中文NER的那些事儿5. Transformer相对位置编码&TENER代码实现
作者:互联网
这一章我们主要关注transformer在序列标注任务上的应用,作为2017年后最热的模型结构之一,在序列标注任务上原生transformer的表现并不尽如人意,效果比bilstm还要差不少,这背后有哪些原因? 解决这些问题后在NER任务上transformer的效果如何?完整代码详见ChineseNER
Transformer水土不服的原因
Hang(2019)在TENER的论文中给出了两点原因
1. 三角函数绝对位置编码只考虑距离没有考虑方向
2. 距离表达在向量project以后也会消失
我们先来回顾下原生Transformer的绝对位置编码, 最初编码的设计是为了满足几个条件
- 每个绝对位置应该有独一无二的位置表征
- 相对位置表征应该和绝对位置无关以及句子长度无关
- 编码可以泛化到训练样本之外的句子长度
于是便有了基于三角函数的编码方式,在pos位置,维度是\(d_k\)的编码中,第i个元素的计算如下
\[PE(pos, i)= \begin{cases} sin(w_k \cdot pos)& \text{if i=2k}\\ cos(w_k \cdot pos),& \text{if i=2k+1} \end{cases} \]\[w_k = \frac{1}{10000^{2k/d_{model}}} \]基于三角函数的绝对位置编码是常数,并不随模型更新。在Transformer中,位置编码会直接加在词向量上,输入的词向量Embedding是E,在self-attention中Q,K进行线性变换后计算attention,对value进行加权得到输出如下
\[\begin{align} q_i &= (E_i+P_i) \dot W_q^T \\ k_j &= (E_j+P_j) \dot W_k^T \\ v_j &= (E_j+P_j) \dot W_v^T \\ a_{i,j} &= softmax(q_ik_j/\sqrt{d_k}) \\ output &= \sum_{j}v_j * a_{i,j}\\ \end{align} \]我们来对\(q_ik_j\)部分进行展开可以得到
\[\begin{align} q_ik_ j&=E_iW_qW_K^TE_j^T(语义交互)+ P_iW_qW_K^TP_j^T (位置交互)\\ & + P_iW_qW_K^TE_j^T(query语义*key位置) + E_iW_qW_K^TP_j^T(key语义*query位置) \\ \end{align} \]其中位置交互是唯一可能包含相对位置信息的部分,如果不考虑线性变换\(w_k\),\(w_q\)只看三角函数位置编码,会发现位置编码内积是相对距离的函数,如下
\[\begin{align} P_iP_j^T & = P_iP_{i+\Delta}^T \\ & = \sum_{k=0}^{d_k/2-1}sin(w_k \cdot i)sin(w_k \cdot (i+\Delta)) + cos(w_k \cdot i )cos(w_k \cdot (i+\Delta))\\ & = \sum_{k=0}^{d_k/2-1}cos(w_k \cdot(i-(i+\Delta))) =\sum_{k=0}^{d_k/2-1} cos(w_k \cdot \Delta) \end{align} \]不同维度\(d_k\),\(P_iP_j^T\)和\(\Delta\)的关系如下,会发现位置编码内积是对称并不包含方向信息,而BiLSTM是可以通过双向LSTM引入方向信息的。对于需要全局信息的任务例如翻译,sentiment analysis,方向信息可能并不十分重要,但对于局部优化的NER任务,因为需要判断每个token的类型,方向信息的缺失影响更大。
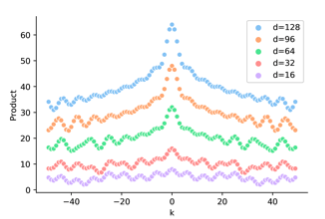
看完三角函数部分,我们把线性变换加上,下图是加入随机线性变换后\(P_iw_iw_j^TP_j^T\)和\(\Delta\)的关系,会发现位置编码的相对距离感知消失了,有人会问那这位置编码有啥用,这是加了个寂寞???

