你必须要知道backbone模块成员之一 :ResNet(超详细代码)
作者:互联网
本文主要贡献代码模块(文末),在本文中对resnet进行了改写,是一份原始版本模块,里面集成了权重文件pth的载入模块(如函数:init_weights(self, pretrained=None)),layers的冻结模块(如函数:_freeze_stages(self)),更是将其改写成可读性高的代码,若你需要执行该模块,可直接将其代码模块粘贴成.py文件即可。而理论模块,并非本文重点,因此借鉴博客:https://zhuanlan.zhihu.com/p/42706477 ,我将不在说明:
注:本人也意在改写更多backbones模块,后续将会放入该github中,可供代码下载:https://github.com/tangjunjun966/backbones
ResNet的作者何凯明也因此摘得CVPR2016最佳论文奖,当然何博士的成就远不止于此,感兴趣的可以去搜一下他后来的辉煌战绩。那么ResNet为什么会有如此优异的表现呢?其实ResNet是解决了深度CNN模型难训练的问题,从图2中可以看到14年的VGG才19层,而15年的ResNet多达152层,这在网络深度完全不是一个量级上,所以如果是第一眼看这个图的话,肯定会觉得ResNet是靠深度取胜。事实当然是这样,但是ResNet还有架构上的trick,这才使得网络的深度发挥出作用,这个trick就是残差学习(Residual learning)。下面详细讲述ResNet的理论及实现。
深度网络的退化问题
从经验来看,网络的深度对模型的性能至关重要,当增加网络层数后,网络可以进行更加复杂的特征模式的提取,所以当模型更深时理论上可以取得更好的结果,从图2中也可以看出网络越深而效果越好的一个实践证据。但是更深的网络其性能一定会更好吗?实验发现深度网络出现了退化问题(Degradation problem):网络深度增加时,网络准确度出现饱和,甚至出现下降。这个现象可以在图3中直观看出来:56层的网络比20层网络效果还要差。这不会是过拟合问题,因为56层网络的训练误差同样高。我们知道深层网络存在着梯度消失或者爆炸的问题,这使得深度学习模型很难训练。但是现在已经存在一些技术手段如BatchNorm来缓解这个问题。因此,出现深度网络的退化问题是非常令人诧异的。
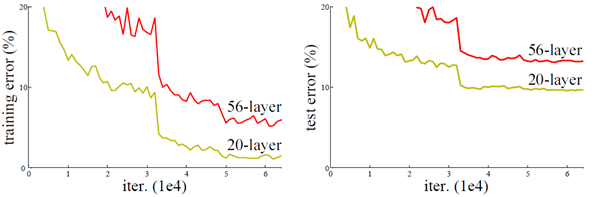 图3 20层与56层网络在CIFAR-10上的误差
图3 20层与56层网络在CIFAR-10上的误差
残差学习
深度网络的退化问题至少说明深度网络不容易训练。但是我们考虑这样一个事实:现在你有一个浅层网络,你想通过向上堆积新层来建立深层网络,一个极端情况是这些增加的层什么也不学习,仅仅复制浅层网络的特征,即这样新层是恒等映射(Identity mapping)。在这种情况下,深层网络应该至少和浅层网络性能一样,也不应该出现退化现象。好吧,你不得不承认肯定是目前的训练方法有问题,才使得深层网络很难去找到一个好的参数。
这个有趣的假设让何博士灵感爆发,他提出了残差学习来解决退化问题。对于一个堆积层结构(几层堆积而成)当输入为 时其学习到的特征记为
,现在我们希望其可以学习到残差
,这样其实原始的学习特征是
。之所以这样是因为残差学习相比原始特征直接学习更容易。当残差为0时,此时堆积层仅仅做了恒等映射,至少网络性能不会下降,实际上残差不会为0,这也会使得堆积层在输入特征基础上学习到新的特征,从而拥有更好的性能。残差学习的结构如图4所示。这有点类似与电路中的“短路”,所以是一种短路连接(shortcut connection)。
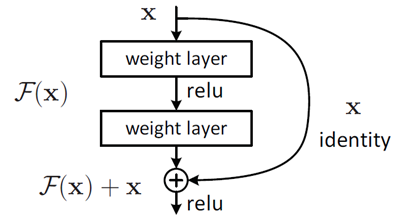 图4 残差学习单元
图4 残差学习单元
为什么残差学习相对更容易,从直观上看残差学习需要学习的内容少,因为残差一般会比较小,学习难度小点。不过我们可以从数学的角度来分析这个问题,首先残差单元可以表示为:
其中 和
分别表示的是第
个残差单元的输入和输出,注意每个残差单元一般包含多层结构。
是残差函数,表示学习到的残差,而
表示恒等映射,
是ReLU激活函数。基于上式,我们求得从浅层
到深层
的学习特征为:
利用链式规则,可以求得反向过程的梯度:
式子的第一个因子 表示的损失函数到达
