音频标签化3:igor-8m项目的训练、评估与测试
作者:互联网
上一节介绍了youtube-8m项目,这个项目以youtube-8m dataset(简称8m-dataset)样本集为基础,进行训练、评估与测试。youtube-8m设计用于视频特征样本,但实际也适用于音频。另外,8m-dataset分两类,一类是聚合特征(video-level,使用整个样本的平均特征),另一类是帧特征(frame-level),帧特征样本适用于sound classification。
除了8m-dataset这个8百万的样本集,另一个样本集--audioset,也是经常使用的样本集,有2百万的样本数据。audioset的介绍早已完成,读者可以关注“广州小程”微信公众号并查阅相应的文章。
本文介绍基于audioset样本集的项目,这个项目能完成训练、评估与测试的功能,最终用于满足音频标签化的需求。
这个开源项目的git地址是:
https://github.com/igor-panteleev/youtube-8m
这里简称为igor-8m项目。
igor-8m项目基于youtube-8m(https://github.com/google/youtube-8m)项目进行了修改,可以使用audioset样本。对于igor-8m项目的产生与改进,读者可以参考这个网页,上面详细提及了项目出现的原因、项目的使用与效果等:
https://medium.com/iotforall/sound-classification-with-tensorflow-8209bdb03dfb
接下来小程简单介绍一下igor-8m的使用。
(一)使用igor-8m
由于igor-8m是基于youtube-8m项目,所以在操作有很大部分是类似的,而小程之前介绍过youtube-8m项目的使用。
(1)环境
环境上,首先要安装了python2.7+,并且安装了tensorflow1.0+。
可以这样检测python跟tensorflow的版本信息:
python --version
python -c 'import tensorflow as tf; print(tf.__version__)'
对于python2.7的mac,可以这样安装tensorflow(需在FQ状态;可优先考虑在虚拟环境中安装tf):
pip install --upgrade https://storage.googleapis.com/tensorflow/mac/cpu/tensorflow-1.8.0-py2-none-any.whl
(2)样本
之前已经介绍过,audioset下载后有两部分内容,一个是音频特征文件,均以“tfrecord”为后缀的文件(也就是tensorflow的record file),另一个是样本描述文件(有三个文本文件),记录了样本的信息(比如视频的ID、起始与终止时间、分类ID等)。
对于audioset的下载,不再重复讲解了,读者可以参考之前的文章。下载到audioset样本后,就可以分别进行训练、评估与测试的操作。
(3)训练
先把igor-8m项目clone下来:
这时可以看到igor-8m项目的目录结构是这样的:
然后就可以使用这个项目就行训练,比如iotforall给出的一个训练命令:

详情可以看这个页面的介绍:
https://medium.com/iotforall/sound-classification-with-tensorflow-8209bdb03dfb
在实际使用上,“训练参数”是一个关键点,读者应该根据样本的质量与数量、训练机器的gpu数量与可用内存大小等等,再经过反复的训练与调整,从而得出较好的训练参数集。
对于train.py使用的参数,可以这样查看:
python train.py --help
可以看到这样的信息:
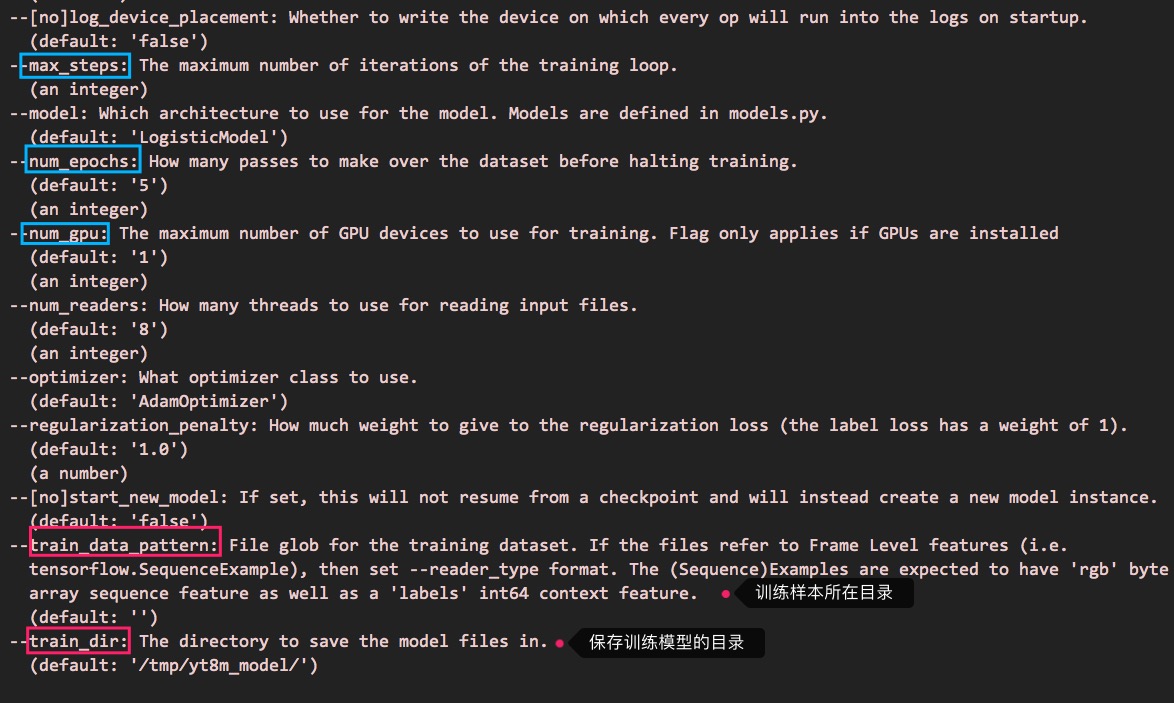
训练后产生模型文件,这个跟youtube-8m的介绍一样,请参阅之前的文章。
(4)评估与测试
igor-8m项目的评估与测试,跟之前介绍的youtube-8m一样,这里面不展开了。
(二)制作tfrecord文件
“样本”是机器学习的一个关键点,以上使用的是audioset样本,这些样本区分为训练、评估与测试的样本,有了它们,就可以完整地操作模型。
在实际使用时,一般原始的音频,要么是实时录制进来的数据(从mic中获取的数据),要么是保存成文件的音频文件(一般是压缩格式的音频)。为了把原始的音频用于训练(这是扩充样本集的办法)、评估或者测试,需要把音频数据转换成tfrecord文件,比如把mp3文件制作成tfrecord文件。
这个制作过程,可以使用之前介绍到的VGG模型来完成,对应的开源项目是:
https://github.com/tensorflow/models/tree/master/research/audioset
阅读里面的代码,做适当的修改,就可以实现音频文件转成tfrecord文件,这里不细说了。
总结一下,本文是对youtube-8m的扩展知识,介绍了igor-8m项目的操作(训练、评估与测试),这个项目使用audioset为样本。最后文章简单介绍了生成tfrecord文件的VGG模型。
标签:audioset,igor,音频,样本,youtube,8m,tensorflow 来源: https://www.cnblogs.com/freeself/p/10449400.html