SQL Server Indexes
作者:互联网
| Posted by scott on 2003年12月31日 Coveres the basics of indexes in SQL Server. Clustered versus non-clustered, composite, and unique indexes, as well as tips for chosing the columns and SQL to create, delete, and rename indexes. |
| Relational databases use indexes to find data quickly when a query is processed. Creating and removing indexes from a database schema will rarely result in changes to an application's code; indexes operate 'behind the scenes' in support of the database engine. However, creating the proper index can drastically increase the performance of an application.
A database engine uses a database index in much the same way a reader uses a book index. For example, one way to find all references to INSERT statements in a SQL book would be to begin on page one and scan each page of the book. We could mark each time we find the word INSERT until we reach the end of the book. This approach is pretty time consuming and laborious. Alternately, we can also use the index in the back of the book to find a page number for each occurrence of the INSERT statements. This approach produces the same results as above, but with tremendous savings in time. When a database has no index to use for searching, the result is similar to the reader who looks at every page in a book to find a word: the database engine needs to visit every row in a table. In database terminology we call this behavior a table scan, or just scan. A table scan is not always a problem, and is sometimes unavoidable. However, as a table grows to thousands of rows and then millions of rows and beyond, scans become correspondingly slower and more expensive. Consider the following query on the Products table of the Northwind database. This query retrieves products in a specific price range. SELECT ProductID, ProductName, UnitPrice FROM Products WHERE (UnitPrice > 12.5) AND (UnitPrice < 14) There is currently no index on the Product table to help this query, so the database engine performs a scan and examines each record to see if UnitPrice falls between 12.5 and 14. In the diagram below, the database search touches a total of 77 records to find just three matches. 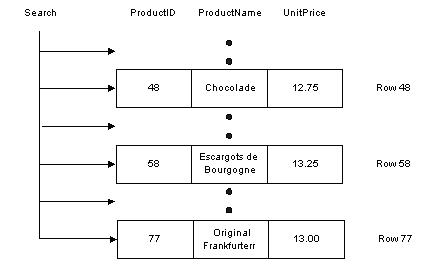 Now imagine if we created an index, just like a book index, on the data in the UnitPrice column. Each index entry would contain a copy of the UnitPrice value for a row, and a reference (just like a page number) to the row where the value originated. The database will sort these index entries into ascending order. The index will allow the database to quickly narrow in on the three rows to satisfy the query, and avoid scanning every row in the table. Creating An IndexHaving a data connection in the Server Explorer view of Visual Studio.NET allows us to easily create new indexes:
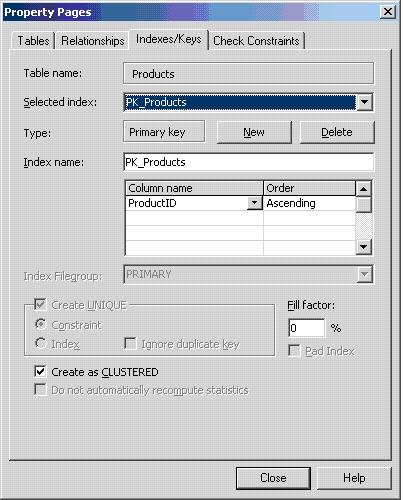
This should bring you to the following tabbed dialog box. The dialog is currently displaying an existing index on the Products table: the PK_Products index. We will see later in this chapter how primary key fields are automatically indexed to enforce uniqueness in the key values.
