实战大数据,HBase 性能调优指南
作者:互联网
1 HBase 表结构设计调优
1.1 Row Key 设计
HBase 中 row key 用来检索表中的记录,支持以下三种方式:
-
通过单个 row key 访问:即按照某个 row key 键值进行 get 操作;
-
通过 row key 的 range 进行 scan:即通过设置 startRowKey 和 endRowKey,在这个范围内进行扫描;
-
全表扫描:即直接扫描整张表中所有行记录。
在 HBase 中,row key 可以是任意字符串,最大长度 64KB,实际应用中一般为 10~100bytes,存为 byte[]字节数组,一般设计成定长的。
row key 是按照字典序存储,因此,设计 row key 时,要充分利用这个排序特点,将经常一起读取的数据存储到一块,将最近可能会被访问的数据放在一块。
举个例子:如果最近写入 HBase 表中的数据是最可能被访问的,可以考虑将时间戳作为 row key 的一部分,由于是字典序排序,所以可以使用 Long.MAX_VALUE - timestamp 作为 row key,这样能保证新写入的数据在读取时可以被快速命中。
Rowkey 规则:
-
rowkey 是一个二进制码流,长度越小越好,一般不超过 16 个字节,主要出于以下考虑:
-
数据的持久化文件 HFile 中是按照 KeyValue 存储的,即你写入的数据可能是一个 rowkey 对应多个列族,多个列,但是实际的存储是每个列都会对应 rowkey 写一遍,即这一条数据有多少个列,就会存储多少遍 rowkey,这会极大影响 HFile 的存储效率;
-
MemStore 和 BlockCache 都会将缓存部分数据到内存,如果 Rowkey 字段过长内存的有效利用率会降低,系统将无法缓存更多的数据,这会降低检索效率。
-
目前操作系统一般都是 64 位系统,内存 8 字节对齐。控制在 16 个字节,8 字节的整数倍,利用操作系统的最佳特性。
-
Rowkey 的设计是要根据实际业务来,常访问的数据放到一起。
对于需要批量获取的数据,比如某一天的数据,可以把一整天的数据存储在一起,即把 rowkey 的高位设计为时间戳,这样在读数据的时候就可以指定 start rowkey 和 end rowkey 做一个 scan 操作,因为高位相同的 rowkey 会存储在一起,所以这样读是一个顺序读的过程,会比较高效。
但是这样有一个很明显的问题,违背了“rowkey 散列设计”原则,很可能会出现数据倾斜问题。所以说没有最好的设计,具体如何权衡就得看实际业务场景了。
-
散列性
我们已知 HBase 的 Rowkey 是按照字典序排列的,而数据分布在 RegionServer 上的方式是做高位哈希,所以如果我们的 rowkey 首位存在大量重复的值那么很可能会出现数据倾斜问题,关于数据倾斜的问题下面会详细说明,总之,原则上就是 rowkey 的首位尽量为散列。