个人感觉上图的效果是加入随机变换得到,而\(W_i,W_j\)本身是trainable的,所以如果相对距离信息有用,\(W_iW_j^T\)未必学不到,这里直接用随机\(W_i\)感觉并不完全合理。But Anyway这两点确实部分解释了原生transformer在NER任务上效果打不过BiLSTM的原因。下面我们来看下基于绝对位置编码的缺陷,都有哪些改良
相对位置编码
既然相对位置信息是在self-attention中丢失的,最直观的方案就是显式的在self-attention中把相对位置信息加回来。相对位置编码有很多种构建方案,这里我们只回顾TENER之前相对经典的两种(这里参考了苏神的让研究人员绞尽脑汁的Transformer位置编码再一次膜拜大神~)。为了方便对比,我们把经典的绝对位置编码计算的self-attenion展开再写一遍
\[\begin{align} q_ik_ j&=E_iW_qW_K^TE_j^T + P_iW_qW_K^TP_j^T + P_iW_qW_K^TE_j^T + E_iW_qW_K^TP_j^T \\ a_{i,j} &= softmax(q_ik_j/\sqrt{d_k}) \\ output &= \sum_{j}v_j * a_{i,j}\\ \end{align} \]RPR
(shaw et al,2018) 提出的RPR可以说是相对位置编码的起源,计算也最简单,只保留了以上Attention的语义交互部分,把key的绝对位置编码,替换成key&Query的相对位置编码,同时在对value加权时也同时引入相对位置,得到如下
\[\begin{align} q_ik_ j&=E_iW_qW_K^TE_j^T(语义交互)+ E_iW_qR_{ij}^T(相对位置att语义) \\ output &= \sum_{j}v_j * (a_{i,j} + R_{ij})\\ \end{align} \]这里\(R_{ij}\)是query第i个字符和key/value第j个字符之间的相对距离j-i的位置编码,query第2个字符和key第4个字符交互对应\(R_{-2}\)的位置编码。这样的编码方式直接考虑了距离和方向信息。
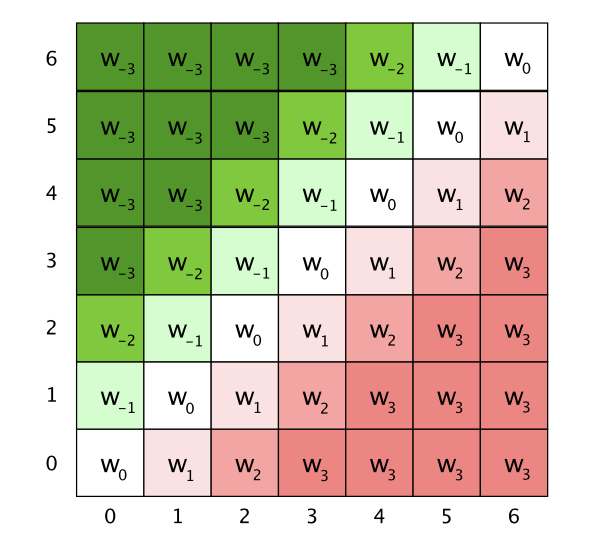
这里的位置编码PE是trainable的变量,为了控制模型参数的大小,同时保证位置编码可以generalize到任意文本长度,对相对位置做了截断,毕竟当前字符确实不太可能和距离太远的字符之前存在上下文交互,所以滑动窗口的设计也很合理。如果截断长度为k,位置编码PE的dim=2k+1,下图是k=3的\(R_{ij}\)
\[R_{ij} = PE[min(max(i-j,-k),k)] \]
Transformer-XL/XLNET
(Dai et al,2019)在Transformer-XL中给出了一种新的相对位置编码,几乎是和经典的绝对位置编码一一对应。
- 把key的绝对位置编码\(p_j\)替换成相对位置编码\(R_{ij}\)
- 把query的绝对位置编码\(W_ip_i\),替换成learnable的两个变量u和v,分别学习key的语义bias和相对位置bias,就得到了如下的attention计算,
以上计算方案也被XLNET沿用,和RPR相比,Transfromer-XL
- 只在attention计算中加入相对位置编码,在对value加权时并没有使用,之后相对位置的改良基本都只针对attention部分