We can create the same index using the following SQL. The command specifies the name of the index (IDX_UnitPrice), the table name (Products), and the column to index (UnitPrice). CREATE INDEX [IDX_UnitPrice] ON Products (UnitPrice) To verify that the index is created, use the following stored procedure to see a list of all indexes on the Products table: EXEC sp_helpindex Customers How It WorksThe database takes the columns specified in a CREATE INDEX command and sorts the values into a special data structure known as a B-tree. A B-tree structure supports fast searches with a minimum amount of disk reads, allowing the database engine to quickly find the starting and stopping points for the query we are using. Conceptually, we may think of an index as shown in the diagram below. On the left, each index entry contains the index key (UnitPrice). Each entry also includes a reference (which points) to the table rows which share that particular value and from which we can retrieve the required information. 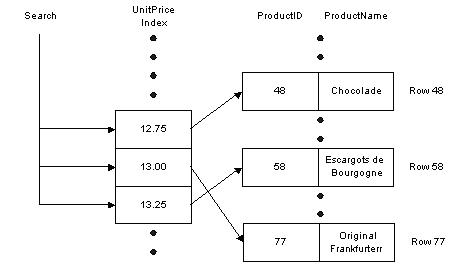 Much like the index in the back of a book helps us to find keywords quickly, so the database is able to quickly narrow the number of records it must examine to a minimum by using the sorted list of UnitPrice values stored in the index. We have avoided a table scan to fetch the query results. Given this sketch of how indexes work, lets examine some of the scenarios where indexes offer a benefit. Taking Advantage of IndexesThe database engine can use indexes to boost performance in a number of different queries. Sometimes these performance improvements are dramatic. An important feature of SQL Server 2000 is a component known as the query optimizer. The query optimizer's job is to find the fastest and least resource intensive means of executing incoming queries. An important part of this job is selecting the best index or indexes to perform the task. In the following sections we will examine the types of queries with the best chance of benefiting from an index. Searching For RecordsThe most obvious use for an index is in finding a record or set of records matching a WHERE clause. Indexes can aid queries looking for values inside of a range (as we demonstrated earlier), as well as queries looking for a specific value. By way of example, the following queries can all benefit from an index on UnitPrice: DELETE FROM Products WHERE UnitPrice = 1 UPDATE Products SET Discontinued = 1 WHERE UnitPrice > 15 SELECT * FROM PRODUCTS WHERE UnitPrice BETWEEN 14 AND 16 Indexes work just as well when searching for a record in DELETE and UPDATE commands as they do for SELECT statements. Sorting RecordsWhen we ask for a sorted dataset, the database will try to find an index and avoid sorting the results during execution of the query. We control sorting of a dataset by specifying a field, or fields, in an ORDER BY clause, with the sort order as ASC (ascending) or DESC (descending). For example, the following query returns all products sorted by price: SELECT * FROM Products ORDER BY UnitPrice ASCWith no index, the database will scan the Products table and sort the rows to process the query. However, the index we created on UnitPrice (IDX_UnitPrice) earlier provides the database with a presorted list of prices. The database can simply scan the index from the first entry to the last entry and retrieve the rows in sorted order. The same index works equally well with the following query, simply by scanning the index in reverse. SELECT * FROM Products ORDER BY UnitPrice DESC Grouping RecordsWe can use a GROUP BY clause to group records and aggregate values, for example, counting the number of orders placed by a customer. To process a query with a GROUP BY clause, the database will often sort the results on the columns included in the GROUP BY. The following query counts the number of products at each price by grouping together records with the same UnitPrice value. SELECT Count(*), UnitPrice FROM Products GROUP BY UnitPrice The database can use the IDX_UnitPrice index to retrieve the prices in order. Since matching prices appear in consecutive index entries, the database is able count the number of products at each price quickly. Indexing a field used in a GROUP BY clause can often speed up a query. Maintaining a Unique ColumnColumns requiring unique values (such as primary key columns) must have a unique index applied. There are several methods available to create a unique index. Marking a column as a primary key will automatically create a unique index on the column. We can also create a unique index by checking the Create UNIQUE checkbox in the dialog shown earlier. The screen shot of the dialog displayed the index used to enforce the primary key of the Products table. In this case, the Create UNIQUE checkbox is disabled, since an index to enforce a primary key must be a unique index. However, creating new indexes not used to enforce primary keys will allow us to select the Create UNIQUE checkbox. We can also create a unique index using SQL with the following command: CREATE UNIQUE INDEX IDX_ProductName On Products (ProductName) The above SQL command will not allow any duplicate values in the ProductName column, and an index is the best tool for the database to use to enforce this rule. Each time an application adds or modifies a row in the table, the database needs to search all existing records to ensure none of values in the new data duplicate existing values. Indexes, as we should know by now, will improve this search time. Index DrawbacksThere are tradeoffs to almost any feature