A gentle introduction to Deep Reinforcement Learning
作者:互联网
https://towardsdatascience.com/drl-01-a-gentle-introduction-to-deep-reinforcement-learning-405b79866bf4
Deep Reinforcement Learning (DRL), a very fast-moving field, is the combination of Reinforcement Learning and Deep Learning. It is also the most trending type of Machine Learning because it can solve a wide range of complex decision-making tasks that were previously out of reach for a machine to solve real-world problems with human-like intelligence.
Today I’m starting a series about Deep Reinforcement Learning that will bring the topic closer to the reader. The purpose is to review the field from specialized terms and jargons to fundamental concepts and classical algorithms in the area, that newbies would not get lost while starting in this amazing area.
My first serious contact with Deep Reinforcement Learning was in Cadiz (Spain), during the Machine Learning Summer School in 2016. I attended the three days seminar of John Schulman (at that time from UC Berkeley and cofounder of OpenAI) about Deep Reinforcement Learning.


It was awesome, but I also have to confess that it was tremendously difficult for me to follow John’s explanations. It’s been a long time since then, and thanks to working with Xavier Giró and Ph.D. students like Victor Campos and MPh.D.am Bellver, I’ve been able to move forward and enjoy the subject.
But even though several years have passed since then, I sincerely believe that the taxonomy of different approaches to Reinforcement Learning that he presented is still a good scheme to organize knowledge for beginners.
Dynamic Programming is actually what most reinforcement learning courses in textbooks start. I will do that, but before, as John did in his seminar, I will introduce the Cross-Entropy method, a sort of evolutionary algorithm, although most books do not deal with it. It will go very well with this first method to introduce deep learning in reinforcement learning, Deep Reinforcement Learning, because it is a straightforward method to implement, and it works surprisingly well.
With this method, we will be able to do a convenient review of how Deep Learning and Reinforcement Learning collaborate before entering the more classical approaches of treating an RL problem without considering DL such as Dynamic Programming, Monte Carlo, Temporal Difference Learning following the order of the vast majority of academic books on the subject. We will then dedicate the last part of this series to the most fundamental algorithms (not the state of the art because it is pervasive) of DL + RL as Policy Gradient Methods.
Specifically, in this first publication, we will briefly present what Deep Reinforcement Learning is and the basic terms used in this research and innovation area.
I think that Deep Reinforcement Learning is one of the most exciting fields in Artificial Intelligence. It’s marrying the power and the ability of deep neural networks to represent and comprehend the world with the ability to act on that understanding. Let’s see if I’m able to share that excitement. Here we go!
1. Background
Exciting news in Artificial Intelligence (AI) has just happened in recent years. For instance, AlphaGo defeated the best professional human player in the game of Go. Or last year, for example, our friend Oriol Vinyals and his team in DeepMind showed the AlphaStar Agent beat professional players at the game of StarCraft II. Or a few months later, OpenAI’s Dota-2-playing bot became the first AI system to beat the world champions in an e-sports game. All these systems have in common that they use Deep Reinforcement Learning (DRL). But what are AI and DRL?
1.1 Artificial Intelligence
We have to take a step back to look at the types of learning. Sometimes the terminology itself can confuse us with the fundamentals. Artificial Intelligence, the main field of computer science in which Reinforcement Learning (RL) falls into, is a discipline concerned with creating computer programs that display humanlike “intelligence”.
What do we mean when we talk about Artificial Intelligence? Artificial intelligence (AI) is a vast area. Even an authoritative AI textbook Artificial Intelligence, a modern approach written by Stuart Rusell and Peter Norvig, does not give a precise definition and discuss definitions of AI from different perspectives:
Artificial Intelligence: A Modern Approach (AIMA) ·3rd edition, Stuart J Russell and Peter Norvig, Prentice Hall, 2009. ISBN 0–13–604259–7
Without a doubt, this book is the best starting point to have a global vision of the subject. But trying to make a more general approach (purpose of this series), we could accept a simple definition in which by Artificial Intelligence we refer to that intelligence shown by machines, in contrast to the natural intelligence of humans. In this sense, a possible concise and general definition of Artificial Intelligence could be the effort to automate intellectual tasks usually performed by humans.
