【AI 全栈 SOTA 综述 】这些你都不知道,怎么敢说会 AI?【语音识别原理 + 实战】
作者:互联网

章目录
前言
语音识别原理
信号处理,声学特征提取
识别字符,组成文本
声学模型
语言模型
词汇模型
语音声学特征提取:MFCC和LogFBank算法的原理
实战一 ASR语音识别模型
系统的流程
基于HTTP协议的API接口
客户端
未来
实战二 调百度和科大讯飞API
实战三 离线语音识别 Vosk
前言

语音识别原理

首先是语音任务,如语音识别和语音唤醒。听到这些,你会想到科大讯飞、百度等中国的平台。因为这两家公司占据了中国 80% 的语音市场,所以他们做得非常好。但是由于高精度的技术,他们不能开源,其他公司不得不花很多钱购买他们的 API,但是语音识别和其他应用很难学习(我培训了一个语音识别项目,10 个图形卡需要运行 20 天),这导致了民间语音识别的发展缓慢。陈军收集了大量 SOTA 在当前领域的原理和实战部分。今天让我们大饱眼福吧!
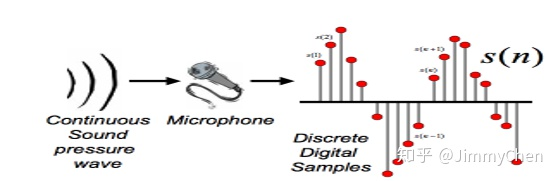
语音采样
在语音输入后的数字化过程中,首先要确定语音的起始和结束,然后进行降噪和滤波(除人声外还有许多噪声),以保证计算机能够识别滤波后的语音信息。为了进一步处理,还需要对音频信号帧进行处理。同时,从微观的角度来看,人们的语音信号一般在一段时间内是相对稳定的,这就是所谓的短期平稳性,因此需要对语音信号进行帧间处理,以便于处理。
通常一帧需要 20~50ms,帧间存在重叠冗余,避免了帧两端信号的弱化,影响识别精度。接下来是关键特征提取。由于对原始波形的识别不能达到很好的识别效果,需要通过频域变换提取特征参数。常用的变换方法是提取 MFCC 特征,并根据人耳的生理特性将每帧波形变换为原始波形向量矩阵。
逐帧的向量不是很直观。您也可以使用下图中的频谱图来表示语音。每列从左到右是一个 25 毫秒的块。与原始声波相比,从这类数据中寻找规律要容易得多。
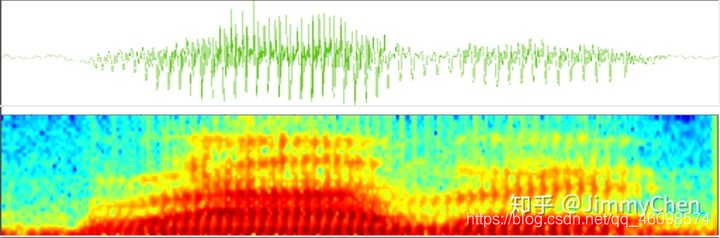
然而,频谱图主要用于语音研究,语音识别还需要逐帧使用特征向量。
识别字符,组成文本
特征提取完成后,进行特征识别和字符生成。这一部分的工作是从每一帧中找出当前的音位,然后从多个音位中构词,再从词中构词。当然,最困难的是从每一帧中找出当前的音素,因为每一帧都少于一个音素,而且只有多个帧才能形成一个音素。如果一开始是错的,以后很难纠正。如何判断每一帧属于哪个音素?最简单的方法是概率,哪个音素的概率最高。如果每帧中多个音素的概率是相同的呢?毕竟,这是可能的。每个人的口音、说话速度和语调都不一样,人们很难理解你说的是你好还是霍尔。然而,语音识别的文本结果只有一个,人们不可能参与到纠错的选择中。此时,多个音素构成了单词的统计决策,单词构成了文本
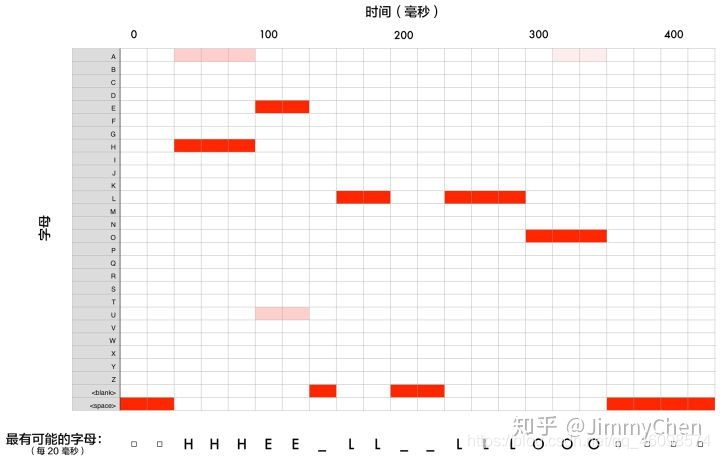
这允许我们得到三个可能的转录-“你好”,“呼啦”和“奥洛”。最后,根据单词的概率,我们会发现 hello 是最有可能的,所以我们输出 hello 的文本。上面的例子清楚地描述了概率如何决定从帧到音素,然后从音素到单词的一切。如何获得这些概率?我们能数一数人类几千年来所说的所有音素、单词和句子,以便识别一种语言,然后计算概率吗?这是不可能的。我们该怎么办?那我们需要模型:
声学模型
cv 君相信大家一定知道是么是声学模型~ 根据语音的基本状态和概率,尝试获取不同人群、年龄、性别、口音、说话速度的语音语料,同时尝试采集各种安静、嘈杂、遥远的语音语料来生成声学模型。为了达到更好的效果,不同的语言和方言会采用不同的声学模型来提高精度,减少计算量。
语言模型
然后对基本的语言模型,单词和句子的概率,进行大量的文本训练。如果模型中只有“今天星期一”和“明天星期二”两句话,我们只能识别这两句话。如果我们想识别更多的句子,我们只需要覆盖足够的语料库,但是模型会增加,计算量也会增加。所以我们实际应用中的模型通常局限于应用领域,如智能家居、导航、智能音箱、个人助理、医疗等,可以减少计算量,提高精度,
词汇模型
最后,它还是一个比较常用的词汇模型,是对语言模型的补充,是一个语言词典和不同发音的注释。例如,地名、人名、歌曲名、热门词汇、某些领域的特殊词汇等都会定期更新。目前,已有许多简化但有效的计算方法,如 HMM 隐马尔可夫模型。隐马尔可夫模型主要基于两个假设:一是内部状态转移只与前一状态相关,二是输出值只与当前状态(或当前状态转移)相关。简化了问题,也就是说,一个句子中一个词序列的概率只与前一个词相关,因此计算量大大简化。
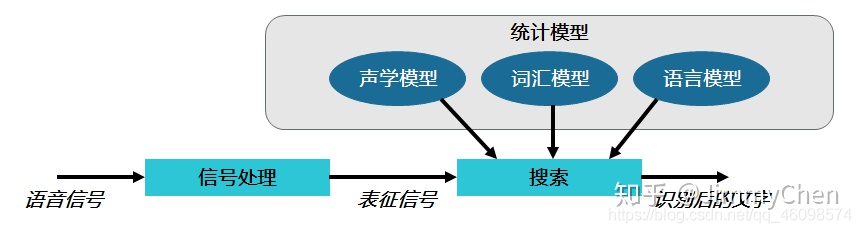
最后,将语音识别为文本。语音声学特征提取:MFCC 和 logfbank 算法原理
几乎所有的自动语音识别系统,第一步都是提取语音信号的特征。通过提取语音信号的相关特征,有助于识别出相关的语音信息,并将背景噪声、情感等无关信息剔除。
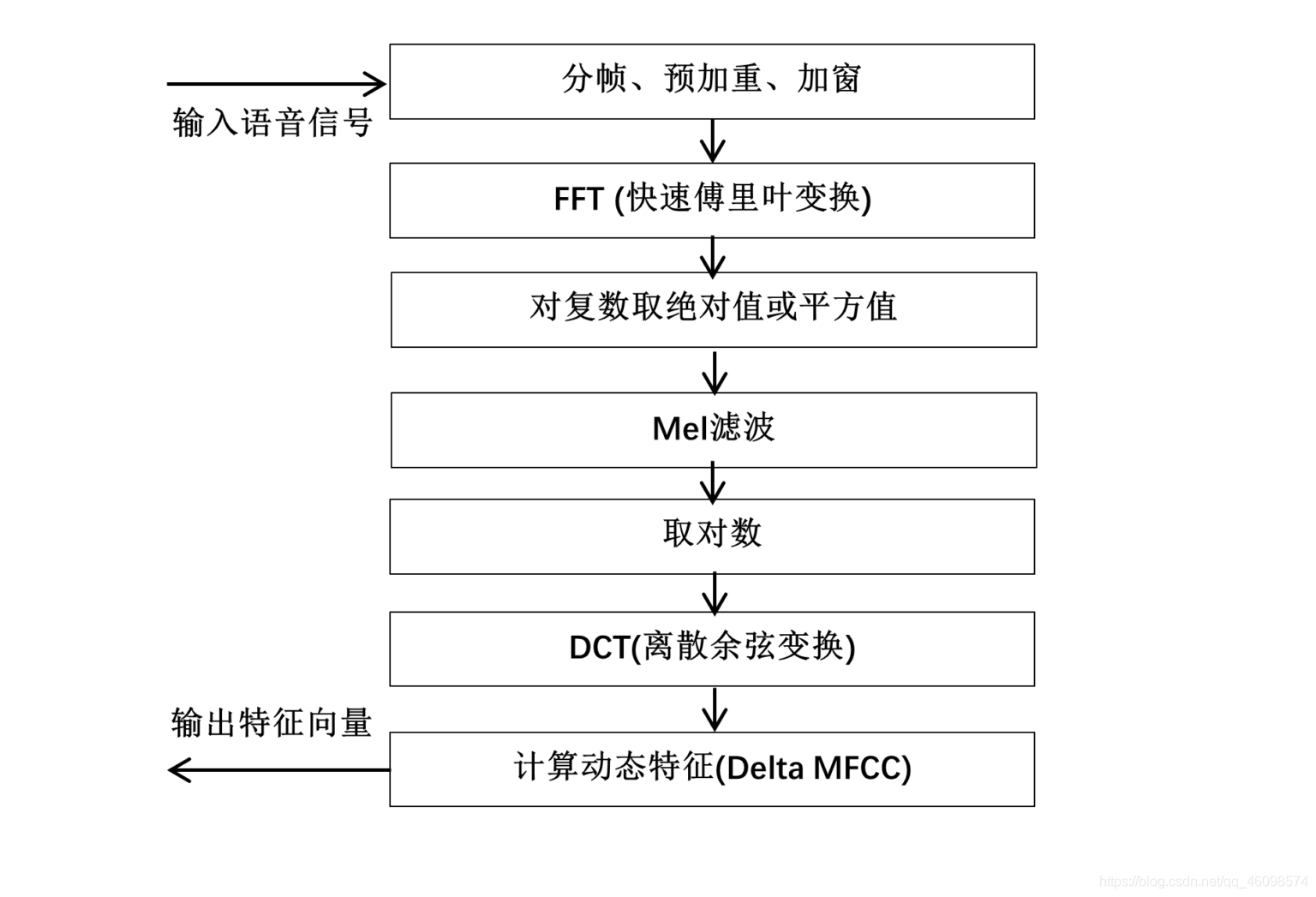
1 MFCC
刚刚 cv 君说到了 MFCC, 这个很经典哦~ MFCC 的全称是“梅尔频率倒谱系数”,这语音特征提取算法是这几十年来,常用的算法之一。这算法通过在声音频率中,对非线性梅尔的对数能量频谱,线性变换得到的。
