HTTP 缓存终极指南
作者:互联网
TL;DR
- 错误的缓存策略是如何抵消你所做的性能优化工作的。
- 缓存存在于客户端并且通过chrome或者其他抓包工具查看其状态信息。
- 客户端通过
header中的各个字段做缓存的过期判断。 - 代理服务器上也存在缓存,并且使得我们在计算浏览器缓存时变得复杂了。
- 合理地配置缓存的策略能有效的提示网页访问速度。
- W3C标准定义了一些异常的缓存情况。
- 缓存与
SW应该合理的使用,避免不必要的网站奔溃。
开篇
你辛辛苦苦把代码压缩,打包,甚至把所有的 **forEach** 改成了for 循环以便提高js的运行速度,可是这还不如缓存做的十分之一;你日赶夜晚赶,学会了FP, FMP, LCP等一大堆苦涩又无聊的术语,为了提升网页的渲染速度,但是缓存仍旧做得比你多。你不甘心,把js同构输出,将CSR改成SSR,可是缓存轻轻松松地就达到了迅速加载的目的;后来你下决心,把http1.x换成了http2,终于将网页首屏打开时间控制在了1s以内。缓存看着你,会对你笑一笑,多路复用不如一路都不用。
这就是缓存的魔力,即便你穷尽所有能优化网页手段,它也会比你做得更多,更快。如果说非要有其他手段和它媲美,那么只有只有ServerWorkder了,不过说到底,SW也算是一种缓存。所以我们可以说,没有什么比浏览器缓存更快得提高网页打开速度,当然,除了内存中的缓存外。
不过我们说到了这么多缓存的厉害程度,遗憾的是,前端工程师在他的领域内对缓存基本上无法控制。除了html意外,几乎所有的缓存设置都在服务器上。但这并不妨碍我们去了解他是怎么工作的。
初识缓存
- 什么缓存
HTTP缓存是服务器与客户端通讯时一种存储策略。每次客户端去服务端请求资源(静态文件,XHR,JSON)时,都需要建立HTTP链接,这种链接很昂贵,反复传输重复的信息不仅仅会很低效,而且还会占用宽带资源给源服务器造成压力。HTTP缓存要解决的就是这些问题。
- 存在哪里
你的电脑里。是的,我没在讲笑。因为存在别人的电脑里或者存在服务器上(也是别人的,除非你很有钱去买服务器)就不叫缓存。所谓缓存要解决的事情,就是去最近的地方,用最快的方式拿到之前就给你的东西。如果要准确地说是存在你的电脑磁盘上或者运行的内存中,具体是哪一种取决你是怎么样访问网页。(刷新还是重启电脑或者浏览器?)
- 怎么存
用HTTP协议通信。服务器与客户端通信是通过HTTP协议的,返回的每个资源中的header头部都会有一段关于缓存的信息,它包含了浏览器存储它的规则,里面包含了缓存的时长,剩余时长,过期时间等信息。这些信息决定了浏览器下次对这个资源想服务请发起请求前需要做的一些列动作,以及之后的交互动作。
- 怎么找
https://(protocol:协议)****www.example.com(domain:域名):443(port:端口)/path/to/file.html( path:路径)?dog=puppy&cat=kitty( parameters:参数)#cow=calf(hash:界面位置)
客户端第一次向服务器请求资源,如果该资源有缓存指令,那么客户端会将缓存存入内存中,并且用上面这段资源地址标识生成一个hash值(不同的浏览器生成规则不一样),作为该缓存资源查找的key值,从而建立映射关系表。浏览器重新发起请求会对资源表示符进行同样的转化,去缓存地址中查找。URI中的任何改动都会导致hash值的变化,进而无法找到缓存,客户端就重新取请求资源。
观察缓存
在Chrome中就可以看到缓存的状态,打开Chrome的NetWork面包,开始抓取网络请求。刷新界面,看到很多请求被抓取并且显示到面板中。这里,我们重点关注三条栏目的状态status, size 以及 time。在status这一栏我们看到了当前http的状态:200和304。

我们首先来解释200,如果仔细看会发现有些200状态是灰色显示,有些是深色。深色的标识这个请求被浏览器一次性返回了所有你要的资源,并且是成功状态。灰色的200 说明 本次是从被缓存中读取的资源了,浏览器获取这个资源时并未与服务发送通讯。
然后我们观察304,304的出现说明当前资源也使用缓存,但是!我们仍然与服务器通讯了,只不过,服务没有返回给我们资源实体,而是返回给我一段消息,这段消息告诉了浏览器,请使用之前你缓存过的资源。
为了更详细地说明我们可以把目光聚焦到time这一行,time标识的是我们从服务器交互的时间。可以清楚的看到,深色200标识的资源会经历181ms的,而浅色200的这一行time显示的是0,即表示本次网络请求从缓存中读取,不与服务器交互。而304状态哪一行的time只有15ms,这说明了虽然304读的是缓存,它仍然会与服务器通讯。之所以size和time都很小,是因为这个http包体积内容非常少,比返回整个资源包要,只需要消耗1个Roundtrip即可。
最后我们关注size这一行,size标识的是本条http请求的的大小以及状态。我们可以从这里直观的看懂缓存的运用。它的值大概有这样积累
- 正常的数值:标识为正常与服务器通讯
- memory chache:从运行内存中读取缓存
- disk cache:从磁盘中读取缓存