As such, the area of artificial intelligence is a vast scientific field that covers many areas of knowledge related to machine learning; even many more approaches are not always cataloged as Machine Learning is included by my university colleagues who are experts in the subject. Besides, over time, as computers have been increasingly able to “do things”, tasks or technologies considered “smart” have been changing.
Furthermore, since the 1950s, Artificial Intelligence has experienced several waves of optimism, followed by disappointment and loss of funding and interest (periods known as AI winter), followed by new approaches, success, and financing. Moreover, during most of its history, Artificial Intelligence research has been dynamically divided into subfields based on technical considerations or concrete mathematical tools and with research communities that sometimes did not communicate sufficiently with each other.
1.2 Machine Learning
Machine Learning (ML) is in itself a large field of research and development. In particular, Machine Learning could be defined as the subfield of Artificial Intelligence that gives computers the ability to learn without being explicitly programmed, that is, without requiring the programmer to indicate the rules that must be followed to achieve their task; the computers do them automatically.
Generalizing, we can say that Machine Learning consists of developing a prediction “algorithm” for a particular use case for each problem. These algorithms learn from the data to find patterns or trends to understand what the data tell us, and in this way, build a model to predict and classify the elements.
Given the maturity of the research area in Machine Learning, there are many well-established approaches to Machine Learning. Each of them uses a different algorithmic structure to optimize the predictions based on the received data. Machine Learning is a broad field with a complex taxonomy of algorithms that are grouped, in general, into three main categories:
- Supervised Learning is the task of learning from tagged data, and its goal is to generalize. We mean that learning is supervised when the data we use for training includes the desired solution, called “label”. Some of the most popular machine learning algorithms in this category are linear regression, logistic regression, support vector machines, decision trees, random forest, or neural networks.
- Unsupervised Learning is the task of learning from unlabeled data, and its goal is to compress. When the training data do not include the labels, we refer to Unsupervised Learning, and it will be the algorithm that will try to classify the information by itself. Some of the best-known algorithms in this category are clustering (K-means) or principal component analysis (PCA).
- Reinforcement Learning is the task of learning through trial and error and its goal is to act. This learning category allows it to be combined with other categories, and it is now a very active research area, as we will see in this series.
1.3 Deep Learning
Orthogonal to this categorization, we can consider a powerful approach to ML, called Deep Learning (DL), a topic of which we have discussed extensively in previous posts. Remember that Deep Learning algorithms are based on artificial neural networks, whose algorithmic structures allow models composed of multiple processing layers to learn data representations with various abstraction levels.
DL is not a separate ML branch, so it’s not a different task than those described above. DL is a collection of techniques and methods for using neural networks to solve ML tasks, either Supervised Learning, Unsupervised Learning, or Reinforcement Learning. We can represent it graphically in Figure 1.
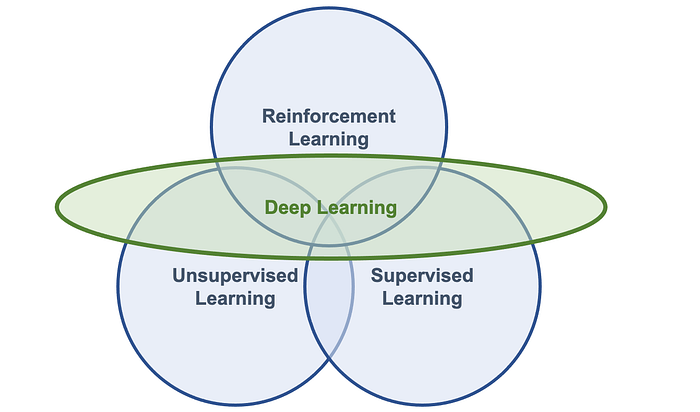
1.4 Deep Reinforcement Learning
Deep Learning is one of the best tools that we have today to handle unstructured environments; they can learn from large amounts of data or discover patterns. But this is not decision-making; it is a recognition problem. Reinforcement Learning provides this feature.