1.1 分帧
由于存储在计算机硬盘中的原始 wav 音频文件是可变长度的,我们首先需要将其切割成几个固定长度的小块,即帧。根据语音信号变化快的特点,每帧的时长一般取 10-30ms,以保证一帧中有足够的周期,且变化不会太剧烈。因此,这种傅里叶变换更适合于平稳信号的分析。由于数字音频的采样率不同,每个帧向量的维数也不同。
1.2 预加重
由于人体声门发出的声音信号有 12dB/倍频程衰减,而嘴唇发出的声音信号有 6dB/倍频程衰减,因此经过快速傅立叶变换后的高频信号中成分很少。因此,语音信号预加重操作的主要目的是对每帧语音信号的高频部分进行增强,从而提高高频信号的分辨率。
1.3 加窗
在之前的成帧过程中,一个连续的语音信号被直接分割成若干段,由于截断效应会导致频谱泄漏。开窗操作的目的是消除每帧两端边缘的短时信号不连续问题。在 MFCC 算法中,窗函数通常是 Hamming 窗、矩形窗和 Hanning 窗。需要注意的是,在开窗之前必须进行预强调。
1.4 快速傅里叶变换
经过以上一系列的处理,我们仍然得到时域信号,而在时域中可以直接获得的语音信息量较少。在语音信号的进一步特征提取中,需要将每一帧的时域信号转换为其频域信号。对于存储在计算机中的语音信号,我们需要使用离散傅立叶变换。由于普通离散傅里叶变换计算复杂度高,通常采用快速傅里叶变换来实现。由于 MFCC 算法是分帧的,每一帧都是一个短时域信号,所以这一步又称为短时快速傅立叶变换。
1.5 计算幅度谱(对复数取模)
完成快速傅里叶变换后,语音特征是一个复矩阵,它是一个能谱。由于能谱中的相位谱包含的信息非常少,我们一般选择丢弃相位谱,保留幅度谱。
丢弃相位谱保留幅度谱一般有两种方法,分别是求每个复数的绝对值或平方值。
1.6 Mel 滤波
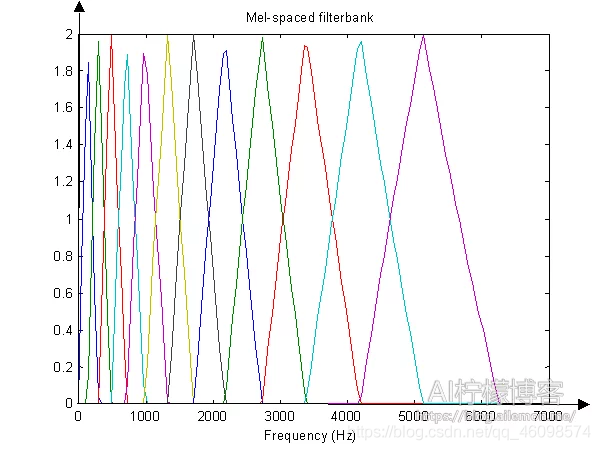
Mel 滤波的过程是 MFCC 的关键之一。Mel 滤波器是由 20 个三角形带通滤波器组成的,将线性频率转换为非线性分布的 Mel 频率。
2 logfBank
对数银行特征提取算法类似于 MFCC 算法,是基于对数银行的特征提取结果进行处理。但是 logfBank 和 MFCC 算法的主要区别在于是否进行离散余弦变换。
随着 DNN 和 CNN 的出现,特别是深度学习的发展,神经网络可以更好地利用 fBank 和 logfBank 特征之间的相关性来提高最终语音识别的准确性,减少 WER,因此可以省略离散余弦变换的步骤。
SOTA 原理+实战 1 深度全卷积神经网络 语音识别
近年来,深度学习在人工智能领域出现,对语音识别也产生了深远的影响。深度神经网络已经逐渐取代了最初的 HMM 隐马尔可夫模型。在人类的交流和知识传播中,大约 70%的信息来自语音。在未来,语音识别将不可避免地成为智能生活的重要组成部分,它可以为语音辅助和语音输入提供必要的基础,这将成为一种新的人机交互方式。因此,我们需要让机器理解人的声音。
语音识别系统的声学模型采用深度全卷积神经网络,直接以声谱图为输入。在模型的结构上,借鉴了图像识别中的最佳网络配置 VGG。这种网络模型具有很强的表达能力,可以看到很长的历史和未来的信息,比 RNN 更健壮。在输出端,模型可以通过 CTC 方案来完成
语音识别系统的声学模型采用深度全卷积神经网络,直接以声谱图为输入。在模型的结构上,借鉴了图像识别中的最佳网络配置 VGG。这种网络模型具有很强的表达能力,可以看到很长的历史和未来的信息,比 RNN 更健壮。在输出端,该模型可以与 CTC 方案完美结合,实现整个模型的端到端训练,直接将声音波形信号转录成汉语普通话拼音序列。在语言模型上,通过最大熵隐马尔可夫模型将拼音序列转换成中文文本。并且,为了通过网络向所有用户提供服务。特征提取通过成帧和加窗操作将普通的 wav 语音信号转换成神经网络所需的二维频谱图像信号
CTC 解码 在语音进行识别信息系统的声学分析模型的输出中,往往包含了企业大量使用连续不断重复的符号,因此,我们需要将连续相同的符合合并为同一个符号,然后再通过去除静音分隔标记符,得到发展最终解决实际的语音学习拼音符号序列。
该语言模型使用统计语言模型,将拼音转换为最终识别的文本并输出它。将拼音到文本的本质建模为隐马尔可夫链,具有较高的准确率。下面深度解析代码,包会系列~
导入 Keras 系列。
import platform as plat import os import time from general_function.file_wav import * from general_function.file_dict import * from general_function.gen_func import * from general_function.muti_gpu import * import keras as kr import numpy as np import random from keras.models import Sequential, Model from keras.layers import Dense, Dropout, Input, Reshape, BatchNormalization # , Flatten from keras.layers import Lambda, TimeDistributed, Activation,Conv2D, MaxPooling2D,GRU #, Merge from keras.layers.merge import add, concatenate from keras import backend as K from keras.optimizers import SGD, Adadelta, Adam from readdata24 import DataSpeech