in computer programming, and indexes are no exception. While indexes provide a substantial performance benefit to searches, there is also a downside to indexing. Let's talk about some of those drawbacks now. Indexes and Disk SpaceIndexes are stored on the disk, and the amount of space required will depend on the size of the table, and the number and types of columns used in the index. Disk space is generally cheap enough to trade for application performance, particularly when a database serves a large number of users. To see the space required for a table, use the sp_spaceused system stored procedure in a query window.EXEC sp_spaceused Orders Given a table name (Orders), the procedure will return the amount of space used by the data and all indexes associated with the table, like so: Name rows reserved data index_size unused ------- -------- ----------- ------ ---------- ------- Orders 830 504 KB 160 KB 320 KB 24 KB According to the output above, the table data uses 160 kilobytes, while the table indexes use twice as much, or 320 kilobytes. The ratio of index size to table size can vary greatly, depending on the columns, data types, and number of indexes on a table. Indexes and Data ModificationAnother downside to using an index is the performance implication on data modification statements. Any time a query modifies the data in a table (INSERT, UPDATE, or DELETE), the database needs to update all of the indexes where data has changed. As we discussed earlier, indexing can help the database during data modification statements by allowing the database to quickly locate the records to modify, however, we now caveat the discussion with the understanding that providing too many indexes to update can actually hurt the performance of data modifications. This leads to a delicate balancing act when tuning the database for performance. In decision support systems and data warehouses, where information is stored for reporting purposes, data remains relatively static and report generating queries outnumber data modification queries. In these types of environments, heavy indexing is commonplace in order to optimize the reports generated. In contrast, a database used for transaction processing will see many records added and updated. These types of databases will use fewer indexes to allow for higher throughput on inserts and updates. Every application is unique, and finding the best indexes to use for a specific application usually requires some help from the optimization tools offered by many database vendors. SQL Server 2000 and Access include the Profiler and Index Tuning Wizard tools to help tweak performance. Now we have enough information to understand why indexes are useful and where indexes are best applied. It is time now to look at the different options available when creating an index and then address some common rules of thumb to use when planning the indexes for your database. Clustered IndexesEarlier in the article we made an analogy between a database index and the index of a book. A book index stores words in order with a reference to the page numbers where the word is located. This type of index for a database is a nonclustered index; only the index key and a reference are stored. In contrast, a common analogy for a clustered index is a phone book. A phone book still sorts entries into alphabetical order. The difference is, once we find a name in a phone book, we have immediate access to the rest of the data for the name, such as the phone number and address. For a clustered index, the database will sort the table's records according to the column (or columns) specified by the index. A clustered index contains all of the data for a table in the index, sorted by the index key, just like a phone book is sorted by name and contains all of the information for the person inline. The nonclustered indexes created earlier in the chapter contain only the index key and a reference to find the data, which is more like a book index. You can only create one clustered index on each table. In the diagram below we have a search using a clustered index on the UnitPrice column of the Products table. Compare this diagram to the previous diagram with a regular index on UnitPrice. Although we are only showing three columns from the Products table, all of the columns are present and notice the rows are sorted into the order of the index, there is no reference to follow from the index back to the data. 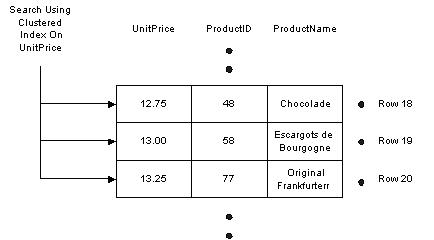 A clustered index is the most important index you can apply to a table. If the database engine can use a clustered index during a query, the database does not need to follow references back to the rest of\ the data, as happens with a nonclustered index. The result is less work for the database, and consequently, better performance for a query using a clustered index. To create a clustered index, simply select the Create As CLUSTERED checkbox in the dialog box we used at the beginning of the chapter. The SQL syntax for a clustered index simply adds a new keyword to the CREATE INDEX command, as shown below: CREATE CLUSTERED INDEX IDX_SupplierID ON Products(SupplierID) Most of the tables in the Northwind database already have a clustered index defined on a table. Since we can only have one clustered index per table, and the Products table already has a clustered index (PK_Products) on the primary key (ProductId), the above command should generate the following error: Cannot create more than one clustered index on table 'Products'. Drop the existing clustered index 'PK_Products' before