Reinforcement Learning can solve the problems using a variety of ML methods and techniques, from decision trees to SVMs, to neural networks. However, in this series, we only use neural networks; this is what the “deep” part of DRL refers to, after all. However, neural networks are not necessarily the best solution to every problem. For instance, neural networks are very data-hungry and challenging to interpret. Still, without doubt, neural networks are at this moment one of the most powerful techniques available, and their performance is often the best.
2. Reinforcement Learning
In this section, we provide a brief first approach to RL, due it is essential for a good understanding of deep reinforcement learning, a particular type of RL, with deep neural networks for state representation and/or function approximation for value function, policy, and so on.
2.1 Learning by interacting
Learning by interacting with our Environment is probably the first approach that comes to our mind when we think about the nature of learning. It is the way we intuit that an infant learns. And we know that such interactions are undoubtedly an essential source of knowledge about our environment and ourselves throughout people’s lives, not just infants. For example, when we are learning to drive a car, we are entirely aware of how the environment responds to what we do, and we also seek to influence what happens in our environment through our actions. Learning from the interaction is a fundamental concept that underlies almost all learning theories and is the foundation of Reinforcement Learning.
The approach of Reinforcement Learning is much more focused on goal-directed learning from interaction than are other approaches to Machine Learning. The learning entity is not told what actions to take, but instead must discover for itself which actions produce the greatest reward, its goal, by testing them by “trial and error.” Furthermore, these actions can affect not only the immediate reward but also the future ones, “delayed rewards”, since the current actions will determine future situations (how it happens in real life). These two characteristics, “trial and error” search and “delayed reward”, are two distinguishing characteristics of reinforcement learning that we will cover throughout this series of posts.
2.2 Key elements of Reinforcement Learning
Reinforcement Learning (RL) is a field that is influenced by a variety of other well-established fields that tackle decision-making problems under uncertainty. For instance, Control Theory studies ways to control complex known dynamical systems; however, the dynamics of the systems we try to control are usually known in advance, unlike the case of DRL, which is not known in advance. Another field can be Operations Research that also studies decision-making under uncertainty but often contemplates much larger action spaces than those commonly seen in RL.
As a result, there is a synergy between these fields, which is undoubtedly positive for science advancement. But it also brings some inconsistencies in terminologies, notations, and so on. That is why in this section, we will provide a detailed introduction to terminologies and notations that we will use throughout the series.
Reinforcement Learning is essentially a mathematical formalization of a decision-making problem that we will introduce later in this series.
Agent and Environment
In Reinforcement Learning there are two core components:
- An Agent, that represents the “solution” , which is a computer program with a single role of making decisions (actions) to solve complex decision-making problems under uncertainty.
- An Environment, that is the representation of a “problem”, which is everything that comes after the decision of the Agent. The environment responds with the consequences of those actions, which are observations or states, and rewards, also sometimes called costs.
For example, in the tic-tac-toe game, we can consider that the Agent is one of the players, and the Environment includes the board game and the other player.
These two core components continuously interact so that the Agent attempts to influence the Environment through actions, and the Environment reacts to the Agent’s actions. How the environment reacts to specific actions is defined by a model that may or may not be known by the Agent, and this differentiates two circumstances:
- When the Agent knows the model, we refer to this situation as a model-based RL. In this case, when we fully know the Environment, we can find the optimal solution by Dynamic Programming. This is not the purpose of this post.
- When the Agent does not know the model, it needs to make decisions with incomplete information; do model-free RL, or try to learn the model explicitly as part of the algorithm.
State
The Environment is represented by a set of variables related to the problem (very dependent on the type of problem we want to solve). This set of variables and all the possible values they can take are referred to as the state space. A state is an instantiation of the state space, a set of values the variables take.