他们的速度排序从慢到快依次是:2,3,1. 可以看到,我们获取资源的时间从181ms 到 15ms 再到 0ms,说明了缓存在解决首屏资源加载上所作的贡献十分突出。
理论上来讲,从运行内存中缓存读取速度也是大于磁盘中读取的速度。
到这里,我们知道了缓存也是有区别的,他们在http中的状态区分是304和浅色200,一般来说,我们为了区分这两种缓存,分别给他们命名为协商缓存和强制缓存。顾名思义,就是一个需要通过一些规则(后面提到)需要与服务通信,而另外一种则完全不需要。
缓存指令
我们知道了观察http缓存的转态,接着就去认识一下它的具体规则标识。这些信息都包含在http请求头里面。任意点击Network中的一条资源,观察它的Response header标识信息。
HTTP/1.1 200 OK
Age: 600
Date: Fri, 30 Oct 2020 13:19:41 GMT
Cache-Control: max-age=3600
Expires: Fri, 30 Oct 2020 14:19:41 GMT
Etag: "16e36-540b1498e39c0"
Last-Modified: Mon, 07 Nov 2016 07:51:11 GMT
curl 'url-address' --compressed -I # 在控制台中敲入命令,也可以很快地查看资源返回头
Cache-Control:这是服务器指导客户端如何存储和读取缓存的主要指令。上文中它的值为max-age=230000,意思是指导客户端缓存这个资源23000秒的时间。cache-control指令的指非常多,下面我们线逐一介绍他们应用他们的含义以及运用场景
max-age=<seconds>
如前所示,Cache-Control: max-age=3600 的出现标识客户端存储缓存的具体时长。浏览器更具这个时长与其他字段进行计算,得到缓存是否过期的结果。针对不同的资源,我们配置的是不同的时间。
no-cache
no-cache标识这个资源文件不应该强制缓存,每次http请求都应该去服务器上验证是否过期。这个标识经常用到重要切频繁变动的静态资源文件上。
no-store
此标识指示浏览器不允许任何缓存,每次都需要去服务器上获取资源。这种标识应该不应该经常出现,它相当于屏蔽了http缓存功能,这样做的代价很高昂,除非你又特殊需求。
private
指示缓存服务器对特定客户缓存。缓存服务器会对该特定用户提供资源缓存的服务,对于其他用户发送过来的请求,代理服务器则不会返回缓存。
must-revalidate:
缓存不仅仅存在于浏览器,也会存在于代理服务器上。如果源服务器和浏览器之前有代理服务器,那么这条指令就会指示代理服务器每次浏览器与代理服务器请求时,代理服务器都需要去原服务器上验证资源的过期时间。这种做法虽然保持了时刻与原服务器的资源同步,但是也增大了源服务器的压力,
proxy-revalidate:
这条指令指示代理服务器和浏览器可以缓存,但是过期了,必须去源服务器上去获取最新的资源。
max-stale=<seconds>
指示服务器在缓存过期后还需要等待多少秒才向服务器发送请求。一搬来说很多人希望缓存永远不过期。可以指定该指令。
min-fresh=<seconds>
强制缓存的最小时间。表示该资源至少要经过min-fresh秒才算过期。这个指令可以用来解决代理服务器带来缓存过短的问题。后面我们会详细介绍到。
s-maxage
最大缓存时间,这条指令会覆盖max-age等其他指令,但是对指明了private的资源不起作用。
- Expire: 除了cache-control之外,浏览器还提供了一个回退的标识。它的优先级是较低的。它的存在属于老旧的规范和兼容。
expire简单明了的设置了强制缓存的过期时间,一旦过了这个时间,资源就需要重新从服务器上取。但也正是因为它直接,所以在可配置方面显得不够灵活,不能适应各种场景需求,因此被后者代替。但是新的浏览器也支持这个表示。只不过现在浏览器会去优先读取cache-control。
expire里面的时间是标准的格林威治时间,所以在判断的时候徐亚对应本地时间计算一下。
- Age: 我们每次获取的资源文件不一定是从原服务器上获取到的。为了提高web的性能,部署的时候我们经常会把资源部署到各个地方的代理服务器上,以便减少物理距离。所以在客户端到原服务器上很多时候都会有一个或者几个代理。如果age出现在了header中,那么可以断定,该资源是从代理服务器上获取的。age这个字段就是以源服务器最后一次响应时为起点,到浏览器获取时的时段。它计算起来稍微有点复杂,但是它很重要。因为依靠它,浏览器才能决定强制的缓存是否过期。
In essence, the Age value is the sum of the time that the response has been resident in each of the caches along the path from the origin server, plus the amount of time it has been in transit along network paths.
