数据可视化整理
作者:互联网
写在之前
选自《Python编程从入门到实践》
正式开始
生成数据
对于密集的数据,只是简单直观的观察无法明白其含义,而通过类似于图表方式呈现数据便于理解含义
Python中的Matplotlib用于制作简单的图表,例如折线图以及散点图
Pygal专注于生成适合在数字设备显示的图表。通过使用Pygal,可在用户与图标交互时突出元素以及调整其大小,还可以轻松地调整整个图表的尺寸,使其适合在不同设备上显示。
Matplotlib
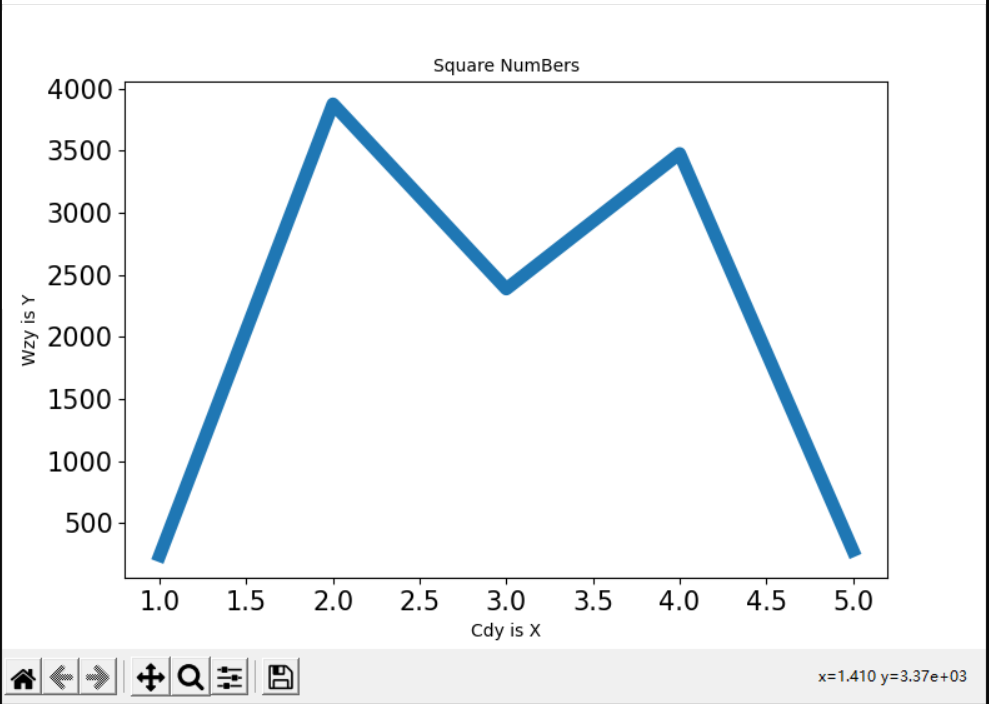
展示使用Matplotlib来绘制一个折线图
# 导入matplotlib中的pyplot模块,利用其中的工具进行操作
import matplotlib.pyplot as plt
# 接下来的两个列表分别对应横纵坐标的数据
InPut=[1,2,3,4,5]
list=[238,3878,2387,3478,278]
plt.plot(InPut,list,linewidth=7.5) #绘制折线图的函数 传递横纵坐标以及线的粗细
plt.title("Square NumBers",fontsize=10) #绘制主标题以及标题字号大小
plt.xlabel("Cdy is X",fontsize=10) #绘制横坐标标题以及标题字号大小
plt.ylabel("Wzy is Y",fontsize=10) #绘制纵坐标标题以及标题字号大小
plt.tick_params(axis='both',labelsize=15) #修改坐标轴上标记字号的大小,‘both’表示都修改
plt.show() #打开matplotlib查看器,显示绘制的图表
效果如下(单击磁盘图标可用于保存):
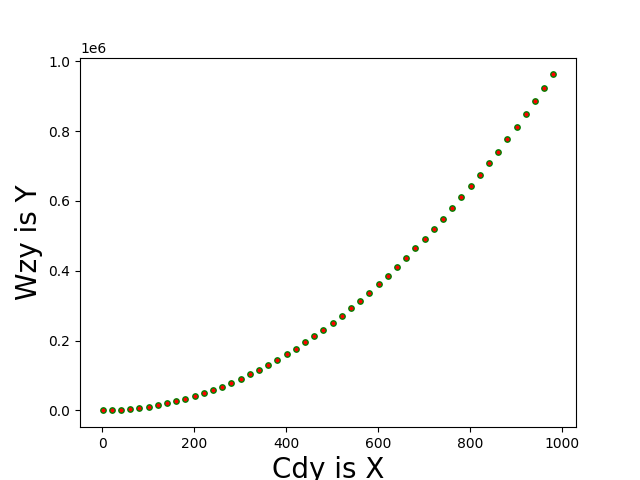
除了折线图之外 还可以绘制散点图
import matplotlib.pyplot as plt
x_values=[]
y_values=[]
