Linked In微服务异常告警关联中的尖峰检测
作者:互联网
LinkedIn 的技术栈由数千个不同的微服务以及它们之间相关联的复杂依赖项组成。当由于服务行为不当而导致生产中断时,找到造成中断的确切服务既具有挑战性又耗时。尽管每个服务在分布式基础架构中配置了多个警报,但在中断期间找到问题的真正根本原因就像大海捞针,即使使用了所有正确的仪器。这是因为客户端请求的关键路径中的每个服务都可能有多个活动警报。缺乏从这些不连贯的警报中获取有意义信息的适当机制通常会导致错误升级,从而导致问题解决时间增加。最重要的是,想象一下在半夜被 NOC 工程师吵醒,他们认为站点中断是由您的服务引起的,结果却意识到这是一次虚假升级,并非由您的服务引起。
为了克服这个问题,我们开发了警报相关性 (AC),旨在提高事件的平均检测时间 (MTTD)/平均解决时间 (MTTR)。 我们的目标是在给定时间内找出服务中断的根本原因,并主动通知服务所有者有关持续问题的信息,重点是降低整体 MTTD/MTTR,同时改善随叫随到体验。 警报关联主要基于从我们的监控系统收集的警报和指标,这为我们提供了服务健康状况的强烈信号。 通过使用我们的监控系统,我们可以利用现有的警报并从中获取更多警报,这为我们提供了强大的信噪比。
Alert Correlation 还利用了另一个称为 Callgraph 的重要服务,它负责了解服务的依赖关系。调用图是使用 LinkedIn 已经标准化的指标构建的。对于服务具有的每个依赖项,其所有下游和上游依赖项也具有相同的度量集,用于映射依赖项。 Callgraph 负责从每个服务中抓取指标列表,查找每个服务的关键依赖关系,并构建依赖关系的地图。它还收集和存储数据,例如调用计数、错误和适用的延迟。通过使用调用图,我们可以映射依赖关系并识别高价值依赖关系(即服务 A 以每秒 1000 次查询 (qps) 的速度调用服务 B 是高价值依赖,而服务 A 以 2 qps 的速度调用服务 B ) 和相关的指标。然后,我们使用近期分析来查找服务指标之间的类似趋势警报。在问题的时间窗口内,我们可以查询服务的依赖关系,从而得出“置信度得分”,该得分表示我们对特定依赖关系是问题的信心程度。
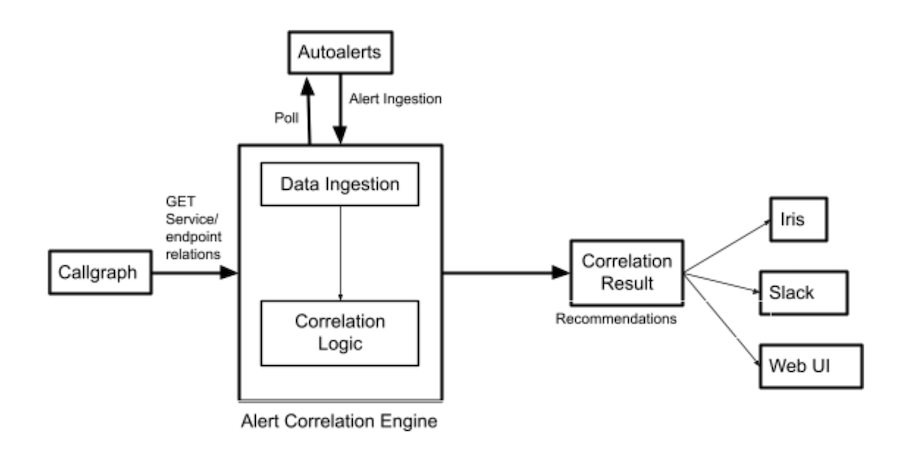
Alert Correlation 服务会定期轮询我们的警报数据库,称为“Autoalerts”(Autoalerts 是 LinkedIn 用于用户定义警报的警报系统),以检查我们基础设施中的活动警报。连同调用图和警报数据,我们构建了一个不健康服务及其依赖关系的图表,包括为图表中的单个服务触发的活动警报(指标超过设定阈值)。将度量数据点与上游和下游依赖项进行比较,以得出置信度分数和严重性分数。