这个是w3c的对Age的定义,本质上,他是两段时间的总和:资源自离开源服务器开始,到目前为止被存储在客户端的时间,以及文件在网络中被传输的时间总和。
-
Date****:标识此服务器最后一次响应此此条资源的时间。Date标识的是服务器时间,这个服务器是源服务器还是代理服务器取决于我们最后通讯的对象是谁。我们后面会用到这个段信息来计算一个缓存是否已经过期。
-
Etag****:是文件的唯一标识,它根据文件的内容生成的,任何内容上的变化都会导致这个值的变化。相当于我们平时用webpack打包生成的hash一样,是一个唯一标识。
-
Last-modifed****:则服务器上文件的最新更新时间,它表示文档何时被修改。
除了以上存在于response header中的指令,在request header中,我们也可以看到它们的身影,只是它们在命名上稍微有点差异。例如Last-modifed在request header中体现为If-modifed-since,If-None-Match则是respone中Etag的标识。而另外一个指令Cache-Control也可以由开发者在html的meta标签添加,告诉服务器优先使用浏览器指定的缓存指令返回资源,而不是用服务器的。

计算规则
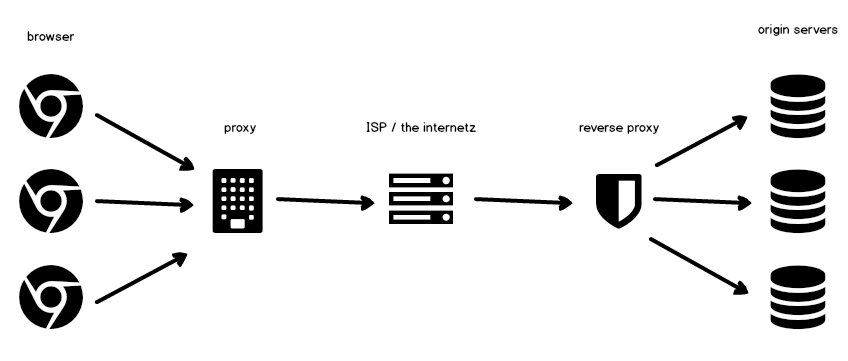
大多数时候,我们都以浏览器和源服务器通讯来作为缓存的查看,观察到缓存只存在浏览器上,并且知道缓存的存储时长和缓存的过期时间。但是,现实中为了减少源服务器的压力以及其他网络分发需求,源服务器与客户端浏览器之间会存在很多个代理服务器(proxy server),代理服务器上也有缓存计算时间,这些代理的服务器的存在使得缓存概念变得稍微复杂了一些,我们观察到的出现在浏览器中的缓存是经过了很多次中转才最终到达浏览器的。因此,要计算缓存的剩余过期时间需要一套算法。这套算法是怎么计算缓存过期时间的呢?下面我们就由潜入深说明:
- 假设我们不考虑中间代理服务器,
age为0,不考虑资源包在网络中的传输时间,即request_time和response_time都为0,并且客户端的时钟与服务器上的一致,并且当前时间为格林威治标准时刻: 2020-10-30 13:20:41。给出下面一段http头,我们来计算当前剩余缓存是否过期:
HTTP/1.1 200 OK
Date: Fri, 30 Oct 2020 13:19:41 GMT
Server: Apache/1.3.3 (Unix)
Cache-Control: max-age=600
Content-Length: 1040
Content-Type: text/html
//公式计算如下
now(客户端当前时间 Fri, 30 Oct 2020 13:20:41 GMT) - Date(Fri, 30 Oct 2020 13:19:41 GMT) <= max-age(缓存时长 600s);
// true;改缓存未到期,可以继续使用。
Date 指格林威治标准时间,因此,我们需要将本地时间做转换再计算。
这个计算相当简单,浏览器与服务器最后的通讯时间与当前时间的差值,就表示该资源在浏览器本地保存的时长,我们拿这个时间与最大缓存时间(max-age)对比,就知道该资源缓存是否过期了。

- 现在我们在浏览器与服务器之间架设一台CDN代理服务器用来较少源服务压力,提高资源加载速度。但是仍然不考虑网络时延,并且假设客户端与服务器的时钟一致,给出一下response header 信息,计算此刻缓存是否有效。
HTTP/1.1 200 OK
Age: 600
Date: Fri, 30 Oct 2020 13:19:50 GMT
Server: Apache/1.3.3 (Unix)
Cache-Control: max-age=3600
Content-Length: 1040
Content-Type: text/html
Age: 服务器上缓存储存的时间
Client_resident_time = now(客户端当前时间) - Date(服务响应时间当前时间) #在缓存浏览器上停留的时长