# 绘制一个[1,21,41,...]的平方分布的散点图
for i in range(1,1001,20):
x_values.append(i)
y_values.append(i**2)
# 后三个分别是点的颜色 点边缘的颜色 点的大小
plt.scatter(x_values,y_values,c="red",edgecolor="green",s=15)
# 同上
plt.xlabel("Cdy is X",fontsize=20)
plt.ylabel("Wzy is Y",fontsize=20)
# plt.savefig("Picture1.png",bbox_inches="tight")
# 将生成的散点图保存在同一文件目录下的图片中
plt.savefig("Picture1.png")
效果如下:
保存在本地文件夹:
Pygal
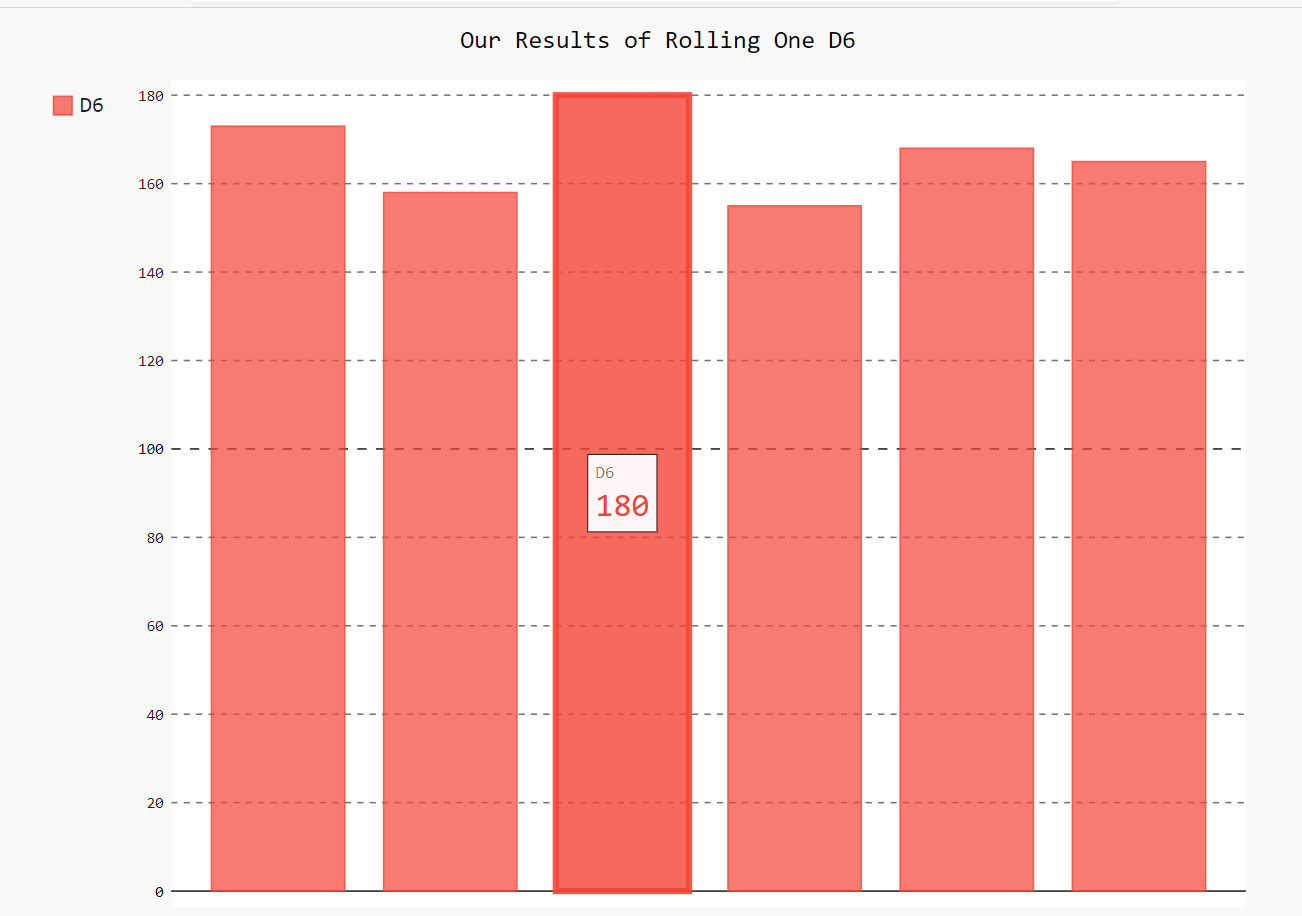
这里模拟的是掷一个色子1000次 然后绘制直方图来显示不同点数的出现次数分布
from random import randint
import pygal
# 一个用于模拟单次随机掷色子的点数的类
class Die():
def __init__(self,num_sides=6):
self.num_sides=num_sides
def roll(self):
return randint(1,self.num_sides)
die=Die()
results=[]
frequencies=[]
# 收集1000次的结果
for roll_num in range(1,1000):
result=die.roll()
results.append(result)
# 收集1000次中不同点数出现的次数
for value in range(1,die.num_sides+1):
frequency=results.count(value)
frequencies.append(frequency)