Observation
Due that we are considering that the Agent doesn’t have access to the actual full state of the Environment, it is usually called observation, the part of the state that the Agent can observe. However, we will often see in the literature observations and states being used interchangeably, so we will do this in this series of posts.
Action and the Transition function
At each state, the Environment makes available a set of actions, from which the Agent will choose an action. The Agent influences the Environment through these actions, and the Environment may change states as a response to the Agent’s action. The function responsible for this mapping is called in the literature transition function or transition probabilities between states.
Reward
The Environment commonly has a well-defined task and may provide to the Agent a reward signal as a direct answer to the Agent’s actions. This reward is feedback on how well the last action contributes to achieving the task to be performed by the Environment. The function responsible for this mapping is called the reward function. As we will see later, the Agent’s goal is to maximize the overall reward it receives, and so rewards are the motivation the Agent needs to act in the desired behavior.
Reinforcement Learning cycle
Let’s summarize in the following Figure the concepts introduced earlier in the Reinforcement Learning cycle:

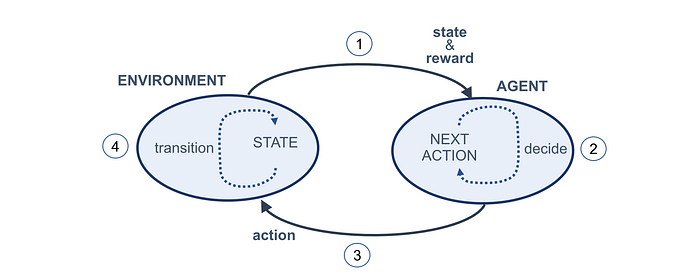
Generally speaking, Reinforcement Learning is basically about turning this Figure into a mathematical formalism.
The cycle begins with the Agent observing the Environment (step 1) and receiving a state and a reward. The Agent uses this state and reward for deciding the next action to take (step 2). The Agent then sends an action to the Environment in an attempt to control it in a favorable way (step 3). Finally, the environment transitions, and its internal state changes as a consequence due to the previous state and the Agent’s action (step 4). Then, the cycle repeats.
Episode
The task the Agent is trying to solve may or may not have a natural ending. Tasks that have a natural ending, such as a game, are called episodic tasks. Conversely, tasks that do not, are called continuous tasks, for example learning forward motion. The sequence of time steps from the beginning to the end of an episodic task is called an episode.
Return
As we will see, Agents may take several time steps and episodes to learn how to solve a task. The sum of rewards collected in a single episode is called a return. Agents are often designed to maximize the return.
One of the limitations is that these rewards are not disclosed to the Agent until the end of an episode, which we introduced earlier as “delayed reward”. For example, in the game of tic-tac-toe the rewards for each movement (action) are not known until the end of the game. It would be a positive reward if the agent won the game (because the agent had achieved the overall desired outcome) or a negative reward (penalties) if the agent had lost the game.
Exploration vs. Exploitation
Another important characteristic, and challenge in Reinforcement Learning, is the trade-off between “exploration” and “exploitation”. Trying to obtain many rewards, an Agent must prefer actions that it has tried in the past and knows that will be effective actions in producing reward. But to discover such actions, paradoxically, it has to try actions that it has not selected never before.
In summary, an Agent has to exploit what it has already experienced to obtain as much reward as possible, but at the same time, it also has to explore to make select better action in the future. The exploration-exploitation dilemma is a crucial topic and still an unsolved research topic. We will talk about this trade-off later in this series.
3. The Frozen-Lake example
Let’s strengthen our understanding of Reinforcement Learning by looking at a simple example, a Frozen Lake (very slippery) where our agent can skate:


The Frozen-Lake Environment that we will use as an example is an ice skating rink, divided into 16 cells (4x4), and as shown in the figure below, some of the cells have broken the ice. The skater named Agent begins to skate in the top-left position, and its goal is to reach the bottom-right place avoiding falling into the four holes in the track.