a) 取反 001 002 变为 100 200
b) Hash
-
唯一性:数据写入的时候两条数据的 rowkey 不能相同
1.2 Column Family
不要在一张表里定义太多的 column family。
目前 Hbase 并不能很好的处理超过 2~3 个 column family 的表。主要有以下两个方面考虑:
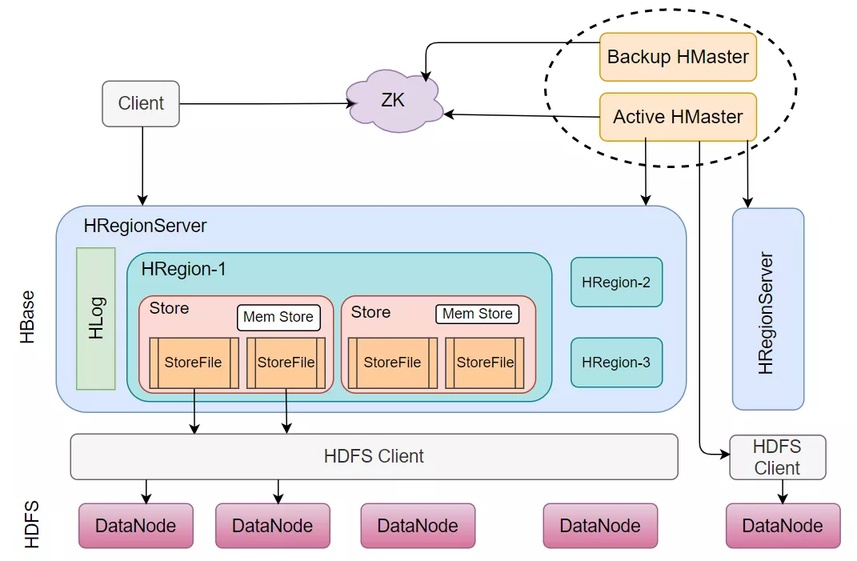
HBase 架构
-
如图,我们已知 Region 由一个或者多个 Store 组成,每个 Store 保存一个列族。当同一个 Region 内,如果存在大小列族的场景,即一个列族一百万行数据,另一个列族一百行数据,此时总数据量达到了 Region 分裂的阈值,那么不光那一百万行数据会被分布到不同的 Region 上,小列族的一百行数据也会分布到不同 region,问题就来了,扫描小列族都需要去不同的 Region 上读取数据,显然会影响性能。
-
在 memstore flush 时,某个大的 column family 在 flush 的时候,它邻近的小 column family 也会因关联效应被触发 flush,尽管小列族的 memstore 还没有达到 flush 的阈值,这样会导致小文件问题,也使得系统产生更多的 I/O。
1.3 表参数调优
Pre-Creating Regions(预分区)
默认情况下,在创建 HBase 表的时候会自动创建一个 region 分区,当导入数据的时候,所有的 HBase 客户端都向这一个 region 写数据,直到这个 region 足够大了才进行切分。这样的局限是很容易造成数据倾斜,影响读写效率。
预分区是一种比较好的解决这些问题的方案,通过预先创建一些空的 regions,定义好每个 region 存储的数据的范围,这样当数据写入 HBase 时,会按照 region 分区情况,在集群内做数据的负载均衡。
-
指定 rowkey 分割的点,手动设定预分区
create 'table1','f1',SPLITS => ['1000', '2000', '3000', '4000']
-
rowkey 前缀完全随机
create 'table2','f1', { NUMREGIONS => 8 , SPLITALGO => 'UniformSplit' }
-
rowkey 是十六进制的字符串作为前缀的
create 'table3','f1', { NUMREGIONS => 10, SPLITALGO => 'HexStringSplit' }BLOOMFILTER 布隆过滤器
默认值为 NONE,布隆过滤器的作用是可以过滤掉大部分不存在目标查询值的 HFile(即略去不必要的磁盘扫描),可以有助于降低读取延迟。