的梯度,小括号中的1表明短路机制可以无损地传播梯度,而另外一项残差梯度则需要经过带有weights的层,梯度不是直接传递过来的。残差梯度不会那么巧全为-1,而且就算其比较小,有1的存在也不会导致梯度消失。所以残差学习会更容易。要注意上面的推导并不是严格的证明。
ResNet的网络结构
ResNet网络是参考了VGG19网络,在其基础上进行了修改,并通过短路机制加入了残差单元,如图5所示。变化主要体现在ResNet直接使用stride=2的卷积做下采样,并且用global average pool层替换了全连接层。ResNet的一个重要设计原则是:当feature map大小降低一半时,feature map的数量增加一倍,这保持了网络层的复杂度。从图5中可以看到,ResNet相比普通网络每两层间增加了短路机制,这就形成了残差学习,其中虚线表示feature map数量发生了改变。图5展示的34-layer的ResNet,还可以构建更深的网络如表1所示。从表中可以看到,对于18-layer和34-layer的ResNet,其进行的两层间的残差学习,当网络更深时,其进行的是三层间的残差学习,三层卷积核分别是1x1,3x3和1x1,一个值得注意的是隐含层的feature map数量是比较小的,并且是输出feature map数量的1/4。
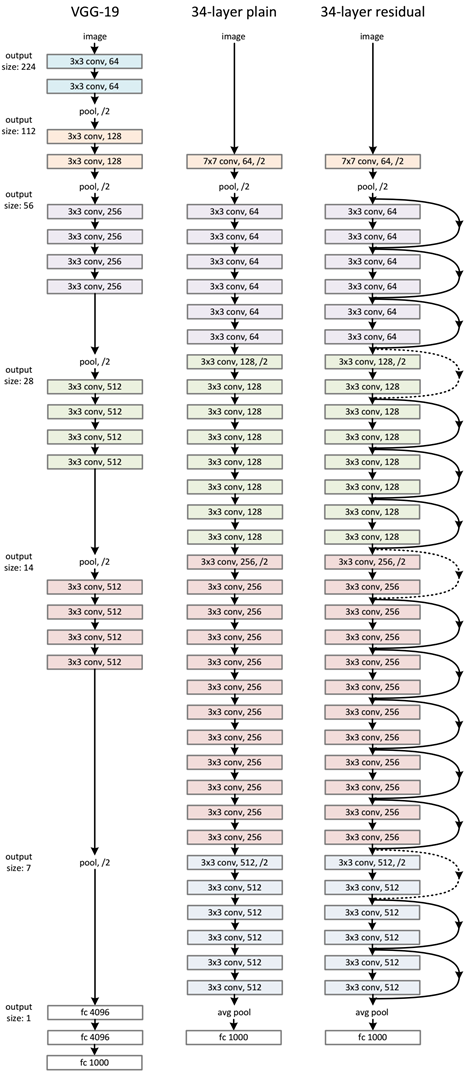 图5 ResNet网络结构图
图5 ResNet网络结构图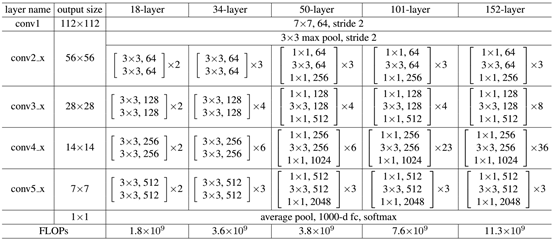 表1 不同深度的ResNet
表1 不同深度的ResNet
下面我们再分析一下残差单元,ResNet使用两种残差单元,如图6所示。左图对应的是浅层网络,而右图对应的是深层网络。对于短路连接,当输入和输出维度一致时,可以直接将输入加到输出上。但是当维度不一致时(对应的是维度增加一倍),这就不能直接相加。有两种策略:(1)采用zero-padding增加维度,此时一般要先做一个downsamp,可以采用strde=2的pooling,这样不会增加参数;(2)采用新的映射(projection shortcut),一般采用1x1的卷积,这样会增加参数,也会增加计算量。短路连接除了直接使用恒等映射,当然都可以采用projection shortcut。
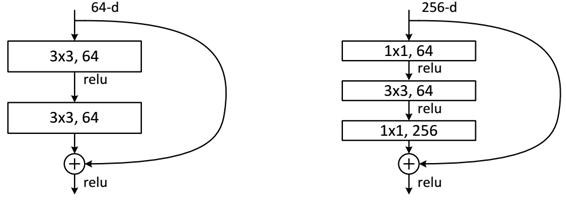 图6 不同的残差单元
图6 不同的残差单元
作者对比18-layer和34-layer的网络效果,如图7所示。可以看到普通的网络出现退化现象,但是ResNet很好的解决了退化问题。
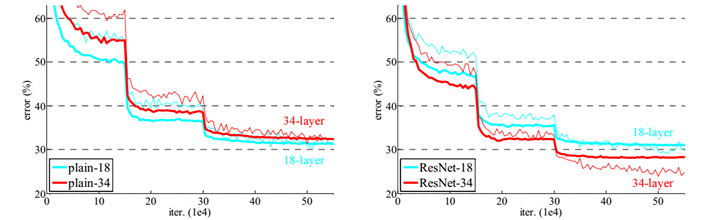 图7 18-layer和34-layer的网络效果
图7 18-layer和34-layer的网络效果
最后展示一下ResNet网络与其他网络在ImageNet上的对比结果,如表2所示。可以看到ResNet-152其误差降到了4.49%,当采用集成模型后,误差可以降到3.57%。
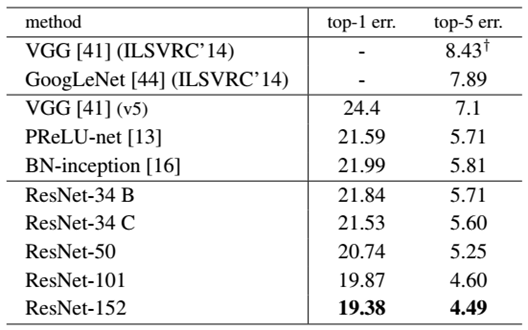 表2 ResNet与其他网络的对比结果
表2 ResNet与其他网络的对比结果
说一点关于残差单元题外话,上面我们说到了短路连接的几种处理方式,其实作者在文献[2]中又对不同的残差单元做了细致的分析与实验,这里我们直接抛出最优的残差结构,如图8所示。改进前后一个明显的变化是采用pre-activation,BN和ReLU都提前了。而且作者推荐短路连接采用恒等变换,这样保证短路连接不会有阻碍。感兴趣的可以去读读这篇文章。
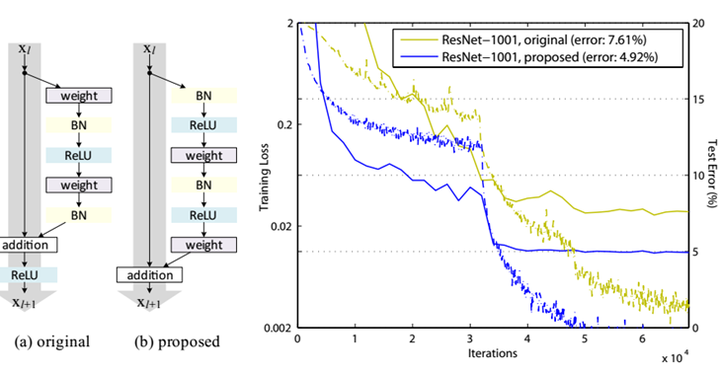
代码如下:
"""
@author: tangjun
@contact: 511026664@qq.com
@time: 2020/12/7 22:48
@desc: resnet 模块
"""
import torch.nn as nn
import torch
from collections import OrderedDict
def Conv(in_planes, out_planes, **kwargs):
"3x3 convolution with padding"
padding = kwargs.get('padding', 1)
bias = kwargs.get('bias', False)
stride = kwargs.get('stride', 1)
