什么是数据湖(转载)
作者:互联网
什么是数据湖
从前,数据少的时候,人们拿脑子记就可以了,大不了采用结绳记事:


后来,为了更有效率的记事和工作,数据库出现了。数据库核心是满足快速的增删改查,应对联机事务。


比如你用银卡消费了,后台数据库就要快速记下这笔交易,更新你的卡余额。
日子久了,人们发现,库里的数据越来越多了,不光要支持联机业务,还有分析的价值。
但是,传统数据库要满足频繁、快速的读写需求,并不适合这种以读取大量数据为特征的分析业务。
于是,人们在现有的数据库基础上,对数据进行加工。这个加工过程,被称为:



经过这三步,数据仓库就建好了。
这个“仓库”,主要是为了数据分析用途,比如用于BI、出报表、做经营分析等等。
简要总结下
数据库用于联机事务,通常为小数据量高频读写。


数据库等原始数据,经过ETL加工以后,就被装进了数据仓库。
数据仓库主要用于联机分析业务,通常为大数据量读取。


虽然应用场景不一样,但他们都是结构化数据。
在相当长的一段时间内,他们联合起来,共同满足企业的实时“交易”型业务和联机“分析性”的业务。
随着时代的发展,数据的类型越来越多,人们对数据的需求也越来越复杂。


企业越来越看重这些“大数据”的价值,希望把他们存好、用好。
这些数据,五花八门,又多又杂,怎么存呢?
索性挖个大坑吧!
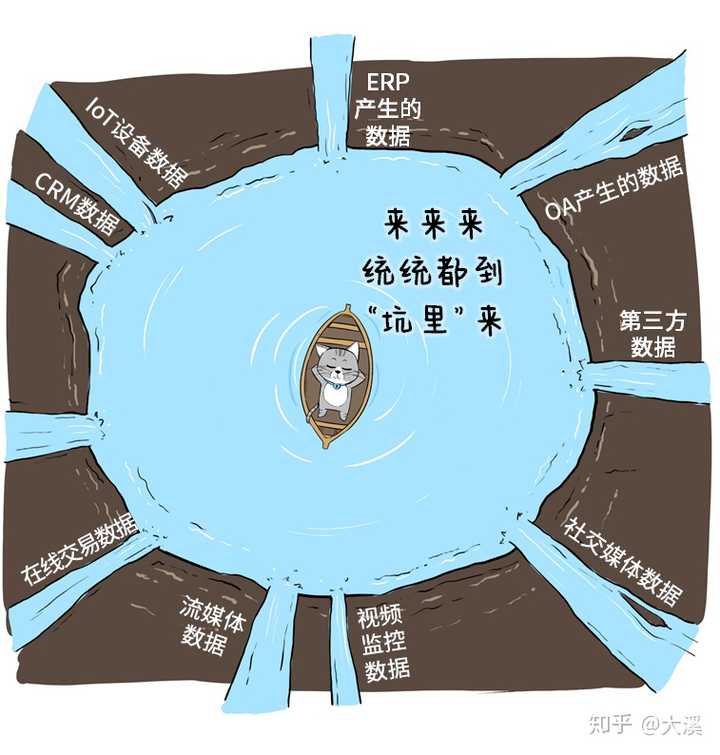

这就是数据湖的原型。
说白了,数据湖就像一个“大水坑”,是一种把各类异构数据进行集中存储的架构。


因为,数据要能存,而不是一江春水向东流。


因为,要足够大,大数据太大,一池存不下。


因为,企业的数据要有边界,可以流通和交换,但更注重隐私和安全,“海到无边天作岸”,那可不行。
so,数据湖,Data Lake,刚刚好。
可是,概念虽好,把这个“水坑”用好却不容易。
1、这个“坑”挖在哪儿?怎么挖?“挖掘机”贵不贵?2、这“坑”挖好后,这么把各种水都引过来灌到坑里?
3、灌了半坑水,如何才能把他们利用起来?
这些,就是当下数据湖面临的挑战:如何建湖?如何做数据ETL?如何使用数据。
拿AWS来举例,他是这样帮我们“挖坑”的。
首先,数据湖是一种存储架构,本质上讲是存储,所以,AWS就用了自己最经典的S3存储,来当数据湖的地基。

