全网最硬核 Java 新内存模型解析与实验 - 5. JVM 底层内存屏障源码分析
作者:互联网
个人创作公约:本人声明创作的所有文章皆为自己原创,如果有参考任何文章的地方,会标注出来,如果有疏漏,欢迎大家批判。如果大家发现网上有抄袭本文章的,欢迎举报,并且积极向这个 github 仓库 提交 issue,谢谢支持~
本篇文章参考了大量文章,文档以及论文,但是这块东西真的很繁杂,我的水平有限,可能理解的也不到位,如有异议欢迎留言提出。本系列会不断更新,结合大家的问题以及这里的错误和疏漏,欢迎大家留言
如果你喜欢单篇版,请访问:全网最硬核 Java 新内存模型解析与实验单篇版(不断更新QA中)
如果你喜欢这个拆分的版本,这里是目录:
JMM 相关文档:
内存屏障,CPU 与内存模型相关:
x86 CPU 相关资料:
ARM CPU 相关资料:
各种一致性的理解:
Aleskey 大神的 JMM 讲解:
相信很多 Java 开发,都使用了 Java 的各种并发同步机制,例如 volatile,synchronized 以及 Lock 等等。也有很多人读过 JSR 第十七章 Threads and Locks(地址:https://docs.oracle.com/javase/specs/jls/se17/html/jls-17.html),其中包括同步、Wait/Notify、Sleep & Yield 以及内存模型等等做了很多规范讲解。但是也相信大多数人和我一样,第一次读的时候,感觉就是在看热闹,看完了只是知道他是这么规定的,但是为啥要这么规定,不这么规定会怎么样,并没有很清晰的认识。同时,结合 Hotspot 的实现,以及针对 Hotspot 的源码的解读,我们甚至还会发现,由于 javac 的静态代码编译优化以及 C1、C2 的 JIT 编译优化,导致最后代码的表现与我们的从规范上理解出代码可能的表现是不太一致的。并且,这种不一致,导致我们在学习 Java 内存模型(JMM,Java Memory Model),理解 Java 内存模型设计的时候,如果想通过实际的代码去试,结果是与自己本来可能正确的理解被带偏了,导致误解。
我本人也是不断地尝试理解 Java 内存模型,重读 JLS 以及各路大神的分析。这个系列,会梳理我个人在阅读这些规范以及分析还有通过 jcstress 做的一些实验而得出的一些理解,希望对于大家对 Java 9 之后的 Java 内存模型以及 API 抽象的理解有所帮助。