kernel_size = kwargs.get('kernel_size', 3)
out = nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride, padding=padding, bias=bias)
return out
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = Conv(inplanes, planes, stride=stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = Conv(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * 4)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class Resnet(nn.Module):
arch_settings = {
18: (BasicBlock, (2, 2, 2, 2)),
34: (BasicBlock, (3, 4, 6, 3)),
50: (Bottleneck, (3, 4, 6, 3)),
101: (Bottleneck, (3, 4, 23, 3)),
152: (Bottleneck, (3, 8, 36, 3))
}
def __init__(self, depth,
in_channels=None,
pretrained=None,
frozen_stages=-1
# num_classes=None
):
self.inplanes = 64
super(Resnet, self).__init__()
self.inchannels = in_channels if in_channels is not None else 3 # 输入通道
# self.num_classes=num_classes
self.block, layers = self.arch_settings[depth]
self.frozen_stages=frozen_stages
self.conv1 = nn.Conv2d(self.inchannels, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(self.block, 64, layers[0], stride=1)
self.layer2 = self._make_layer(self.block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(self.block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(self.block, 512, layers[3], stride=2)
# self.avgpool = nn.AvgPool2d(7)
# self.fc = nn.Linear(512 * self.block.expansion, self.num_classes)
self._freeze_stages() # 冻结函数
def _freeze_stages(self):
if self.frozen_stages >= 0:
self.norm1.eval()
for m in [self.conv1, self.norm1]:
for param in m.parameters():
param.requires_grad = False
for i in range(1, self.frozen_stages + 1):
m = getattr(self, 'layer{}'.format(i))
m.eval()
for param in m.parameters():
param.requires_grad = False
def init_weights(self, pretrained=None):
if isinstance(pretrained, str):
self.load_checkpoint(pretrained)
elif pretrained is None:
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, a=0, mode='fan_out', nonlinearity='relu')