# 为了创建条形图 我们创建了一个pygal.Bar()的实例,并将其存储在hist中
hist=pygal.Bar()
# 标题
hist.title="Our Results of Rolling One D6"
# 横坐标轴
hist.x_lables=['1','2','3','4','5','6']
# 使用add将一系列值添加到图表中,'D6'表示标签也就是图例
hist.add('D6',frequencies)
# 存储在一个文件中,文件名为
hist.render_to_file('die_visual.svg')
效果如下(我们把光标移到对应的条形上面之后,显示具体数字,体现交互性):
生成的文件位于同一文件目录中:
下载数据
对于数据可视化,很大一部分都是可视化从网上下载的庞大复杂的数据
这里处理的是两种比较常见的数据存储格式:CSV以及JSON
CSV
文本文件中存储数据最简单的就是将数据作为一系列以逗号分隔的值(CSV)作为文件
例如:
2983,238478,3802387,2378-238-2387,-2378,...,23878,238478,,238478
对于人而言 阅读起来非常麻烦 但是对于程序而言 这有助于加快数据分析过程
接下来对于保存在一个csv格式文件里的阿拉斯加锡特卡天气数据进行分析
首先是分析csv文件头
# 导入csv模块
import csv
filename="sitka_weather_07-2014.csv"
# 打开文件并将结果文件对象存储在f中
with open(filename) as f:
#调用csv.reader()创建一个与该文件相关的阅读器(reader)
#这里的话我把reader理解为一个指针 指向当前的一行
reader=csv.reader(f)
#next表示返回调用文件(reader)的下一行
header_now=next(reader)
print(header_now)
效果如下:

在具体打印某一列的数据:
import csv
filename="sitka_weather_07-2014.csv"