置信度分数表示特定服务成为根本原因的概率。严重性评分表示确定的根本原因对上游服务造成的不利影响的程度。这些分数是通过算法得出的,尽管该实现的细节超出了本文的范围。 Alert Correlation 中的一个模块对受共同根本原因影响的上游进行分组,并生成相关结果,也称为推荐,这些结果通过 Slack、Web UI 和 Iris(Linkedin 的内部通知系统)等不同界面与用户共享。
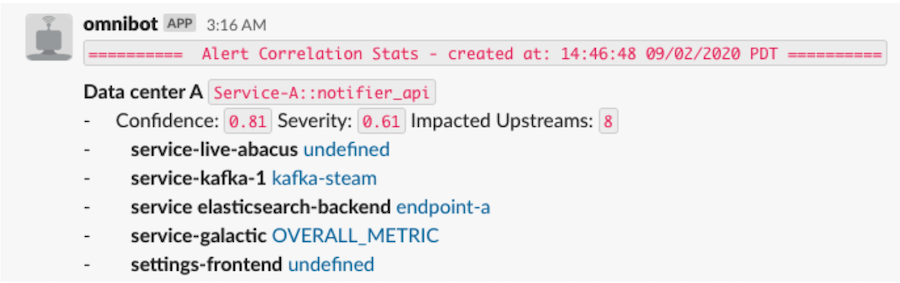
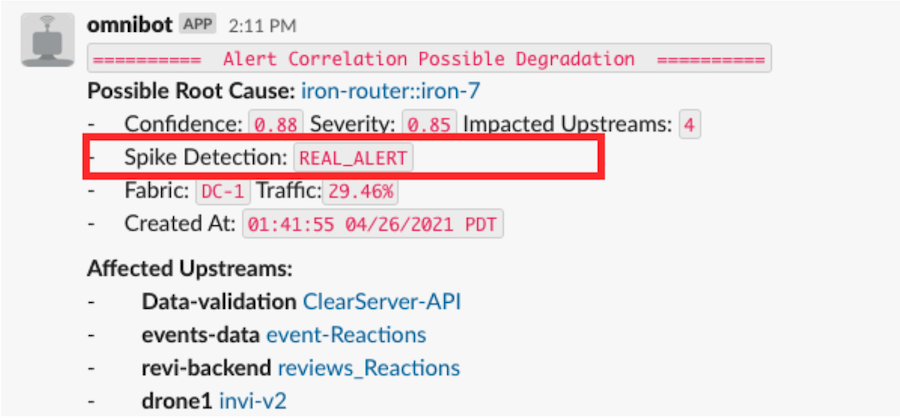
上面的图 2 表示通过 Slack 与服务所有者共享的通知。 该通知包括以下信息:
- 观察到问题的数据中心,即“数据中心 A”
- 根本原因服务,以及行为不端的端点,即“Service-A”及其端点 notifier_api
- 置信度得分,即 Service-A 的概率为 0.81 是根本原因
- 严重性评分,衡量影响的大小,即 0.61
- 受影响上游和受影响端点的列表
警报关联中的尖峰检测
LinkedIn 的服务随着时间的推移不断发展,并将继续增长并变得更加复杂,需要额外的基础设施来支持它们。 如果我们遇到生产事故,Alert Correlation 可以为您指出问题的潜在根本原因。
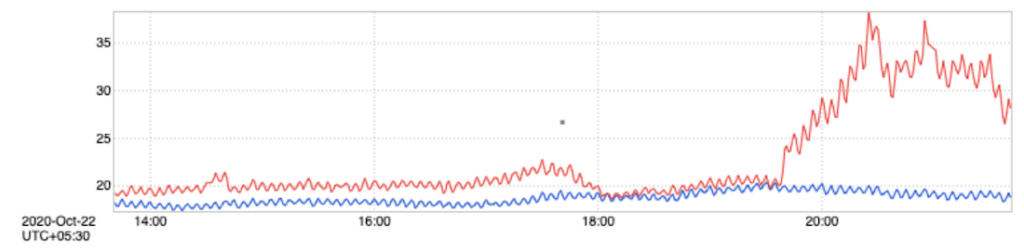
我们的警报是通过查看过去 15 天的指标趋势并得出所见标准偏差来生成的,这通常很宽泛; 在某些时候,不同的团队将他们的警报阈值配置得相当高,以避免误报。 由于警报相关引擎抛出建议,历史配置的警报通常会导致误报,因为它对警报数据变得敏感,由于异常或尖峰,如下所示。
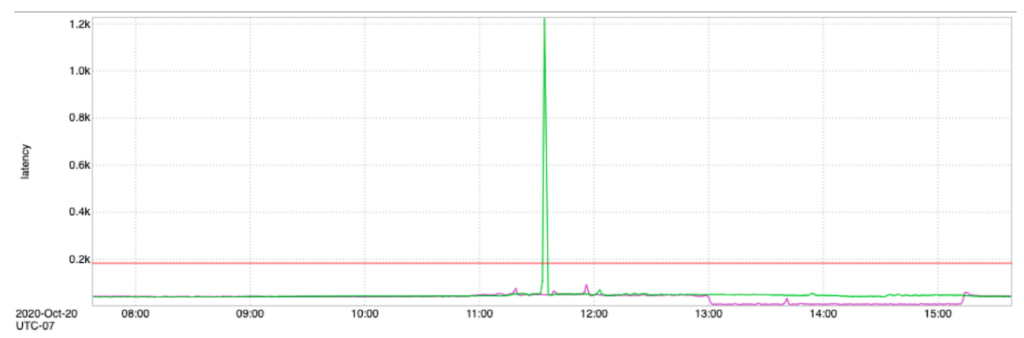
上述尖峰来自受导致尖峰的异常影响的指标;在生产场景中,对于受此类导致峰值的异常影响的服务,我们有多个指标。尖峰通常是短暂的异常,可能由多种原因引起,这些原因可能会或可能不会显着到足以作为警报引发。峰值间接导致团队查看针对下游或上游服务发布的建议,然后花一些时间来确定这是真正的问题还是误报。这也增加了值班工程师的警报疲劳和整体工作量,他们必须弄清楚警报是否值得调查。因此,我们想要一种方法来实时检测这些峰值并将它们分类为真正的警报或只是一个峰值。为了获得更准确的警报建议,我们还使用了动态警报阈值,这些阈值会根据警报的过去趋势定期调整,并将这些警报用作更具适应性的阈值。
