我在b站读研究生——跟着李沐读论文1 ——Gan
作者:互联网
我在b站读研究生——跟着李沐读论文1 ——Gan
目录- 我在b站读研究生——跟着李沐读论文1 ——Gan
- 读论文
- 感悟与想法
- 感谢
读论文
标题+作者+时间+期刊+被引


generative adversarial Nets 生成对抗网络
作者 Ian J.Goodfellow 深度学习(花书)的作者
摘要 Abstract
我们推出了一个通过对抗过程来估计生成模型的新的结构,在这个结构中,我们同时训练两个模型:一个是探索数据分布的生成模型G,另一个则是用来估计数据是否来自训练数据而非G生成结果中概率的判别模型D,G的训练程序用来最大化D犯错误的概率。这一结构模拟了MiniMax二人博弈,在任意G和D的空间中,存在唯一的解决方案使得G能够恢复训练数据的分布情况,此时的D总等于\(1/2\)。在G和D使用多层感知机定义的情况下,整个系统可以使用反向传播进行训练。在训练或生成样本时,不需要马尔可夫链或事展开的近似推理网络,实验通过对生成样品进行定性并量化评估来证明这一框架的能力。
1 Introduction 导言
2 Related work 相关工作
3 Adversarial nets 模型
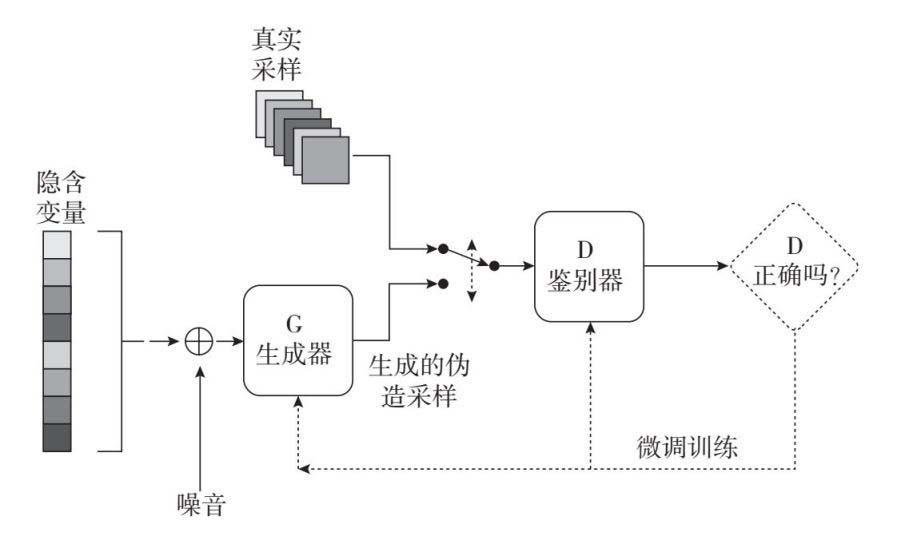
目标函数
\[min _G \ max_D V(D,G) = E_{x \sim p_{data(x)}}[logD(x)] + E_{z \sim p_{z(z)}}[log(1-D(G(z)))] \]真实数据\(x\)分布\(p_g\) , 噪声\(z\)服从分布\(p_z(z)\) , \(D\)表示鉴别器 , \(G\) 表示生成器
我们首先看为什么是\(max D\).
我们先看公式的前一项, \(x\)服从真实分布,当鉴别器\(D\)的辨别能力很强时,能够把所有真实样本识别出来,标记为1,此时\(log(D(x))\)的结果为0 。接着,看公式的后一项, \(G(z)\)是生成器生成的伪造样本,当鉴别器\(D\)的辨别能力很强时,能够把所有伪造样本识别出来,标记为0,此时\(log(1-D(G(z)))\)的结果为0。但是上面的分析是假设鉴别器是很完美的情况,当不完美时,两项结果都是负数值,所以我们想要一个很好的分类器的话,我们需要求目标函数最大值。
接着看为什么是\(min G\)
上式中,伪造样本的结果只与第二项有关。当生成器能力很强时,鉴别器无法区分,则将伪造数据\(G(z)\)识别为真,即\(D(G(z))=1\) ,则\(log(1-D(G(z)))\)为负无穷,所以我们想要一个很好的分类器的话,我们要求目标函数最小值。
但这个公式也存在问题。在前期,生成器能力较弱,识别器识别效果过好会导致后一项结果为0,不能继续求梯度。于是作者给出的建议是将\(log(1-D(G(z)))\)改为\(log (D(G(z)))\) ,这样的话会避免结果为1,丧失梯度,但是此时值为负无穷,也有问题。
4 Theoretical Results 理论
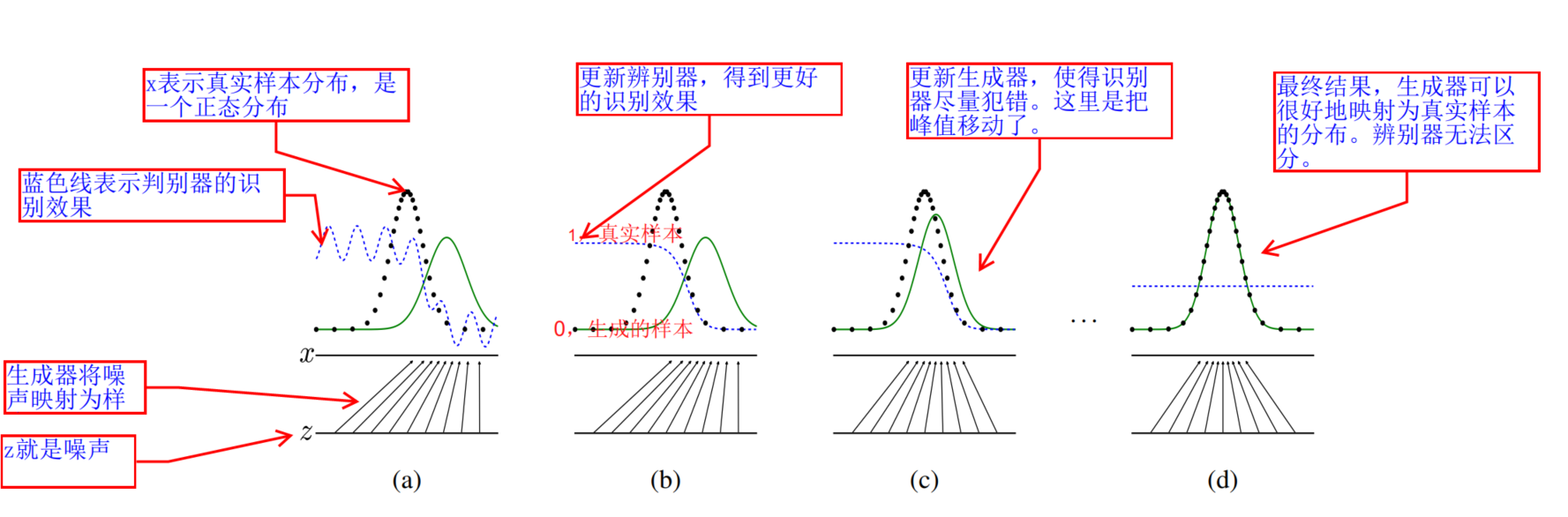
算法
训练过程形象的图示