但是,还是强调一点,内存模型的设计,出发点是让大家可以不用关心底层而抽象出来的一些设计,涉及的东西很多,我的水平有限,可能理解的也不到位,我会尽量把每一个论点的论据以及参考都摆出来,请大家不要完全相信这里的所有观点,如果有任何异议欢迎带着具体的实例反驳并留言。
8. 底层 JVM 实现分析
8.1. JVM 中的 OrderAccess 定义
JVM 中有各种用到内存屏障的地方:
- 实现 Java 的各种语法元素(volatile,final,synchronized,等等)
- 实现 JDK 的各种 API(VarHandle,Unsafe,Thread,等等)
- GC 需要的内存屏障:因为要考虑 GC 多线程与应用线程(在 GC 算法中叫做 Mutator)的工作方式,究竟是停止世界(Stop-the-world, STW)的方式,还是并发的方式
- 对象引用屏障:例如分代 GC,复制算法,年轻代 GC 的时候我们一般是从一个 S 区复制存活对象到另一个 S 区,如果复制的过程,我们不想停止世界(Stop-the-world, STW),而是和应用线程同时进行,那么我们就需要内存屏障,例如;
- 维护屏障:例如分区 GC 算法,我们需要维护每个区的跨区引用表以及使用情况表,例如 Card Table。这个如果我们想要应用线程与 GC 线程并发修改访问,而不是停止世界,那么也需要内存屏障。