The described example is coded as the Frozen-Lake Environment from Gym. With this example of Environment, we will review and clarify the RL terminology introduced until now. It will also be useful for future posts in this series to have this example.
3.1 Gym Toolkit
OpenAI is an artificial intelligence (AI) research organization that provides a famous toolkit called Gym for training a reinforcement learning agent to develop and compare RL algorithms. Gym offers a variety of environments for training an RL agent ranging from classic control tasks to Atari game environments. We can train our RL agent to learn in these simulated environments using various RL algorithms. Throughout the series, we will use the Gym toolkit to build and evaluate reinforcement learning algorithms for several classic control tasks such as Cart-Pole balancing or mountain car climbing.
Gym also provides 59 Atari game environments, including Pong, Space Invaders, Air Raid, Asteroids, Centipede, Ms. Pac-Man, etc. Training our reinforcement learning agent to play Atari games is an interesting as well as challenging task. Later in this series, we will train our DQN reinforcement learning agent to play Atari Pong game environment.
Let’s introduce as an example one of the most straightforward environments called Frozen-Lake environment.
3.2 The Frozen-Lake Environment
Frozen-Lake Environment is from the so-called grid-world category when the Agent lives in a grid of size 4x4 (has 16 cells), which means a state space composed of 16 states (0–15) in the i, j coordinates of the grid-world.
In Frozen-Lake, the Agent always starts at a top-left position, and its goal is to reach the bottom-right position of the grid. There are four holes in the fixed cells of the grid, and if the Agent gets into those holes, the episode ends, and the reward obtained is zero. If the Agent reaches the destination cell, it receives a reward of +1, and the episode ends. The following Figure shows a visual representation of the Frozen-Lake Environment:


To reach the goal, the Agent has an action space composed of four directions movements: up, down, left, and right. We also know that there is a fence around the lake, so if the Agent tries to move out of the grid world, it will just bounce back to the cell from which it tried to move.
Because the lake is frozen, the world is slippery, so the Agent’s actions do not always turn out as expected — there is a 33% chance that it will slip to the right or the left. If we want the Agent to move left, for example, there is a 33% probability that it will, indeed, move left, a 33% chance that it will end up in the cell above, and a 33% chance that it will end up in the cell below.
This behavior of the Environment is reflected in the transition function or transition probabilities presented before. However, at this point, we do not need to go into more detail on this function and leave it for later.
As a summary, we could represent all this information visually in the following Figure:

3.3 Coding the Environment
Let’s look at how this Environment is represented in Gym. I suggest to use the Colab offered by Google to execute the code described in this post (Gym package is already installed). If you prefer to use your Python programming environment, you can install Gym using the steps provided here.
The first step is to import Gym:
import gymThen, specify the game from Gym you want to use. We will use the Frozen-Lake game:
env = gym.make('FrozenLake-v0')The environment of the game can be reset to the initial state using:
env.reset()And, to see a view of the game state, we can use:
env.render()The surface rendered by render()is presented using a grid like the following:

Where the highlighted character indicates the position of the Agent in the current time step and
- “S” indicates the starting cell (safe position)
- “F” indicates a frozen surface (safe position)
- “H” indicates a hole
- “G”: indicates the goal
The official documentation can be found here to see the detailed usage and explanation of Gym toolkit.
3.4 Coding the Agent
For the moment, we will create the most straightforward Agent that we can make that only does random actions. For this purpose, we will use the action_space.sample() that samples a random action from the action space.
Assume that we allow a maximum of 10 iterations; the following code can be our “dumb” Agent:
import gymenv = gym.make("FrozenLake-v0")
env.reset()for t in range(10):
print("\nTimestep {}".format(t))
env.render()
a = env.action_space.sample()
ob, r, done, _ = env.step(a)
if done:
print("\nEpisode terminated early")
breakIf we run this code, it will output something like the following lines, where we can observe the Timestep, the action, and the Environment state:

In general, it is challenging, if not almost impossible, to find an episode of our “dumb” Agent in which, with randomly selected actions, it can overcome the obstacles and reach the goal cell. So how could we build an Agent to pursue it?. This is what we will present in the next installment of this series, where we will further formalize the problem and build a new Agent version that can learn to reach the goal cell.