配置方式: create 'table',{BLOOMFILTER =>'ROW |``ROWCOL``'}
-
ROW,表示对 Rowkey 进行布隆过滤,Rowkey 的哈希值在每次写入行时会被添加到布隆过滤器中,在读的时候就会通过布隆过滤器过滤掉大部分无效目标。
-
ROWCOL 表示行键 + 列簇 + 列的哈希将在每次插入行时添加到布隆。
VERSIONS 版本
默认值为 1 ,大数据培训我们知道 HBase 是一个多版本共存的数据库,多次写入相同的 rowkey + cf + col 则会产生多个版本的数据,在有些场景下多版本数据是有用的,需要把写入的数据做一个对比或者其他操作;但是如果我们不想保留那么多数据,只是想要覆盖原有值,那么将此参数设为 1 能节约 2/3 的空间。所以第一步搞清楚你的需求,是否需要多版本共存。
配置方式: create 'table',{VERSIONS=>'2'}
COMPRESSION 压缩方式
默认值为 NONE ,常用的压缩方式是 Snappy 和 LZO,它们的特点是用于热数据压缩,占用 CPU 少,解压/压缩速度较其他压缩方式快,但是压缩率较低。Snappy 与 LZO 相比,Snappy 整体性能优于 LZO,解压/压缩速度更快,但是压缩率稍低。各种压缩各有不同的特点,需要根据需求作出选择。另外,不知道选什么的情况下,我建议选 Snappy,毕竟在 HBase 这种随机读写的场景,解压/压缩速度是比较重要的指标。
配置方式:create 'table',{NAME=>'info',COMPRESSION=>'snappy'}
Time To Live
创建表的时候,可以通过 HColumnDescriptor.setTimeToLive(int timeToLive) 设置表中数据的存储生命期,默认值为 Integer.MAX_VALUE ,大概是 64 年,即约等于不过期,这个参数是说明该列族数据的存活时间。超过存活时间的数据将在表中不再显示,待下次 major compact 的时候再彻底删除数据。需要根据实际情况配置。
配置方式: create 'table',{NAME=>'info', FAMILIES => [{NAME => 'cf', MIN_VERSIONS => '0', TTL => '500'}]}
Memory
创建表的时候,可以通过 HColumnDescriptor.setInMemory(true) 将表放到 RegionServer 的缓存中,保证在读取的时候被 cache 命中。
BLOCKCACHE 是读缓存,如果该列族数据顺序访问偏多,或者为不常访问的冷数据,那么可以关闭这个 blockcache,这个配置需要谨慎配置,因为对读性能会有很大影响。
配置方式:create 'mytable',{NAME=>'cf',BLOCKCACHE=>'false'}
Compact & Split