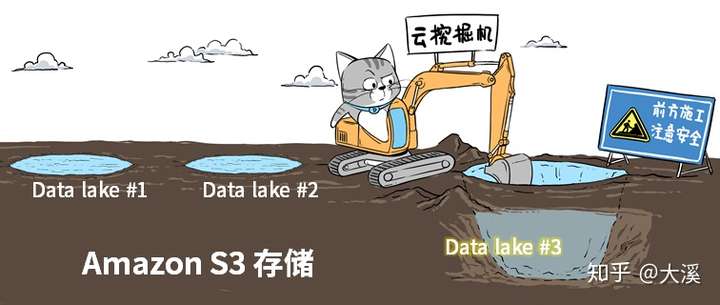
企业基于AWS云服务,可以快速挖出一个适合自己的“湖”,而且这个“湖”根据需求,可大可小,按“注水量”付费。
接下来,就是如何把企业的各种异构数据注入到湖里,也就是我们前面说过的“ETL”,看起来很麻烦。
有个非常酷的产品叫AWS Glue,这简直就是个自动化数据分拣机,可以快速完成复杂的ETL过程,处理完的数据,既可以注入数据湖,也可以给数仓或数据库用。
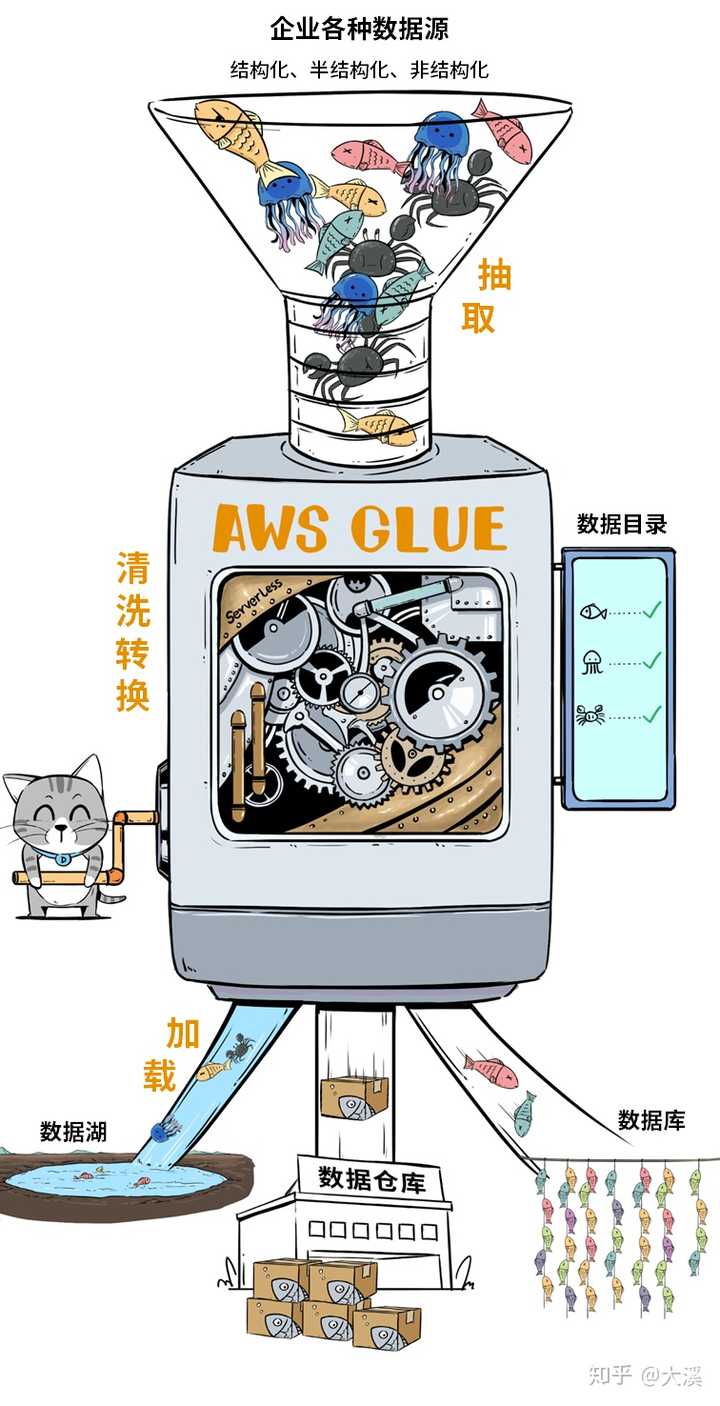
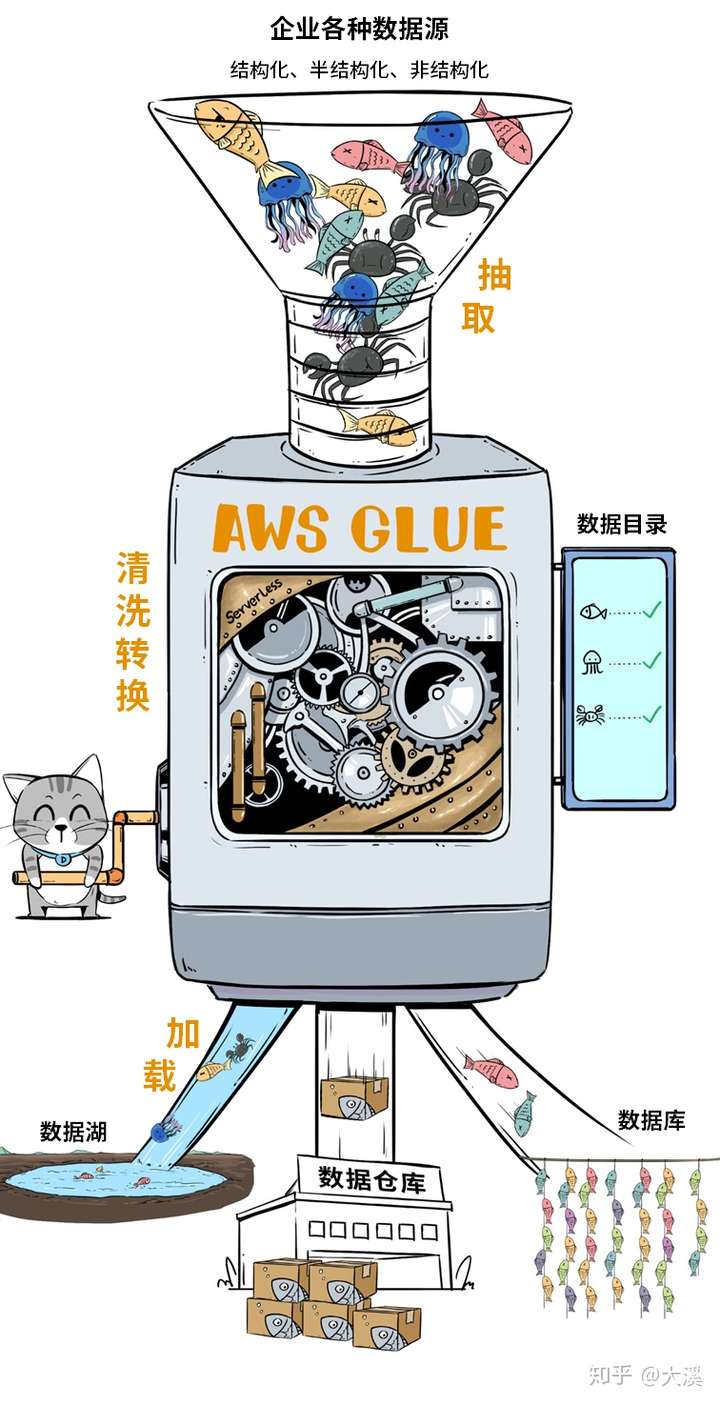
Glue神器有两个特色:
①它能自动化的生成元数据目录,大大简化数据管理工作量;
②它是无服务器架构的,呼之则来,挥之则来,一次还可以整好多台,开足马力处理数据。
目前这个神器已经在AWS中国(宁夏)区域和(北京)区域正式上线了。
同时,还有一个工具,也同步上线,叫做Amazon Athena。