Client_current_age = Age + Client_resident_time; # 缓存在代理服务器和在浏览器上总共停留的时长
Client_current_age > max-age // true
现在我们的计算稍微复杂了一些,Client_resident_time 计算的是现在距离最后一次代理服务器响应浏览器的时间,这个时间表示了该资源存在浏览器有多久了。而Age计算的是代理服务器上缓存资源的时长。所以,资源被缓存的实际时长就是这两段时长的和:第一段是缓存在代理服务器上的时长Age,第二个则是缓存在浏览器上的时长Now - Date。

- 资源包在网络中传输中是需要花费时间的,因此,我们最后一种情况需要把这种网络时延加入计算的变量当中。不同的设备在不同的环境下都会存在网络传输过长的问题,这段时间并不是固定的,它与你所处的地理位置有关系。我们大致通过收发时间差来计算这段时间为
response_delay。下面是w3c标准列出来的计算缓存过期的方法。通过这个计算出来的值与max-age和expired做对比,最终判断本地缓存是否过期。
/*
* age_value:header中的Age
* is the value of Age: header received by the cache with
* this response.
* date_value :header中的Date
* is the value of the origin server's Date: header
* request_time:首次发送请求资源时间
* is the (local) time when the cache made the request
* that resulted in this cached response
* response_time: 首次接受资源请求时间
* is the (local) time when the cache received the
* response
* now:本地当前时间
* is the current (local) time
*/
//计算资源在网络中传输的时长
apparent_age = max(0, response_time - date_value);
//如果存在中间代理服务,取age,如果不存在代理服务器,age就可以表示网络包传输的时长
corrected_received_age = max(apparent_age, age_value);
//计算从资源发送到接受的这段时长
response_delay = response_time - request_time;
//将age和来回的延迟时间相加,计算实际的age时间。
corrected_initial_age = corrected_received_age + response_delay;
//缓存在本机上的实际时长
resident_time = now - response_time;
//从原服务器到现在缓存在你本地机器上的的时间
current_age = corrected_initial_age + resident_time;
上面的公示计算很简单,但要理解它们的意义可能需要花点时间。总的来说它是将网络延迟加入计算中,得出的缓存过期时间。我建议你去读几遍w3c的原文档,多读几遍也许就自然懂了。
综上所述,缓存不仅仅是指存在浏览器上,而是存在任何客户端上。这些客户端指的是非源服务器的机器,其中包括了代理服务器。
观察资源是否从代理服务器上获取还可以通过via标识来判断。它标识了代理服务器的信息。
所以,在计算缓存的时候并不是只是凭借cache-control和expired两个字段来简单推导的。代理服务器上从接受源服务器的资源开始,便自己维护了定时器,定时器过期之前,代理服务器不在向源服务器发起请求。这样做显著地减少了源服务器的压力。但是如果源服务器上的资源在缓存时长内被修改,那么我们的客户端就不再会收到最新的资源。你可以用cache-control: private这样的设置来避免中间服务器被缓存,但是你这样做却是一刀切得把CDN这样的工具效用降低。很多CDN提供商都提供了缓存刷新机制,这种操作相当于是在它们的代理服务器上强制清楚了缓存,就跟我们在network中选中disable cache一样。
