Swin Transformer
作者:互联网
论文链接:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
Introduction
目前Transformer应用到图像领域主要有两大挑战:
- 视觉实体变化大,在不同场景下视觉Transformer性能未必很好
- 图像分辨率高,像素点多,Transformer基于全局自注意力的计算导致计算量较大
提出了一种包含滑窗操作,具有层级设计的Swin Transformer
总体架构
注意W-MSA和SW-MSA是成对使用的

整个模型采取层次化的设计,一共包含4个Stage,每个stage都会缩小输入特征图的分辨率,像CNN一样逐层扩大感受野。
W-MSA
Windows Multi-Head Self-Attention
每个方框都是一个窗口,每个窗口是固定有7×7个patch,但是patch的大小是不固定的,它会随着patch merging的操作而发生变化。比如一开始patch大小是4x4,把周边四个窗口的patch拼在一起,从而得到了8x8的patch。

经过这一系列的操作之后,patch的数目在变少,最后整张图只有一个窗口,7个patch。所以我们可以认为降采样是指让patch的数量减少,但是patch的大小在变大。

CNN在每个窗口做的是卷积的计算,每个窗口最后得到一个值,这个值代表着这个窗口的特征。而swin transformer在每个窗口做的是self-attention的计算,得到的是一个更新过的窗口,然后通过patch merging的操作,把窗口做了个合并,再继续对这个合并后的窗口做self-attention的计算。
每个窗口内计算self-attention可以减小计算量,但是缺点是窗口之间无法进行信息交互,也就是说每个窗口的感受野变小,所以文章提出了shift window attention
SW-MSA
Shifted Windows Multi-Head Self-Attention
W-MSA和SW-MSA是成对使用的,那么第L+1层使用的就是SW-MSA(右侧图)。根据左右两幅图对比能够发现窗口(Windows)发生了偏移(可以理解成窗口从左上角分别向右侧和下方各偏移了\(\left \lfloor \frac {M} {2} \right \rfloor\)个像素)。
偏移后的窗口中,比如对于第一行第2列的2x4的窗口,它能够使上一层的第一排的两个窗口信息进行交流。再比如,第二行第二列的4x4的窗口,他能够使上一层的四个窗口信息进行交流


但对窗口进行偏移之后,窗口的数量又增多了(从4个变成9个),这样计算量又大了。
接下来来到本文的最亮点,通过设置合理的mask,让Shifted Window Attention在与Window Attention相同的窗口个数下,达到等价的计算结果。
首先我们对Shift Window后的每个窗口都给上index,并且做一个roll操作(window_size=2, shift_size=-1)
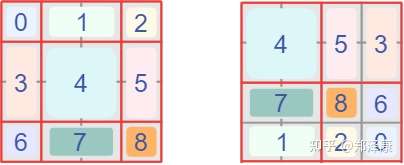
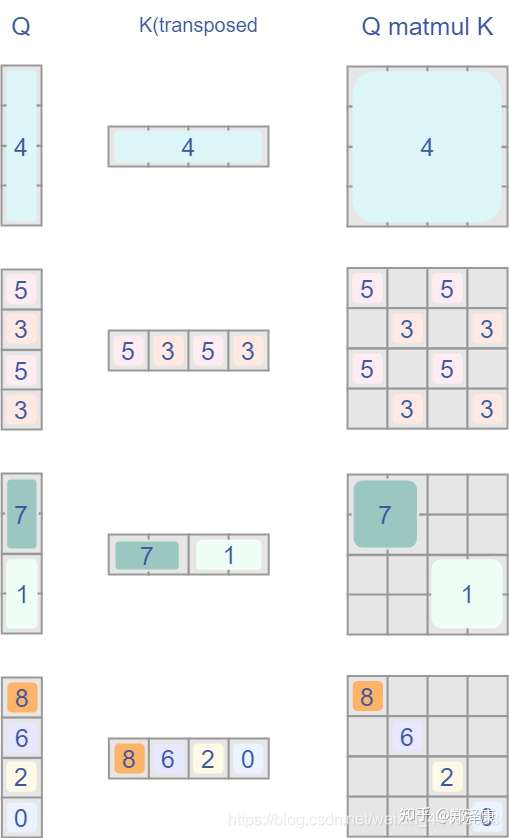
但是把不同的区域合并在一起(比如5和3)进行MSA,这信息不就乱窜了吗?
是的,为了防止这个问题,在实际计算中使用的是masked MSA即带蒙板mask的MSA,这样就能够通过设置蒙板来隔绝不同区域的信息了,这个mask的计算方法是将矩阵乘积后index不一致的地方暴力减去100,softmax后就会忽略掉对应的值。
if self.shift_size > 0:
# calculate attention mask for SW-MSA
H, W = self.input_resolution
img_mask = torch.zeros((1, H, W, 1)) # 1 H W 1
h_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
mask_windows = window_partition(img_mask, self.window_size) # nW, window_size, window_size, 1
mask_windows = mask_windows.view(-1, self.window_size * self.window_size)
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
if mask is not None:
nW = mask.shape[0]
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
Relative Position Bias
\[Attention(Q,K,V)=SoftMax \left (\frac {QK^T} {\sqrt d} +B \right )V \]B就是bias,相对位置索引怎么求的见博客
总结
- 先对特征图进行LayerNorm
- 通过self.shift_size决定是否需要对特征图进行shift
- 然后将特征图切成一个个窗口
- 计算Attention,通过self.attn_mask来区分Window Attention还是Shift Window Attention
- 将各个窗口做merging
- 如果之前有做shift操作,此时进行reverse shift,把之前的shift操作恢复
- 做dropout和残差连接
- 再通过一层LayerNorm+全连接层,以及dropout和残差连接
Reference
标签:Transformer,Swin,窗口,shift,self,mask,window,size 来源: https://www.cnblogs.com/xiaoqian-shen/p/15575125.html