with open(filename) as f:
reader=csv.reader(f)
header_now=next(reader)
highs=[]
# 从reader当前指向一行向下不断枚举 反复提取第0列
for row in reader:
highs.append(row[0])
print(highs)
效果如下:

提取数据完成之后,我们来利用提取的数据绘制气温折线图:
import csv
from datetime import datetime
from matplotlib import pyplot as plt
filename="sitka_weather_2014.csv"
highs=[]
dates=[]
lows=[]
with open(filename) as f:
reader=csv.reader(f)
header_now=next(reader)
for row in reader:
current_date=datetime.strptime(row[0],"%Y-%m-%d")
#利用python提供的datetime工具来处理日期
dates.append(current_date)
high=int(row[1])
highs.append(high)
low=int(row[3])
lows.append(low)
# 调整显示屏幕尺寸
fig=plt.figure(dpi=128,figsize=(10,6))
# 分别画两条不同颜色的折线来表示高低温
plt.plot(dates,highs,c="blue")
plt.plot(dates,lows,c="red")
# 中间填充色
plt.fill_between(dates,highs,lows,facecolor='blue',alpha=0.1)
# 绘制倾斜标签
fig.autofmt_xdate()
plt.show()
效果如下:
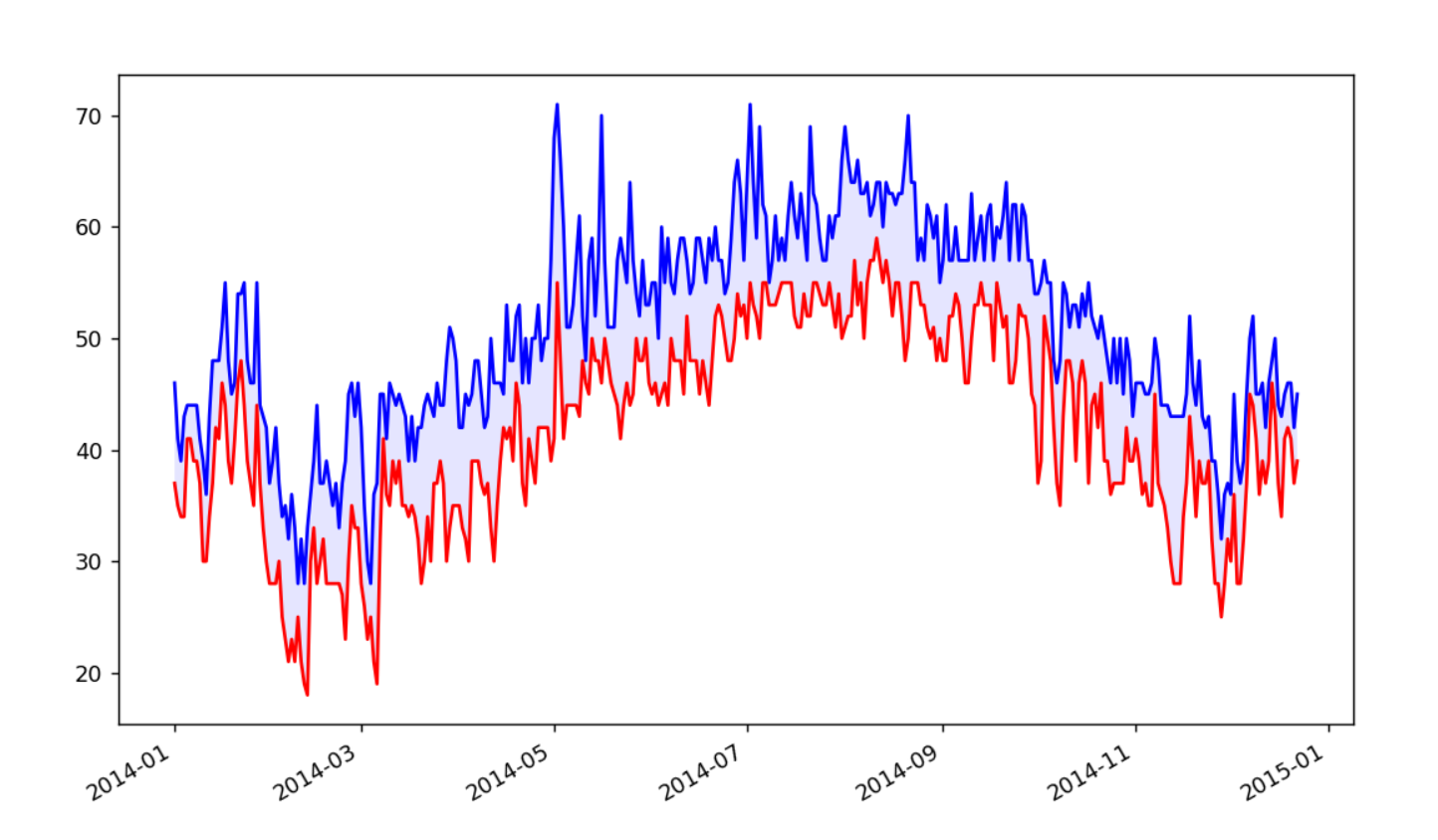
