如何理解图数据库的分布与分区
作者:互联网
什么是分布式系统?
通常,分布式系统是一组计算机程序,它们在多个独立的服务器上协同工作以实现共同目标。这些服务器指的是这些商用服务器,而不是大型机。这里用于跨服务器协作的硬件主要基于以太网设备或高端 RMDA 设备。
为什么我们需要分布式系统?
构建分布式系统的主要原因是用软件技术和廉价的硬件设备取代昂贵的硬件设备的成本。特别是在大多数私有机房,而不是公有云或超级计算条件下,采购成本是业务决策的重要依据。
除了降低成本之外,分布式技术的另一个好处是其可扩展性。通过在原来的服务器数量上添加几台服务器,然后结合分布式系统的调度和分发能力,可以使用新服务器来提供额外的服务。
与购买更多同等数量的服务器或购买更高配置的服务器相比,分布式技术允许您按需购买服务器,从而降低过度配置的风险,提高硬件资源的利用率。
分布式系统的基本问题
在分布式技术中,由于数据存储和计算需要在多个独立的服务器上实现,因此必须涉及一系列底层技术。在本文中,我们只讨论两个问题:一个是数据复制或副本问题,另一个是如何将大数据的存储和计算分发到独立的服务器。
数据副本问题
商用服务器的硬件可靠性和维护成本远低于大型机。因为在大型机房中,几乎每小时都会发生网线松动、硬盘损坏和电源故障。分布式软件系统解决或避免这些硬件问题是一个基本问题。一种常见的解决方案是在多台服务器上复制数据。丢失部分数据副本后,系统仍可使用剩余数据副本提供服务。
更重要的是,当系统的访问负载过大时,系统还可以通过添加更多副本来提供更多的服务。此外,还需要一些技术来确保数据副本彼此一致;也就是说,不同服务器上每个副本的数据是相同的。对于图形数据库,还存在数据副本问题。解决这个问题的方法类似于关系数据库或大数据系统中数据副本问题的解决方式。
数据分区问题
单个服务器的硬件、内存和 CPU 是有限的。如果数据太大,则不可能将所有数据存储在单个服务器上。因此,TB级甚至PB级的数据必须分发到多台服务器上,我们称这个过程为数据分区。当请求要访问多个数据分区时,分布式系统需要将请求分发到每个正确的数据分区,然后合并结果。
图数据库数据分区问题:图分区
在图形数据库中,分布过程被想象地称为图形分区。 一个大图被划分成多个小图,每个小图的存储和计算存储在不同的服务器上。
与关系数据库和大数据系统中的分区问题相比,图分区问题更值得特别注意。
让我们看一下静态图结构,例如 CiteSeer 数据集,它是一个科学论文的引用网络,由 3312 篇论文及其之间的引用组成。它是一个可以存储在单个服务器上的小规模数据集。
Twitter 2010 数据集是一个由 Twitter 用户组成的社交网络,由 1271 万个顶点和 2.3 亿条边组成。将此数据集存储在 2022 年生产的单个主流服务器上相对容易。但是,可能需要购买十年前生产的非常昂贵的高端服务器才能做到这一点。
但是,WDC(Web 数据共享)数据集由 17 亿个顶点和 640 亿条边组成。在当前的主流服务器上存储如此大规模的数据集是困难或不可能的。
另一方面,由于人类的数据增长速度快于摩尔定律,数据之间的连接或关系数量呈指数级增长,高于数据生产的速度,数据分区问题似乎是图数据库系统不可避免的问题。但这听起来与主流分布式技术中数据的分区或散列方式没有什么不同。毕竟,数据被划分为多个大数据系统。
等等,对图形进行分区有那么容易吗?