在 HBase 中,数据在更新时首先写入 WAL 日志 (HLog) 和内存 (MemStore) 中,MemStore 中的数据是排序的,当 MemStore 累计到一定阈值时,就会创建一个新的 MemStore,并且将老的 MemStore 添加到 flush 队列,由单独的线程 flush 到磁盘上,成为一个 StoreFile。于此同时, 系统会在 zookeeper 中记录一个 redo point,表示这个时刻之前的变更已经持久化了 (minor compact)。
StoreFile 是只读的,一旦创建后就不可以再修改。因此 Hbase 的更新其实是不断追加的操作。当一个 Store 中的 StoreFile 达到一定的阈值后,就会进行一次合并 (major compact),将对同一个 key 的修改合并到一起,形成一个大的 StoreFile,当 StoreFile 的大小达到一定阈值后,又会对 StoreFile 进行分割 (split),等分为两个 StoreFile。
由于对表的更新是不断追加的,处理读请求时,需要访问 Store 中全部的 StoreFile 和 MemStore,将它们按照 row key 进行合并,由于 StoreFile 和 MemStore 都是经过排序的,并且 StoreFile 带有内存中索引,通常合并过程还是比较快的。
实际应用中,可以考虑必要时手动进行 major compact,将同一个 row key 的修改进行合并形成一个大的 StoreFile。同时,可以将 StoreFile 设置大些,减少 split 的发生。
hbase 为了防止小文件(被刷到磁盘的 menstore)过多,以保证保证查询效率,hbase 需要在必要的时候将这些小的 store file 合并成相对较大的 store file,这个过程就称之为 compaction。在 hbase 中,主要存在两种类型的 compaction:minor compaction 和 major compaction。
-
minor compaction: 是较小的、很少文件的合并。
minor compaction 的运行机制要复杂一些,它由一下几个参数共同决定:
hbase.hstore.compaction.min:默认值为 3,表示至少需要三个满足条件的 store file 时,minor compaction 才会启动hbase.hstore.compaction.max默认值为 10,表示一次 minor compaction 中最多选取 10 个 store filehbase.hstore.compaction.min.size表示文件大小小于该值的 store file 一定会加入到 minor compaction 的 store file 中hbase.hstore.compaction.max.size表示文件大小大于该值的 store file 一定会被 minor compaction 排除hbase.hstore.compaction.ratio将 store file 按照文件年龄排序(older to younger),minor compaction 总是从 older store file 开始选择 -