但是我们不能保证我们的数据没有半分纰漏
比如说我们的示例文件之中存在数据缺失
所以我们需要来一个检查机制来对数据进行筛查 防止出现数据缺失造成的错误
import csv
from datetime import datetime
from matplotlib import pyplot as plt
filename="death_valley_2014.csv"
highs=[]
dates=[]
lows=[]
with open(filename) as f:
reader=csv.reader(f)
header_now=next(reader)
for row in reader:
try:
current_date=datetime.strptime(row[0],"%Y-%m-%d")
high=int(row[1])
low=int(row[3])
# 一个特殊的异常类型 数据缺失 打印出缺失的日期
except ValueError:
print(current_date,"missing_date")
else:
dates.append(current_date)
highs.append(high)
lows.append(low)
fig=plt.figure(dpi=128,figsize=(10,6))
tot=len(dates)
plt.plot(dates,highs,c="blue")
plt.plot(dates,lows,c="red")
plt.fill_between(dates,highs,lows,facecolor='blue',alpha=0.1)
fig.autofmt_xdate()
plt.show()
效果如下:

JSON
JSON同样是数据存储的格式之一
我们提取json格式的数据并利用pygal来处理 这里展示的根据世界人口数据来生成世界人口地图
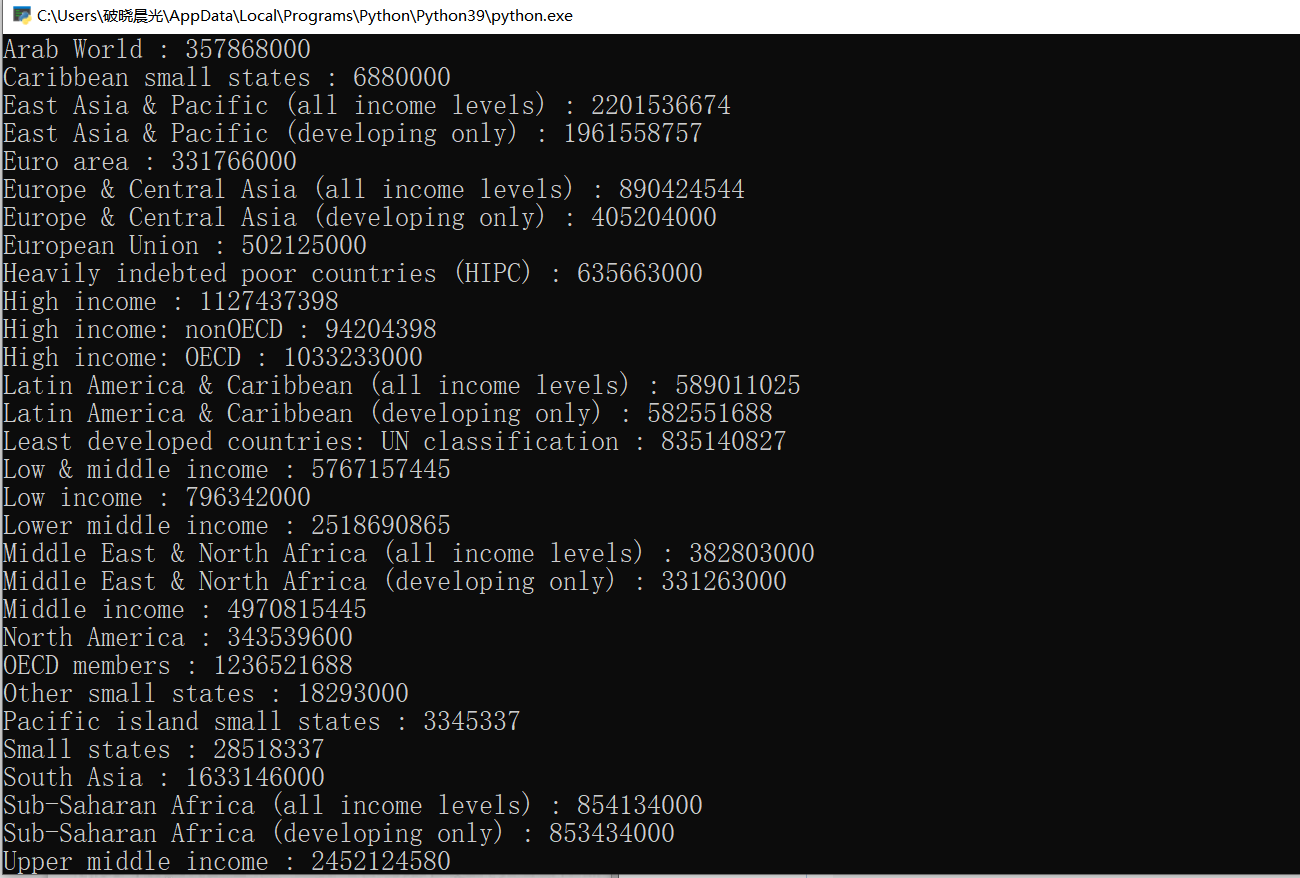
首先 提取json格式的数据
import json