- PE沿用了三角函数而非trainable变量,所以不需要截断k=max_seq_len。不过加了线性变换\(W_R\)来保留灵活性,且和绝对位置编码不同的是,位置编码和语义用不同的W来做线性变换
- 加入了全局语义bias和全局位置bias,和绝对位置编码相比每个term都有了明确的含义
TENER:相对位置编码的NER模型
TENER是transformer在NER任务上的模型尝试,文章没有太多的亮点,更像是一篇用更合适的方法来解决问题的工程paper。沿用了Transformer-XL的相对位置编码, 做了两点调整,一个是key本身不做project,另一个就是在attention加权时没用对attenion进行scale, 也就是以下的归一化不再用\(\sqrt{d_k}\)对query和key的权重进行调整,得到的attenion会更加sharp。这个调整可以让权重更多focus在每个词的周边范围,更适用于局部建模的NER任务。
\[a_{i,j} = softmax(q_ik_j/\sqrt{d_k}) \]我们来直观对比下,同样的数据集和模型参数。绝对位置编码和unscale的相对位置编码attention的差异,这里都用了两层的transformer,上图是绝对位置编码,下图是unscale的相对位置编码。可以明显看到unscale的相对位置编码的权重,在第一层已经学习到部分周围信息后,第二层的attention范围进一步缩小集中在词周围(一定程度上说明可能1层transfromer就够用了),而绝对位置编码则相对分散在整个文本域。

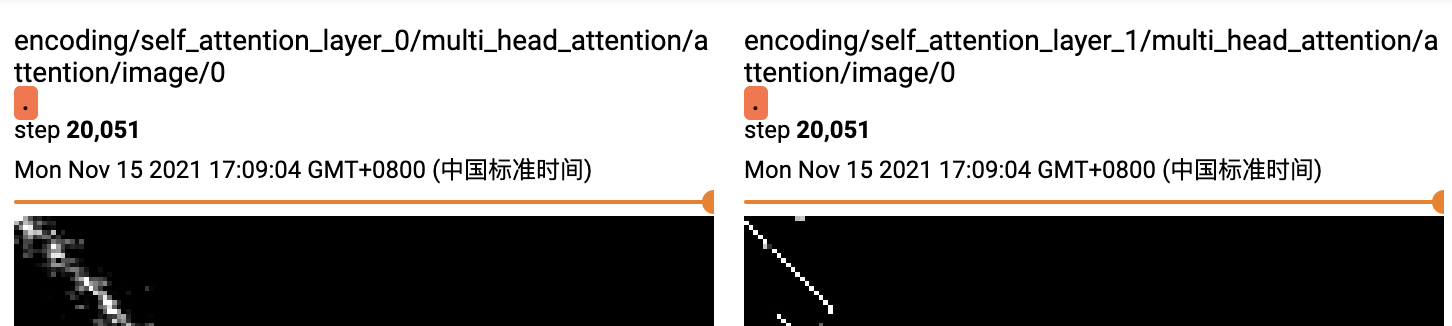
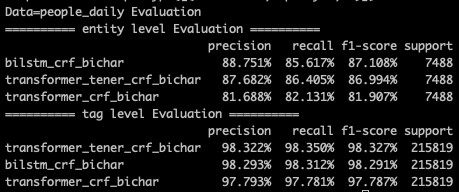
下面来对比下效果,transformer任务默认都是用的bichar输入,所以我们也和bilstm_bichar进行对比,在原paper中作者除了对句子部分使用transformer来提取信息,还在token粒度做了一层transformer,不过这里为了更公平的和bilstm对比,我们只保留了句子层面的transformer。以下是分别在MSRA和PeopleDaily两个任务上的效果对比。
只是把绝对位置编码替换成相对位置编码,在两个任务上都有4~5%的效果提升,最终效果也基本和bilstm一致。这里没做啥hyper search,参数给的比较小,整体上transformer任务扩大embedding,ffnsize效果会再有提升~

REF
- TENER: Adapting Transformer Encoder for Named Entity Recognition, 2019, Hang Yan
- Self-attention with relative position represen- tations
- Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
- XLNet: Generalized Autoregressive Pretraining for Language Understanding
- 苏剑林. (Feb. 03, 2021). 《让研究人员绞尽脑汁的Transformer位置编码 》[Blog post]. Retrieved from https://kexue.fm/archives/8130
- 工业界求解NER问题的12条黄金法则
标签:编码,Transformer,attention,TENER,align,位置,iW,相对,NER 来源: https://www.cnblogs.com/gogoSandy/p/15565803.html