4.1 global Optimality of \(p_g = p_{data}\)
proposition 1.
\[For \ G \ fixed , the \ optimal \ discriminator \ D \ is \\ D*_G(x) = \frac{p_{data}(x)}{p_{data}(x)+p_g(x)} \ \ (2) \]proof :
理解:如果生成器\(G\)确定下来,那么对于鉴别器D , 它的最优解为 。我们看这个公式,这个公式就是用来检测两块数据是否是来自于同一分布。当\(p_{data}=p_g\)时,\(D=1/2\) ,分类器对于输入样本x,都输出1/2,完全无法区分,也就是两类数据来自于同一分布
Theorem 1 .
\[ \text {The global minimum of the virtual trainijng criterion C(G) is achieved if \ and \ only \ if } \\ p_g = p_{data} . \\ \text{At that point , C(G) achieves the value} \ -log4. \]Proof
理解; 要想生成器G取得最优解,当且仅当 生成器伪造数据的分布等于真实数据的分布 。
4.2 Convergence of Algorithm 1
Proposition 2 .
\[If \ G \ and \ D \ have \ enough \ capacity, \ and \ at \ each \ step \ of \ Algorithm 1, \\ the \ discriminator \ is \ allowed \ to \ reach \ its \ optimum \ given \ G, \\ and \ p_g \ is \ updated \ so \ as \ to\ improve \ the \ criterion \\ E_{x \sim p_{data(x)}}[logD^*_G(x)] + E_{z \sim p_{z(z)}}[log(1-D^*_G(x))] \\ then \ p_g \ converges \ to \ p_{data} \]5 Experiments 实验


6 Advantage and disadvantage 优缺点
7 Conclusions and future work 总结与展望
感悟与想法
1 根据李沐大神的描述,这个想法并不是原创的,虽然做的时候是自己做的,但是是和前人重合了。但是依然收到了广阔欢迎,是因为他教会了大家,引发了大家的兴趣。有人乐意跟随他,我们从引用数量中也可以看出这一篇文章之后有3,4万篇文章。
2 写作。摘要很简洁,因为这是原创的工作,上来就是propose a new framework 。但是我们在跟随前人工作的时候就要写清楚我们的改进在什么地方,有什么好处。
感谢
作者:杜若飞er
链接:https://www.jianshu.com/p/a7d7955512c3
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
标签:研究生,work,log,样本,生成器,鉴别器,Gan,李沐读,data 来源: https://www.cnblogs.com/zuti666/p/15563792.html