filename="population_data.json"
with open(filename) as f:
pop_data=json.load(f)
#将其中的数据导入到一个列表中
for pop_dict in pop_data:
if pop_dict["Year"]=='2010':
country_name=pop_dict["Country Name"]
population=int(float(pop_dict["Value"]))
print(country_name+" : "+str(population))
效果如下:
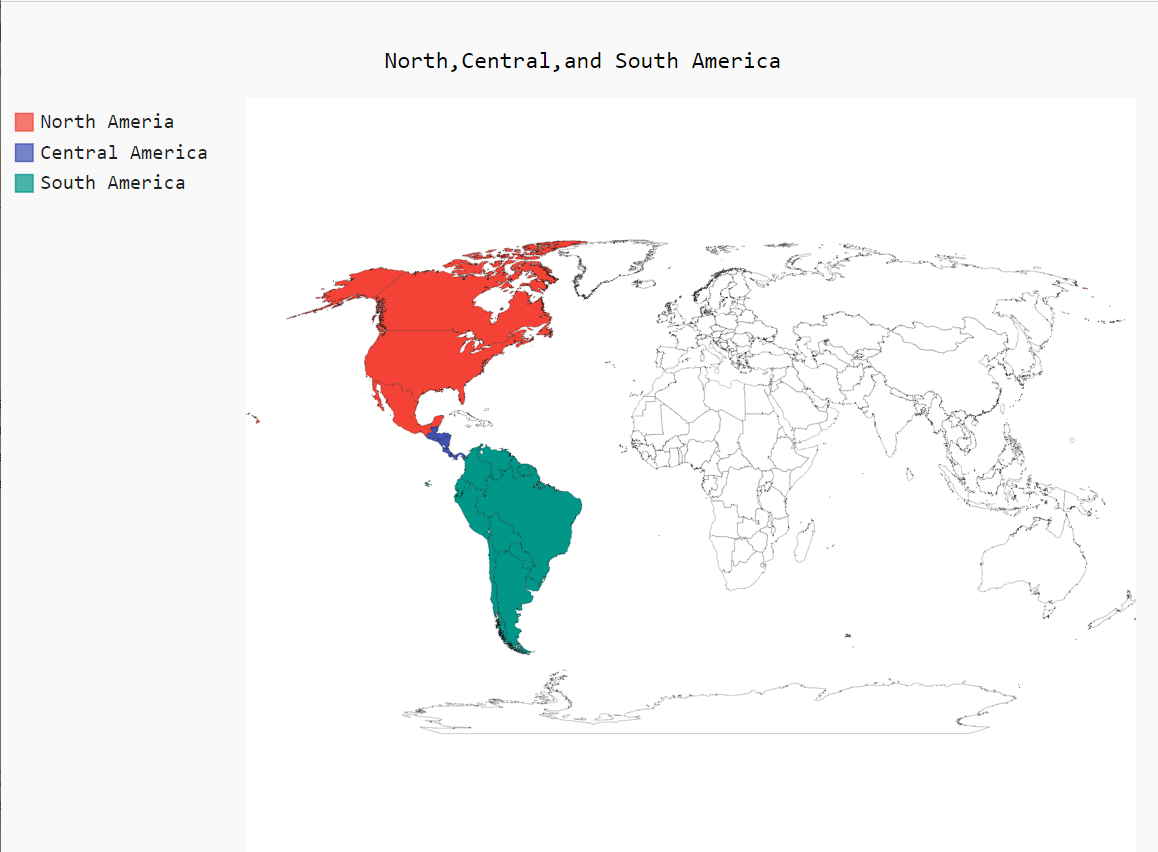
其次 生成一个简单,美洲的的地图
# pygal自己提供了一个地图制作工具
import pygal.maps.world
wm = pygal.maps.world.World()
wm.title="North,Central,and South America"
# add()前者是标签 后者是利用python的国别码来代表国家的列表
wm.add('North America',['ca','mx','us'])
wm.add('Central America',['bz','cr','gt','hn','ni','pa','sv'])
wm.add('South America',['ar','bo','br','cl','co','ec','gf','gy','pe','py','sr','uy','ve'])
wm.render_to_file("americas.svg")
效果如下:
接下来 按照2010年的人口数据来制作世界人口分布地图
import json
import pygal
from pygal.style import RotateStyle
from pygal.style import LightColorizedStyle
import pygal.maps.world
