One Thing One Click: A Self-Training Approach for Weakly Supervised 3D Semantic Segmentation笔记
作者:互联网
点云初学者,有理解错误的欢迎提出。
简述
问题:对点云上的每个点进行标签标注的成本高昂
目的: achieve a performeance comaprable with a fully supervised baseline given the extremely-sparse annotations。【弱监督下的点云语义分割】。
实验所采用的数据集:
ScanNet-v2 S3DIS基本流程:
- 对数据集进行super-voxel partition。然后“One Thing One Click” :对每个实例选一个点进行标注;对一个点标注实质上就是对点所属的segment进行标注。【标注策略:每个实例被划分为多个segment,随机选一个segment标注】。
- 利用得到的有标签的数据分别训练3D U-Net(负责语义分割)和Relation Net(辅助计算voxel之间相似度)。
- 保持前面两个网络的参数不变,将点云送入这两个网络,通过优化一个能量函数选出具有高置信度的unlabelled voxel更新其标签。
- 重复2和3步骤直到收敛。
创新点:设计了一个融合 self-traing 的 label-propagation 机制,实现了弱监督下点云的语义分割
与前面SegGroup的异同:
- 这篇论文生成伪标签的方法不具有通用性。
- 这篇论文不要求对最具有代表性的segment进行标注;随机即可。
- 两篇论文生成的伪标签在后续的过程中不会发生变化。
Overview
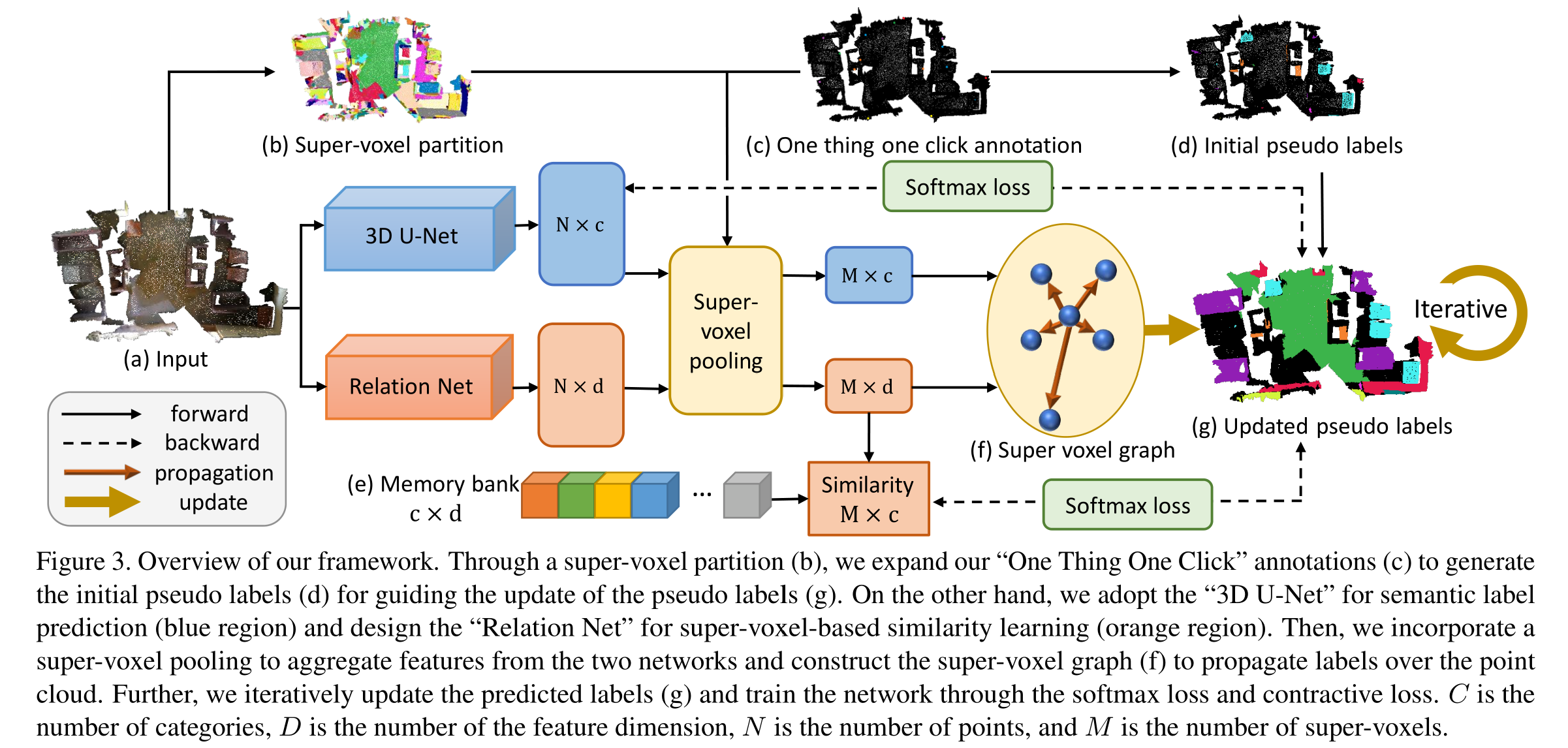
备注:下标\(i,j\)分别表示点和voxel的index
3D Segmantic Segmentation Network
3D U-Net网络作为骨架。损失函数:
\[\large L_s=\frac{1}{N}\sum_{i=1}^{N}-logP(y_i,\bar{c}|p_i,c_i,\Theta) \]其中\(\bar{c}是点p_i的\)ground truth
Super-voxel pooling
作用:聚合体素内的点的特征
方法:对体素内点的特征向量求和再平均得到体素的特征向量。
Relation Network