导入声学模型默认输出的拼音的表示大小是 1428,即 1427 个拼音+1 个空白块。
abspath = ''
ModelName='261'
NUM_GPU = 2
class ModelSpeech(): # 语音模型类
def __init__(self, datapath):
'''
初始化
默认输出的拼音的表示大小是1428,即1427个拼音+1个空白块
'''
MS_OUTPUT_SIZE = 1428
self.MS_OUTPUT_SIZE = MS_OUTPUT_SIZE # 神经网络最终输出的每一个字符向量维度的大小
#self.BATCH_SIZE = BATCH_SIZE # 一次训练的batch
self.label_max_string_length = 64
self.AUDIO_LENGTH = 1600
self.AUDIO_FEATURE_LENGTH = 200
self._model, self.base_model = self.CreateModel()
转换路径
self.datapath = datapath
self.slash = ''
system_type = plat.system() # 由于不同的系统的文件路径表示不一样,需要进行判断
if(system_type == 'Windows'):
self.slash='\\' # 反斜杠
elif(system_type == 'Linux'):
self.slash='/' # 正斜杠
else:
print('*[Message] Unknown System\n')
self.slash='/' # 正斜杠
if(self.slash != self.datapath[-1]): # 在目录路径末尾增加斜杠
self.datapath = self.datapath + self.slash
定义 CNN/LSTM/CTC 模型,使用函数式模型,设计输入层,隐藏层和输出层。
def CreateModel(self):
'''
定义CNN/LSTM/CTC模型,使用函数式模型
输入层:200维的特征值序列,一条语音数据的最大长度设为1600(大约16s)
隐藏层:卷积池化层,卷积核大小为3x3,池化窗口大小为2
隐藏层:全连接层
输出层:全连接层,神经元数量为self.MS_OUTPUT_SIZE,使用softmax作为激活函数,
CTC层:使用CTC的loss作为损失函数,实现连接性时序多输出
'''
input_data = Input(name='the_input', shape=(self.AUDIO_LENGTH, self.AUDIO_FEATURE_LENGTH, 1))
layer_h1 = Conv2D(32, (3,3), use_bias=False, activation='relu', padding='same', kernel_initializer='he_normal')(input_data) # 卷积层
#layer_h1 = Dropout(0.05)(layer_h1)
layer_h2 = Conv2D(32, (3,3), use_bias=True, activation='relu', padding='same', kernel_initializer='he_normal')(layer_h1) # 卷积层
layer_h3 = MaxPooling2D(pool_size=2, strides=None, padding="valid")(layer_h2) # 池化层
#layer_h3 = Dropout(0.05)(layer_h3) # 随机中断部分神经网络连接,防止过拟合
layer_h4 = Conv2D(64, (3,3), use_bias=True, activation='relu', padding='same', kernel_initializer='he_normal')(layer_h3) # 卷积层
#layer_h4 = Dropout(0.1)(layer_h4)
layer_h5 = Conv2D(64, (3,3), use_bias=True, activation='relu', padding='same', kernel_initializer='he_normal')(layer_h4) # 卷积层
layer_h6 = MaxPooling2D(pool_size=2, strides=None, padding="valid")(layer_h5) # 池化层
#layer_h6 = Dropout(0.1)(layer_h6)
