是三个。
这里也解释了为什么兜底方法是用一个 Map 装着呢?
我最开始觉得这是“兜底方法”的兜底策略,因为永远要把用户当做那啥,你不知道它会写出什么神奇的代码。
比如我上面的例子,其实最后生效的一定是这个方法:
@Recover
public void channelNotResp(TimeoutException timeoutException) throws Exception {
log.info("3.没有获取到渠道的返回信息,发送预警!");
}
因为它是 Closest。
给你截个图,表示我没有乱说:

但是,校稿的时候我发现这个地方不对,并不是用户那啥,而是真的有可能会出现一个 @Retryable 修饰的方法,针对不同的异常有不同的兜底方法的。
比如下面这样:
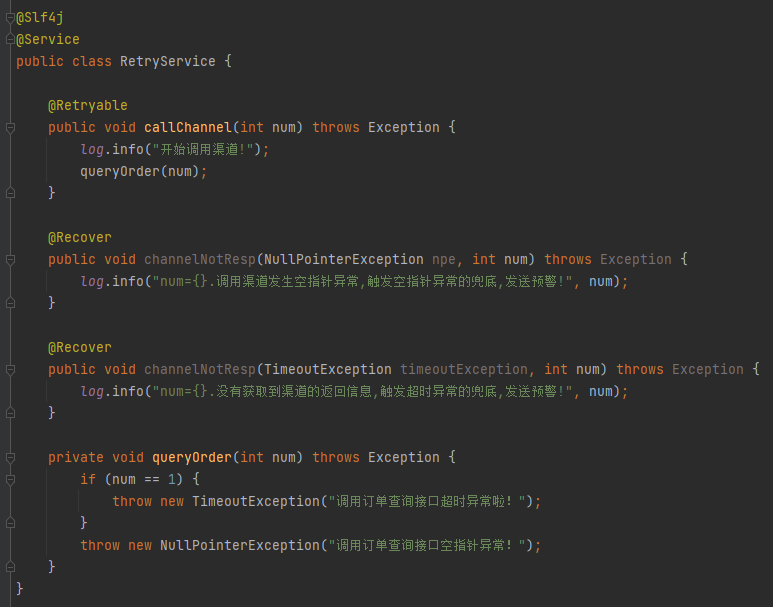
当 num=1 的时候,触发的是超时兜底策略,日志是这样的:
http://localhost:8080/callChannel?num=1
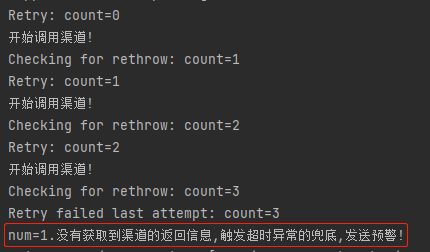
当 num>1 的时候,触发的是空指针兜底策略,日志是这样的:
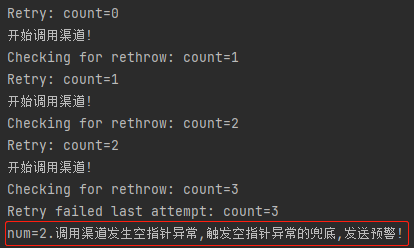
妙啊,真的是妙不可言啊。
看到这里我觉得对于 Spring-retry 这个组件算是入门了,有了一个基本的掌握,对于主干流程是摸的个七七八八,简历上可以用“掌握”了。
后续只需要把大的枝干处和细节处都摸一摸,就可以把“掌握”修改为“熟悉”了。

有点瑕疵
最后,再补充一个有点瑕疵的东西。
再看一下它处理 @Recover 的方法这里,只是对方法的返回值进行了处理:
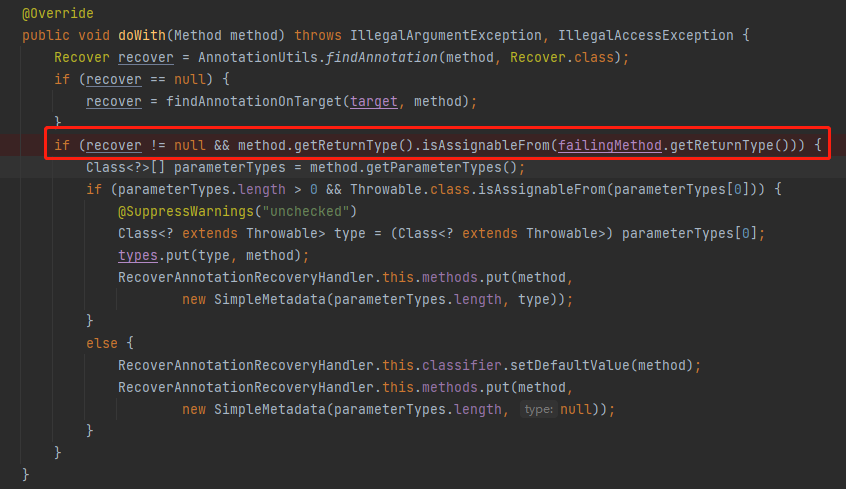
我当时看到这里的第一眼的时候就觉不对劲,少了对一种情况的判断,那就是:泛型。
比如我搞个这玩意:
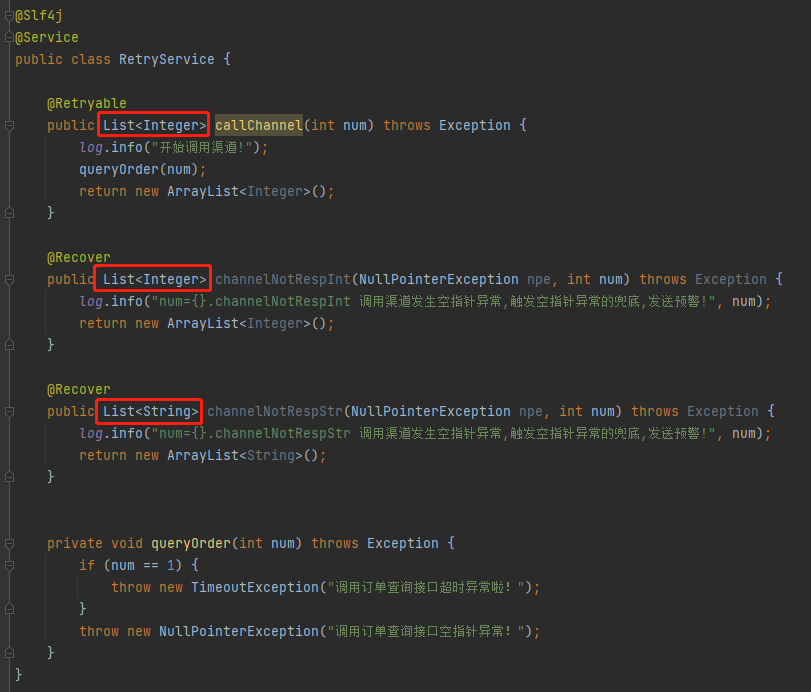
按理来说我希望的兜底策略是 channelNotRespInt 方法。
但是执行之后你就会发现,是有一定几率选到 channelNotRespStr 方法的:
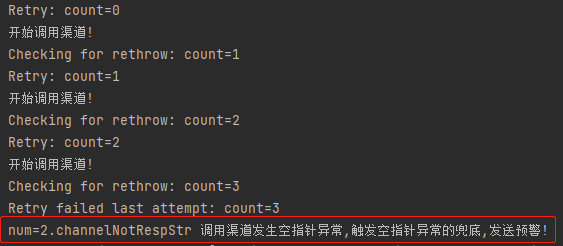
这玩意不对啊,我明明想要的是 channelNotRespInt 方法来兜底呀,为什么没有选正确呢?
因为泛型信息已经没啦,老铁:
假设我们要支持泛型呢?