基本结构就是3D U-Net移除最后一个分类层。目的:为每个super-voxel生成一个与类别紧密相关\(f_j\)。借鉴了原型网络的思想采用对比学习进行训练。
如果完全采用原型网络的思想可能会导致最后生成的每个类的原型背离了实际的categorical center导致网络不稳定且难以收敛。因此设计了 memory bank。它的作用是生成每个类别的原型 ( prototype ) ;memory bank的shape是\(c×d\),其中每一行代表一个类别的原型。以\(f_i\)作为" query ", Relation Network的损失函数:【个人感觉好像公式写错了,少了一个exp。见补充材料里面对对比学习介绍】
\[\large L_c=\frac{1}{M}\sum_{j}^{M}(-log \frac{f_j·k_{\bar{c}}/\tau}{\sum_{c}f_j·k_c/\tau}) \]其中\(\bar{c}是v_j的ground\ truth\ , \tau是一个\text{temperature hyperparameter}\);这个损失函数的作用是:groups the embeddings of voxels which have same category together, while pushing those of different categories apart.
memory bank里面原型的更新方法:
\[\large k_{\bar{c}}\gets mk_{\bar{c}}+(1-m)f_j \]其中\(m\)是一个 momentum coefficient,刚开始memory bank里面的值是随机的。
Pseudo Label Generation by Graph Propagation
通过最小化一个energy function来给每个unlabelled voxel 分配一个标签。然后基于这个分配到的标签对voxel计算一个置信度,如果这个置信度超过一个阈值那么就可以将最小化energy function分配到的标签确定为该voxel的标签。
energy function:
\[\large \begin{eqnarray} E(Y|V)&&=\sum_{j}\psi_u(y_j|V,\Theta)+\sum_{j<j'}\psi_p(y_j,y_{j'}|V,\mathcal{R},\Theta)\\ \end{eqnarray} \]其中:
