【句句干货】科研葵花宝典
作者:互联网
我愿称之为【科研最强葵花宝典】
本片文章摘自https://scientist-with-logic.github.io/ 博客,这个博客分享关于科研和创新方面的一些经验。
一口气从头到尾把该博主的科研经验学习了一遍,实在是醍醐灌顶!解了我的许多困惑,真乃神功也。
想要发表论文,你需要提升自己的逻辑思维能力
拥有强大逻辑思维能力的人可以把一个方法的理解出三种层次:
- 数学层次
学生开始按照论文里面的公式,一步步进行推导。过了几天以后,经过推导,这个学生发现论文里面的公式是正确的,然后按照公式可以一步步明白作者的方法。这时候理解的层次就是数学层次。 - 几何层次
当一个学生理解到了这个层次的时候,就可以直观地想象出数据的样子还有数据被操作的过程了。 - 物理层次
在这个层次上,你不光可以想象到数据在空间中的样子,你还可以明白这些数据在每一步被处理的时候到底是什么含义。
那我们为什么要把一个方法理解到这么深的层次呢?当我们对于个方法的理解越丰富,我们对一个方法可以改进的地方就越多。那么将来大家可以创新的机会就越多了。很多论文如果真正地研究透了以后,会发现其实他就是另一篇论文在某一个地方的改进而已。然而为什么这种改进在这些作者手中就发表出来了,而且发表在了很顶级的期刊或者会议呢?那就是因为作者们掌握了正确的逻辑思维,作者们知道怎么发现,理解并且创新。
可是绝大多数人都是怎么做的?绝大多数人理解到了数学层次上就停下了,他们会把公式写成代码,然后一遍遍去运行代码来看实验结果。这时候有很大的概率实验是很难复现的。究其原因就是对于这个方法的理解出现了偏差。可是人们往往误以为是自己的代码写的不对。然后花费几个月的时候去改代码,调参数。大家这么做背后的原因是大家习惯了所谓的“勤能补拙”。大家都认为我不把代码能力练得炉火纯青,我就没法做实验,我就没法弄出来好的结果。可是事实上,很多的时候如果你对于一个方法的理解够深,不需要做实验也是可以知道结果的。大家习惯了不去思考更深一层的东西,而是幻想着去通过体力上的努力来弥补脑力上的思考。因为不会正确的逻辑思维,一个人就会懒于思考,他就会误以为思考这些太浪费时间。这样是不行的。
我们自己应该整理出来的一套逻辑。我写这两个版本就是为了让大家看一看不同的逻辑思维在写作和理解上带来的差距。逻辑思维能力不是一个超能力,而是一个我们每个人通过训练都可以获得的能力。这个训练不会经历三年五年,只要掌握了正确的方法,两三个月就可以让你自己的逻辑思维能力大大提升。最终这个良好的逻辑思维能力足以支撑你把能够发表的论文的档次一点点提高。
一篇论文应该怎么写?
我开始思考,我当初是怎么学的写作呢?我的写作风格师承我的导师。当初我写一段,导师就当面给我改一段,边改边告诉我这个地方为什么要这么改。导师改完以后逻辑就变得比之前通顺很多,读起来也更好理解了。一句话总结,就是多写多改。
为什么你提出的idea会和别人重合?怎么写introduction和abstract?
一个idea里面包含的信息是很多的。而且这些信息表达的顺序一般来说也是比较固定的。之所以要按照一定顺序将这些信息表达出来,就是为了让你的idea变得有逻辑,让读者能够更加轻松地理解你的idea。因此,一个合格的idea,应该按照下面的顺序将以下的信息逐个表达出来:
- idea的背景
- 一个具体的研究问题
具体的研究问题和背景有时候容易混淆。这个具体的问题指的是你的论文直接要解决的一个问题,而不是一个特别宽泛的问题。
其实,一个idea可以对应解决不同的研究问题。而在论文里面写的不同的研究问题,就将决定这个idea的定位,还有这篇论文的档次高低。 - 别人是怎么做的
这里面要列举一下别人的科研工作。请大家注意,这个可不是参考文献里面随随便便列举一些论文。这里应该是你真正理解的几种方法。 - 别人的方法中存在什么问题
这里我们需要把别人的方法中的最致命的问题提出来。这个问题将是我们的论文真正解决的一个问题!这个十分的关键!千万别和2混淆! - 别人的方法出现这些问题的原因是什么
我们一定要在idea中将别人方法中出现问题的原因找出来。只有找到了问题的原因,我们才有可能解决这个问题。如果没有这一条,那么读者就会不明白为什么你的方法一定从理论上就可以解决这个问题。如果没有这一条,即使我们做了大量实验证明你的方法比别人好,读者也不会相信我的方法一定比别人的好,因为原理上说不通。 - 你发现了什么新的现象或者信息,并利用这一现象提出一个新的方法来避免前人的问题。
insight! 你发现了什么新的现象或者信息,并利用这一现象提出一个新的方法来避免前人的问题。这一条就很有意思了。这一条是我们的idea的核心。只有引入了新的信息和观察到了别人没有观察到的现象,并加以利用,我们的方法才可能比别人的方法好! - 你的方法里面真正的挑战是什么
如果一个idea里面没有任何挑战,那将这个idea的创新性将大打折扣。同时,一个没有挑战的idea一定很容易被别人想到。然而,我不是在这里劝大家一定要去硬生生地编造一些挑战出来,而是要真真切切地有挑战才可以。 - 为了克服挑战,你提出的具体的设计是什么?