- JIT 也需要内存屏障:同样地,应用线程究竟是解释执行代码还是执行 JIT 优化后的代码,这里也是需要内存屏障的。
这些内存屏障,不同的 CPU,不同的操作系统,底层需要不同的代码实现,统一的接口设计是:
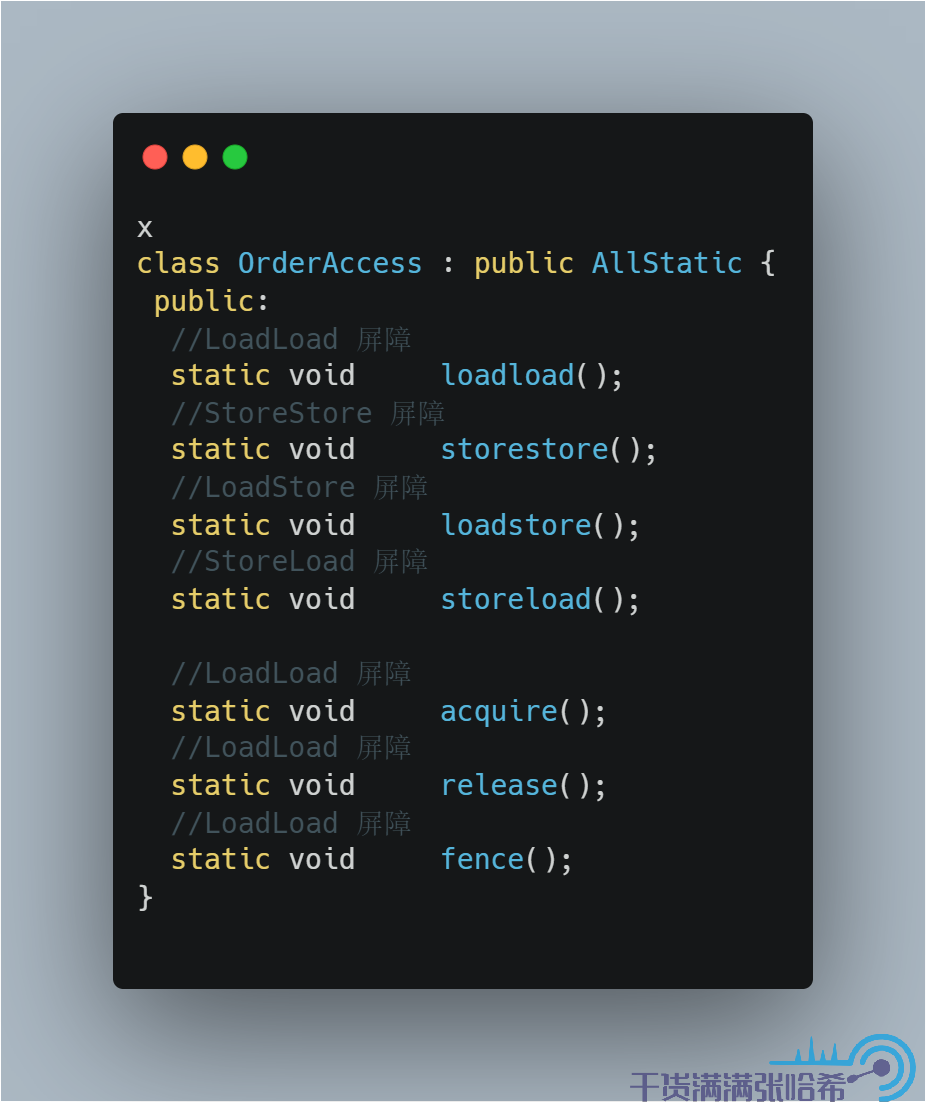
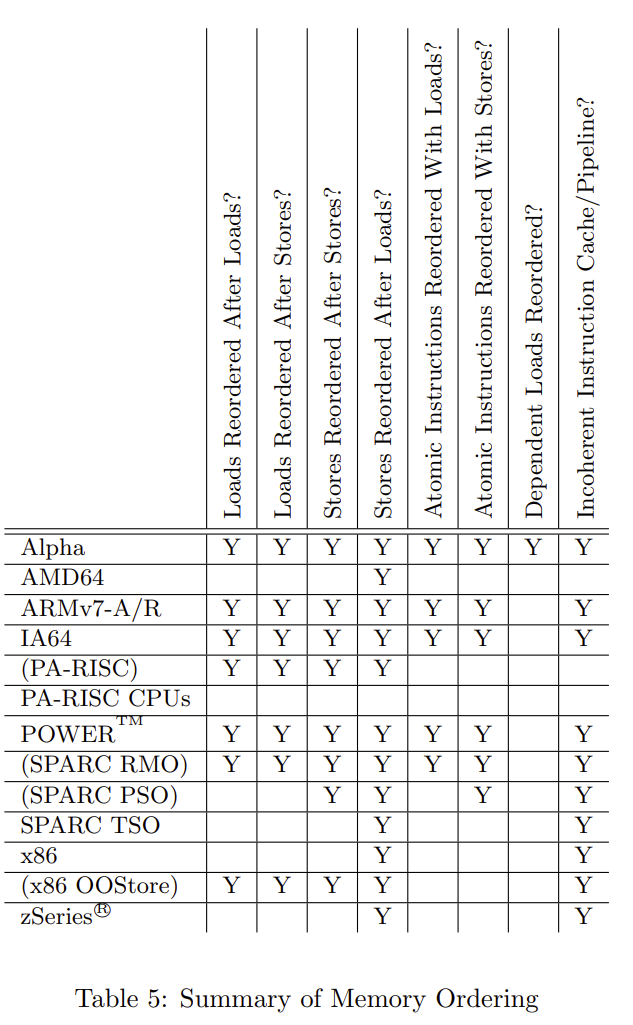
不同的 CPU,不同的操作系统实现是不一样的,结合前面 CPU 乱序表格:
我们来看下 linux + x86 的实现:
源代码地址:orderAccess_linux_x86.hpp
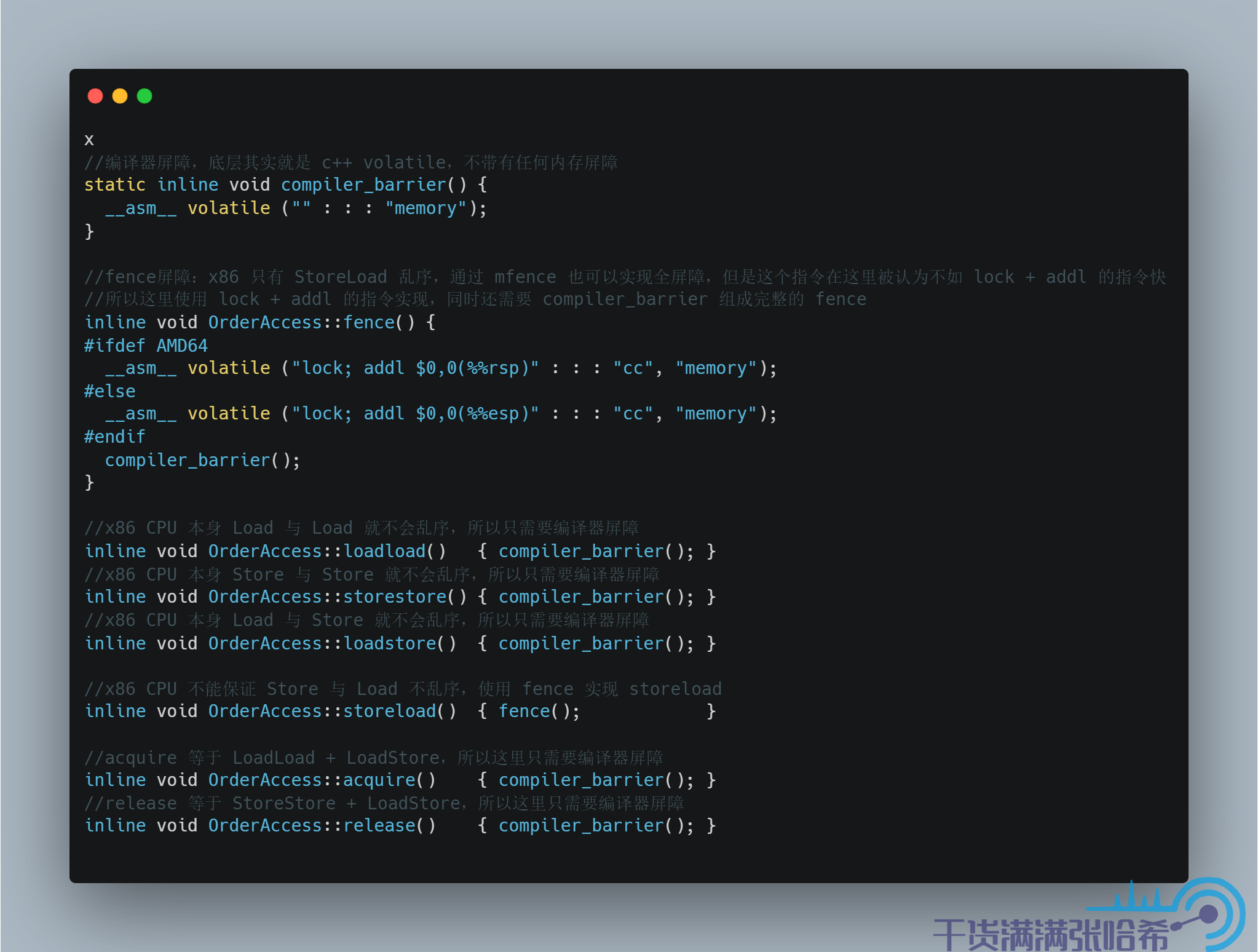
对于 x86,由于 Load 与 Load,Load 与 Store,Store 与 Store 本来有一致性保证,所以只要没有编译器乱序,那么就天生有 StoreStore,LoadLoad,LoadStore 屏障,所以这里我们看到 StoreStore,LoadLoad,LoadStore 屏障的实现都只是加了编译器屏障。