4. How Reinforcement Learning differs from other Learning paradigms
To finish this post, let’s review the basis of Reinforcement Learning for a moment, comparing it with other learning methods.
4.1 Reinforcement Learning vs. Supervised Learning
In supervised learning, the system learns from training data that consists of a labeled pair of inputs and outputs. So, we train the model (Agent) using the training data in such a way that the model can generalize its learning to new unseen data (the labeled pairs of inputs and outputs guide the model in learning the given task).
Let’s understand the difference between supervised and reinforcement learning with an example. Imagine we want to train a model to play chess using supervised learning. In this case, we will train the model to learn using a training dataset that includes all the moves a player can make in each state, along with labels indicating whether it is a good move or not. Whereas in the case of RL, our agent will not be given any sort of training data; instead, we just provide a reward to the agent for each action it performs. Then, the agent will learn by interacting with the environment, and it will choose its actions based on the reward it gets.
4.1 Reinforcement Learning vs. Unsupervised Learning
Similar to supervised learning, in unsupervised learning, we train the model based on the training data. But in the case of unsupervised learning, the training data does not contain any labels. And this leads to a common misconception that RL is a kind of unsupervised learning due we don’t have labels as input data. But it is not. In unsupervised learning, the model learns the hidden structure in the input data, whereas, in RL, the model learns by maximizing the reward.
A classic example is a movie recommendation system that wants to recommend a new movie to the user. With unsupervised learning, the model (agent) will find movies similar to the film the user (or users with a profile similar to the user) has viewed before and recommend new movies to the user. Instead, with Reinforcement Learning, the agent continually receives feedback from the user. This feedback represents rewards (a reward could be time spent watching a movie, time spent watching trailers, how many movies in a row have he watched, and so on). Based on the rewards, an RL agent will understand the user’s movie preference and then suggest new movies accordingly. It is essential to notice that an RL agent can know if the user’s movie preference changes and suggest new movies according to the user’s changed movie preference dynamically.
4.3 Where are the data in Reinforcement Learning?
We can think that we don’t have data in Reinforcement Learning as we have in Supervised or Unsupervised Learning. However, the data is actually the Environment because if you interact with this Environment, then data (trajectories) can be created, which are sequences of observations and actions. Then we can do some learning on top, and that’s basically the core of Reinforcement Learning.
Sometimes, we can use extra data from people or trajectories that exist, for instance, in imitation learning. We might actually just observe a bunch of people playing the game, and we don’t need to know precisely how the Environment works. Sometimes we have explicitly given a data set, as a sort of a supervised data set, but in the pure Reinforcement Learning setting, the only data is the Environment.
5. Applications of RL
Reinforcement Learning has evolved rapidly over the past few years with a wide range of applications. One of the primary reasons for this evolution is the combination of Reinforcement Learning and Deep Learning. This is why we focus this series on presenting the basic state-of-the-art Deep Reinforcement Learning algorithms (DRL).
5.1 Real-life applications of DRL
The media has tended to focus on applications where DRL defeat humans at games, with examples as I mentioned at the beginning of this post: AlphaGo defeated the best professional human player in the game of Go; AlphaStar beat professional players at the game of StarCraft II; OpenAI’s Dota-2-playing bot beat the world champions in an e-sports game.
Fortunately, there are many real-life applications of DRL. One of the well known is in the area of driverless cars. In manufacturing, intelligent robots are trained using DRL to place objects in the right position, reducing labor costs, and increasing productivity. Another popular application of RL is dynamic pricing that allows changing the price of products based on demand and supply. Also, in a recommendation system, RL is used to build a recommendation system where the user’s behavior continually changes.