写论文就是通过我们严谨的逻辑思维,将一个模糊的想法,一点点细化成为一个有价值的,有说服力的idea!
如果你按照今天我介绍的这个标准去提一个idea,你真的还会担心有人跟你提出相同的idea么?我跟很多同学沟通的时候我发现,他们的idea之所以跟别人重合,是因为他们并没有深思熟虑。有的时候看到一篇新发表的论文就拍自己大腿,后悔地说当初我怎么就慢了呢?我怎么没快点把这个idea发表了呢?可是大家认真想一想,你有没有真的去把这个idea做出来?我说的实际操作过程中遇到的挑战往往不是直接就能想到的,而是要通过实验才发现自己最初的idea并不能在实际中直接使用。而是需要我们克服一些之前没想到的困难才可以。这时候,大家还真的认为idea那么容易就跟别人重合么?
刚才这8条信息,按照我这个写作的方法,再稍微加一些实验的结果,就是我们的论文的introduction了。如果将这8条信息,每一条浓缩成一句话,然后把8句话合在一起,那就是abstract了。在此,我想我不光介绍了什么才是一个idea,我还告诉了大家应该怎么写abstract和introduction。
此外,不同写作顺序带来的影响和好处。也想告诉大家一下,一个正确的逻辑是多么重要。一个错误的逻辑将会让整个idea变得混乱不堪,无法理解,十分罗嗦。
怎么判断你提出来的idea的档次高低?
一个idea的创新程度,就可以反映在这个idea处于这棵树的层级。
任何idea都有一定的假设条件。有的idea里面的假设条件很明显,有的则是很隐晦。每当有一个创新性很强的idea出现的时候,它都会打破原有方向上的某些假设条件。
一个idea的创新程度,取决于它打破了这个人类知识树的哪一层上的假设。
两种提出idea的思路
在我们阅读了大量的别人的论文以后,我们掌握了一些有趣的insights。这时候我们开始提出自己的idea。当我们有了一个初步的idea以后,我们便开始通过做一些实验来验证自己提出的idea,并且将这个idea中的细节部分逐步完善。最终,一个idea会引申出好几个designs。这些designs也就对应了论文中的几个technical contributions。
现在我们回到我们掌握了几个insights后,开始想自己的idea的那个时刻。我们可能会提出两种类型的idea:一种是应用型的idea。另一种是颠覆性的idea。颠覆性的idea引申出的几个designs其实是在完成不同的任务。这些任务全都成功地完成了以后,我们这个idea所期盼的研究的目标才得以完成。而应用型的idea最后引申出来的的几个designs其实是在做相同的任务,只不过是每个design对应着不同的场景。
首先我们来看看应用型的idea。
在这个idea里面,我们有两个设计:basic design 和advanced design。其中,basic design就可以满足我们最基本的需求。而advanced design存在的目的只是为了更大地扩展basic design的应用场景或者提高一下basic design的性能。即使我们没有Advanced design,我们最初的设计也是可以用的,只不过是效果稍微差了一点点而已。
颠覆式的idea
颠覆式的idea的design往往是相互影响,缺一不可的。所以这种idea里面结局的问题往往是非常复杂而且交织在一起的。一旦这种科研项目做成了,其成功往往是颠覆性的。
那么这两种idea一般都是怎么想出来的呢? 其实大家可以看出来,这两种idea里面,应用型的idea应该比颠覆性的idea容易想到。这是为什么呢?因为应用型的idea里面,我们只需要想出一个简单但是有效的设计作为basic design就好了。至于advanced design,我们可以多换一些场景,没准就可以想出来。换句话说,即使我们想不出来advanced design,我们至少还有basic design。按照世俗的眼光来看,只要basic design说的通,我们计算机的同学们至少可以试着往CCF C类会议投稿。
一个应用型的idea一般是这样提出来的: 我看了几篇论文。经过我的思考和理解,我发现了这几篇论文的几个insights,然后我开始想怎么能够扩展一下这些insights?这时候,我可能想到,有一些insights稍加修改,就可以用于别的场景了。于是我为了在新的场景里面使用这个改进后的insight,我就编造出了一个有意思的设计和场景。这样一来,我就有了basic design。之后,我就稍微做一些实验,看看basic design的效果。一般来说,这种稍微改进后的insight都可以使得你的实验效果变得很好。于是乎,我们为了给论文增加一些分量,我们试着找一些新的场景或者需求。总而言之,应用型的idea之所以被我称为是应用型,是因为这种idea是建立在深入思考并且理解了别人论文的insight以后,把别人的insight加以扩展,并且应用到了新的场景下面,解决的是新场景下的一些问题。
一个颠覆性的idea是怎么提出来的呢?