\[\large \begin{eqnarray} \psi_u(y_j|V,\Theta)&&=-logP(y_j|V,\Theta)\\ \end{eqnarray} \]\[\large \begin{eqnarray} \psi_p(y_j,y_{j'})=&&\mathbb{1}(y_j,y_{j'})exp\{-\lambda_c\frac{||c_j-c_{j'}||^2}{2\sigma_c^2}-\lambda_p\frac{||p_j-p_{j'}||^2}{2\sigma_p^2}-\lambda_u\frac{||u_j-u_{j'}||^2}{2\sigma_u^2}-\lambda_f\frac{||f_j-f_{j'}||^2}{2\sigma_f^2}\}\\ &&if\ y_j=y_{j'}\ ,\mathbb{1}(y_j,y_{j'})=0 \ ;else, 1 \end{eqnarray} \]\(c_j, c_{j'}, p_j,p_{j'}和u_j,u_{j'}\)是 the normalized mean color, mean coordinates and mean 3D U-Net feature, respectively, of super-voxels
\(v_j和v_{j'}\)
可以看出如果\(v_j和v_{j'}\)的相似度高但是预测的标签不一样那么energy function就会很高。置信度的定义【联系论文作者,论文里面的负号是误添的,应该是没有】:
\[\large C_{j}=\frac{1}{n_j}\sum_i^{n_j}log(y_i|p_i,V,\Theta,\mathcal{R},G),\ p_i\in v_j \]G denotes the graph propagation.【本人理解:就是指最小化energy function的过程】
self-training
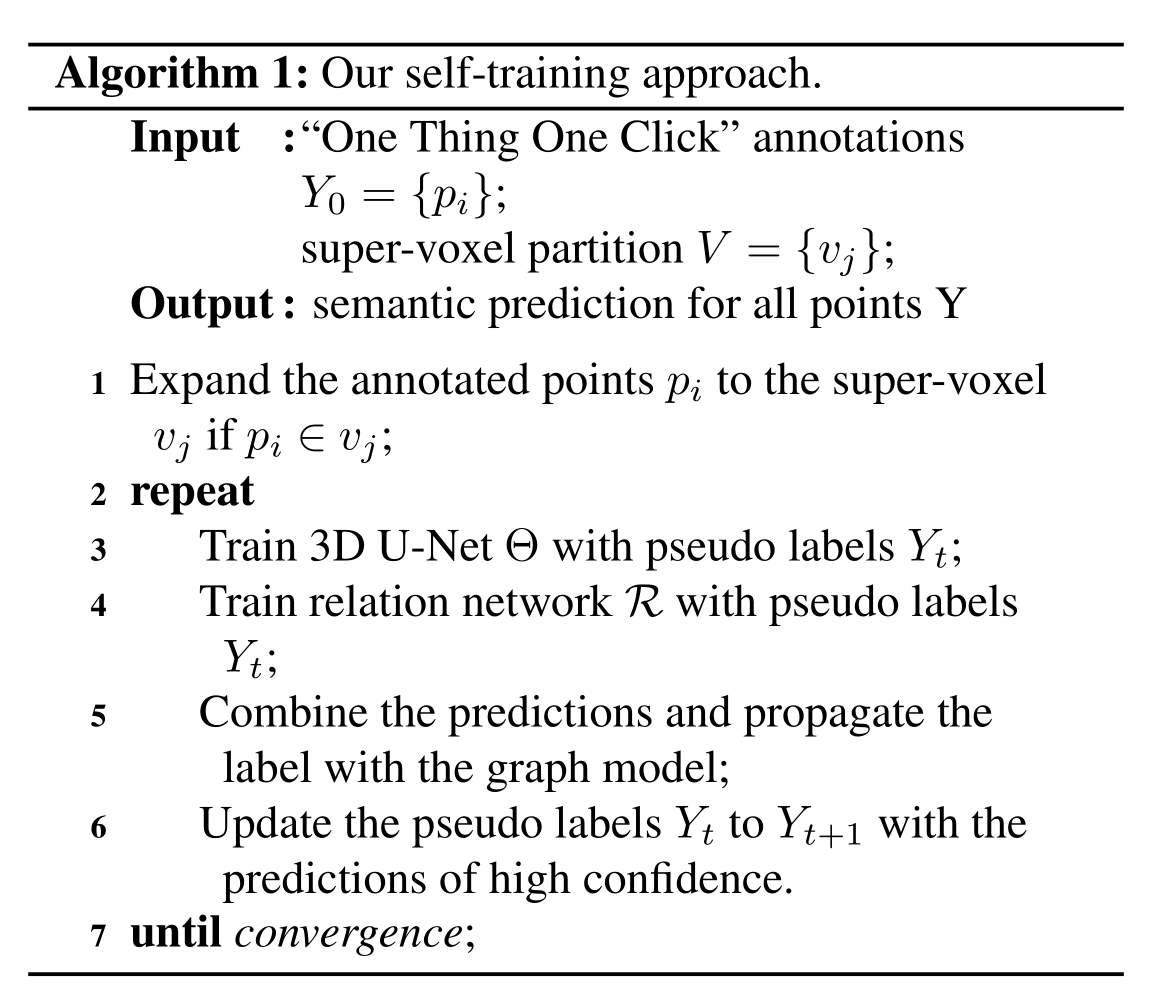
实验
- 与其他全监督的点云语义分割网络和弱监督语义分割网络相比:
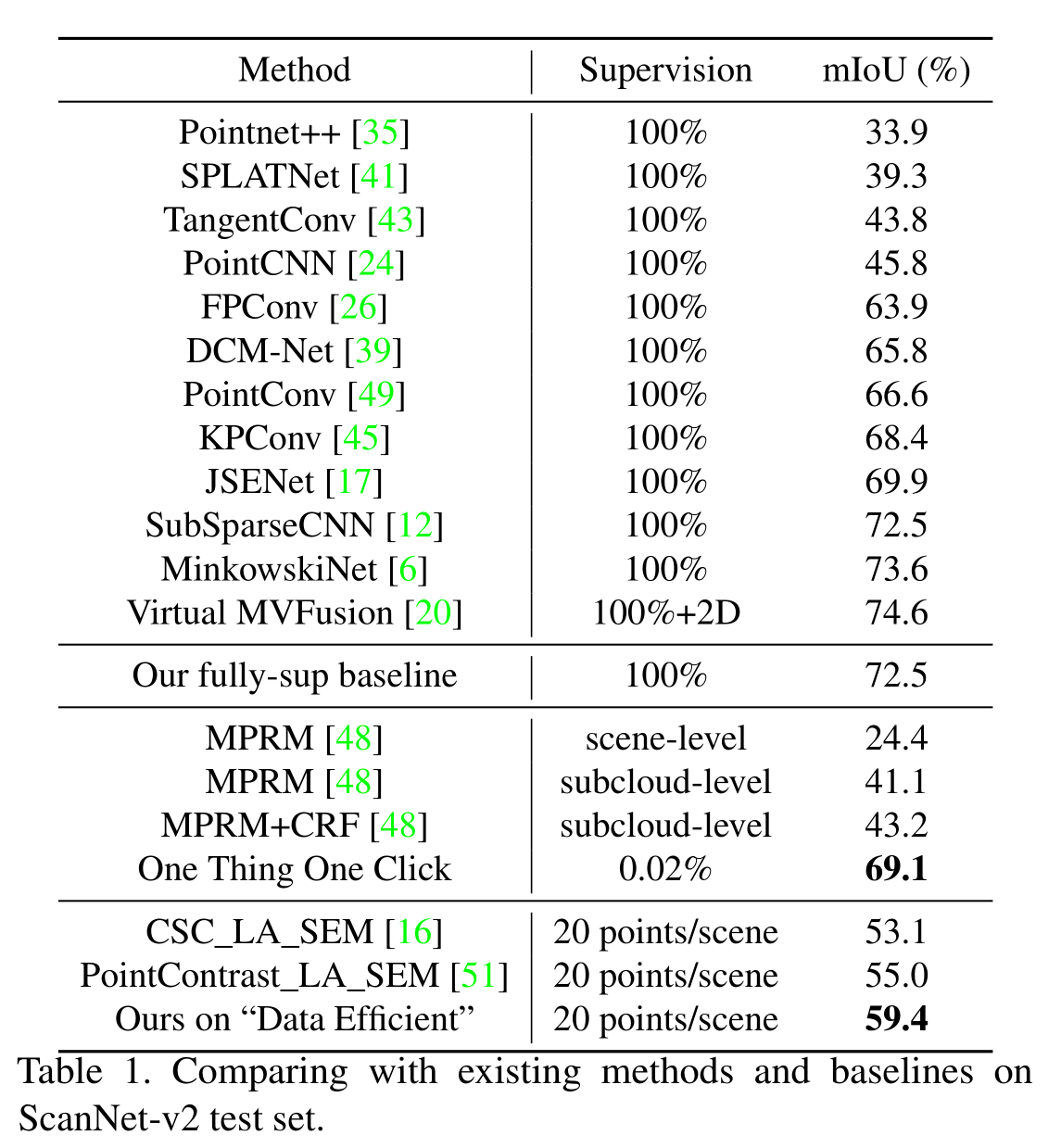
可以看出以仅0.02%的标注消耗实现了69.1%的mIou。关于Data Efficient的解释见论文。
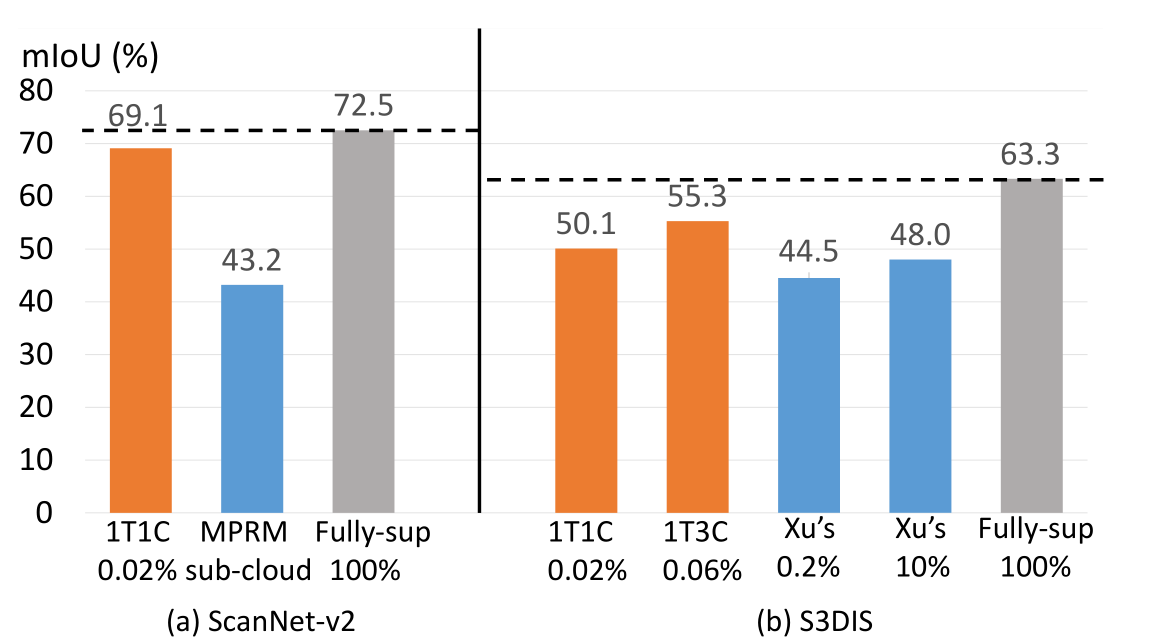
1T3C:每一个实例一开始选三个segment进行标注。
- 与自己相比:(存疑)
