kafka是什么?
作者:互联网
一.介绍
kafka是一个分布式消息系统,由linkedin使用scala编写,用作LinkedIn的活动流(Activity Stream)和运营数据处理管道(Pipeline)的基础。具有高水平扩展和高吞吐量。
特点:
- 提供Pub/Sub方式的海量消息处理。
- 以高容错的方式存储海量数据流。
- 保证数据流的顺序。
Kafka提供了类JMS的特性,但在设计实现上并不遵循JMS规范,Kafka对消息保存时根据Topic进行归类,发送消息者称为Producer,消息接受者称为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)称为broker。同时无论是kafka集群,还是producer和consumer都依赖于zookeeper集群保存一些meta信息,来保证系统可用性。
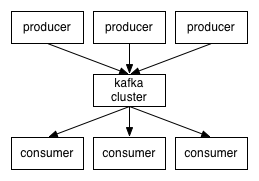
Kafka核心组件及简单的运作流程图:
Topic :消息根据Topic进行归类
Producer:发送消息者
Consumer:消息接受者
Kafka cluster:kafka集群
broker:每个kafka实例(server)
Zookeeper:依赖集群保存meta信息
二.使用场景
假设你意气风发,要开发新一代的互联网应用,以期在互联网事业中一展宏图。借助云计算,很容易开发出如下原型系统:
- Web应用:部署在云服务器上,为个人电脑或者移动用户提供的访问体验。
- SQL数据库:为Web应用提供数据持久化以及数据查询。
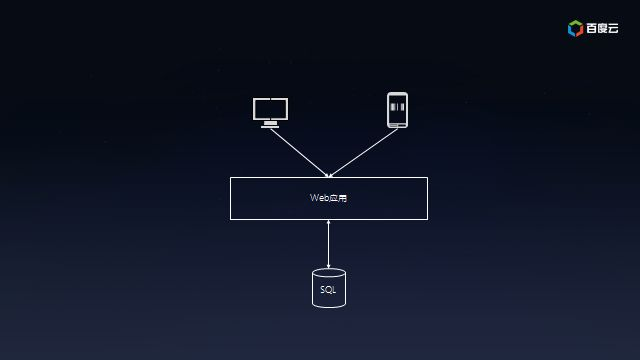
这套架构简洁而高效,很快便能够部署到百度云等云计算平台,以便快速推向市场。互联网不就是讲究小步快跑嘛!
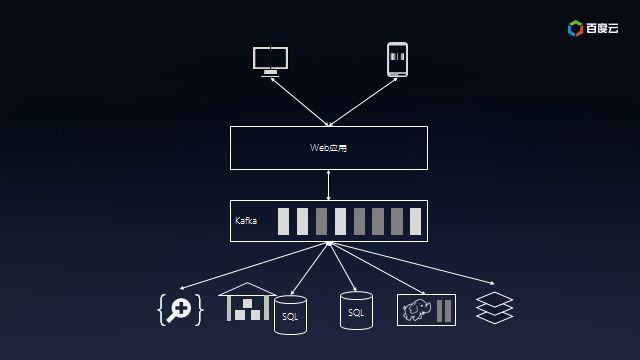
好景不长。随着用户的迅速增长,所有的访问都直接通过SQL数据库使得它不堪重负,不得不加上缓存服务以降低SQL数据库的荷载;
为了理解用户行为,开始收集日志并保存到Hadoop上离线处理,同时把日志放在全文检索系统中以便快速定位问题;由于需要给投资方看业务状况,也需要把数据汇总到数据仓库中以便提供交互式报表。此时的系统的架构已经盘根错节了,考虑将来还会加入实时模块以及外部数据交互,真是痛并快乐着……
这时候,应该跑慢一些,让灵魂跟上来。
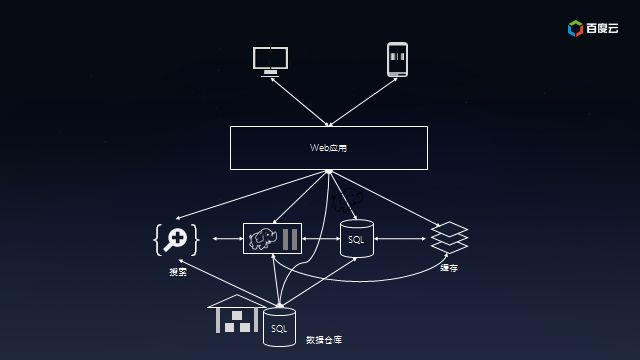
本质上,这是一个数据集成问题。没有任何一个系统能够解决所有的事情,所以业务数据根据不同用途存而放在不同的系统,比如归档、分析、搜索、缓存等。数据冗余本身没有任何问题,但是不同系统之间像意大利面条一样复杂的数据同步却是挑战。
这时候就轮到Kafka出场了。