当我们阅读如一些Paper的开山之作的时候,我们需要理解这种方法的每一个步骤,明白每个步骤中的假设条件和insight。比如上面这张图,我们学习的方法有一个输入,中间有三个步骤,最后是一个输出结果。如果我们对于输入的背后含义有一定的理解以后,我们应该可以对这种输入进行一些改进。这样一来,一旦这个方法的输入改变了,接下来的每一个步骤可能都需要重新计算,或者重新设计用以适应新的输入。这样一来,这种idea,一定是颠覆性的。
需要说明一下,不要觉得应用型的idea就发不到顶级会议上,也不要觉得颠覆性的idea就一定可以发到顶会上。一个idea的提出,就像上面这个图片里面的种子萌芽一样。只有我们在后续的研究过程中,不断地在这个idea基础上拓展新的insight,提出新的设计,它才会成长为一个参天大树。以后我会给大家举很多论文的例子来说明这一点。一个idea的档次高低是可以评价的,但是由提出这个idea,到最终形成论文,这个过程中有更多的因素会左右论文的档次。其实,一个真正决定论文发表的档次的因素,是如何将自己的论文找到合适的定位!
我还得说明一下,千万不要误以为,应用型的idea就是所谓的incremental work。什么叫incremental work?稍微调一调代码,效果变好了一些。然后把公式定理等等换一个说法重新写一遍。顶多增加一些小的约束条件之类的。这种工作,并不是通过改进insight来做到的,而是通过一些小技巧,也就是人们口中常说的tricks来达到的。这样的研究,往往并不会给大家带来新的insight。而,真正区别一个idea,一篇论文,或者一个研究,到底是不是incremental work的标准就是这一样工作有没有给读者带来新的信息,有没有带来新的insight。如果没有,哪怕这个工作看起来再怎么复杂,再怎么量大,也还是一个incremental work。
科研的道路里面没有确定的答案。把这个再扩展一下,任何与创新有关的行为,一定都存在风险!我们在做的一切事情,也都是为了减小风险。但是风险不可能降低到0。想要降低风险我们应该怎么做?我认为只有不断提高自己的逻辑思维,不断思考。一个人的逻辑思维能力只要强大了,无论是科研还是做别的任何与创新有关的事情,都会很成功。
一篇论文的档次是靠什么判断的?