major compaction 的功能是将所有的 store file 合并成一个,触发 major compaction 的可能条件有:
major_compact 命令、
majorCompact() API、
region server 自动运行
相关参数:
hbase.hregion.majoucompaction默认为 24 小时、hbase.hregion.majorcompaction.jetter默认值为 0.2 防止 region server 在同一时间进行 major compaction
hbase.hregion.majorcompaction.jetter 参数的作用是:对参数 hbase.hregion.majoucompaction 规定的值起到浮动的作用,假如两个参数都为默认值 24 和 0.2,那么 major compact 最终使用的数值为:19.2~28.8 这个范围。
此外,hbase.regionserver.regionSplitLimit 最大的 region 数量,hbase.hregion.max.filesize 每个 region 的最大限制,这 2 个参数是用来控制 Region 分裂的。
在生产环境下,这两个操作一般都会设置为禁止自动合并和禁止自动 split,因为这两步的操作都是比较耗费资源的,自动会让操作时间不可控,如果是在业务繁忙的时间做了这些操作造成的影响是非常大的,所以一般配置禁止自动,转为自己管理,在系统没那么繁忙的晚上手动出发相关操作。
2 HBase 写调优
2.1 多 HTable 并发写
创建多个 HTable 客户端用于写操作,提高写数据的吞吐量。举一个例子:
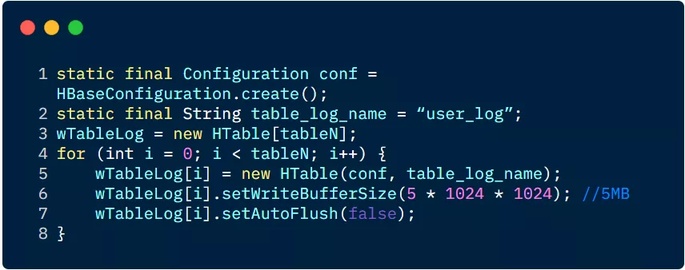
2.2 HTable 写参数设置
2.2.1 Auto Flush
通过调用 HTable.setAutoFlush(false) 方法可以将 HTable 写客户端的自动 flush 关闭,这样可以批量写入数据到 HBase,而不是有一条 put 就执行一次更新,只有当 put 填满客户端写缓存时,才实际向 HBase 服务端发起写请求。默认情况下 auto flush 是开启的。
2.2.2 Write Buffer
通过调用 HTable.setWriteBufferSize(writeBufferSize)方法可以设置 HTable 客户端的写 buffe r 大小,如果新设置的 buffer 小于当前写 buffer 中的数据时,buffer 将会被 flush 到服务端。其中,writeBufferSize 的单位是 byte 字节数,可以根据实际写入数据量的多少来设置该值。