In today’s business activities, DRL is used extensively in supply chain management, demand forecasting, inventory management, handling warehouse operations, etc. DRL is also widely used in financial portfolio management, predicting, and trading in commercial transaction markets. DRL has been commonly used in several Natural Language Processing (NLP) tasks, such as abstractive text summarization, chatbots, etc.
Many recent research papers suggest applications of DRL in healthcare, education systems, smart cities, among many others. In summary, no business sector is left untouched by DRL.
5.2 Safely and Security of DRL
DRL agents can sometimes control hazardous real-life Environments, like robots or cars, which increases the risk of making incorrect choices. There is an important field called safe RL that attempts to deal with this risk, for instance, learning a policy that maximizes rewards while operating within predefined safety constraints.
Also, DRL agents are also at risk from an attack, like any other software system. But DRL adds a few new attack vectors over and above traditional machine learning systems because, in general, we are dealing with systems much more complex to understand and model.
Considering the safety and security of DRL systems are outside the introductory scope of this post. Still, I would like the reader to be aware of it and if in the future you put a DRL system into operation, keep in mind that you should treat this point in more depth.
5.3 We cannot shy away from our responsibility
Artificial Intelligence is definitely penetrating society, like electricity, what will we expect? The future we will “invent” is a choice we make jointly, not something that happens. We are in a position of power. With DRL, we have the power and authority to automate decisions and entire strategies.
This is good! But as in most things in life, where there is light, can be the shadow, and DRL technology is hazardous in the wrong hands. I ask you that as engineers consider what we are building: Could our DRL system accidentally add bias? How does this affect individuals?. Or how does our solution affect the climate due to its energy consumption? Can be our DRL solution unintended used? Or use?. Or, in accordance with our ethics, can it have a type of use that we could consider nefarious?
We must mull over the imminent adoption of Artificial Intelligence and its impact. Were we to go on to build Artificial Intelligence without regard to our responsibility of preventing its misuse, we can never expect to see Artificial Intelligence help humanity prosper.
All of us, who are working or want to work on these topics, cannot shy away from our responsibility, because otherwise, we will regret it in the future.
6. Summary
We started the post by understanding the basic idea of RL. We learned that RL is a trial and error learning process and the learning in RL happens based on a reward. We presented the difference between RL and the other ML paradigms. Finally, we looked into some real-life applications of RL and thought about the safety, security, and ethics of DRL.
In the next post, we will learn about the Markov Decision Process (MDP) and how the RL environment can be modeled as an MDP. Next, we will review several important fundamental concepts involved in RL. See you in the next post!
Post updated on 8/12/2020
Deep Reinforcement Learning Explained Series
by UPC Barcelona Tech and Barcelona Supercomputing Center
A relaxed introductory series that gradually and with a practical approach introduces the reader to this exciting technology that is the real enabler of the latest disruptive advances in the field of Artificial Intelligence.
Deep Reinforcement Learning Explained - Jordi TORRES.AI
Content of this series
About this series
I started to write this series in May, during the period of lockdown in Barcelona. Honestly, writing these posts in my spare time helped me to #StayAtHome because of the lockdown. Thank you for reading this publication in those days; it justifies the effort I made.
Disclaimers — These posts were written during this period of lockdown in Barcelona as a personal distraction and dissemination of scientific knowledge, in case it could be of help to someone, but without the purpose of being an academic reference document in the DRL area. If the reader needs a more rigorous document, the last post in the series offers an extensive list of academic resources and books that the reader can consult. The author is aware that this series of posts may contain some errors and suffers from a revision of the English text to improve it if the purpose were an academic document. But although the author would like to improve the content in quantity and quality, his professional commitments do not leave him free time to do so. However, the author agrees to refine all those errors that readers can report as soon as he can.
标签:Environment,learning,introduction,Agent,will,gentle,Reinforcement,Learning 来源: https://www.cnblogs.com/dhcn/p/15333710.html