任何一个研究方向都是从一篇或者几篇论文发展起来的。如果我们把这个研究方向的论文按照引用的顺序列出来的话,我们可以得到上面这张图。比如论文A是这个方向的开山之作,之后由A又展开成了三个新的论文,再往后这些论文就会演变成新的,而每个小的科研方向也会有越来越多的分支。
如果我们把这些文章的场景都拿出来对比一下,我们就可以发现,在这张图中高层的论文,其研究的场景往往是更加普适的。换句话说,这些论文提出来的方法可以应用在很多场景,只是其普适性不能保证在所有的场景下,都取得好的效果。于是乎,从高层的论文逐渐向下产生了一些新的论文。这些新的论文所在层级稍微低一些,其场景会更加细化。其效果在特定的场景下一定是优于上一层的论文的。
一般来说,我们发表的论文,如果所处的层级比较高,那么我们的创新和贡献也会更大,相应的我们的论文的档次也会更高。那么,如果我们现在已经写好了一篇文章的初稿,为了提升我们论文的档次,我们应该怎么做呢?答案就是对论文重新定位。
重新定位,顾名思义,我们现在已经有了对我们的论文的一个定位。比如说,我们现在的论文是从论文D那里衍生出来的。我们阅读了论文D,然后我们通过改进论文D,然后我们得到了我们现在的论文,我给叫E吧。那么我们的论文E应该是D的一个下一层的节点。于是乎,我们认为,我们的论文E应该是档次比D要低一些。
现在我们对E做重新定位,我们期盼的目标是,我们可以把E在整棵树中的层级提高一些。比如说,我们的论文E经过重新定位以后,其位置和论文D变成了一个层级。这样一来,我们就可以把我们的论文E投稿到论文D所在的会议或者期刊了。
凭什么能够把E的层级提升到和D一个层级呢 ?想知道这个,我们就需要了解一下论文D到底是怎么一回事!在这里提醒一下大家,论文D是论文C的改进,论文C是论文B的改进,论文B是论文A的改进。如下图所示:
如果E是在D的基础上增加了两个步骤而已。这时候E会变得更加复杂,而其能解决的场景也变窄了。即使效果在E的场景里有所提高,其档次也不会很高。
但是如果原来E不只是简单地在D的基础上增加了step 10,并且对D本身对C的改进的step 8也进行了改进。这样一来,E所对应的场景就不再是论文D中场景的细化了,而是跟D并列的关系。那么文论E的档次,现在被我们提高到了和D一样的级别啦!
给一篇文章重新定位,其实是对一篇文章重新思考,重新认识的一个过程。我们需要对自己的论文里面的设计有深入的思考。同时,我们也需要对我们的研究的相关工作有一个更加清晰的了解才可以。所以,在这里,我还要再次强调一下看论文的时候要深入思考它的insight,这样才可能把一篇论文中的所有隐含的步骤都补齐。这样才会对于我们的论文有一个更加高级的定位!
请大家认真思考自己的研究,认真对待自己之前读过的论文,多去思考论文背后深层的insight。我们需要在阅读别人的论文,学习别人的方法的这个过程中,从作者的写作逻辑中还原出作者做科研的逻辑!这样我们才有机会把别人的论文中的的所有步骤完全找到,进而对我们的论文做出一个正确的,合理的定位!
如何快速掌握一个新的科研方向?
对于一个新的科研方向,无论是新手还是老手,都需要阅读论文来掌握这个方向。这时候,一个典型的错误就是阅读综述性的文章!因为综述性的文章一般都写的不太好,这是大实话!接下来我先告诉大家一个正确的思路,然后再给大家分析一下,为什么阅读综述性文章不是一个正确的思路。当然了,如果你就是看看一个领域的热闹,那么你可以去阅读综述性的文章。但是,如果你真的算在这个领域有所创新,那么你最好不要从综述入手。
我们在任何一个科研方向上所看到的论文,经过整理都应该符合这种树状的结构。我们现在希望能够掌握一个新的科研方向,无论我们是新手还是老手,我们需要做的就是尽快把这一刻论文树给整理出来!但是问题是,如何快的整理出这一颗论文树?
我们现在仔细的看一下这张图。首先呢当我们接触到一个新的科研方向的时候,我们一定是从这个科研方向的最近的发表的论文入手。我们会找到2020年或2021年的这个发表的顶级的论文来阅读。
其实这个时候呢,我们看见的论文因为他是最近发表了,所以说它应该在这个整个的树状结构的最底层。然后这些论文由于他们是最近发表的,所以呢这些论文的引用量一般都会非常的低。毕竟他们刚刚发表不久嘛。由于绝大多数文章都不是开山之作,这些文章基本都是在引用前人的工作的基础上,然后做了一些自己的创新,提出了自己的一些方法。
这时候我们在接触一个新的方向的时候,比如说,我们现在找到了一篇发表在2021年的论文D。然后我们开始阅读D。经过我们对于论文D的反复思考,我们发现论文D是论文C的改进,论文C是论文B的改进,论文B是论文A的改进。而论文A是这个方向的开山之作。
现在,我们刚刚读完论文D,我们已经明白了这颗论文树有一条分支D->C->B->A。可是这个时候,很多同学们会面临一个选择,那就是,对于如茫茫大海一般的论文树,我是沿着D->C->B->A这个分支去阅读,还是我先把D这一层的论文(2021年发表的)都读一遍呢?到底这两个选择,哪一个更让我们更快速地把论文树给整理出来呢?用计算机的术语讲,我们应该是按照深度优先搜索去阅读论文(D->C->B->A),还是广度优先?