layer_h7 = Conv2D(128, (3,3), use_bias=True, activation='relu', padding='same', kernel_initializer='he_normal')(layer_h6) # 卷积层
#layer_h7 = Dropout(0.15)(layer_h7)
layer_h8 = Conv2D(128, (3,3), use_bias=True, activation='relu', padding='same', kernel_initializer='he_normal')(layer_h7) # 卷积层
layer_h9 = MaxPooling2D(pool_size=2, strides=None, padding="valid")(layer_h8) # 池化层
#layer_h9 = Dropout(0.15)(layer_h9)
layer_h10 = Conv2D(128, (3,3), use_bias=True, activation='relu', padding='same', kernel_initializer='he_normal')(layer_h9) # 卷积层
#layer_h10 = Dropout(0.2)(layer_h10)
layer_h11 = Conv2D(128, (3,3), use_bias=True, activation='relu', padding='same', kernel_initializer='he_normal')(layer_h10) # 卷积层
layer_h12 = MaxPooling2D(pool_size=1, strides=None, padding="valid")(layer_h11) # 池化层
#layer_h12 = Dropout(0.2)(layer_h12)
layer_h13 = Conv2D(128, (3,3), use_bias=True, activation='relu', padding='same', kernel_initializer='he_normal')(layer_h12) # 卷积层
#layer_h13 = Dropout(0.3)(layer_h13)
layer_h14 = Conv2D(128, (3,3), use_bias=True, activation='relu', padding='same', kernel_initializer='he_normal')(layer_h13) # 卷积层
layer_h15 = MaxPooling2D(pool_size=1, strides=None, padding="valid")(layer_h14) # 池化层
#test=Model(inputs = input_data, outputs = layer_h12)
#test.summary()
layer_h16 = Reshape((200, 3200))(layer_h15) #Reshape层
#layer_h16 = Dropout(0.3)(layer_h16) # 随机中断部分神经网络连接,防止过拟合
layer_h17 = Dense(128, activation="relu", use_bias=True, kernel_initializer='he_normal')(layer_h16) # 全连接层
inner = layer_h17
#layer_h5 = LSTM(256, activation='relu', use_bias=True, return_sequences=True)(layer_h4) # LSTM层
rnn_size=128
gru_1 = GRU(rnn_size, return_sequences=True, kernel_initializer='he_normal', name='gru1')(inner)
gru_1b = GRU(rnn_size, return_sequences=True, go_backwards=True, kernel_initializer='he_normal', name='gru1_b')(inner)
gru1_merged = add([gru_1, gru_1b])
gru_2 = GRU(rnn_size, return_sequences=True, kernel_initializer='he_normal', name='gru2')(gru1_merged)
gru_2b = GRU(rnn_size, return_sequences=True, go_backwards=True, kernel_initializer='he_normal', name='gru2_b')(gru1_merged)
gru2 = concatenate([gru_2, gru_2b])
layer_h20 = gru2
#layer_h20 = Dropout(0.4)(gru2)
layer_h21 = Dense(128, activation="relu", use_bias=True, kernel_initializer='he_normal')(layer_h20) # 全连接层
