manacher
作者:互联网
\(\text{Description}\)
给出一个只由小写英文字符 \(\text{a,b,c,}\dots\text{,y,z}\) 组成的长度为 \(n\) 的字符串 \(S\),求 \(S\) 中最长回文串的长度 。
\(\text{Solution}\)
例如 \(S=\text{abcbac}\) 时,\(S\) 中最长回文串为 \(\text{abcba}\),长度为 \(5\)。
对于 最长回文串 的问题,我们有以下几种方法:
1. 枚举
枚举左右端点 \(l,r\),再判断区间 \([l,r]\) 内是否为回文串并更新答案。
时间复杂度 \(\mathcal{O}(n^3)\)。
2. 扩展
枚举中间点 \(mid\),再尝试往两边扩展。
时间复杂度 \(\mathcal{O}(n^2)\)。
3. \(\rm manacher\)
按照我们对字符串算法的感觉,最后肯定是能做到线性的。
所以 \(\rm manacher\) 算法诞生了!
当然我们习惯叫它“马拉车”。
它的思想和 \(\rm KMP\) 类似,都是通过某些方法来减少重复的计算。
首先它做了一些细节上的优化,我们看到扩展算法中 \(n\) 可能为奇数或偶数,当 \(n\) 是奇数时还比较好弄,但 \(n\) 为偶数时 \(mid\) 就会变成中间的空隙,所以 \(\rm manacher\) 有一个 \(\operatorname{init}\) 函数来对字符串进行改造。
void init() //n为原字符串长度,l为改造后长度
{
s[0] = '$';
s[++l] = '#';
for (int i = 0; i < n; i++)
{
s[++l] = a[i];
s[++l] = '#';
}
}
若改造前 \(S=\text{abcbac}\),则改造后 \(S=\text{\$\#a\#b\#c\#b\#a\#c\#}\)。
这个第 \(0\) 位的 \(\text{\$}\) 是防止越界的,我们可以不管它。
除去 \(\$\) 后,这个新的 \(S\) 的长度 \(l\) 就变成了 \(2n+1\),它一定是个奇数,这样就方便处理了。
然后进入正题,即如何减少重复的计算。
我们开一个 \(len\) 数组,\(len_i\) 表示以 \(i\) 为中心点最多能往两边扩展多少。
当 \(S=\text{\$\#a\#b\#c\#b\#a\#c\#}\) 时,\(S_6=\text{c}\),以 \(\text{c}\) 为中心点,往左能扩展到 \(\text{\#a\#b\#c}\),往右能扩展到 \(c\#b\#a\#\),所以 \(len_6=6\)。
再用两个变量 \(maxr\) 和 \(mid\),\(maxr\) 记录当前往两边扩展到的最右端,\(mid\) 则是 \(maxr\) 所对应的中心点。
从 \(1\) 遍历到 \(l\),当遍历到第 \(i\) 位时:
-
若 \(i\le maxr\)
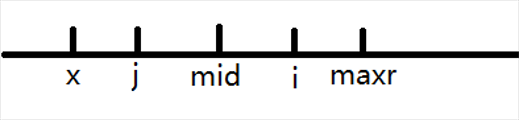
设♂这个 \(maxr\) 关于 \(mid\) 对称的是 \(x\),那么 \(x\sim maxr\) 这一段是回文的。
再设 \(i\) 关于 \(mid\) 对称的是 \(j\),因为是回文的所以 \(len_i=len_j\)。但是如果 \(i+len_i-1>maxr\),这一段多出去的部分我们是不知道的,只能令 \(len_i\gets\min(len_j,maxr-i+1)\),其中 \(maxr-i+1\) 为 \(i\sim maxr\) 这一段的长度。
问题来了:该如何计算 \(j\) 呢?
好吧我知道很水\(\because mid=\dfrac{i+j}{2}\)
\(\therefore j=2\times mid-i\)
-
现在无论 \(i\) 是否 \(\le maxr\),都只剩下我们没有处理过的部分了,那就暴力呗。
-
尝试更新 \(maxr,mid\)。
void manacher()
{
int maxr = 0, mid = 0;
for (int i = 1; i <= l; i++)
{
if (i <= maxr)
{
len[i] = min(len[(mid << 1) - i], maxr - i + 1); //j = (mid << 1) - i
}
while (s[i + len[i]] == s[i - len[i]]) //暴力扩展
{
len[i]++;
}
if (i + len[i] - 1 > maxr) //更新
{
maxr = i + len[i] - 1;
mid = i;
}
}
}
显然最后 \(ans=\max_{1\le i\le l}\{len_i\}\),但是输出的并不是 \(ans\) 而是 \(ans-1\)。
还是以 \(S=\text{\$\#a\#b\#c\#b\#a\#c\#}\) 为例,最长往左扩展到 \(\text{\#a\#b\#c}\),\(len_6=6\),那么去掉 \(\#\) 后 \(\text{abc}\) 的长度就是 \(\dfrac{len_6}{2}\),整个回文串 \(\text{abcba}\) 的长度就是 \(2\times\dfrac{len_6}{2}-1=len_6-1\),所以最后输出的是 \(ans-1\)。
时间复杂度
其实就相当于一直更新 \(maxr\),把 \(maxr\) 从 \(0\) 推到底,因此时间复杂度为 \(\mathcal{O}(n)\)。
\(\text{Code}\)
#include <iostream>
#include <cstdio>
#include <cstring>
using namespace std;
const int MAXN = 1.1e7 + 5;
char a[MAXN], s[MAXN << 1];
int len[MAXN << 1];
int n, l;
void init()
{
s[0] = '$';
s[++l] = '#';
for (int i = 0; i < n; i++)
{
s[++l] = a[i];
s[++l] = '#';
}
}
void manacher()
{
int maxr = 0, mid = 0;
for (int i = 1; i <= l; i++)
{
if (i <= maxr)
{
len[i] = min(len[(mid << 1) - i], maxr - i + 1);
}
while (s[i + len[i]] == s[i - len[i]])
{
len[i]++;
}
if (i + len[i] - 1 > maxr)
{
maxr = i + len[i] - 1;
mid = i;
}
}
}
int main()
{
scanf("%s", a);
n = strlen(a);
init();
manacher();
int ans = 0;
for (int i = 1; i <= l; i++)
{
ans = max(ans, len[i]);
}
printf("%d\n", ans - 1);
return 0;
}
标签:maxr,manacher,mid,len,int,text 来源: https://www.cnblogs.com/mangoworld/p/manacher.html