我的建议是深度优先!
现在我给大家讲一讲,为什么按照深度优先的方式阅读论文可以迅速整理出论文树,从而掌握一个科研方向的发展?
其实很多同学跟我抱怨,我在阅读论文的时候,insight理解总是太浅显。这是因为我们阅读了论文D以后我们发现,很难找到论文D的Insight。
在论文D的作者做科研的时候,他是知道上面的步骤这张图的。然而,为了把他的设计表达清楚,他可能运用我之前讲过的写作技巧和论文定位的技巧来提升论文的档次。
这样一来,虽然论文D本身是用了论文C,B和A的insight和方法,但是在论文D里面,可能你看不太出来。你会误以为论文的D方法里面大部分都是原创的。其实不然。那我们在阅读D的时候,一定要注意D是和谁对比的,一般来说对比实验的论文就是C或者B,或者A。或者大家要注意参考文献,看看D到底引用了哪些和D的背景相似的论文。这样大家就有机会理解D的由来了。
我们在回到我们刚才的问题,为什么按照D->C->B->A,这种深度优先的方式去阅读论文就会让我们快速掌握整颗论文树呢?原因我刚刚其实已经说了,那就是因为写作技巧和论文定位!
我的意思是,别小看了D->C->B->A这条线。你真的天真的以为,其他的分支就真的比D->C->B->A这条线多出来多少新的创新么?我可以告诉你,别看这个论文树很大,很茂密,其实大量的论文都是没啥新的信息。大量的论文,即使是顶级论文,由于作者的写作技巧加上高超的论文定位技巧,他可以把一个创新型很少的工作,给弄成一个看似很厉害的工作。这样一来,大量的论文其实是冗余的。也就是说,我们只要掌握了D->C->B->A这一条线,其他的分叉,基本也都是D->C->B->A的变种。而且这些变种的创新程度也不是很高。
从我们掌握这个科研领域的insight的角度来说,阅读一百篇创新型很小的论文,意义不是很大。因此,我建议按照D->C->B->A这种深度优先去阅读。这样一来,你不需要把整棵树都看完,你只需要深入思考D->C->B->A这四篇文章即可!!!!!!
如果你真的把D->C->B->A这四篇论文都吃透了,insight都理解了,剩下的其他分叉上面的论文对你来说,每一篇顶多花1个小时就能理解了。这样一来,你可以做到快速掌握其他分支的论文了,你就可以快速跟进最新的研究工作了!
那我现在来说说,为啥综述性的文章对于掌握一个科研方向意义不大?就是因为我们掌握一个科研方向,主要是掌握这个科研方向最新的insight。而综述性文章往往不能把insight给大家都呈现出来。而且综述论文作者有自己的一套思路,他的思路不一定适合你,也不一定适合你们的实验室。因此,你读了综述以后,你还是得按照我刚才说的D->C->B->A这种深度优先去深入理解一条分支才可以。与其这样,大家千万别在综述文章上花太多时间。大致看一看综述文章,了解一下基本情况就可以了。
如何区别挑别人论文中的毛病和发现别人论文方法的不足?
咱们想象一下下面这个场景:
我读了论文D,我发现D好像有个缺陷,然后我就找到了D的一个毛病。这时候我得到了一个什么信息呢?我知道了,D有XXX这个问题。那么这时候,我们有idea了么?远远没有。因为,我们从别人的毛病入手的时候,我们相当于找到了一个问题,但是我们没有解决方法!!找到了别人的毛病,但是你基本上不要可能找到解决方案,因为这种毛病要么没意义,要么根本无法解决!
那好,现在咱们换一个思路,从掌握别人的insight入手,然后我们看看会发生什么?
我们读了几篇文章,掌握了几个insights。然后这时候,我们想的第一个不是这几个论文有什么新的问题,而是怎么利用这些insights。当我们想到了一种很巧妙利用这些insights的方法之后,我们就有了一个新的方法!这时候,我们会给这个方法去找一个背景和问题!大家明白了吧,从insight入手,我们是现有解决方案,然后我们去为这个方案找一个有趣的背景和问题。然后在我们整理相关论文的时候,我们再去挑那些论文的毛病和问题。这时候,我们有了我们研究的问题和解决方案了,我们想怎么挑别人的毛病就怎么挑。反正我们已经有了一个idea,再怎么挑别人的毛病不会影响到我们自己的idea了。
从insight入手,我们先有了解决方案,然后再去找一个合适的背景和故事。先有答案,后找问题,这个可是比先找问题后找答案,容易的多的多的多的多!