因此,我们需要一种方法来进行异常检测,该方法需要实时、计算成本低且足够稳定,以检测尖峰并确保将误报降至最低。 我们提出了中值估计作为检测异常值的理想解决方案。 中值作为一种强大的估计工具,因为它在存在大的异常值的情况下不会出现偏差。 我们使用称为中值绝对偏差 (MAD) 的中值估计来计算过去 30 分钟警报数据的中值。 一组定量观察的中值绝对偏差主要是分散的度量,即数据集的分散程度。 通过使用 MAD,我们确定了围绕中位数的正偏差的中位数。
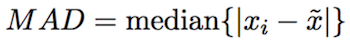

然后我们使用上面的 MAD 以及 Iglewicz 和 Hoaglin 提出的修正 Z-score 算法中绝对值大于 3.5 的中值,将其标记为潜在的异常值。 修改后的 z 分数是衡量异常值强度的标准化分数,即特定分数与典型分数的差异程度。
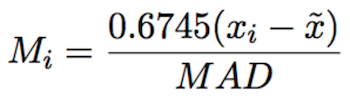
现在,我们能够通过使用修改后的 z 方方法来确定异常值检测方法,该方法不会因样本大小而产生偏差,对于受影响的服务,我们通过活动警报获取指标。 对于每个指标,我们在使用我们的指标框架(AMF - 自动指标框架)确定根本原因之前的最后 30 分钟获取指标数据点。 一旦我们有了正确的数据集,即度量数据,我们将修改后的 z-score 算法应用于每个度量数据集,因为我们有多个服务度量。 然后,我们最终根据阈值和连续的异常值数据等特定条件,对来自每个服务指标(保存异常值详细信息)的分类数据进行清理、隔离和分组,以确定它是真正的警报还是峰值。
尖峰或异常基本上是数据集中的异常值,而真正的警报与模式(即警报指标数据集)没有区别。 如果警报反映了异常模式以及我们为用例确定的一些额外分类因素,例如:警报持续了多长时间(即警报持续时间), 要处理的服务(包括下游和上游)、置信度分数等。所有这些因素,以及我们在服务上应用的用户定义的预过滤器,都有助于我们减少假阴性的数量。
结论
通过基于五分钟的窗口大小对结果进行聚合和分组以识别真正的警报,对服务的各个指标(即相关图)应用尖峰检测后,我们可以显着提高发布到的建议的总量 我们的 Slack 频道使用上述算法,最多将 36% 的警报建议分类为平均一周内的峰值。 这种简单的方法为异常的分类方式创造了一种可预测的行为,没有大量的计算要求,并且能够实时完成,同时确保我们有一个简单的代码库来维护。 此外,我们还能够在整体推荐质量方面减少假阴性结果,准确率为 99%。 目前,我们不仅通过 Slack 推荐为我们集成了此功能,还为我们的下游客户端集成了此功能,这些客户端通过 API 端点使用警报关联数据。
标签:指标,依赖,服务,Linked,尖峰,警报,告警,异常,我们 来源: https://www.cnblogs.com/BigDataToAI/p/linkedin_alert_correlation.html