为何RL泛化这么难:UC伯克利博士从认知POMDP、隐式部分可观察解读
作者:互联网
https://zhuanlan.zhihu.com/p/439057436
强化学习为何泛化如此困难?来自加州大学伯克利分校等机构的研究者从认知 POMDP、隐式部分可观察两个方面进行解释。
机器之心报道,编辑:陈萍、杜伟。
当今强化学习(RL)的问题很多,诸如收敛效果不好。在偏弱的实验环境里,模型测试结果看起来尚可,许多问题暴露得不明显,但大量实验已经证明深度 RL 泛化很困难:尽管 RL 智能体可以学习执行非常复杂的任务,但它似乎对不同任务的泛化能力较差,相比较而言,监督深度网络具有较好的泛化能力。
有研究者认为,对于监督学习来说,发生一次错误只是分类错一张图片。而对于 MDP(马尔可夫决策过程)假设下的 RL,一次识别错误就会导致次优决策,甚至可能一直错误下去,这也是 RL 在现实世界没法用的根源。
为什么强化学习的泛化能力从根本上来说很难,甚至从理论的角度来说也很难?来自加州大学伯克利分校的博士生 Dibya Ghosh 等研究者共同撰文解释了这一现象,文章从认知 POMDP(Epistemic POMDP)、隐式部分可观察(Implicit Partial Observability)两个方面进行解释。论文共同一作 Dibya Ghosh 的研究方向是使用强化学习进行决策。之前,他曾在蒙特利尔的 Google Brain 工作。

论文地址:https://arxiv.org/pdf/2107.06277.pdf
通过示例进行学习
在正式分析 RL 泛化之前,研究者首先通过两个示例解释 RL 中泛化困难的原因。
猜图游戏
在这个游戏中,RL 智能体在每个回合(episode)中都会看到一张图像,并尽可能快地猜出图像标签(下图 1)。每个时间步长内(timestep),智能体必须进行一次猜测;如果猜测正确,那么这一回合就结束了。但如果猜错了,则智能体会收到一个负反馈,并要在下一个回合中对相同的图像进行其他猜测。因为每张图像都有唯一的标签(有正确的标签函数 f_true:x—>y),智能体接收图像作为观测,这是一个完全可观测的 RL 环境。
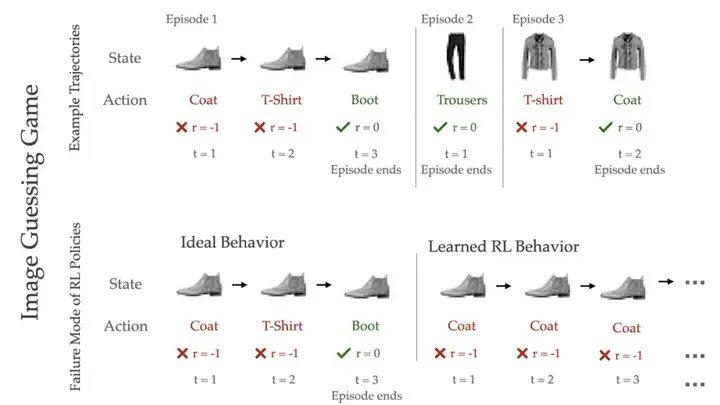
图 1:在猜图游戏中,智能体反复猜测图像标签,直到正确为止。
假设我们可以访问无限数量的训练图像,并使用标准 RL 算法学习策略。该策略将学习如何确定地预测真实标签(y:=f_true(x)),同时这也是 MDP 中的最高回报(return)策略。假如只有一组有限的训练图像,RL 算法仍然会学习相同的策略,确定性地预测与图像匹配的标签。
但是,这种策略的泛化能力如何呢?在未见过的测试图像上,如果智能体预测标签仍然正确,智能体将会获得最高的奖励;如果不正确,智能体会收到灾难性的低回报,因为它永远不会猜到正确的标签。这种灾难性的失败模式一直存在,因为即使现代深度网络提高了泛化能力并减少了错误分类的机会,但测试集上的错误也不能完全减少到 0。
我们能做得比这种确定性预测策略更好吗?因为学习 RL 策略忽略了猜图游戏的两个显著特征:1) 智能体会在一个回合中接收猜测是否正确的反馈,以及 2) 智能体可以在未来的时间步长中更改其猜测。消除过程(process-of-elimination)策略可以很好地利用这两个特征:首先,RL 会选择它认为最有可能的标签,如果不正确,则消除该标签并适应下一个最有可能的标签,依此类推。然而,这种基于记忆的自适应策略永远不会被标准 RL 算法学习,因为它们优化了 MDP 目标并且只学习确定性和无记忆策略。