if hasattr(m, 'bias') and m.bias is not None: # m包含该属性且m.bias非None # hasattr(对象,属性)表示对象是否包含该属性
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def load_checkpoint(self, pretrained):
checkpoint = torch.load(pretrained)
if isinstance(checkpoint, OrderedDict):
state_dict = checkpoint
elif isinstance(checkpoint, dict) and 'state_dict' in checkpoint:
state_dict = checkpoint['state_dict']
if list(state_dict.keys())[0].startswith('module.'):
state_dict = {k[7:]: v for k, v in checkpoint['state_dict'].items()}
unexpected_keys = [] # 保存checkpoint不在module中的key
model_state = self.state_dict() # 模型变量
for name, param in state_dict.items(): # 循环遍历pretrained的权重
if name not in model_state:
unexpected_keys.append(name)
continue
if isinstance(param, torch.nn.Parameter):
# backwards compatibility for serialized parameters
param = param.data
try:
model_state[name].copy_(param) # 试图赋值给模型
except Exception:
raise RuntimeError(
'While copying the parameter named {}, '
'whose dimensions in the model are {} not equal '
'whose dimensions in the checkpoint are {}.'.format(
name, model_state[name].size(), param.size()))
missing_keys = set(model_state.keys()) - set(state_dict.keys())
print('missing_keys:',missing_keys)
def _make_layer(self, block, planes, num_blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for i in range(1, num_blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x):
outs = []
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
outs.append(x)
x = self.layer2(x)
outs.append(x)
x = self.layer3(x)
outs.append(x)
x = self.layer4(x)
outs.append(x)
# x = self.avgpool(x)
# x = x.view(x.size(0), -1)
# x = self.fc(x)
return tuple(outs)
if __name__ == '__main__':
x = torch.ones((2, 3, 215, 215))
model = Resnet(depth=50)
model.init_weights(pretrained='./resnet50.pth')
# out = model(x)
#
# print(out)
标签:nn,self,backbone,ResNet,残差,stride,模块,planes,out 来源: https://www.cnblogs.com/tangjunjun/p/14947868.html