#layer_h17 = Dropout(0.3)(layer_h17)
layer_h22 = Dense(self.MS_OUTPUT_SIZE, use_bias=True, kernel_initializer='he_normal')(layer_h21) # 全连接层
y_pred = Activation('softmax', name='Activation0')(layer_h22)
model_data = Model(inputs = input_data, outputs = y_pred)
#model_data.summary()
labels = Input(name='the_labels', shape=[self.label_max_string_length], dtype='float32')
input_length = Input(name='input_length', shape=[1], dtype='in
label_length = Input(name='label_length', shape=[1], dtype='int64')
# Keras doesn't currently support loss funcs with extra parameters
# so CTC loss is implemented in a lambda layer
#layer_out = Lambda(ctc_lambda_func,output_shape=(self.MS_OUTPUT_SIZE, ), name='ctc')([y_pred, labels, input_length, label_length])#(layer_h6) # CTC
loss_out = Lambda(self.ctc_lambda_func, output_shape=(1,), name='ctc')([y_pred, labels, input_length, label_length])
模型加载方式
model = Model(inputs=[input_data, labels, input_length, label_length], outputs=loss_out)
model.summary()
# clipnorm seems to speeds up convergence
#sgd = SGD(lr=0.0001, decay=1e-6, momentum=0.9, nesterov=True, clipnorm=5)
#ada_d = Adadelta(lr = 0.01, rho = 0.95, epsilon = 1e-06)
opt = Adam(lr = 0.001, beta_1 = 0.9, beta_2 = 0.999, decay = 0.0, epsilon = 10e-8)
#model.compile(loss={'ctc': lambda y_true, y_pred: y_pred}, optimizer=sgd)
model.build((self.AUDIO_LENGTH, self.AUDIO_FEATURE_LENGTH, 1))
model = ParallelModel(model, NUM_GPU)
model.compile(loss={'ctc': lambda y_true, y_pred: y_pred}, optimizer = opt)
定义 ctc 解码
# captures output of softmax so we can decode the output during visualization
test_func = K.function([input_data], [y_pred])
#print('[*提示] 创建模型成功,模型编译成功')
print('[*Info] Create Model Successful, Compiles Model Successful. ')
return model, model_data
def ctc_lambda_func(self, args):
y_pred, labels, input_length, label_length = args
y_pred = y_pred[:, :, :]
#y_pred = y_pred[:, 2:, :]
return K.ctc_batch_cost(labels, y_pred, input_length, label_length)
定义训练模型和训练参数
def TrainModel(self, datapath, epoch = 2, save_step = 1000, batch_size = 32, filename = abspath + 'model_speech/m' + ModelName + '/speech_model'+ModelName):
'''
训练模型
参数:
datapath: 数据保存的路径
epoch: 迭代轮数
save_step: 每多少步保存一次模型
filename: 默认保存文件名,不含文件后缀名
'''
data=DataSpeech(datapath, 'train')
