long类型数字后为何+L,float类型数字后为何+F?
作者:互联网
首先直接回答问题
-
long类型数字后面为什么一定要加L?
基本数据类型int,占用4个字节,取值范围为
-231 ~ 231-1,转换为十进制是-2147483648 ~ 2147483647
基本数据类型long,占用8个字节,取值范围为-263 ~ 263-1,转换为十进制是-9223372036854775808 ~ 9223372036854775807在Java中,整数的默认数据类型是int。当我们将一个整数赋值给任何类型变量时,这个整数默认是int型。
如果这个数字小于int的最大值,可以直接给long赋值,因为int的取值范围小于long型,可以自动转换。
如果这个数字大于int的最大值,此时不能自动转换,我们就需要在数字后面加上L来进行强转,否则会报错。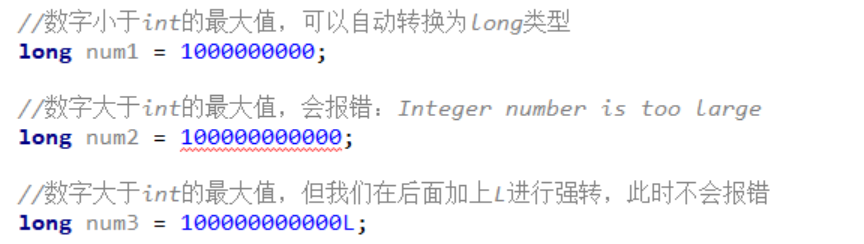
-
float类型数字后面为什么一定要加F?
基本数据类型float,占用4个字节,取值范围为
-3.40E+38 ~ +3.40E+38
基本数据类型double,占用8个字节,取值范围为-1.79E+308 ~ +1.79E+308在Java中,浮点数的默认数据类型是double,当我们将一个浮点数赋值给任何类型变量时,这个浮点数默认是double型。
如果我们将整数赋值给float,因为float的取值范围大于int,会自动进行转换。
如果我们将浮点数赋值给float,因为float的取值范围小于double,此时需要在后面加上F进行强转换。
思考
看完上述回答,你可能会有如下疑问:
-
按照默认类型,比如声明 long a=100000, 那么a还是int 类型吗?
这里的a为变量类型,不同于数据类型。
你声明的是什么类型,编译器就会给你开辟个什么类型的空间。
double a=2;
虽说2是整数,但编译器开辟的空间是8个字节,也就double的大小。8个字节储存一个4个字节的整数,其它地方自然用0填充了,你可以理解为2.00实际还是2。 -
为什么给float类型变量赋值需要加F,而给byte、short赋值的时候却不需要呢?
-
自动类型转换:容量小的类型自动转换为容量大的数据类型。
数据类型按容量大小排序为:[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-haFp7nDb-1627133951222)(https://i.loli.net/2021/07/21/wX3jLoc7DFE6hgl.png)] 特别的:当byte、short、char三者在计算时首先都转换为int类型(包含例如byte和byte之间进行计算)。
-
强制类型转换:将容量大的数据类型转换为容量小的数据类型。(备注:可能造成精度降低或溢出)
JVM规范中,并没有说float,int,byte等占多少个字节,而是真正的有效位是多少。比如byte的有效位是1个字节,也就是-128到127。使用Java编程的时候,就只能用byte表示-128到127之间的数,而真正JVM实现,一般byte还是占用和int一样大小:4个字节。
也就说在JVM看来,short,byte,int都是同一个东西。
这也就解释了为什么byte,short使用int字面量赋值的时候会不用强制转型。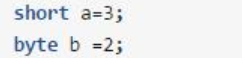
因为编译器在编译的只需要根据字面值3,字面值2来确定是否超过有效值即可,并不用做深入的检查,因为他们在JVM存在的类型也是一样的。

同时在通过JVM在操作byte,short,int都是用的相同的指令:iconst,bipush等也能证明。
然而double和float在JVM中存储是不一样的(可参考下一条理解)。

因此在使用double给float赋值的时候,会报错的。
-
-
在答案中,10.2并没有超出单精度浮点数表示的范围,为什么还会报错?
这是由于两种浮点数类型在存储时,所采用的标准不同所导致的。同样一个浮点数,用单精度表示和用双精度表示,表示结果并不相同,存在精度上的差异。而双精度向单精度强制转换时,会造成精度损失。
Java 语言支持两种基本的浮点类型: float 和 double 。java 的浮点类型都依据 IEEE 754 标准。IEEE 754 定义了32 位和 64 位双精度两种浮点二进制小数标准。(可自行百度了解)
参考文章:
https://blog.csdn.net/CGB1804Great/article/details/103545545
https://blog.csdn.net/xuwen1997/article/details/108650470
标签:数字,int,double,float,数据类型,为何,byte,字节 来源: https://blog.csdn.net/weixin_45605541/article/details/119064385