Kafka可以让合适的数据以合适的形式出现在合适的地方。Kafka的做法是提供消息队列,让生产者单往队列的末尾添加数据,让多个消费者从队列里面依次读取数据然后自行处理。之前连接的复杂度是O(N^2),而现在降低到O(N),扩展起来方便多了:
在Kafka的帮助下,你的互联网应用终于能够支撑飞速增长的业务,成为下一个BAT指日可待。
以上故事说明了Kafka主要用途是数据集成,或者说是流数据集成,以Pub/Sub形式的消息总线形式提供。但是,Kafka不仅仅是一套传统的消息总线,本质上Kafka是分布式的流数据平台。
三.举例说明
生产者消费者,生产者生产鸡蛋,消费者消费鸡蛋,生产者生产一个鸡蛋,消费者就消费一个鸡蛋,假设消费者消费鸡蛋的时候噎住了(系统宕机了),生产者还在生产鸡蛋,那新生产的鸡蛋就丢失了。再比如生产者很强劲(大交易量的情况),生产者1秒钟生产100个鸡蛋,消费者1秒钟只能吃50个鸡蛋。
那要不了一会,消费者就吃不消了(消息堵塞,最终导致系统超时),消费者拒绝再吃了,”鸡蛋“又丢失了,这个时候我们放个篮子在它们中间,生产出来的鸡蛋都放到篮子里,消费者去篮子里拿鸡蛋,这样鸡蛋就不会丢失了,都在篮子里。
而这个篮子就是”kafka“。鸡蛋其实就是“数据流”,系统之间的交互都是通过“数据流”来传输的(就是tcp、http什么的),也称为报文,也叫“消息”。消息队列满了,其实就是篮子满了,”鸡蛋“ 放不下了,那赶紧多放几个篮子,其实就是kafka的扩容。各位现在知道kafka是干什么的了吧,它就是那个"篮子"
四.基本概念
消费者:(Consumer):从消息队列中请求消息的客户端应用程序
生产者:(Producer) :向broker发布消息的应用程序
AMQP服务端(broker):用来接收生产者发送的消息并将这些消息路由给服务器中的队列,便于fafka将生产者发送的消息,动态的添加到磁盘并给每一条消息一个偏移量,所以对于kafka一个broker就是一个应用程序的实例
主题(Topic):一个主题类似新闻中的体育、娱乐、教育等分类概念,在实际工程中通常一个业务一个主题。
分区(Partition):一个Topic中的消息数据按照多个分区组织,分区是kafka消息队列组织的最小单位,一个分区可以看作是一个FIFO( First Input First Output的缩写,先入先出队列)的队列。
kafka分区是提高kafka性能的关键所在,当你发现你的集群性能不高时,常用手段就是增加Topic的分区,分区里面的消息是按照从新到老的顺序进行组织,消费者从队列头订阅消息,生产者从队列尾添加消息。
备份(Replication):为了保证分布式可靠性,kafka0.8开始对每个分区的数据进行备份(不同的Broker上),防止其中一个Broker宕机造成分区上的数据不可用。
kafka0.7是一个很大的改变:1、增加了备份2、增加了控制借点概念,增加了集群领导者选举 。
标签:队列,鸡蛋,Kafka,生产者,消息,kafka,什么 来源: https://www.cnblogs.com/rxysg/p/15697048.html