num_data = data.GetDataNum() # 获取数据的数量
yielddatas = data.data_genetator(batch_size, self.AUDIO_LENGTH)
for epoch in range(epoch): # 迭代轮数
print('[running] train epoch %d .' % epoch)
n_step = 0 # 迭代数据数
while True:
try:
print('[message] epoch %d . Have train datas %d+'%(epoch, n_step*save_step))
# data_genetator是一个生成器函数
#self._model.fit_generator(yielddatas, save_step, nb_worker=2)
self._model.fit_generator(yielddatas, save_step)
n_step += 1
except StopIteration:
print('[error] generator error. please check data format.')
break
self.SaveModel(comment='_e_'+str(epoch)+'_step_'+str(n_step * save_step))
self.TestModel(self.datapath, str_dataset='train', data_count = 4)
self.TestModel(self.datapath, str_dataset='dev', data_count = 4)
def LoadModel(self,filename = abspath + 'model_speech/m'+ModelName+'/speech_model'+ModelName+'.model'):
'''
加载模型参数
'''
self._model.load_weights(filename)
self.base_model.load_weights(filename + '.base')
def SaveModel(self,filename = abspath + 'model_speech/m'+ModelName+'/speech_model'+ModelName,comment=''):
'''
保存模型参数
'''
self._model.save_weights(filename+comment+'.model')
self.base_model.save_weights(filename + comment + '.model.base')
f = open('step'+ModelName+'.txt','w')
f.write(filename+comment)
f.close()
def TestModel(self, datapath='', str_dataset='dev', data_count = 32, out_report = False, show_ratio = True):
'''
测试检验模型效果
'''
data=DataSpeech(self.datapath, str_dataset)
#data.LoadDataList(str_dataset)
num_data = data.GetDataNum() # 获取数据的数量
if(data_count <= 0 or data_count > num_data): # 当data_count为小于等于0或者大于测试数据量的值时,则使用全部数据来测试
data_count = num_data
try:
ran_num = random.randint(0,num_data - 1) # 获取一个随机数
words_num = 0
word_error_num = 0
nowtime = time.strftime('%Y%m%d_%H%M%S',time.localtime(time.time()))
if(out_report == True):
txt_obj = open('Test_Report_' + str_dataset + '_' + nowtime + '.txt', 'w', encoding='UTF-8') # 打开文件并读入
txt = ''
for i in range(data_count):
data_input, data_labels = data.GetData((ran_num + i) % num_data) # 从随机数开始连续向后取一定数量数据
# 数据格式出错处理 开始
# 当输入的wav文件长度过长时自动跳过该文件,转而使用下一个wav文件来运行
num_bias = 0
while(data_input.shape[0] > self.AUDIO_LENGTH):
print('*[Error]','wave data lenghth of num',(ran_num + i) % num_data, 'is too long.','\n A Exception raise when test Speech Model.')