2.2.3 WAL Flag
在 HBae 中,客户端向集群中的 RegionServer 提交数据时(Put/Delete 操作),首先会先写 WAL(Write Ahead Log)日志(即 HLog,一个 RegionServer 上的所有 Region 共享一个 HLog),只有当 WAL 日志写成功后,再接着写 MemStore,然后客户端被通知提交数据成功;如果写 WAL 日志失败,客户端则被通知提交失败。这样做的好处是可以做到 RegionServer 宕机后的数据恢复。
因此,对于相对不太重要的数据,可以在 Put/Delete 操作时,通过调用 Put.setWriteToWAL(false) 或 Delete.setWriteToWAL(false) 函数,放弃写 WAL 日志,从而提高数据写入的性能。
值得注意的是:谨慎选择关闭 WAL 日志,因为这样的话,一旦 RegionServer 宕机, Put/Delete 的数据将会无法根据 WAL 日志进行恢复。
2.3 批量写
通过调用 HTable.put(Put) 方法可以将一个指定的 row key 记录写入 HBase,同样 HBase 提供了另一个方法:通过调用 HTable.put(List) 方法可以将指定的 row key 列表,批量写入多行记录,这样做的好处是批量执行,只需要一次网络 I/O 开销,这对于对数据实时性要求高,网络传输 RTT 高的情景下可能带来明显的性能提升。
2.4 多线程并发写
在客户端开启多个 HTable 写线程,每个写线程负责一个 HTable 对象的 flush 操作,这样结合定时 flush 和写 buffer(writeBufferSize),可以既保证在数据量小的时候,数据可以在较短时间内被 flush(如 1 秒内),同时又保证在数据量大的时候,写 buffer 一满就及时进行 flush。下面给个具体的例子:
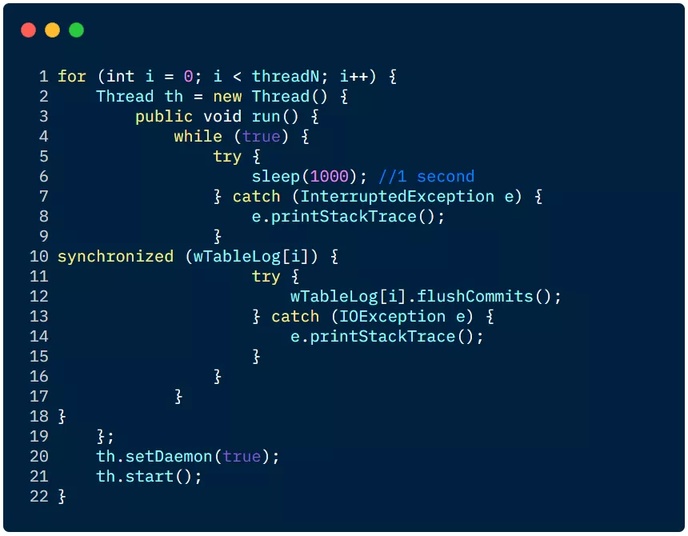
3 HBase 读调优
3.1 多 HTable 并发写
创建多个 HTable 客户端用于读操作,提高读数据的吞吐量,举一个例子:
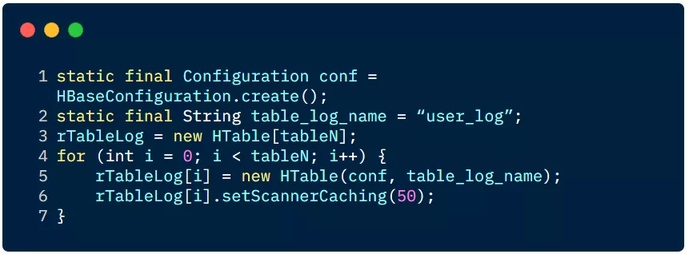
3.2 HTable 读参数设置
3.2.1 Scanner Caching
hbase.client.scanner.caching 配置项可以设置 HBase scanner 一次从服务端抓取的数据条数,默认情况下一次一条。通过将其设置成一个合理的值,可以减少 scan 过程中 next() 的时间开销,代价是 scanner 需要通过客户端的内存来维持这些被 cache 的行记录。
有三个地方可以进行配置:
-
在 HBase 的 conf 配置文件中进行配置;