论文的实验部分应该怎么写?读者需要我们给他们展示什么试验结果?
我们应该怎么向读者介绍实验结果?总地来说,我们给读者展示实验结果的时候,我们的原则是:我们只给读者看他们想要知道实验,我们不需要把我们做科研的过程中的每一个步骤的实验都给读者展示一遍。
我们来看看,读者或者审稿人一般会想看到哪些实验结果呢?
1. 你的方法的整体性能,以及和别人方法的对比。
一般来说,我们的论文都会提到一些前人的工作。同时我们的论文也会解决一个研究问题。那么,我们需要给读者展示的第一个实验结果,就应该是我们的方法的效果到底怎么样?别人对比一下,我们取得了多大的提升?
请大家注意,这个实验结果,是我们在一个公认的理想条件下做的测试。这是什么意思呢?这个测试条件不一定特别符合实际,但是大家都在这种理想环境下做的测试,我们就可以跟随大家以前的做法来做同样的测试。
2. 你的方法中一些关键的参数,对于你的方法整体性能的影响。
3. 你的方法在不同的但常见的场景下的性能。
我们提出的方法,一般都可以适用于很多场景。在一些机器学习的文章中,提出的方法要在不同的数据集上面测试,这也是在测试文中方法在不同场景中的表现。
当然了,这些场景的选择是有技巧的。一般来说,我们在Introduction中宣称,我们的方法可以解决xx场景下的xx问题。这时候我们一定要在实验里面进行测试。除了我们宣称的场景,我们还可以参考一下前人的工作都是在哪些场景下做的测试。为了展示我们的方法的普适性,我们可以在别人做过的场景中再测试测我们的方法。归根结底,场景的选择一定要符合实际,而且具有一定的普适性,千万别拿一些非常奇怪的场景来凑篇幅。
4. 采用了你的方法以后,系统中的一些其他性能受到什么样的影响?
论文推荐写作顺序
一般来说,我们在写作的时候,先写design部分。因为这部分最难写,而且需要反复修改写作逻辑。当我们design的逻辑确定了以后,我们去补充试验结果。因为design部分不同的写作逻辑,可能会影响文章的定位,以及需要测试的实验。当我们有了design和实验结果以后,我们再去写Introduction。因为Introduction是整个文章的概括。没有一个清晰的定位和design,以及实验结果,Introduction部分的8条信息也就没法填满了。
一个正确的科研过程
想要理解我们为什么会花了几个月甚至几年的时间做一个项目却最终失败,我们先来看一个正确的做科研的过程吧。
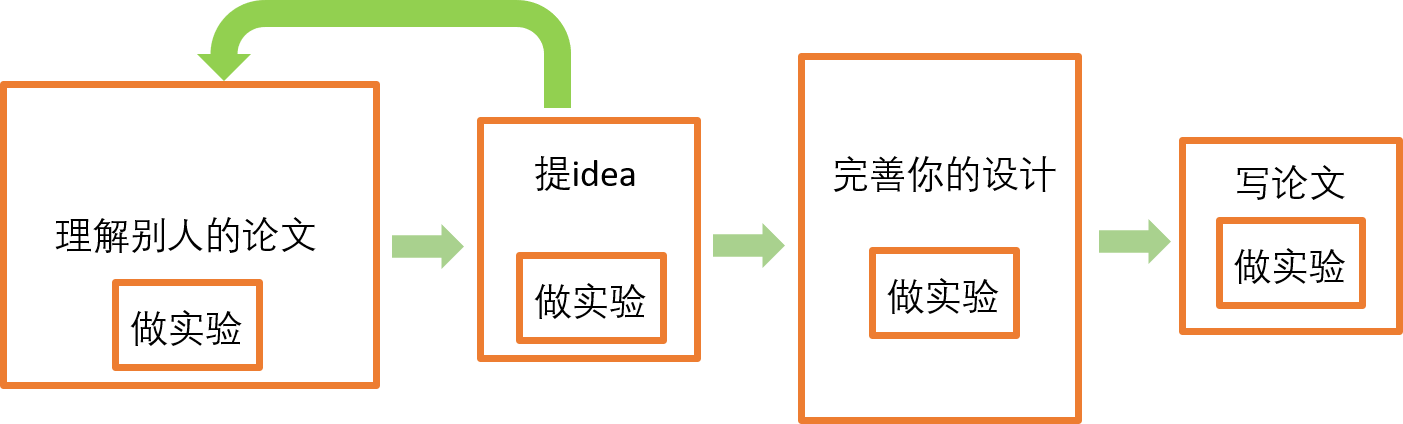
在这张图中,我把每个阶段用一个不同大小的方框来表示。大的方框表示这个阶段需要花时间长一些,小的方框表示这个阶段花的时间少一些。接下来我来详细地给大家讲一下这张图。
01理解别人的论文
我们做科研项目的第一个阶段一定是阅读别人的论文,然后理解别人的论文。我们阅读论文的目的是理解别人的方法。这个过程需要我们对于别人方法中的insight有深入的思考。