因为代理服务器的关系,资源缓存在浏览器上停留的时长会比实际上源文件设置的max-age更短。有时候客户端实际缓存的时间会非常短,为了解决这个问题,可以强制一个缓存最小时间。指定cache-control: min-fresh=xxxxx,来告诉客户端至少缓存多少秒才重新请求。
通过计算,我们得到了一个应用本地缓存的结果。如果计算结果大于0,说明强制缓存的还未过期了,不需要重新请求,我们可以直接将缓存独处,交给渲染进程处理。这个过程,网络进程不参与其中。而如果计算结果小于等于0,强制缓存的阶段就结束了,开始我们另外一套流程:
此时,浏览器会携带head中的两个字段信息发往服务器,一个是If-None-Match(Etag),另外一个是Last-Modified-Since(Last-Modified)。前者是文件的唯一标识,它根据文件的内容生成的,任何内容上的变化都会导致这个值的变化。相当于我们平时用webpack打包生成的hash一样。last-modifed则服务器上文件的最新更新时间,它表示文档合适租了最后一次修改。客户端就是发起了这样一个http请求,携带两个信息。服务器收到请求后,综合两个信息去对比当前的文件状态。如果匹配不上,服务端返回最新的的资源 200 ,如果匹配上,返回一304,告知浏览器继续用此资源。
# Request Header
HTTP/1.1 200 OK
If-Modified-Since: Mon, 29 Jun 1998 02:28:12 GMT
If-None-Match: "3e86-410-3596fbbc"
- etag的优先级高于last-modified。服务器上的有些文件,往往定期更新文件日期,对于准确的衡量文件的新鲜度,etag最为适宜。
- 但过度依赖etag会造成性能损耗。etag对生产需要服务器对文件内容做加密处理,以便得出最新的etage的值与传过来的值作比较。
合理的策略
既然这样,缓存在提升首屏资源加载性能上这么有用,我们是不是可以把每个缓存资源设置超长的过期时间呢?不能说这个说法错误,毕竟每个人面对的业务是不同的。如果你的网站是个类似于政府企业或者个人展示的网站,设置越长的过期缓存时间就越能提升加载界面的用户体验。但是日新月异的互联网来说,唯一不变的就是变化。在我们实际工作中如果设置了超长的缓存时间,你辛辛苦苦加班的工作,可能任何人都看不到。
缓存终归到底,是一项应用技术,它的学习成本不是很高,很多人都可以以很短的实际学会去设置。它的计算规则交由浏览器和服务器按照标准规范实现的自动计时机制,我们应该更多的关注如何建立合理的缓存策略,在不损害Web的优势前提之下,取得缓存与性能的平衡。以下是我们对于配置合理缓存策略的几点建议:
- 图片长期缓存
图片是所有静态文件中数量最多,体积最大的。虽然它不阻塞dom的解析,但是它对客户端的流量消耗十分显著。对于那些图片内容居多的网站来说,图片的加载与否,是决定用户期待首屏出现心里时间的标准。因此,我建议你把图片的时间做长期缓存。至于这牺牲了图片替换的便捷性,我们只能说需要在两者之前取的平衡。
- 协商缓存html文件
html文档是一切资源文档的入口,如果入口做了强制缓存,意味着很多依赖资源文件无法更新都只能使用缓存状态。所以,推荐使用协商缓存,每次都发送一小段信息片段去做服务器上的新鲜度校验,以保障文件的及时更新。另外还有一个重要原因永远保持html最新是因为javascript是可以操作dom的!!想像一下这种情况:a.html由于被强制缓存而未更新,而js却是最新的,这样导致了最新的js操作的是一份老旧的dom文档。这钟情况就是造成js报错。像下面的这还的常见错误一样:
document.getElementById('newId').innerHtml = "New version published!!!!"