这个工具,让我们可以用标准的SQL,对存储在S3里的数据进行查询,不管是结构化的还是非结构化的。这就意味着,大家可以用最熟悉的SQL,轻松在S3硬地里“吃土”,当然也能在湖里“划水”,轻松进行数据洞察。
数据入湖之后,并不是简单摸鱼划水就完事了,光有Athena做查询还很不够。AWS提供了一系列的工具,让企业能进行“湖底大开发”,满足各种各样的业务需求。
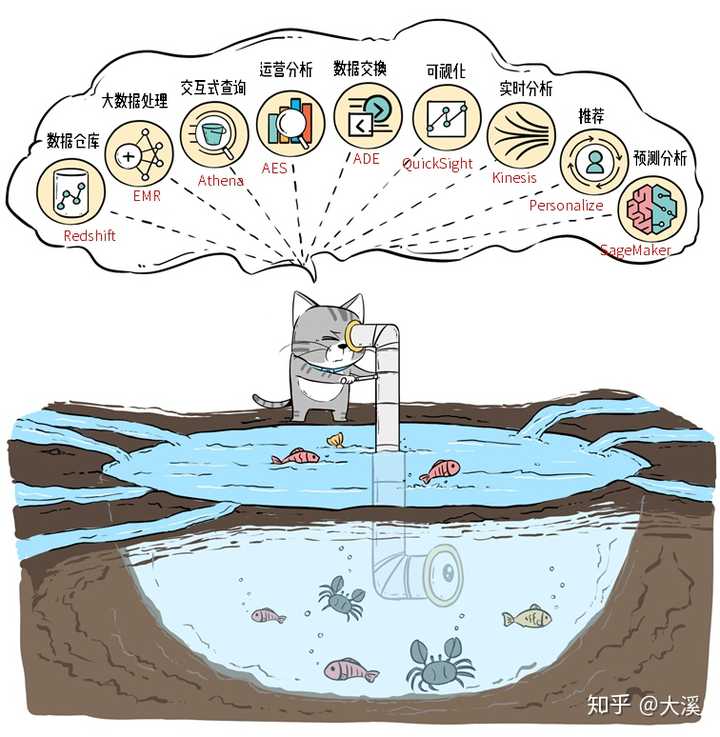
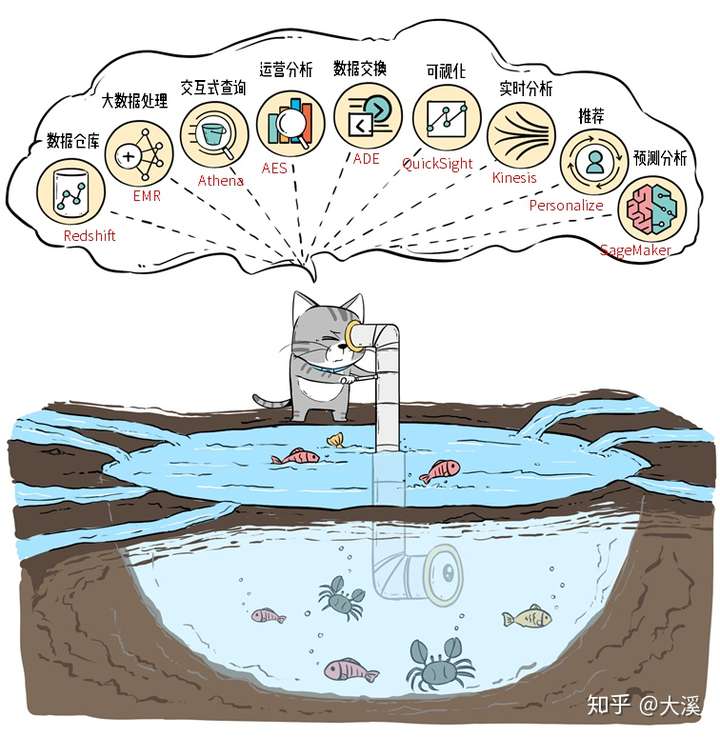
数据湖发展到现在,已经成为企业数据体系的基础:数据库、数仓、大数据处理、机器学习等各种数据服务,都可以“一湖尽收”。
标签:存储,联机,什么,AWS,转载,数据,数据库,ETL 来源: https://www.cnblogs.com/coco2015/p/14975520.html