虽然我们知道一篇论文里面和核心的insight已经很模糊了。一篇论文由于写作技巧和重定位,我们作为读者已经很难还原出来读者当时怎么思考的了。这就需要我们一点点顺藤摸瓜,把这个小方向的几篇论文都读懂。把这个论文的树形结构给弄清楚。这样我们才算是刚刚看懂几篇文章。接下来我们需要深入理解这些论文中的insights。为了深入的理解insights,我们应该动手做一些实验来验证别人论文中的insights。请大家注意,我说的不是复现别人的实验结果。复现别人的结果应该是非常困难的,毕竟很多论文的结果都涉嫌造假。但是insights不太敢造假,而且论文能发表出来,说明审稿人已经认可论文中发现的insights了。我们应该做的是,通过一些实验看看那些insights到底长什么样子。到底他们的物理含义是什么,到底是怎么产生这些现象的,这背后有什么假设条件。这个阶段我们做的实验主要是一些验证性的实验,其目的是验证别人论文中的insights。我们希望通过这些验证性的实验来理解别人的方法。
02提出自己的idea
我相信,在做一些实验来理解insights的时候,大部分同学都已经开始思考idea了。在大家动手做实验的时候,经常会发现一些很有趣的现象,这时候大家就离提出自己的idea不远了。
教大家的方法,大家在掌握了几个insights之后,深入思考了它们背后的假设条件和含义以后,应该可以提出一个idea。当然了,为了扩展我们的思路,我们也会做一些探索性的实验,来验证一下我们的一些猜想。
当我们提出一个idea以后,我们需要做的第一件事就是可行性的验证,也就是去验证这个idea背后的假设条件到底成立还是不成立。只要一个idea背后的假设条件是成立的,那么这个idea很大概率是是可行的。也就不会出现做着做着发现idea错了的尴尬情况。这种验证,当然也需要我们做一些实验,或者从理论上进行一些推导。总之,我们需要验证我们的idea。
此外,如果这个idea的档次不是我们期待的,那么我们没必要在这个idea上面浪费时间。我们可以重新思考,然后提出一个新的idea。
03完善你的设计
如果我们提出的idea可行并且达到了我们希望的档次,那么我们就应该去把这个idea一点点展开,如果是一个应用型的idea,那么我们应该去思考怎么增加一些advanced design。如果是一个颠覆性的idea,我们应该慎重地去把这个idea完整地做出来。
04写论文
我们应该把刚才这两个问题先放一放,当我们完善了自己的设计以后,不应该急着去做实验来测试我们提出的方法,而是应该先开始写论文。这是因为,即使我们现在做了一些实验,我们将来也可能因为论文的写作,把现在做的实验结果给砍掉。
我们为了让读者更好地理解我们的论文,我们给读者呈现出来的写作逻辑和我们刚才做科研的逻辑完全不一样。我们很有可能为了论文的写作而重新设计一些实验场景。因此,我们只有在把论文的核心设计部分写完以后,才能够清晰地看到一个项目的全貌。然后我们才能知道,我们到底需要做哪些测试。
05往顶会去投
尽快把自己的研究写成一篇论文。如果工作量很大,大家可以尝试往顶级会议去投稿。无论是否录用,只要你完整地体验过从提出idea到写完一篇论文的整个过程,你都会得到很大的提升!如果你的工作量不足以达到顶会的篇幅要求,那就往低一些级别的会议投稿。
纸上得来终觉浅,绝知此事要躬行!