creating another. As a general rule of thumb, every table should have a clustered index. If you create only one index for a table, use a clustered index. Not only is a clustered index more efficient than other indexes for retrieval operations, a clustered index also helps the database efficiently manage the space required to store the table. In SQL Server, creating a primary key constraint will automatically create a clustered index (if none exists) using the primary key column as the index key. Sometimes it is better to use a unique nonclustered index on the primary key column, and place the clustered index on a column used by more queries. For example, if the majority of searches are for the price of a product instead of the primary key of a product, the clustered index could be more effective if used on the price field. A clustered index can also be a UNIQUE index. A Disadvantage to Clustered IndexesIf we update a record and change the value of an indexed column in a clustered index, the database might need to move the entire row into a new position to keep the rows in sorted order. This behavior essentially turns an update query into a DELETE followed by an INSERT, with an obvious decrease in performance. A table's clustered index can often be found on the primary key or a foreign key column, because key values generally do not change once a record is inserted into the database. Composite IndexesA composite index is an index on two or more columns. Both clustered and nonclustered indexes can be composite indexes. Composite indexes are especially useful in two different circumstances. First, you can use a composite index to cover a query. Secondly, you can use a composite index to help match the search criteria of specific queries. We will go onto more detail and give examples of these two areas in the following sections. Covering Queries with an IndexEarlier in the article we discussed how an index, specifically a nonclustered index, contains only the key values and a reference to find the associated row of data. However, if the key value contains all of the information needed to process a query, the database never has to follow the reference and find the row; it can simply retrieve the information from the index and save processing time. This is always a benefit for clustered indexes. As an example, consider the index we created on the Products table for UnitPrice. The database copied the values from the UnitPrice column and sorted them into an index. If we execute the following query, the database can retrieve all of the information for the query from the index itself. SELECT UnitPrice FROM Products ORDER BY UnitPrice We call these types of queries covered queries, because all of the columns requested in the output are contained in the index itself. A clustered index, if selected for use by the query optimizer, always covers a query, since it contains all of the data in a table. For the following query, there are no covering indexes on the Products table. SELECT ProductName, UnitPrice FROM Products ORDER BY UnitPrice This is because although the database will use the index on UnitPrice to avoid sorting records, it will need to follow the reference in each index entry to find the associated row and retrieve the product name. By creating a composite index on two columns (ProductName and UnitPrice), we can cover this query with the new index. Matching Complex Search CriteriaFor another way to use composite indexes, let's take a look at the OrderDetails table of Northwind. There are two key values in the table (OrderID and ProductID); these are foreign keys, referencing the Orders and Products tables respectively. There is no column dedicated for use as a primary key; instead, the primary key is the combination of the columns OrderID and ProductID. The primary key constraint on these columns will generate a composite index, which is unique of course. The command the database would use to create the index looks something like the following: CREATE UNIQUE CLUSTERED INDEX PK_Order_Details
ON [Order Details] (OrderID, ProductID)
The order in which columns appear in a CREATE INDEX statement is significant. The primary sort order for this index is OrderID. When the OrderID is the same for two or more records, the database will sort this subset of records on ProductID. The order of columns determines how useful the index is for a query. Consider the phone book sorted by last name then first name. The phone book makes it easy to find all of the listings with a last name of Smith, or all of the listings with a last name of Jones and a first name of Lisa, but it is difficult to find all listings with a first name of Gary without scanning the book page by page. Likewise, the composite index on Order Details is useful in the following two queries: SELECT * FROM [Order Details] WHERE OrderID = 11077 SELECT * FROM [Order Details] WHERE OrderID = 11077 AND ProductID = 13 However, the following query cannot take advantage of the index we created since ProductID is the second part of the index key, just like the first name field in a phone book. SELECT * FROM [Order Details] WHERE ProductID = 13 In this case, ProductID is a primary key, however, so an index does exist on the ProductID column for the database to use for this query. Suppose the following query is the most popular query executed by our application, and we decided we needed to tune the database to support it. SELECT ProductName, UnitPrice FROM Products ORDER BY UnitPrice We could create the following index to cover the query. Notice we