-
通过调用 HTable.setScannerCaching(int scannerCaching) 进行配置;
-
通过调用 Scan.setCaching(int caching) 进行配置。
三者的优先级越来越高。
3.2.2 Scan Attribute Selection
scan 时指定需要的 Column Family,可以减少网络传输数据量,否则默认 scan 操作会返回整行所有 Column Family 的数据。
3.2.3 Close ResultScanner
通过 scan 取完数据后,记得要关闭 ResultScanner,否则 RegionServer 可能会出现问题(对应的 Server 资源无法释放)。
3.3 批量读
通过调用 HTable.get(Get) 方法可以根据一个指定的 row key 获取一行记录,同样 HBase 提供了另一个方法:通过调用 HTable.get(List) 方法可以根据一个指定的 row key 列表,批量获取多行记录,这样做的好处是批量执行,只需要一次网络 I/O 开销,这对于对数据实时性要求高而且网络传输 RTT 高的情景下可能带来明显的性能提升。
3.4 多线程并发读
在客户端开启多个 HTable 读线程,每个读线程负责通过 HTable 对象进行 get 操作。
下面是一个多线程并发读取 HBase,获取某电商网站上店铺一天内各分钟 PV 值的例子:
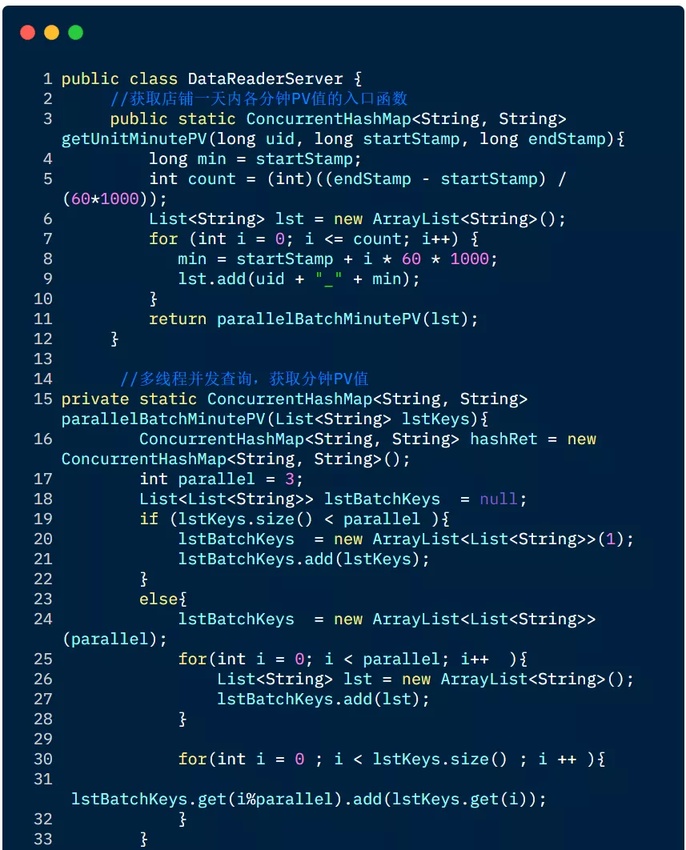
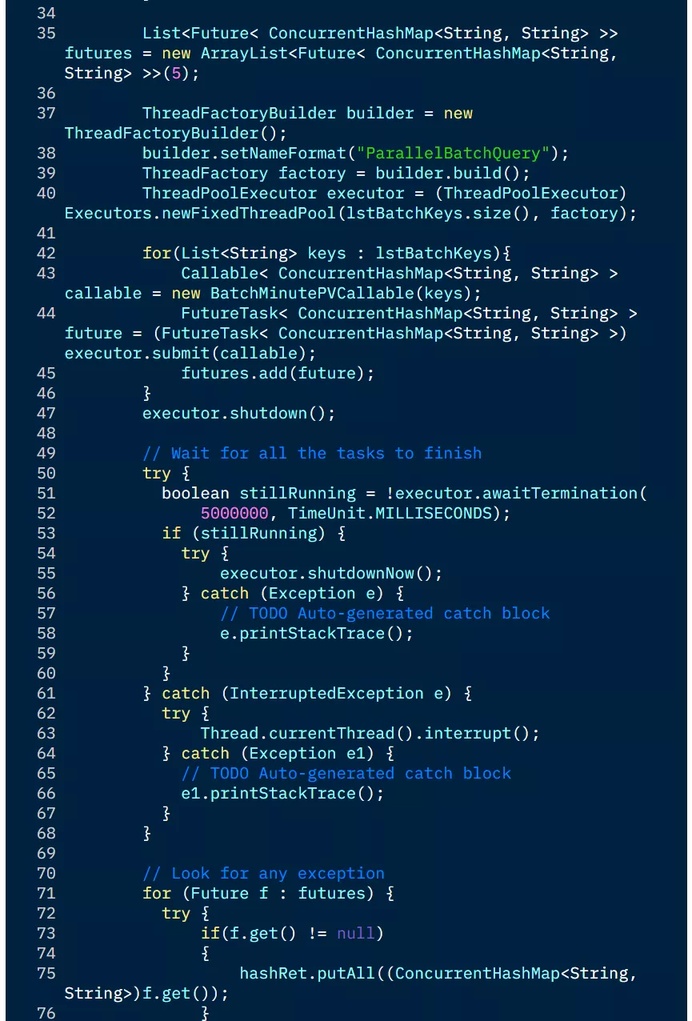
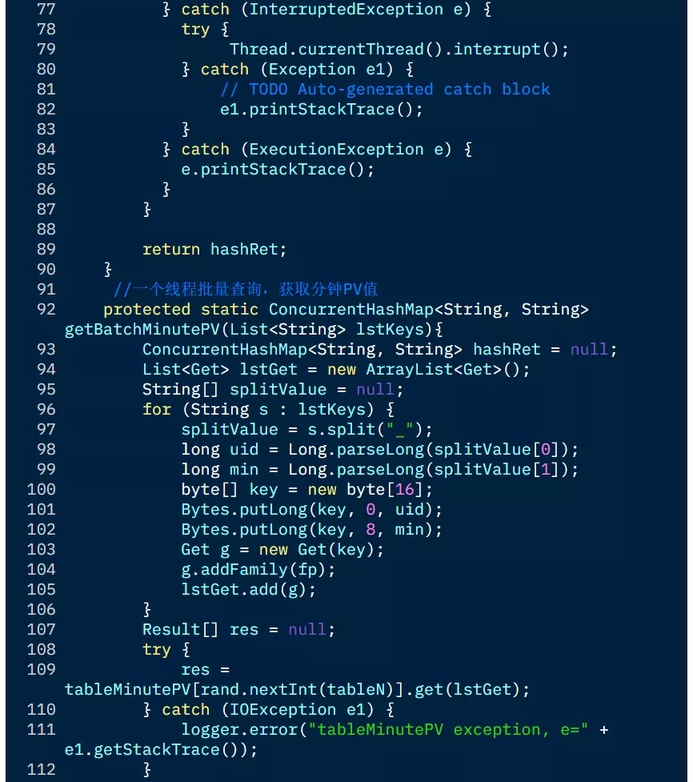
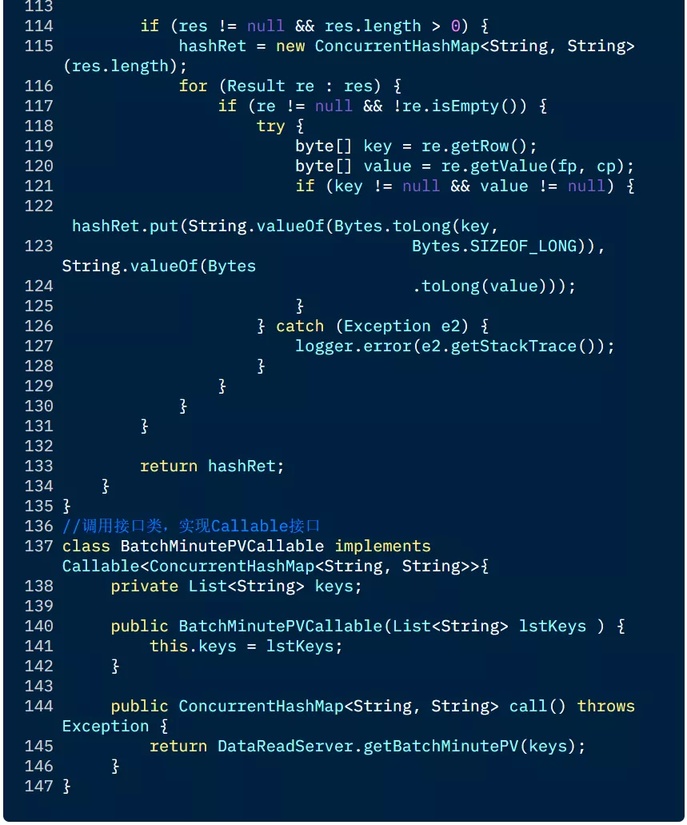
3.5 缓存查询结果
对于频繁查询 HBase 的应用场景,可以考虑在应用程序中做缓存,当有新的查询请求时,首先在缓存中查找,如果存在则直接返回,不再查询 HBase;否则对 HBase 发起读请求查询,然后在应用程序中将查询结果缓存起来,下次便可直接在缓存中查找。至于缓存的替换策略,可以考虑 LRU 等常用的策略。
3.6 BlockCache
HBase 上 Regionserver 的内存分为两个部分,一部分作为 Memstore,主要用来写;另外一部分作为 BlockCache,主要用于读。
-
写请求会先写入 Memstore,Regionserver 会给每个 region 提供一个 Memstore,当 Memstore 满 64MB 以后,会启动 flush 刷新到磁盘。当 Memstore 的总大小超过限制时(heapsize * hbase.regionserver.global.memstore.upperLimit * 0.9),会强行启动 flush 进程,从最大的 Memstore 开始 flush 直到低于限制。