审稿的真相
会议论文的审稿流程
从2016年开始,几乎每年的infocom我都参与了审稿。这个会议的审稿流程主要是两个步骤:1,审稿人拿到要审的论文,然后开始写审稿意见,并对自己审阅的论文进行排序。2,TPC meeting。这个会议的核心内容是,审稿人要对一些有争议的论文进行讨论,从而决定论文是否录用。
其实,一篇论文是否录用,主要决定在第一步。在TPC meeting的时候,除非这篇论文有大佬撑腰并且说服其他审稿人,否则的话,一个人人都反对的论文,是不太可能被录用的。那么在审稿阶段,发生了哪些事情呢?
每年infocom会分发给一个审稿人8-10篇左右的论文。有时候多一些,有时候少一些。咱们就取个平均值,9篇。假设今年我拿到了9篇投稿的论文。我作为审稿人,我会阅读这9篇论文,然后给这些论文打分(1分-5分)。然后也会给这几篇论文进行排序(1-9)。一篇论文会被3个审稿人审阅。也就是一篇论文会拿到3个审稿意见。每一篇论文最终的得分,是从这三个审稿人所打的分数计算出来的。这个计算的过程考虑到审稿人对于这个领域的熟悉程度,以及每个审稿人打分的严苛程度等因素。
但是不管怎么说,请大家记住,一个审稿人拿到的9篇论文中,将来可能会产生2篇录用的论文(20%的录用率)。也就是说,被我排在前两名的论文,会有很大的机会被录用。而排名在3-9名的论文,估计就没啥机会了。
有的同学可能会说,还有两位审稿人呢?万一我对于这个专业领域的熟悉程度不高,那么即使我给这一篇论文的排名不高,只要其他审稿人喜欢这篇论文,这篇论文是不是也有机会呢?额。。。不太可能。不像一些ACM的顶会,会有五六个,甚至七个审稿人,infocom只给每个论文分配3个审稿人。这也就意味着,对于同一篇论文,每个审稿人给出的分数,都非常关键。
这样一来,这一篇论文在我这里的排名就非常关键了。如果这篇论文,排在我审阅的论文中的前两名,那么基本就稳了。在明白了审稿过程以后,我们来看看审稿的过程中,发生了哪些有趣的事情?
审稿的真相
在审了好多次infocom以后,我基本可以讲,在我每年收到的9篇需要审稿的文章中,都会有2-3篇论文没有满足篇幅要求。前几年,infocom官网要求投稿的论文正文占9页,有时候是10页。无论篇幅是多少,投稿的论文一定要严格符合这一要求才行。
比如说,infocom要求今年投稿的篇幅中,正文占8页。有的同学的论文正文占了7页半。算上参考文献,一共有8页。这样的话,这篇论文,100%被拒。凡是录用的论文,他们投稿的篇幅都是正正好好满足要求的。一行不多,一行也不会少。这是规矩!虽然有的会议写建议最多不超过XX页,但是只要你没有占满XX页,你的论文被录用的概率都会小很多。哪怕在conclusion后面有几行留白,也一定要用vspace给调整到完全正好才行。我见过最夸张的一次是,有一篇投稿的论文只写了7页半,而那年的infocom要求正文是9页。这样的话,这篇论文没有任何机会。
每年,一个审稿人手里,没有达到篇幅要求的论文,大概有2-3篇。有的满足了篇幅的要求,但是论文中的图片被放得非常大。这样的论文明显是在凑篇幅。这种论文我们也算在不满足篇幅的行列中。咱们夸张点说,如果今年我审阅的论文中,有3篇没达到篇幅要求,那么这意味着,真正参与到竞争的论文,就只剩下6篇了。也就是说,如果你的论文只要满足了篇幅要求,你就只会跟其他5篇论文产生竞争关系。进一步讲,你的录用率应该是多少呢 ?我们来算算,2/6 = 33.3%。
大家明白了吧。infocom真正的录用率,应该是33%左右,而不是官方公布的20%,因为有很多事没写完的。那么我们再来看看这6篇满足篇幅要求的论文,这几篇论文虽然都写到了篇幅要求的页数,它们们几个里面,肯定有1个是写作特别差的。这个论文描述的idea一定不符合我之前讲过的8点信息。也就是说,这篇论文,肯定让审稿人看得云里雾里。这样的论文也必定不会被录取。
这样一来,真正有战斗力的论文,不会超过5篇。也就是说,真正的录用率,绝对在2/5=40%左右!而不是官方公布的20%! 我相信大家看到这里就明白了,为什么那些懂infocom的教授们会说“投infocom的论文有50%的机会被录用” 了吧。
标签:insight,句句,论文,idea,一个,干货,葵花宝典,这个,我们 来源: https://www.cnblogs.com/lwp-nicol/p/15110861.html