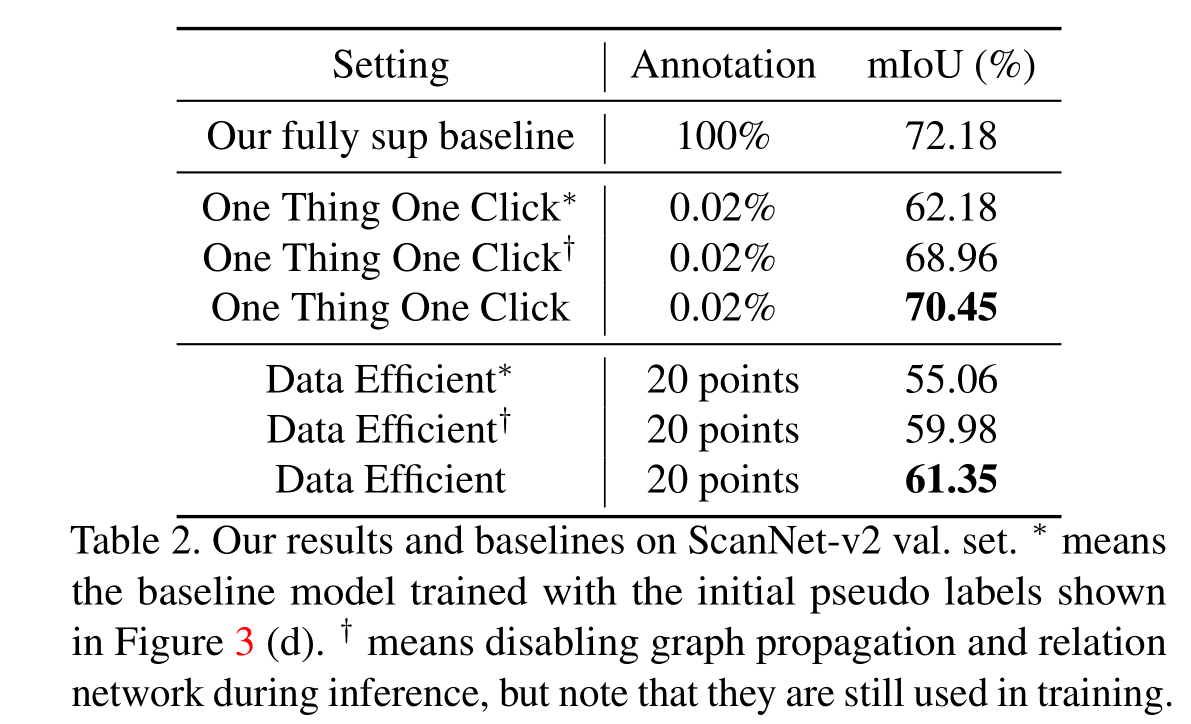
可以看出论文提出的方法与全监督相比仅有2%的性能下降。不过这个*所说的仅在初始伪标签下进行训练啥意思?仅在初始伪标签下训练性能就能达到62.18?
- 对Relation Network的分析
对Scannet-v2中的每个类随机选取200个super-voxels,进行t-SNE可视化:
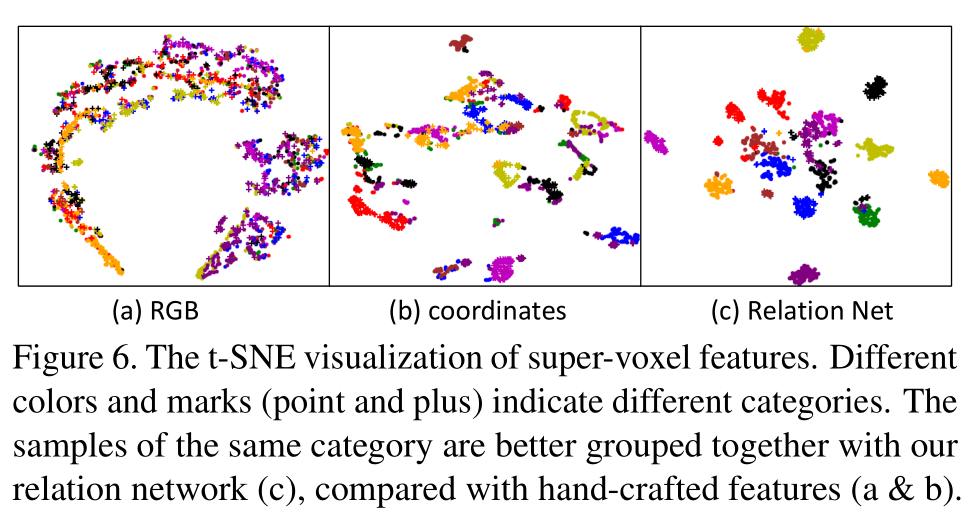
可以看出对Relation Network学到的特征进行聚类,效果好于对RGB和坐标特征进行聚类的效果。
- 每一次iteration伪标签更新的情况:

Iteration1就是图三的Initial pseudo labels。文中指出大约5次Iteration网络性能就收敛了;再增加迭代次数并不能带来显著的性能提升。【注意:性能收敛时仍然可能出现有些super-voxel没有标签】
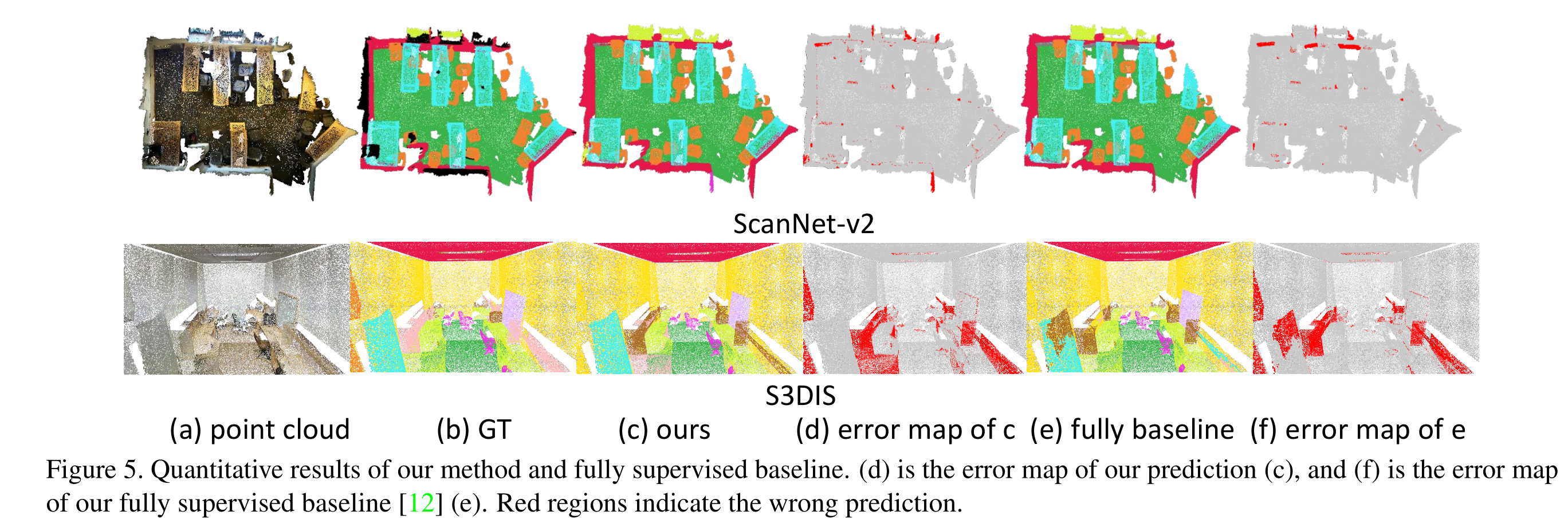
- 定量分析的可视化结果:
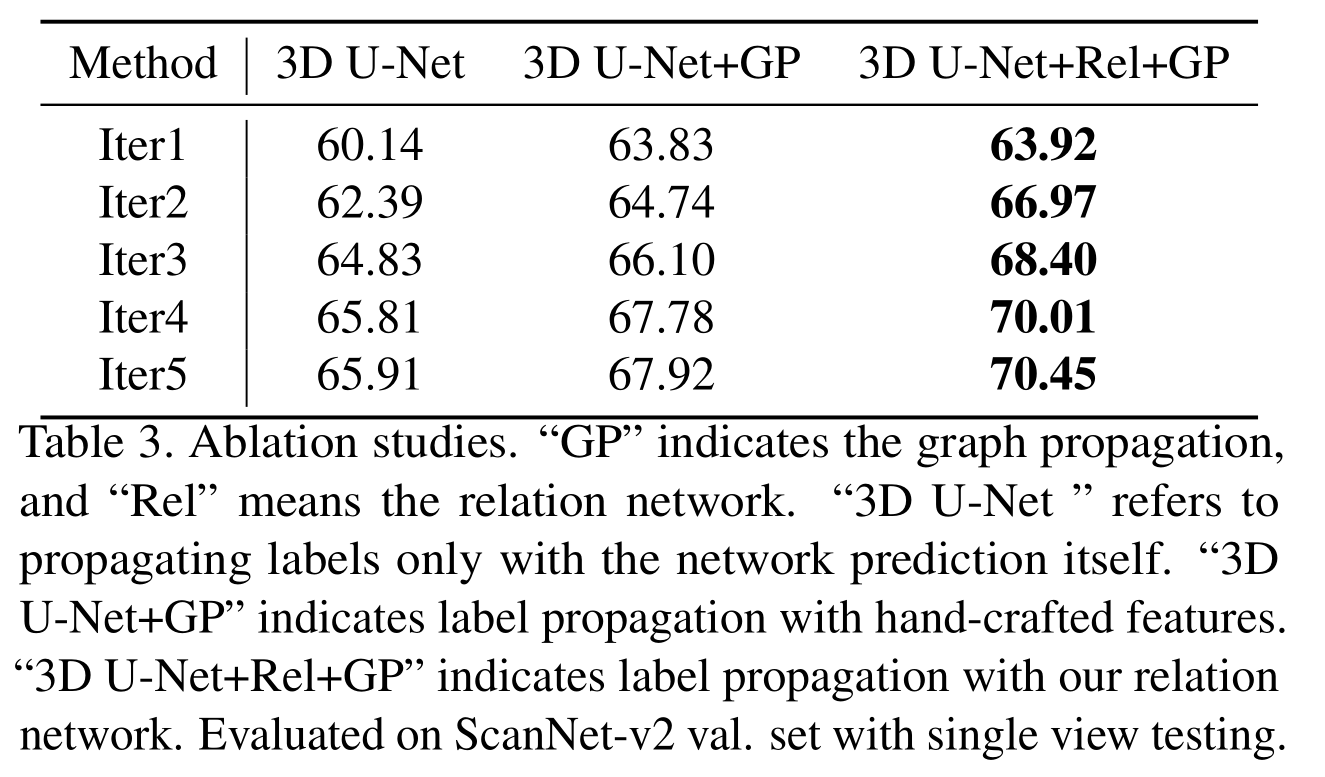
- Ablation study
其他详细实验看论文