迷宫求解算法
作为 RL 泛化基准测试的主要内容,迷宫求解问题要求智能体可以导航到迷宫中的目标,并且给出整个迷宫的鸟瞰图。这项任务是完全基于观察的,智能体通过观察展示整个迷宫图。因此,最优策略是无记忆和确定性的,只要智能体沿着最短路径到达目标即可。
就像在猜图游戏中一样,RL 通过最大化训练迷宫布局内的回报,确定性会采取它认为以最短路径到达目标的行动(action)。
这种 RL 策略泛化能力很差,因为如果学习策略选择了一个错误的动作,比如撞墙或折回原来的道路,它将继续循环同样的错误并且永远无法解决迷宫问题。但是,这种失败模式是完全可以避免的,因为即使 RL 智能体最初采取了这样一个不正确的行动,在经过几次跟随之后,智能体会收到所采取的行为正确与否的信息(比如基于下一次观察)。
为了尽可能地进行泛化,如果智能体最初的行动导致了意想不到的结果,那么智能体应该适应它所选择的行动,但是这种行动回避了标准的 RL 目标。
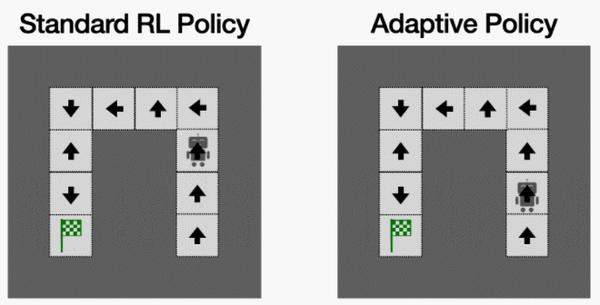
图 2:在迷宫任务中,RL 策略泛化能力很差:当出现错误时,它们会重复犯同样的错误,导致失败(左)。泛化良好的智能体也会犯错误,但具有适应性和从这些错误中恢复的能力(右)。用于泛化的标准 RL 目标不会学习这种行为。
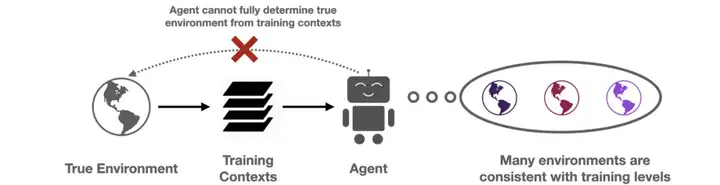
图 3:有限的训练数据集使智能体无法准确地恢复真实环境。相反,存在一种隐式部分可观察,因为智能体不知道在一组一致的环境中哪一个是真实的环境。
当给智能体一个小的上下文训练集时,许多动态模型与提供的训练上下文匹配,但与保留(held-out)的上下文有所不同。这些相互矛盾的假设体现了智能体在有限训练集中的认知不确定性。更重要的是,智能体通过轨迹接收到的信息,可以在评估时改变其认知不确定性。假设对于猜谜游戏中的图像,智能体最初在「t-shirt / coat」标签之间不确定。如果智能体猜测「t-shirt 」并收到错误的反馈,智能体会改变其不确定性并对「 coat」标签变得更有信心,这意味着它应该因此而适应并猜测「 coat」。
认知 POMDP 与隐示部分可观察
RL 智能体有两种方式处理其认知不确定性:主动转向低不确定性区域和采用信息收集。但是它们都没有回答这些问题:「是否有一个最好的方法来处理不确定性,如果有的话,我们该如何描述呢?」从贝叶斯的角度来看,事实证明存在这样一个最优解:最优泛化要求我们解决「部分可观察的马尔可夫决策过程 (POMDP)」,POMDP 隐式地由智能体认知不确定性创建。
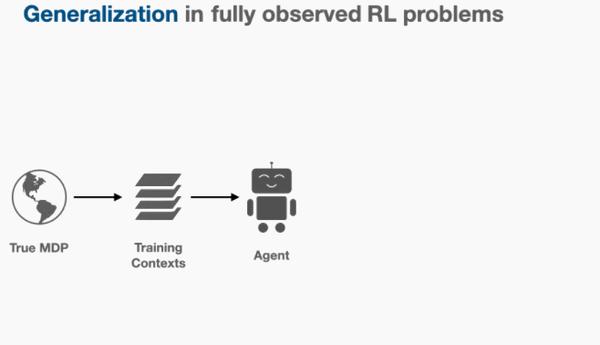
认知 POMDP(epistemic POMDP)作用如下:由于智能体只能看到有限的训练集,因此有许多可能的环境与提供的训练上下文一致。一致的环境集可以通过贝叶斯后验对环境进行编码 P(M | D),在认知 POMDP 的每一个阶段中,智能体被放入这种一致的环境中 M~P(M | D),并要求在其中最大化奖励。
该系统对应于 POMDP,因为行动所需的相关信息,智能体只能通过部分观察到:虽然环境中的状态被观察到,但环境 M 生成这些状态的信息对智能体是隐藏的。认知 POMDP 将泛化问题实例化到贝叶斯 RL 框架中,该框架更一般性地研究了 MDP 分布下的最优行为。