num_bias += 1
data_input, data_labels = data.GetData((ran_num + i + num_bias) % num_data) # 从随机数开始连续向后取一定数量数据
# 数据格式出错处理 结束
pre = self.Predict(data_input, data_input.shape[0] // 8)
words_n = data_labels.shape[0] # 获取每个句子的字数
words_num += words_n # 把句子的总字数加上
edit_distance = GetEditDistance(data_labels, pre) # 获取编辑距离
if(edit_distance <= words_n): # 当编辑距离小于等于句子字数时
word_error_num += edit_distance # 使用编辑距离作为错误字数
else: # 否则肯定是增加了一堆乱七八糟的奇奇怪怪的字
word_error_num += words_n # 就直接加句子本来的总字数就好了
if(i % 10 == 0 and show_ratio == True):
print('Test Count: ',i,'/',data_count)
txt = ''
if(out_report == True):
txt += str(i) + '\n'
txt += 'True:\t' + str(data_labels) + '\n'
txt += 'Pred:\t' + str(pre) + '\n'
txt += '\n'
txt_obj.write(txt)
定义预测函数和返回预测结果。
#print('*[测试结果] 语音识别 ' + str_dataset + ' 集语音单字错误率:', word_error_num / words_num * 100, '%')
print('*[Test Result] Speech Recognition ' + str_dataset + ' set word error ratio: ', word_error_num / words_num * 100, '%')
if(out_report == True):
txt = '*[测试结果] 语音识别 ' + str_dataset + ' 集语音单字错误率: ' + str(word_error_num / words_num * 100) + ' %'
txt_obj.write(txt)
txt_obj.close()
except StopIteration:
print('[Error] Model Test Error. please check data format.')
def Predict(self, data_input, input_len):
'''
预测结果
返回语音识别后的拼音符号列表
'''
batch_size = 1
in_len = np.zeros((batch_size),dtype = np.int32)
in_len[0] = input_len
x_in = np.zeros((batch_size, 1600, self.AUDIO_FEATURE_LENGTH, 1), dtype=np.float)
for i in range(batch_size):
x_in[i,0:len(data_input)] = data_input
base_pred = self.base_model.predict(x = x_in)
#print('base_pred:\n', base_pred)
#y_p = base_pred
#for j in range(200):
# mean = np.sum(y_p[0][j]) / y_p[0][j].shape[0]
# print('max y_p:',np.max(y_p[0][j]),'min y_p:',np.min(y_p[0][j]),'mean y_p:',mean,'mid y_p:',y_p[0][j][100])
# print('argmin:',np.argmin(y_p[0][j]),'argmax:',np.argmax(y_p[0][j]))
# count=0
# for i in range(y_p[0][j].shape[0]):
# if(y_p[0][j][i] < mean):
# count += 1
# print('count:',count)
base_pred =base_pred[:, :, :]
#base_pred =base_pred[:, 2:, :]
r = K.ctc_decode(base_pred, in_len, greedy = True, beam_width=100, top_paths=1)
#print('r', r)
r1 = K.get_value(r[0][0])
#print('r1', r1)
#r2 = K.get_value(r[1])
#print(r2)
r1=r1[0]
return r1
pass
def RecognizeSpeech(self, wavsignal, fs):
'''
最终做语音识别用的函数,识别一个wav序列的语音
'''
#data = self.data
#data = DataSpeech('E:\\语音数据集')
#data.LoadDataList('dev')
# 获取输入特征
#data_input = GetMfccFeature(wavsignal, fs)
#t0=time.time()
data_input = GetFrequencyFeature3(wavsignal, fs)
#t1=time.time()
#print('time cost:',t1-t0)
input_length = len(data_input)
input_length = input_length // 8
data_input = np.array(data_input, dtype = np.float)
#print(data_input,data_input.shape)
data_input = data_input.reshape(data_input.shape[0],data_input.shape[1],1)
#t2=time.time()
r1 = self.Predict(data_input, input_length)
#t3=time.time()
#print('time cost:',t3-t2)
list_symbol_dic = GetSymbolList(self.datapath) # 获取拼音列表
最终做语音识别用的函数,识别一个 wav 序列的语音
r_str=[]
for i in r1:
r_str.append(list_symbol_dic[i])
return r_str
pass
def RecognizeSpeech_FromFile(self, filename):
'''
最终做语音识别用的函数,识别指定文件名的语音
'''
wavsignal,fs = read_wav_data(filename)
r = self.RecognizeSpeech(wavsignal, fs)
return r
pass
@property def model(self): ''' 返回keras model ''' return self._model if(__name__=='__main__'):
main 函数,启动
datapath = abspath + ''