have specified two columns for the index: UnitPrice and ProductName (making the index a composite index): CREATE INDEX IX_UnitPrice_ProductName ON Products(UnitPrice, ProductName) While covered queries can provide a performance benefit, remember there is a price to pay for each index we add to a table, and we can also never cover every query in a non-trivial application. Additional Index GuidelinesChoosing the correct columns and types for an index is another important step in creating an effective index. In this section, we will talk about two main points, namely short index keys and selective indexes (we'll explain what selective indexes are in just a moment). Keep Index Keys ShortThe larger an index key is, the harder a database has to work to use the index. For instance, an integer key is smaller in size then a character field for holding 100 characters. In particular, keep clustered indexes as short as possible. There are several approaches to keeping an index key short. First, try to limit the index to as few columns as possible. While composite indexes are useful and can sometimes optimize a query, they are also larger and cause more disk reads for the database. Secondly, try to choose a compact data type for an index column, based on the number of bytes required for each data type. Integer keys are small and easy for the database to compare. In contrast, strings require a character-by-character comparison. As a rule of thumb, try to avoid using character columns in an index, particularly primary key indexes. Integer columns will always have an advantage over character fields in ability to boost the performance of a query. Distinct Index KeysThe most effective indexes are the indexes with a small percentage of duplicated values. Think of having a phone book for a city where 75% of the population has the last name of Smith. A phone book in this area might be easier to use if the entries were sorted by the resident's first names instead. A good index will allow the database to disregard as many records as possible during a search. An index with a high percentage of unique values is a selective index. Obviously, a unique index is the most selective index of all, because there are no duplicate values. SQL Server will track statistics for indexes and will know how selective each index is. The query optimizer utilizes these statistics when selecting the best index to use for a query. Maintaining IndexesIn addition to creating an index, we'll need to view existing indexes, and sometimes delete or rename them. This is part of the ongoing maintenance cycle of a database as the schema changes, or even naming conventions change. View Existing IndexesA list of all indexes on a table is available in the dialog box we used to create an index. Click on the Selected index drop down control and scroll through the available indexes. There is also a stored procedure named sp_helpindex. This stored procedure gives all of the indexes for a table, along with all of the relevant attributes. The only input parameter to the procedure is the name of the table, as shown below. EXEC sp_helpindex Customers Rename an IndexWe can also rename any user created object with the sp_rename stored procedure, including indexes. The sp_rename procedure takes, at a minimum, the current name of the object and the new name for the object. For indexes, the current name must include the name of the table, a dot separator, and the name of the index, as shown below: EXEC sp_rename 'Products.IX_UnitPrice', 'IX_Price' This will change the name of the IX_UnitPrice index to IX_Price. Delete an IndexIt is a good idea to remove an index from the database if the index is not providing any benefit. For instance, if we know the queries in an application are no longer searching for records on a particular column, we can remove the index. Unneeded indexes only take up storage space and diminish the performance of modifications. You can remove most indexes with the Delete button on the index dialog box, which we saw earlier. The equivalent SQL command is shown below. DROP Index Products.IX_Price Again, we need to use the name of the table and the name of the index, with a dot separator. Some indexes are not so easy to drop, namely any index supporting a unique or primary key constraint. For example, the following command tries to drop the PK_Products index of the Products table. DROP INDEX Products.PK_Products Since the database uses PK_Products to enforce a primary key constraint on the Products table, the above command should produce the following error. An explicit DROP INDEX is not allowed on index 'Products.PK_Products'. It is being used for PRIMARY KEY constraint enforcement. Removing a primary key constraint from a table is a redesign of the table, and requires careful thought. It makes sense to know the only way to achieve this task is to either drop the table and use a CREATE TABLE command to recreate the table without the index, or to use the ALTER TABLE command. ConclusionIn this article we learned how to create, manage, and select indexes for SQL Server tables. Most of what we covered is true for any relational database engine. Proper indexes are crucial for good performance in large databases. Sometimes you can make up for a poorly written query with a good index, but it can be hard to make up for poor indexing with even the best queries. |
转载于:https://www.cnblogs.com/Stephen/archive/2004/05/02/8261.html
标签:index,indexes,database,Indexes,query,SQL,table,Server,UnitPrice 来源: https://blog.csdn.net/weixin_34405332/article/details/93223645