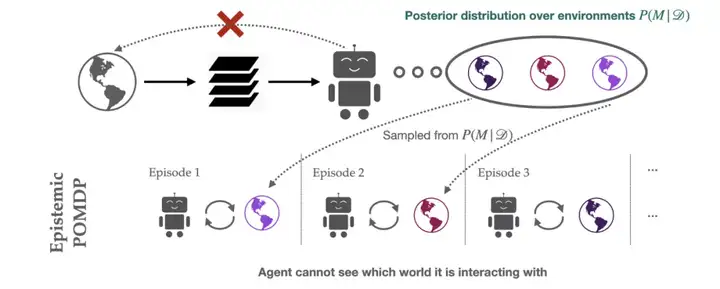
图 4:在认知 POMDP 中,智能体在每个阶段中与不同的相互一致环境进行交互,但不知道它具体与哪个交互可以导致部分可观察性。要想做得好,智能体必须采用(可能基于内存的)策略,使得其无论置于哪个环境中,都可以很好地工作。
让我们通过一个示例来了解认知 POMDP 。对于猜谜游戏,智能体不确定图像究竟如何标记,因此每个可能的环境 M∼P(M∣D) 对应于不同图像标签器,其与训练数据集保持一致:f_M:X→Y。在猜谜游戏的认识 POMDP 中,每阶段随机选择一个图像 x 和标签器 f_M,并要求智能体输出采样分类器 y=f_M(x) 分配的标签。智能体不能直接这样做,因为分类器的身份没有提供给智能体,只提供了图像 x。如果所有标签器 f_M 后验都同意某个图像的标签,则智能体可以只输出这个标签(没有部分可观察性)。但是,如果不同的分类器分配不同的标签,则智能体必须使用平均效果良好的策略。
认知 POMDP 还强调了从有限训练集上下文中学习策略的危险:在训练集上运行完全可观察的 RL 算法。这些算法将环境建模为 MDP,并学习 MDP 最优策略,即确定性和马尔可夫策略。这些策略不考虑部分可观察性,因此往往泛化性很差(例如在猜谜游戏和迷宫任务中)。这表明基于 MDP 训练目标(现代算法标准)与认知 POMDP 训练目标(实际上决定了所学习策略的泛化程度)之间存在不匹配。
在 RL 中推进泛化
我们应该怎么做才能学习更好泛化的 RL 策略?认知 POMDP 提供了一个规范的解决方案:当可以计算智能体在环境上的后验分布时,通过构建认知 POMDP 并在其上运行 POMDP 求解算法将产生泛化贝叶斯最优的策略。
遗憾的是,在大多数有趣的问题中,还不能完全做到。尽管如此,认知 POMDP 可以作为设计具有更好泛化能力 RL 算法的标杆。作为第一步,研究者在论文中引入了一种称为 LEEP 的算法,该算法使用统计自助法 (Bootstrapping) 来学习近似认知 POMDP 的策略。
在具有挑战性的 RL 智能体泛化基准测试 Procgen 上,LEEP 在测试时的性能比 PPO 显著提高(图 3)。虽然只是粗略的逼近,但 LEEP 提供的一些迹象表明,尝试在 epistemic POMDP 中学习策略可以成为开发更通用 RL 算法的有效途径。
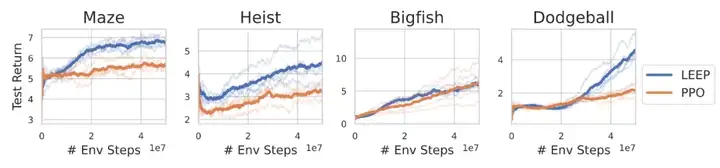
图 5:LEEP,一种基于认知 POMDP 目标的算法,在四个 Procgen 任务中比 PPO 具有更好的泛化性能。
在监督学习中,优化训练集性能可以提高模型泛化能力,因此,很容易假设 RL 中的泛化可以用同样的方式解决,但这显然是错误的。RL 中有限的训练数据将隐式的部分可观察性引入到一个完全可观察的问题中。这种隐式的部分可观察性,正如认知 POMDP 形式化的那样,意味着在 RL 中很好地泛化需要自适应或随机行为,这是 POMDP 问题的关键。
最终,这凸显了深度 RL 算法泛化的不兼容性:由于训练数据有限,基于 MDP 的 RL 目标与最终决定泛化性能的隐式 POMDP 目标不一致。
原文链接:https://bair.berkeley.edu/blog/
标签:泛化,POMDP,认知,智能,标签,RL 来源: https://www.cnblogs.com/dhcn/p/15623219.html