同时,前文中我们分析过,acquire 其实就是相当于在 Load 后面加上 LoadLoad,LoadStore 屏障,对于 x86 还是需要编译器屏障就够了。release 我们前文中也分析过,其实相当于在 Store 前面加上 LoadStore 和 StoreStore,对于 x86 还是需要编译器屏障就够了。于是,我们有如下表格:
我们再看下前面我们经常使用的 Linux aarch64 下的实现:
源代码地址:orderAccess_linux_aarch64.hpp
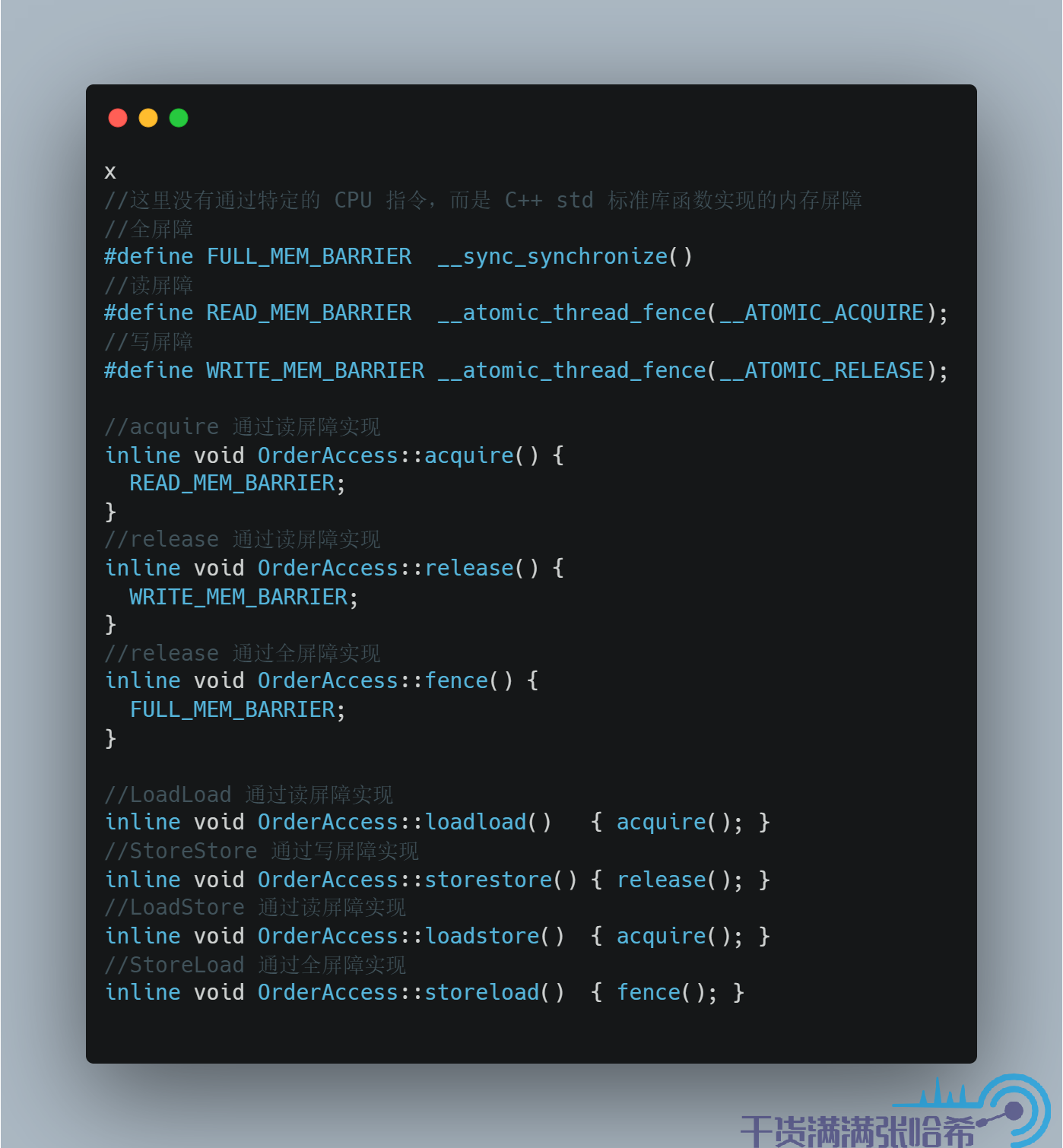
如前面表格里面说,ARM 的 CPU Load 与 Load,Load 与 Store,Store 与 Store,Store 与 Load 都会乱序。JVM 针对 aarch64 没有直接使用 CPU 指令,而是使用了 C++ 封装好的内存屏障实现。C++ 封装好的很像我们前面讲的简易 CPU 模型的内存屏障,即读内存屏障(__atomic_thread_fence(__ATOMIC_ACQUIRE)),写内存屏障(__atomic_thread_fence(__ATOMIC_RELEASE)),读写内存屏障(全内存屏障,__sync_synchronize())。