Redis 作为数据库 — 使用 K6 进行速度测试
作者:互联网
测试设置
这些测试是在我的M1 Pro Macbook Pro上进行的,具有32 GB的内存,连接到WiFi和电池电源。我正在使用 Jetbrains Rider 在发布模式下运行 Visualizer 微服务,在命令行中运行 Redis Stack,在 VSCode 中运行 Visualizer 前端,以及当前版本的 macOS Ventura。
数据摄取
这是在 Redis 中存储单个推文的代码
| varinternalId=await_tweetCollection.InsertAsync(tweetModel); |
查看原始信息TweetDbService - 存储推文.cs由GitHub 托管
这在专用微服务中运行,每次从 Twitter 的示例流中检索新推文时都会执行。在以后的文章中,我将介绍可视化工具的体系结构。
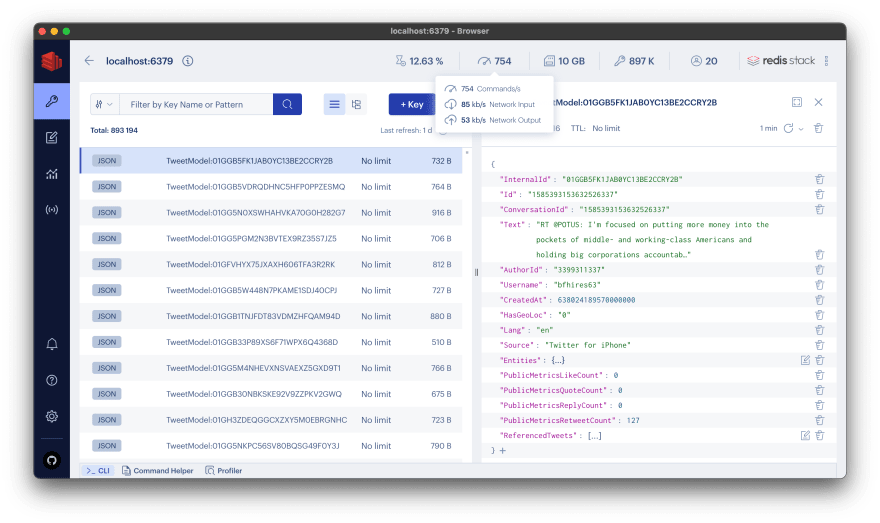
使用 RedisInsight,我可以看到,使用我当前的设置,我可以设法每秒发送大约 700 个命令,其中大部分是存储推文。
数据检索
检索数据由另一个微服务处理,该微服务仅从 Redis 读取数据。
使用K6,我编写了一个脚本,从 GraphQL API 检索 10 条推文。
| 从“K6/http”导入http; | |
| 导入{检查}从“K6”; | |
| import{Counter}from“k6/metrics”; | |
| import{htmlReport}from“https://raw.githubusercontent.com/benc-uk/k6-reporter/main/dist/bundle.js”; | |
| import{textSummary}from“https://jslib.k6.io/k6-summary/0.0.1/index.js”; | |
| 导出常量请求=新计数器(“http_reqs”); | |
| 导出常量选项 = { | |
| 阶段:[ | |
| { 目标:60,持续时间:“5s”}, | |
| { 目标:30,持续时间:“1s”}, | |
| { 目标:10,持续时间:“1s”}, | |
| { 目标:0,持续时间:“2s”}, | |
| ], | |
| }; | |
| 常量查询 = ` | |
| query getFilteredTweets($filter: FindTweetsInputTypeQl!){ | |
| 推特 { | |
| 查找(过滤器: $filter) { | |
| 总 | |
| 推文 { | |
| 编号 | |
| 作者标识 | |
| 用户名 | |
| 对话标识 | |
| 朗 | |
| 源 | |
| 发短信 | |
| 创建于 | |
| geoLoc { | |
| 纬度 | |
| 经度 | |
| } | |
| 实体 { | |
| 主题标签 | |
| 提到 | |
| } | |
| publicMetricsLikeCount | |
| publicMetricsRetweetCount | |
| publicMetricsReplyCount | |
| } | |
| } | |
| } | |
| } | |
| `; | |
| 常量变量={过滤器:{页面大小:10,页数:1 } }; | |
| letheaders={“Content-Type”:“application/json” }; | |
| 导出默认功能 () { | |
| constres=http.发布( | |
| “https://localhost:7083/graphql”, | |
| 杰森。stringify({query:query,variables:variables}), | |
| { 标头:标头 } | |
| ); | |
| constcheckRes=check(res, { | |
| “状态为 200”:(r)=>r。状态===200, | |
| }); | |
| } | |
| 这将导出为 HTML 作为文件名“result.html”,并使用文本摘要导出为 stdout | |
| 利用句柄摘要回调通过 K6-REPORTER https://github.com/benc-uk/k6-reporter 导出为 HTML | |
| 导出函数句柄摘要(数据) { | |
| 返回 { | |
| “result.html”:htmlReport(data), | |
| stdout:textSummary(data,{indent:“ ”,enableColors:true}), | |
| }; |