from country_codes import get_country_code
filename="population_data.json"
with open(filename) as f:
pop_data=json.load(f)
# 把上面传递的列表替换成了字典
# 这样的话add函数会自动根据字典value的值来决定颜色深浅
world_population={}
for pop_dict in pop_data:
if pop_dict["Year"]=="2010":
country=pop_dict["Country Name"]
population=int(float(pop_dict["Value"]))
code=get_country_code(country)
if code:
world_population[code]=population
#利用颜色编码设置基本颜色 后者LightColorizedStyle是加亮
wm=pygal.maps.world.World(style=RotateStyle("#336699",base_style=LightColorizedStyle))
wm.add('2010',world_population)
wm.render_to_file("World_Population.svg")
效果如下:
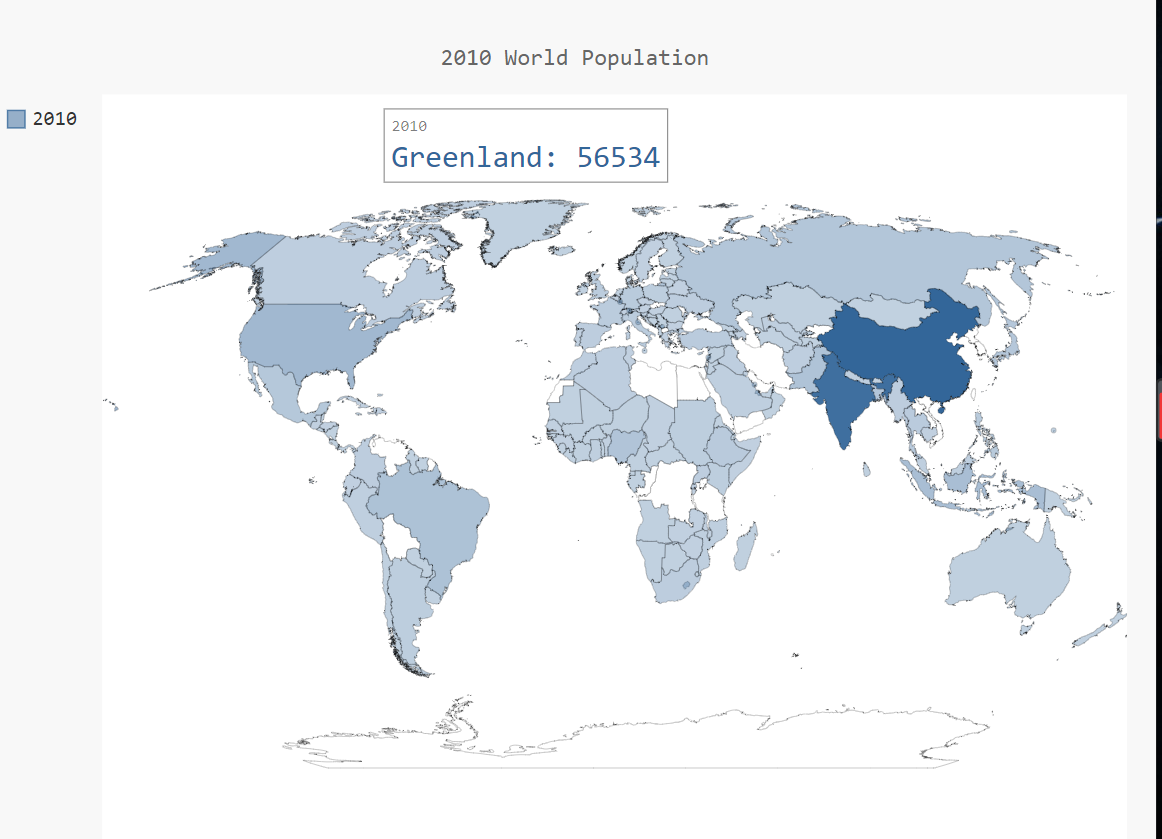
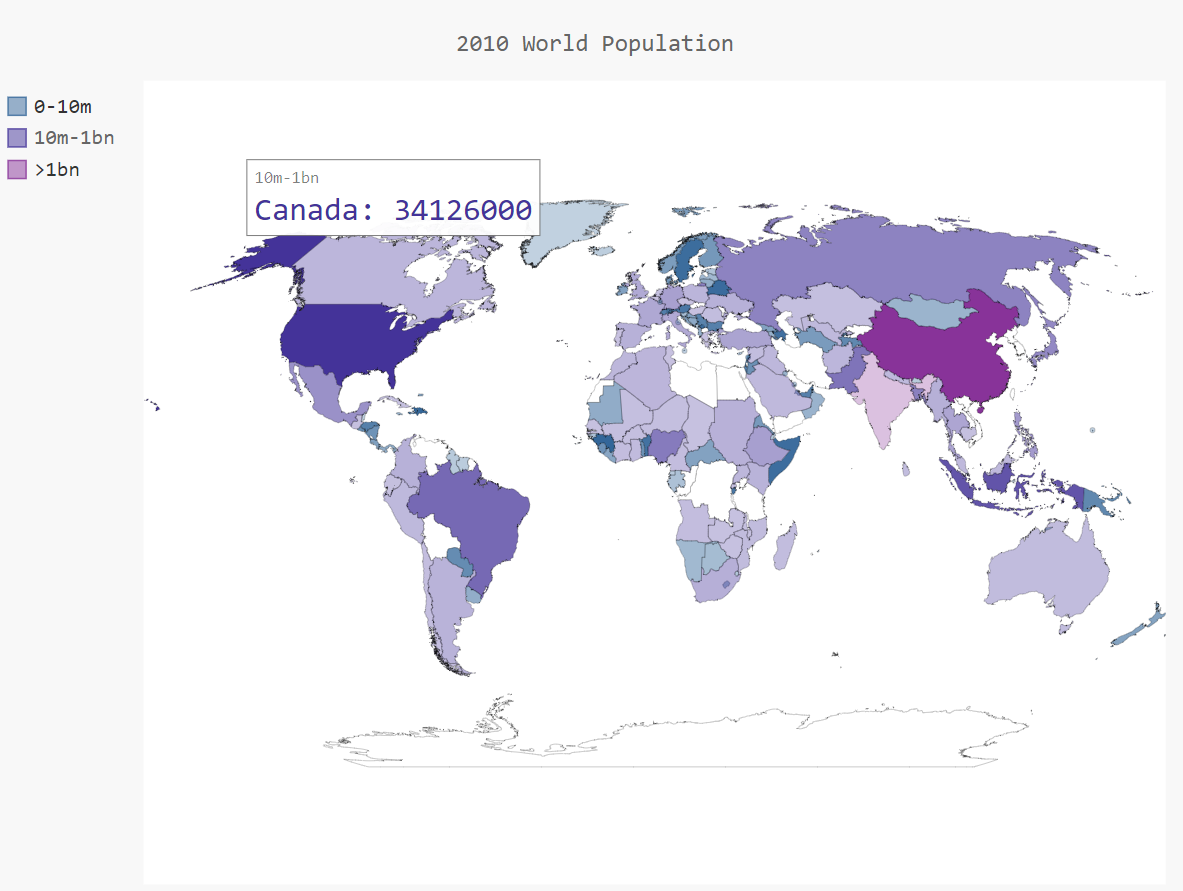
可以很明显的发现 对于数据来讲 由于特殊数据(中国,印度的人口)的存在 导致了直观感觉不是很好
所以我们接下来进行一个简单的分组(010^7,10^7109,大于109)
import json
import pygal
from pygal.style import RotateStyle
from pygal.style import LightColorizedStyle
import pygal.maps.world
from country_codes import get_country_code
filename="population_data.json"
with open(filename) as f:
pop_data=json.load(f)
world_population={}
for pop_dict in pop_data:
if pop_dict["Year"]=="2010":
country=pop_dict["Country Name"]
population=int(float(pop_dict["Value"]))
code=get_country_code(country)
if code:
world_population[code]=population
cc_pops_1={}
cc_pops_2={}
cc_pops_3={}
for cc,pop in world_population.items():
if pop<10000000:
cc_pops_1[cc]=pop
elif pop<1000000000:
cc_pops_2[cc]=pop
else:
cc_pops_3[cc]=pop
wm=pygal.maps.world.World(style=RotateStyle("#336699",base_style=LightColorizedStyle))
wm.title="2010 World Population"
# 打上分组的标签 分别传递三个不同的字典
wm.add('0-10m',cc_pops_1)
wm.add('10m-1bn',cc_pops_2)
wm.add('>1bn',cc_pops_3)
wm.render_to_file("World_Population1.svg")
效果如下:
标签:plt,pop,可视化,pygal,reader,整理,import,csv,数据 来源: https://www.cnblogs.com/tcswuzb/p/15116920.html