modelpath = abspath + 'model_speech'
if(not os.path.exists(modelpath)): # 判断保存模型的目录是否存在
os.makedirs(modelpath) # 如果不存在,就新建一个,避免之后保存模型的时候炸掉
system_type = plat.system() # 由于不同的系统的文件路径表示不一样,需要进行判断
if(system_type == 'Windows'):
datapath = 'E:\\语音数据集'
modelpath = modelpath + '\\'
elif(system_type == 'Linux'):
datapath = abspath + 'dataset'
modelpath = modelpath + '/'
else:
print('*[Message] Unknown System\n')
datapath = 'dataset'
modelpath = modelpath + '/'
ms = ModelSpeech(datapath)
原理+实战二 百度和科大讯飞语音识别
端到端的深度合作学习研究方法我们可以用来进行识别英语或汉语普通话,这是两种截然不同的语言。因为使用神经网络手工设计整个过程的每个组成部分,端到端的学习使我们能够处理各种各样的声音,包括嘈杂的环境,压力和不同的语言。我们的方法关键是提高我们可以应用的 HPC 技术,以前发展需要数周才能进行完成的实验,现在在几天内就可以通过实现。这使得学生我们自己能够更快地进行迭代,以鉴别出优越的架构和算法。最后,在数据信息中心进行使用称为 Batch Dispatch with GPU 的技术,我们研究表明,我们的系统分析可以同时通过网络在线配置,以低成本部署,低延迟地为大量用户管理提供一个服务。
端到端语音识别是一个活跃的研究领域,将其用于重新评估 DNN-HMM 的输出,取得了令人信服的结果。Rnn 编解码器使用编码器 rnn 将输入映射到固定长度矢量,而解码器网络将固定长度矢量映射到输出预测序列。有着自己注意力的 RNN 编码器 – 解码器在预测音素教学方面进行表现一个良好。结合 ctc 损失函数和 rnn 对时间信息进行了模拟,并在字符输出的端到端语音识别中取得了良好的效果。Ctc-rnn 模型也能很好地预测音素,尽管在这种情况下仍然需要一本词典。
数据技术也是端到端语音进行识别系统成功的关键,Hannun 等人使用了中国超过 7000 小时的标记语言语音。数据增强对于提高计算机视觉和语音识别等深度学习的性能非常有效。现有的语音系统也可以用来引导新的数据收集。我们从以往的方法中得到启示,引导更大的数据集和数据增加,以增加百度系统中的有效标记数据量。
现在的演示是识别音频文件的内容。token 获取见官网,这边调包没什么含金量 Python 技术篇-百度进行语音 API 鉴权认证信息获取 Access Token 注:下面的 token 是我自己可以申请的,:下面的 token 是我自己申请的,建议按照我的文章自己来申请专属的。
import requests
import os
import base64
import json
apiUrl='http://vop.baidu.com/server_api'
filename = "16k.pcm" # 这是我下载到本地的音频样例文件名
size = os.path.getsize(filename) # 获取本地语音文件尺寸
file1 = open(filename, "rb").read() # 读取本地语音文件
text = base64.b64encode(file1).decode("utf-8") # 对读取的文件进行base64编码
data = {
"format":"pcm", # 音频格式
"rate":16000, # 采样率,固定值16000
"dev_pid":1536, # 普通话
"channel":1, # 频道,固定值1
"token":"24.0c828682d414bf79b08f89c4c7dcd83a.2592000.1562739150.282335-16470175", # 重要,鉴权认证Access Token,需要自己来申请
"cuid":"DC-85-DE-F9-08-59", # 随便一个值就好了,官网推荐是个人电脑的MAC地址
"len":size, # 语音文件的尺寸
"speech":text, # base64编码的语音文件
}
try:
r = requests.post(apiUrl, data = json.dumps(data)).json()
print(r)
print(r.get("result")[0])
except Exception as e:
print(e)
科大讯飞同样的方式,参见官网教程。
实战三 离线语音识别 Vosk
cv 君今天由于篇幅问题,介绍了大量原理和 Sota 算法,所以现在再最后分享一个,需要了解更多,欢迎持续关注本系列。
Vosk 支持 30 多种语言,并且现在做的不错,在离线语音里面不错了,https://github.com/alphacep/vosk-api
带 Android python,c++ 的 pc 版本,等等 web 部署方案 Android 的话,就需要你安装 Android 包,然后还要下载编译工具,gradle,通过 Gradle 等方式编译。
即可编译,编译成功后会生成 apk 安装包,手机就能安装,离线使用了。
/**
* Adds listener.
*/
public void addListener(RecognitionListener listener) {
synchronized (listeners) {
listeners.add(listener);
}
}
/**
* Removes listener.
*/
public void removeListener(RecognitionListener listener) {
synchronized (listeners) {
listeners.remove(listener);
}
}
/**
* Starts recognition. Does nothing if recognition is active.
*
* @return true if recognition was actually started
*/
public boolean startListening() {
if (null != recognizerThread)
return false;
recognizerThread = new RecognizerThread();
recognizerThread.start();
return true;
}
这边实战的比较简单,后续我做了很多优化,支持 Android,python ,c++,java 语言等部署,欢迎咨询 cv 君。

智能语音交互图
总结
今天说了很多,欢迎各位看官赏脸观看,这篇文章较多地在介绍 Tricks,互动性和趣味性在后面实战部分~而且又是语音的算法,今天没法给大家演示很多有趣的。
后文,可以给大家由浅入深地进阶语音部分的其他领域部分:
一:诸如 Siri ,小爱同学这样的唤醒词算法和模型和 SOTA;
二: 说话人区别(鉴别思想)的 SOTA
三:多语种思路+少语种+困难语种思路和 SOTA
四:各个语音比赛 SOTA 方案
标签:layer,SOTA,AI,self,全栈,语音,input,model,data 来源: https://www.cnblogs.com/Agora/p/15463282.html