补充
对比学习
来自:对比学习综述
简述:
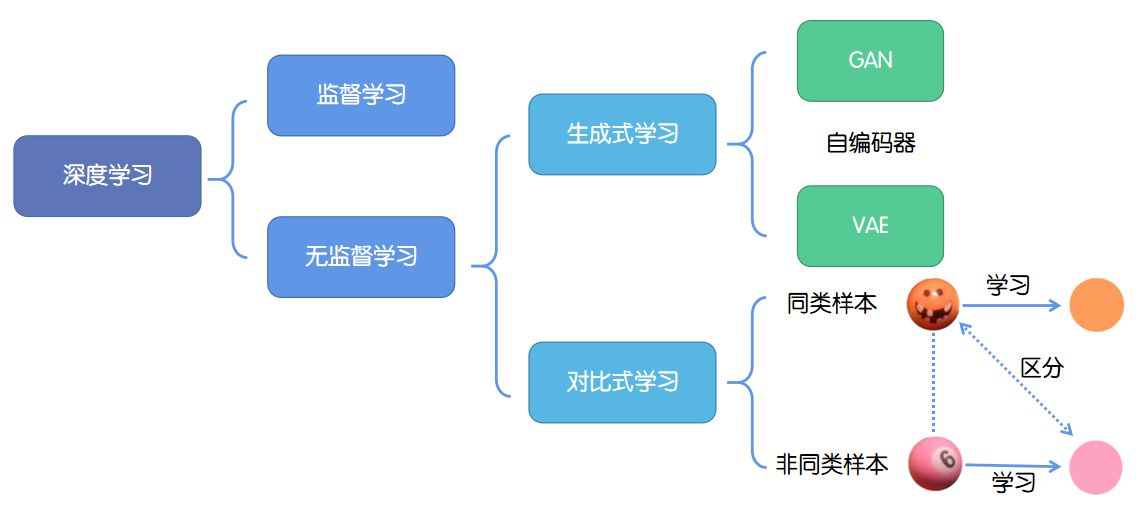
Prototypical Networks for Few-shot Learning(用于小样本学习的原型网络)
来自:( 小样本学习(few-shot learning)之原形网络(Prototypical Networks)
简述:
该文提出了一种可以用于few-shot learning的原形网络(prototypical networks)。该网络能识别出在训练过程中从未见过的新的类别,并且对于每个类别只需要很少的样例数据。原形网络将每个类别中的样例数据映射到一个空间当中,并且提取他们的“均值”来表示为该类的原形(prototype)。使用欧几里得距离作为距离度量,训练使得本类别数据到本类原形表示的距离为最近,到其他类原形表示的距离较远。测试时,对测试数据到各个类别的原形数据的距离做softmax,来判断测试数据的类别标签。
标签:voxel,Training,Weakly,Semantic,标签,网络,large,&&,类别 来源: https://www.cnblogs.com/duolaam/p/15596447.html