从 github 上的描述来看,目前作者已经开始着力于这个方法的研究了:
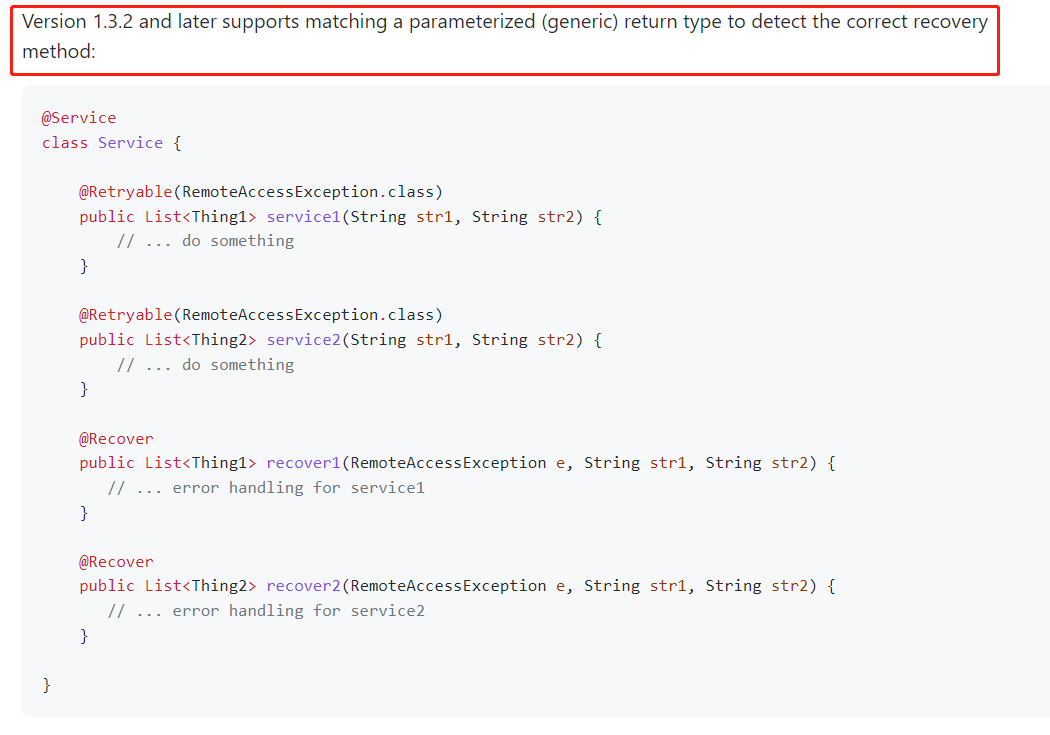
从 1.3.2 版本之后会支持泛型的。
但是目前 maven 仓库里面最高的版本还是在 1.3.1:
想看代码怎么办?
只有把源码拉下来看一眼了。
直接看这个类的提交记录:
org.springframework.retry.annotation.RecoverAnnotationRecoveryHandler
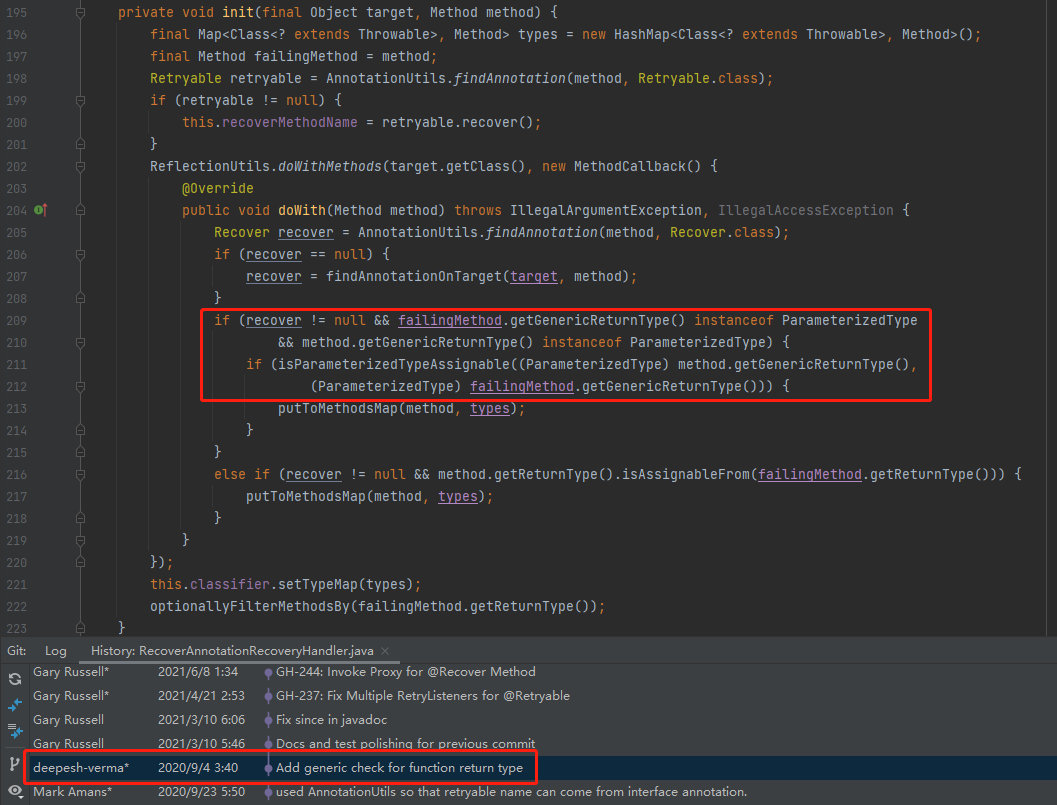
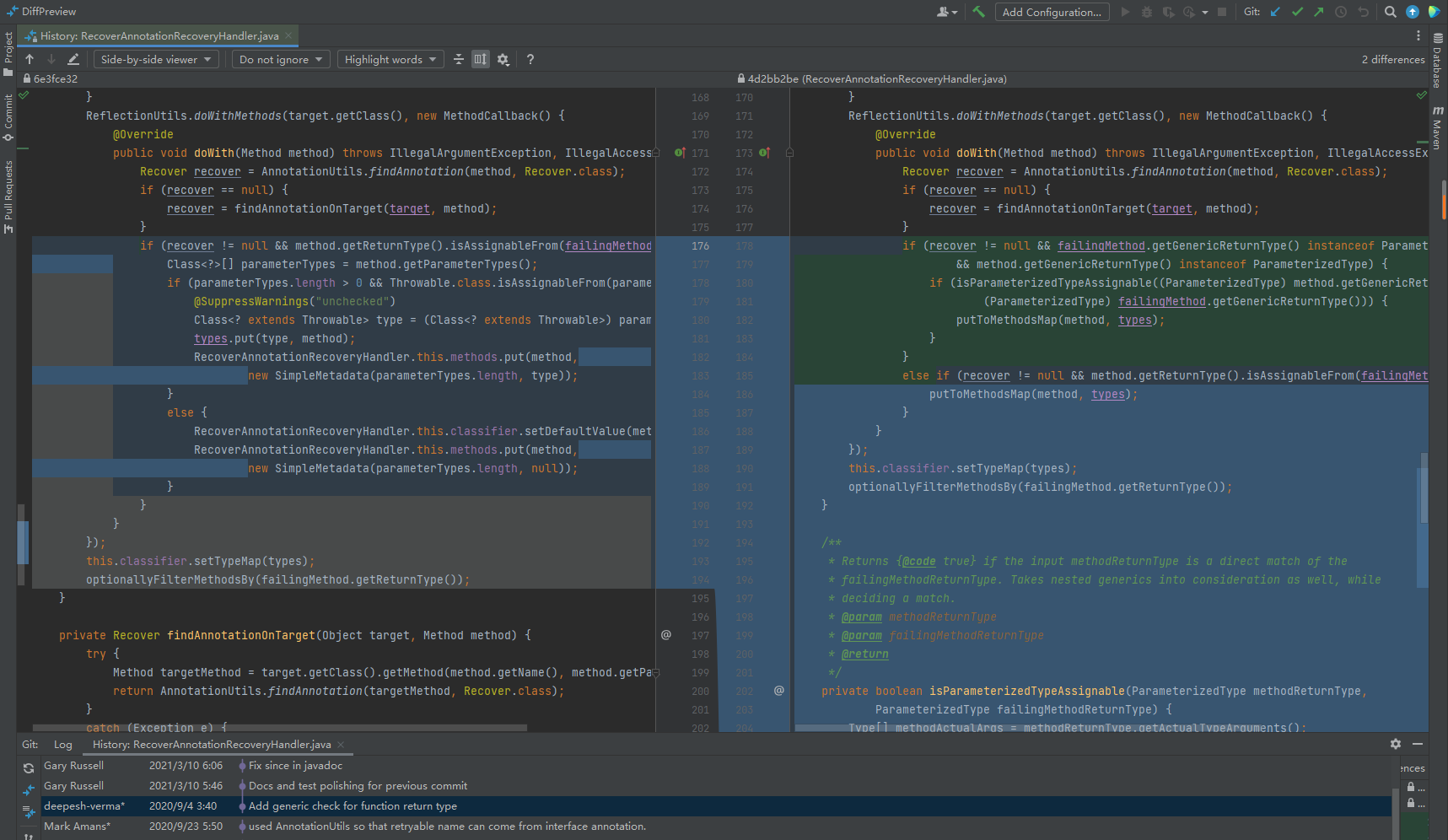
可以看到判断条件发生了变化,增加了对于泛型的处理。
我这里就是指个路,你要是有兴趣去研究就把源码拉下来看一下。具体是怎么实现的我就不写了,写的太长了也没人看,先留个坑在这里吧。
主要是写到这里的时候女朋友催着我去打乒乓球了。她属于是人菜瘾大的那种,昨天才把她给教会,今天居然扬言要打我个 11-0,看我不好好的削她一顿,杀她个片甲不留。

本文已收录至个人博客,里面全是优质原创,欢迎大家来瞅瞅:
https://www.whywhy.vip/
标签:retry,代码,这个,优雅,重试,源码,注解,Retryable,方法 来源: https://www.cnblogs.com/thisiswhy/p/15812946.html