//Uncaught TypeError: Cannot set property 'innerHtml' of null
因此,在HTML文档的Mate标签中,我们建议加上cache-control=no-cache,来告诉服务器不需要强制缓存html界面,尤其是在富客户端的应用中,HTML的初始加载的内容会较少。
<meta http-equiv="cache-control" content="no-cache">
- 对公共资源缓存
对于公共组件或者第三方库,建议你长时间的强制缓存,很多开源的类库依旧有CDN做托管。如果时通过npm包引入的话,借助构建工具webpack或者rollup等,可以轻松做到分离并且缓存代码。而对于业务代码,你可以设置较短时间的强制缓存,具体根据你们的上线发布频率来决定。比如你们公司固定上线时间窗口是每周三凌晨2点。你直接设置expired的过期在这个时间点即可。但也有很多上线窗口不确定情况,我建议你以最小间隔时间为强制缓存时间。比如,你们的发布时间有时候是一周,有时候一个月,有时候又是24小时,对于这样的情况,取24小时为适宜。
- 资源环境的版本策略
请确保你的html与静态资源(css、javascript)等一致。如果你担心他们不同步,我建议你为每一个静态资源添加一个版本号后缀。每次修改引用后缀,手动修改版本号后缀。
- 数据缓存
严格来说,我们是不需要缓存数据的,毕竟数据这种实时性很强的信息不太适合缓存。不过,决定权依然在你的手上,根据自己的业务需求来缓存数据,也是提供客户体验的一种方式。值得注意的是只有get请求可以被缓存,post请求是无法被缓存的。get缓存也不经常发生,通常在html界面的跳转和回退操作上。
-
404 206也可以被缓存
-
测试环境
测试环境下不建议使用强制缓存,毕竟这是文件资源经常变动的环境。我们在这里吃过亏,所以特意写下来当作一个知识点,以保证看过这篇文章之后不会有同事在测试环境调试代码时总是摸着脑袋问你自己的代码怎么不起作用。
小知识
关于缓存的大多数知识我们在上面已经差不多讲完了。在阅读W3C标准规范的时候,我们也发现了一些经常被忽略的小知识,下我们列出来,希望对你有帮助:
**
- 10%
如果cache-control和expired 都未出现在你的http response头中,浏览器也会为当前资源做缓存。规则是取资源最后一次被修改的时间与服务器最后一次响应间隔的时长的十分之一。如果到期了,就开始请求新的url。相当于浏览器自动给你计算了一个cache-control值。当然,这是标准规范,不是所有浏览器都实现了。
Cache-control: max-age=(Date - Last-modified) * 0.1
W3C称这种方式为启发式(heuristic)缓存。是除了强制缓存和协商缓存之外的第三种缓存规则。
- Now
资源处于强制缓存期间浏览器不与服务器通讯,浏览器计算资源是否过期的定时器就需要客户端自身去维护,而客户端的时间是可以被修改的。所以,如果你修改了客户端的时间,是会改变缓存的新鲜度的。
- disable cache
你是否会使用Chrome浏览器中的NetWork面板,当我们启用disable cache时,我们都会看到原来浅色的200都变成了深色,说明了虽然缓存还未到期但本次却不再从缓存中读取资源而是从服务器上读取。如果你自己观察,就会发现,当我们勾选这个选项时,浏览器会自动帮我们为每个http请求加上一段request请求指令:pragma: no 和 cache-control: no-cache,此时我们看到,age却依旧存在。这是因为我们虽然强制了浏览器上的缓存清除,但是代理服务器上的缓存却还是存在的。你设置 cache-control:must-revalidate 来指示代理服务器每次都去源服务器上验证资源是否有效,以此保证同原服务器上的资源保持同步。当然这也会引起其他的服务器性能问题。
- 缓存与SW
ServiceWorker(SW)也有自己的生命周期以及函数,它也有自己的缓存策略,如果你对这些还不太熟悉,那么当部署的缓存不幸与sw采用的策略相冲突了,就会发现你的应用里面会有两位神仙在打架,而你对此却是一脸懵逼。我们这边暂时对sw不做介绍,如果你需要了解,我推荐你看这篇sw入门的课程。
总结
现在你应该对HTTP缓存有了初步的了解,在本篇文章中我们首先提到了什么是缓存以及它的作用,我们通过各种工具我们可以看到一个资源的缓存状态;W3C规范对http缓存的计算方式有清楚明确的定义;中间代理缓存使得缓存计算的实际变得复杂,但他们的作用却无法替代;我们澄清了一点,不只是浏览器上会存在缓存,代理服务器也会保存缓存。合理的布置缓存策略会让你的网页在第二次加载的时候变快。最后,缓存与sw之前有着很复杂的关系,它们都是双刃剑,你应该对它们有所了解,才能让它们为你所用。
参考文档
- http-cache
- https://developer.mozilla.org/en-US/docs/Web/HTTP/Caching
- Caching Tutorial
- https://www.w3.org/Protocols/rfc2616/rfc2616-sec13.html
标签:HTTP,缓存,浏览器,age,代理服务器,服务器,终极,资源 来源: https://www.cnblogs.com/constantince/p/15475355.html