不,不是。在图形数据库领域,图形分区问题是技术、产品和工程之间的权衡。
图分区面临的三个问题
第一个问题:应该分区什么?在大数据或关系型数据库系统中,基于行的分区或基于列的分区是基于记录或字段执行的,或者基于数据ID进行分区,这在语义和技术上都很直观。但是,图数据结构的强连接性使得图数据难以分区。一个顶点可以通过多条边连接到许多其他顶点,其他顶点也可以通过其相邻边连接到许多其他顶点。它就像几乎相互链接的网页一样。那么对于一个图数据库,应该对什么进行分区,才能使语义直观和自然?(在 RDBMS 中,这等效于当表中存在大量外键时如何对数据进行分区。当然,也存在一些自然的语义划分方法。例如,在COVID-19疫情下,中国和其他国家的各种毒株的传播链是两种不同的网络结构。
然后,引入第二个问题。
第二个问题:是数据分区后如何保证每个分区的数据大致均衡。自然形成的图符合少数 20% 顶点连接到其他 80% 顶点的幂低,这些少数顶点称为超级节点或密集节点。这意味着少数顶点与大多数其他顶点相关联。因此,可以预期包含超级节点的分区的负载和热点远高于包含其他顶点的其他分区的负载和热点。

上图显示了由互联网上网站的超链接形成的关联网络的视觉效果,其中超级网站(节点)可见。
第三个问题:当原有的分区方法随着图网络的增长而逐渐过时,图分布和连接模式发生变化时,如何评估和执行重新分区?下图显示了人脑中 860 亿个神经元之间连接的视觉效果。随着学习、运动、睡眠和衰老,神经元连接在每周水平上不断变化。原始分区方法可能根本跟不上更改。
当然,还需要考虑许多其他细节。在本文中,我们尽量避免使用过多的技术术语。
不幸的是,从技术角度来看,图分区问题没有灵丹妙药,每个产品都必须做出权衡。
以下是不同产品进行权衡的一些示例。
不同图形数据库产品中的分区方法
1. 分布式但未分区
Neo4j 3.5 采用无分区分布式架构。
使用分布式系统的原因是为了确保写入数据在多个副本中的一致性和就绪可用性。
这意味着全部图形数据存储在每台服务器上,数据大小不能大于单个服务器的内存和硬盘的容量。我们可以通过添加多个写入副本来保证单个服务器在数据写入过程中的故障。我们可以通过添加多个只读副本来提高读取性能(写入性能没有提高)。
这种解决方案可以避免上面提到的图数据分区的三个问题,理论上,将这样的解决方案称为分布式图数据库并没有错。
除此之外,由于数据在每个服务器上都是完整的,因此ACID事务相对容易实现。
2. 由用户分发和分区
由用户分布式和分区的体系结构通常由Neo4j 4.x Fabric表示。根据用户的业务案例,用户可以指定可以将子图放置在(一组)服务器上。例如,在一个集群中,产品 E 的子图放在服务器 E 上,产品 N 的子图放在服务器 N 上(当然,为了服务本身的可用性,这些服务器也可以放在上图提到的因果集群中。在此过程中,对于写入和读取操作,用户需要指定要操作的服务器或服务器组。
该解决方案将上述三个问题留给用户在产品级别决策。因此,这种解决方案也称为分布式图形数据库。
此外,该解决方案可以保证服务器 E 中的 ACID 事务。但是,有一定数量的边连接服务器 E 中的顶点和其他服务器中的顶点,因此这些边的 ACID 事务在技术上无法保证。
有关 Neo4j 4.x 结构架构的详细信息。
3. 非等效分布式、分区和粗粒度复制
此解决方案允许多个副本和图形数据分区,这两个过程需要少量用户参与。
有关TigerGraph分区解决方案的详细信息,请参阅此YouTube视频。
在TigerGraph的解决方案中,顶点和边在编码后分散在多个分区中。
上述问题中的前两个问题可以通过对顶点和边进行编码来部分解决。用户可以决定是在分布式系统还是单个服务器中读取或计算数据。
但是,此类分区集必须以完整和相同的副本进行复制(因此横向扩展的粒度是整个图形而不是分区),这需要更大的存储空间。
4. 完全等效的分布式、分区和细粒度复制
还有一些解决方案的体系结构设计目的将图形可伸缩性或复原能力相对置于整个系统设计的最高优先级。假设数据的生成速度比摩尔定律快,数据之间的交互和关系呈指数级高于数据生成速率。因此,有必要能够处理这种爆炸性增长的数据并快速提供服务。
在该解决方案中,明显的特征是存储层和计算层的分离设计,每个层都具有细粒度的可扩展性。
数据在存储层中使用哈希或一致哈希解决方案进行分区。哈希基于顶点或主键的 ID 执行。此解决方案仅解决了第一个问题。
为了解决超级节点和负载均衡问题(第二个问题),引入了B树数据结构的另一层。它将超级节点拆分为多个处理单元,在线程之间平衡数据,并横向扩展计算层。
对于第三个问题,解决方案是使用细粒度分区方法,以便可以执行某些分区的横向扩展。
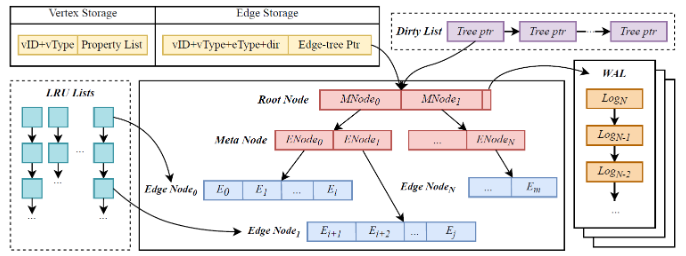
当然,此解决方案也称为分布式图形数据库。
上面提到的四种解决方案在产品和技术层面进行了不同的权衡,重点是合适的业务场景。因此,这些解决方案都可以称为分布式图形数据库。