-
读请求先到 Memstore 中查数据,查不到就到 BlockCache 中查,再查不到就会到磁盘上读,并把读的结果放入 BlockCache。由于 BlockCache 采用的是 LRU 策略,因此 BlockCache 达到上限 (heapsize * hfile.block.cache.size * 0.85) 后,会启动淘汰机制,淘汰掉最老的一批数据。
一个 Regionserver 上有一个 BlockCache 和 N 个 Memstore,它们的大小之和不能大于等于 heapsize * 0.8,否则 HBase 不能启动。默认 BlockCache 为 0.2,而 Memstore 为 0.4。
对于注重读响应时间的系统,可以将 **BlockCache ** 设大些,比如设置 BlockCache=0.4,Memstore=0.39,以加大缓存的命中率。
有关 BlockCache 机制,感兴趣的小伙伴可以去深入了解!
4 如何处理数据倾斜问题?
数据倾斜是分布式领域一个比较常见的问题,在大量客户端请求访问数据或者写入数据的时候,只有少数几个或者一个 RegionServer 做出响应,导致该服务器的负载过高,造成读写效率低下,而此时其他的服务器还是处于空闲的状态。
造成这种情况主要的原因就是数据分布不均匀,可能是数据量分布不均匀,也可能是冷热数据分布不均匀。而糟糕的 rowkey 设计就是发生热点即数据倾斜的源头,所以这里会详细说说避免数据倾斜的 rowkey 设计方法。
-
加盐:加盐即在原本的 rowkey 前面加上随机的一些值。
-
随机数:加随机数这种方式在各种资料中经常会被提到,就是在 rowkey 的前面增加随机数来打散 rowkey 在 region 的分布,但是我觉得这不是一种好的选择,甚至都不能作为一种选择,因为 HBase 的设计是只有 rowkey 是索引,rowkey 都变成随机的了,读数据只能做性能极低的全表扫描了。总之不推荐。
-
哈希:哈希的方式明显比随机数更好,哈希会使同一行永远用一个前缀加盐。同样可以起到打散 rowkey 在 region 的分布的目的,使负载分散到整个集群,最重要读是可以预测的。使用确定的哈希可以让客户端重构完整的 rowkey,可以使用 get 操作准确获取某一个行数据。
-
反转:反转即把低位的随机数反转到高位。比如手机号码或者时间戳的反转,高位基本固定是 1 开头的,而末位是随机的。这种同样是一种比较常规的构成散列的方式。
-
hbase 预分区:预分区上面已经提到过,这种方式对于处理数据量分布不均匀,和冷热数据分布不均匀都是有一定效果的,但是需要对业务的应用场景做好准确的预判。
标签:指南,HTable,调优,compaction,rowkey,HBase,数据,hbase 来源: https://www.cnblogs.com/msjhw/p/15744282.html