sklearn实现决策树
作者:互联网
导入包
from sklearn.datasets import load_iris, load_wine
from sklearn import tree
from sklearn,model_selection import train_test_split
from sklearn.metrics import accuracy_score
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
导入红酒数据集
X, y = load_wine(as_frame=True, return_X_y=True)
train_X, valid_X, train_y, valid_y = sklearn.model_selection.train_test_split(X, y, test_size=0.3)
这里的as_frame好像只有在sklearn 1.0 以后才实现了。
红酒数据集分类
clf = tree.DecisionTreeClassifier(criterion='entropy'
, random_state=30
, splitter='random'
, max_depth=3)
clf = clf.fit(train_X, train_y)
clf.score(valid_X, valid_y)
这里的score是accuracy_score。返回的是准确率,计算公式:
\[A C C=\frac{T P+T N}{T P+T N+F P+F N} \]准确度:0.9444444444444444
好像还不错,再来个交叉验证。
from sklearn.model_selection import cross_val_score
cross_val_score(clf, X, y, cv=5).mean()
acc: 0.9273015873015874
嗯,可以的。
波士顿房价预测
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]
reg = tree.DecisionTreeRegressor(max_depth=5
,random_state=30)
cross_val_score(reg, data, target, scoring='neg_mean_squared_error', cv=5)

原本的sklearn使用的是\(R2\)作为评判标准。
\[\begin{gathered} R^{2}=1-\frac{u}{v} \\ u=\sum_{i=1}^{N}\left(f_{i}-y_{i}\right)^{2} \quad v=\sum_{i=1}^{N}\left(y_{i}-\hat{y}\right)^{2} \end{gathered} \]R2越接近1模型拟合越好。

可以看到模型在有的交叉验证上,效果很好,有的却较差。
画决策树
import graphviz
dot_data = tree.export_graphviz(clf, out_file=None, filled=True)
graph = graphviz.Source(dot_data)
graph
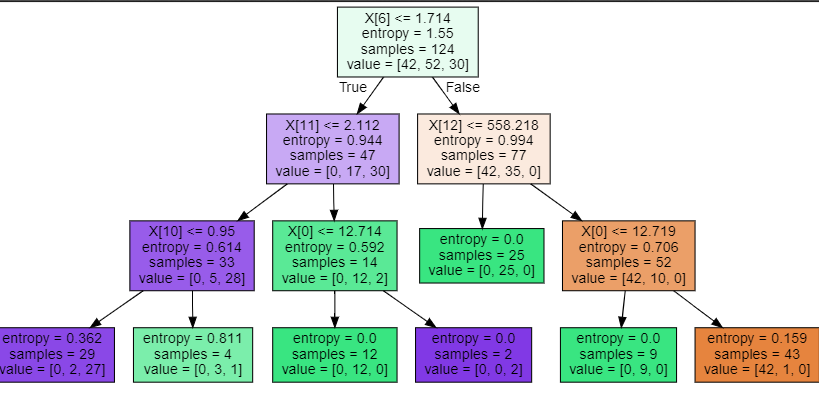
节点越纯净,颜色越深。
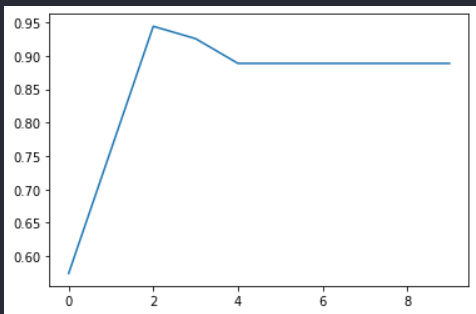
单参数搜索
test = []
for i in range(10):
clf = tree.DecisionTreeClassifier(criterion='entropy'
, random_state=30
, splitter='random'
, max_depth=i+1)
clf = clf.fit(train_X, train_y)
sc = clf.score(valid_X, valid_y)
test.append(sc)
plt.plot(test)
泰坦尼克号数据集
all_data = pd.read_csv('./data.csv')
all_data.info()
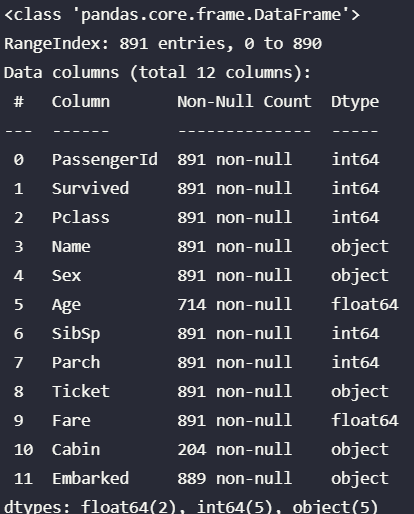
'Ticket', 'Cabin', 'Name' 这三个属性不仅缺失较多,而且对于预测没啥帮助。
可以都删了。
all_data.drop(['Ticket', 'Cabin', 'Name'], inplace=True, axis=1)
all_data.Age.fillna(all_data.Age.mean(), inplace=True) #年龄填充均值
all_data.info()
对于离散的Object直接转为one_hot
all_data = pd.get_dummies(all_data)
训练
x = all_data.iloc[:, all_data.columns != 'Survived']
y = all_data.iloc[:, all_data.columns =='Survived']
train_X, valid_X, train_y, valid_y = train_test_split(x,y, test_size=0.3)
clf = tree.DecisionTreeClassifier(criterion='entropy'
, random_state=30
, max_depth=4
, min_samples_leaf=5
, min_samples_split=5
)
clf.fit(train_X, train_y)
clf.score(valid_X, valid_y)
acc: 0.8246268656716418
交叉验证
cross_val_score(clf, x, y, cv=5).mean()
acc: 0.7991337643587973
网格搜索
from sklearn.model_selection import GridSearchCV
gini_thresholds = np.linesapce(0, 0.5, 20)
parameters = {'splitter':('best','random')
,'criterion':("gini","entropy")
,"max_depth":[*range(1,10)]
,'min_samples_leaf':[*range(1,50,5)]
,'min_impurity_decrease':[*np.linspace(0,0.5,20)]
}
clf = tree.DecisionTreeClassifier(random_state=25)
GS = GridSearchCV(clf, parameters, cv=10)
GS.fit(train_X,train_y)
GS.best_params_
GS.best_score_
{'criterion': 'entropy', 'max_depth': 3, 'min_impurity_decrease': 0.0, 'min_samples_leaf': 16, 'splitter': 'best'}
0.8186123911930363
标签:score,实现,clf,train,import,sklearn,data,决策树 来源: https://www.cnblogs.com/kalicener/p/15617087.html