acquire 的作用是作为接收点解包让后面的都看到包里面的内容,类比简易 CPU 模型,其实就是阻塞等待 invalidate queue 完全处理完保证 CPU 缓存没有脏数据。release 的作用是作为发射点将前面的更新打包发出去,类比简易 CPU 模型,其实就是阻塞等待 store buffer 完全刷入 CPU 缓存。所以,acquire,release 分别使用读内存屏障和写内存屏障实现。
LoadLoad 保证第一个 Load 先于第二个,那么其实就是在第一个 Load 后面加入读内存屏障,阻塞等待 invalidate queue 完全处理完;LoadStore 同理,保证第一个 Load 先于第二个 Store,只要 invalidate queue 处理完,那么当前 CPU 中就没有对应的脏数据了,就不需要等待当前的 CPU 的 store buffer 也清空。
StoreStore 保证第一个 Store 先于第二个,那么其实就是在第一个写入后面放读内存屏障,阻塞等待 store buffer 完全刷入 CPU 缓存;对于 StoreLoad,比较特殊,由于第二个 Load 需要看到 Store 的最新值,也就是更新不能只到 store buffer,同时过期不能存在于 invalidate queue 未处理,所以需要读写内存屏障,即全屏障。
8.2. volatile 与 final 的内存屏障源码
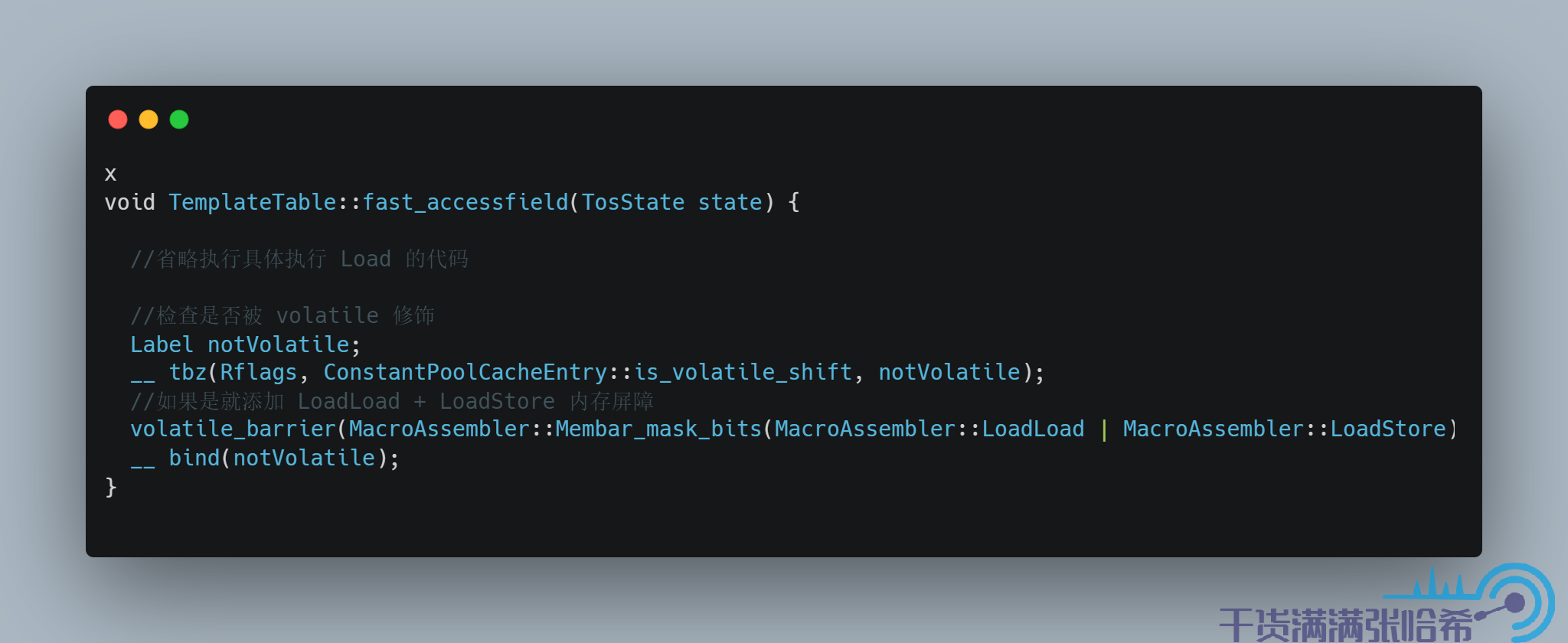
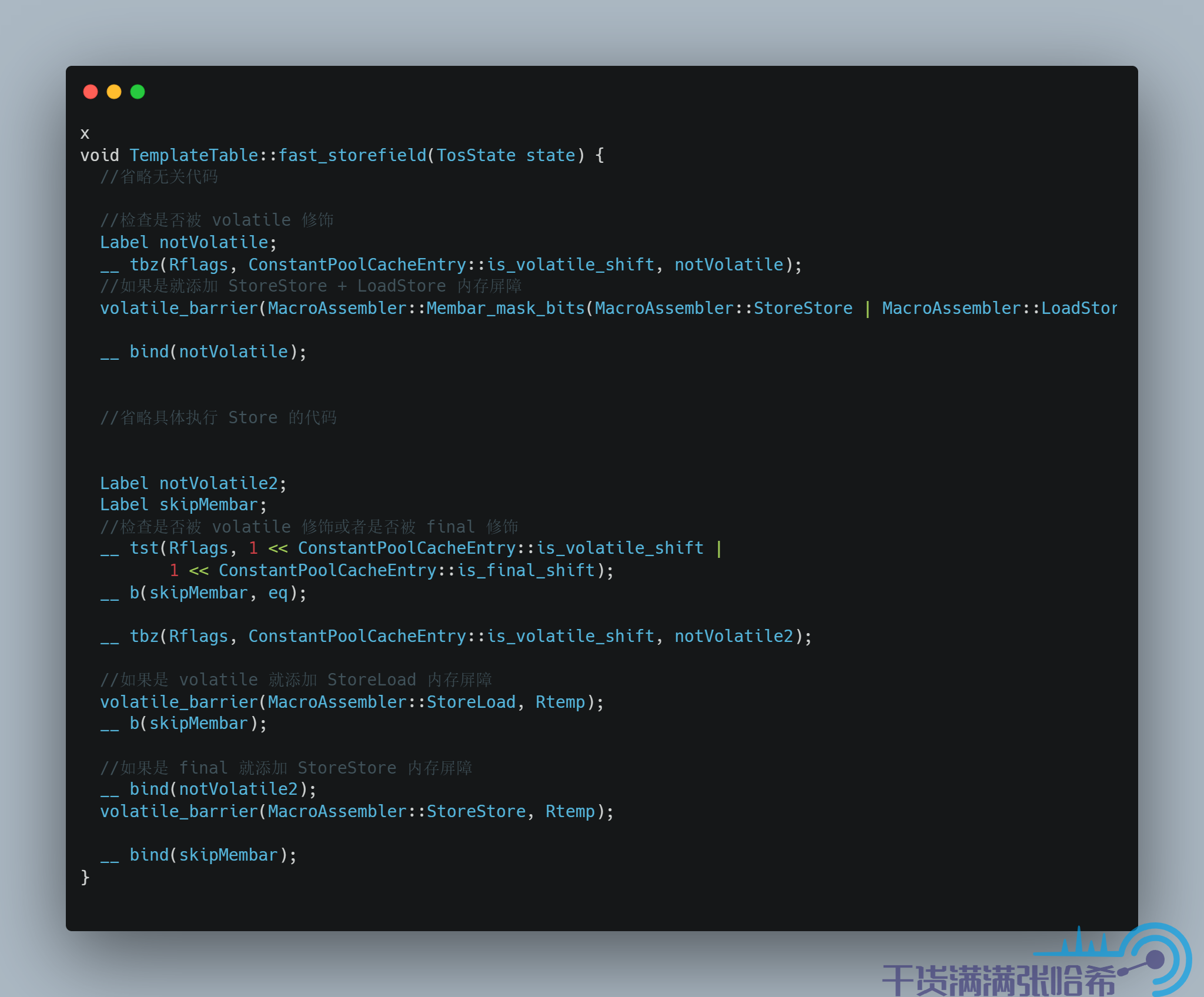
我们接下来看一下 volatile 的内存屏障插入的相关代码,以 arm 为例子. 我们其实通过跟踪 iload 这个字节码就可以看出来如果 load 的是 volatile 关键字或者 final 关键字修饰的字段会怎么样,以及 istore就可以看出来如果 store的是 volatile 关键字或者 final 关键字修饰的字段会怎么样
对于字段访问,JVM 中也有快速路径和慢速路径,我们这里只看快速路径的代码:
对应源码:
微信搜索“我的编程喵”关注公众号,加作者微信,每日一刷,轻松提升技术,斩获各种offer:
我会经常发一些很好的各种框架的官方社区的新闻视频资料并加上个人翻译字幕到如下地址(也包括上面的公众号),欢迎关注:

标签:Load,Store,Java,CPU,屏障,内存,源码,硬核 来源: https://www.cnblogs.com/zhxdick/p/16079488.html