PostgreSQL并发控制机制(1):隔离级别
作者:互联网
并发控制是多个事务在并发运行时,数据库保证事务一致性(Consistency)和隔离性(Isolation)的一种机制。主流商用关系数据库使用的并发控制技术主要有三种:严格两阶段封锁(S2PL)、多版本并发控制(MVCC)和乐观并发控制(OCC)。PostgreSQL使用了多版本并发控制技术的一种变体:快照隔离Sanpshot Isolation(简称SI)。通过SI,PostgreSQL提供了四个事务隔离级别,但实现与ANSI SQL标准有一些差异。
一、基础知识
为了更好的描述,下面使用更一般化(抽象)的形式化语言描述数据库事务操作,同时对ANSI SQL标准隔离级别作一简要介绍。
1、形式化语言
使用形式化语言对读写操作、事务操作等进行描述。
读写操作
w和r,w表示写,r表示读。 这里的w泛指数据变更操作,包括但不限于插入、删除等操作。
示例:w1(x),r2(y)。其中w和r分别表示写和读,1和2分别表示事务T1和T2,x和y表示数据项。数据项是一个宽泛的概念,包括但不限于元组tuple、页page甚至是整个关系relation。
事务操作
c和a,c表示事务提交,a表示事务放弃(回滚)
示例:c1,a2。c表示commit提交,其后的数字指代事务,如c1表示事务T1提交。a表示abort回滚,a2表示事务T2回滚。
谓词
谓词P,指操作数据的条件范围。通常与读写操作一起出现。示例:r1[P]。r1[P]表示事务T1读满足谓词P的结果集。
2、ANSI SQL标准隔离级别
ANSI SQL标准通过禁止某些现象(暂且作为Phenomena的翻译)进行定义(还可以通过锁、数据流图定义)。下面首先使用形式化语言来定义以下几种现象:
脏写P0(Dirty Write):T1更新了数据,T2也更新了该数据。
w1(x)... w2(x)... (c1 or a1)
脏读P1(Dirty Read):T1更新了数据,T2读到该数据。
w1(x)...r2(x)... (c1 or a1)
不可重复读P2(Fuzzy or Non-Repeatable Read):T2更新数据,T1无法重复读
r1(x)...w2(x)... (c1 or a1)
幻读P3(Phantom):T2插入满足谓词P(Predicate)的数据,T1重新执行读,结果不同
r1(P)...w2(y in P)...(c1 or a1)
ANSI SQL标准通过禁止上述现象的形式定义了四个隔离级别,分别是读未提交、读已提交、可重复读和可串行化:

可串行化:禁止所有并发异象,效果如同事务以串行的方式执行
可重复读:除幻读外,禁止其他现象
读已提交:禁止脏读和脏写
读未提交:禁止脏写
二、PostgreSQL隔离级别
PostgreSQL与ANSI SQL标准相应,也定义了四种隔离级别:
testdb=# \help set transaction
Command: SET TRANSACTION
Description: set the characteristics of the current transaction
Syntax:SET TRANSACTION transaction_mode [, ...]
...
where transaction_mode is one of:
ISOLATION LEVEL { SERIALIZABLE | REPEATABLE READ | READ COMMITTED | READ UNCOMMITTED }
...
1、READ COMMITTED vs READ UNCOMMITTED
READ UNCOMMITTED和READ COMMITTED这两个级别在PostgreSQL中没有任何区别。
见下面例子,T1(session 1)启动事务,插入数据到表t1中,但不提交事务;T2(session 2)读取t1的数据,按READ UNCOMMITTED的定义,T2应可“脏读”数据表t1的数据,但实际上并没有获取脏数据。
-- session 1
testdb=# \d t1
Table "public.t1"
Column | Type | Collation | Nullable | Default--------+---------+-----------+----------+---------
id | integer | | |
testdb=# select * from t1;
id----
( rows)
testdb=# START TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
START TRANSACTION
testdb=# insert into t1 values(1);
INSERT 1
testdb=#
-- session 2
testdb=# START TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
START TRANSACTION
testdb=# select * from t1;
id----
( rows)
读未提交在PostgreSQL并没有实现,详细可参考PostgreSQL手册[1]。
2、REPEATABLE READ
在PostgreSQL 9.0或以下版本并没有可重复读隔离级别,在9.1之后,PostgreSQL实现了Serializable Snapshot Isolation(简称SSI),原隔离级别SERIALIZABLE变为新增的隔离级别REPEATABLE READ,新实现的SSI成为SERIALIZABLE。
严格上来说,PostgreSQL中的REPEATABLE READ隔离级别是Snapshot Isolation,比起ANSI SQL标准定义的可重复读,除了禁止P2 Non-Repeatable Read现象之外,还可以禁止P3 Phantom。
-- session 1
[local]:5432 postgres@testdb=# insert into t1 select generate_series(1,5);
INSERT 0 5Time: 3.638 ms
[local]:5432 postgres@testdb=# select * from t1 where id <= 10;
id
----
1
2
3
4
5
(5 rows)
Time: 0.607 ms
[local]:5432 postgres@testdb=# START TRANSACTION ISOLATION LEVEL REPEATABLE READ;
START TRANSACTIONTime: 0.292 ms
[local]:5432 postgres@testdb=#* select txid_current();
txid_current
--------------
502
(1 row)
Time: 0.284 ms
-- session 2
[local]:5432 postgres@testdb=# insert into t1 select generate_series(6,10);
INSERT 0 5Time: 1.511 ms
[local]:5432 postgres@testdb=# select * from t1;
id
----
1
2
3
4
5
6
7
8
9
10
(10 rows)
Time: 0.434 ms
-- session 1
[local]:5432 postgres@testdb=#* select * from t1 where id <= 10;
id
----
1
2
3
4
5
(5 rows)
Time: 0.536 ms
如上例所示,session 1查询数据表t1,返回1-5,session 2插入5行数据(6-10)。session 1再次查询表t1,返回的数据仍然是1-5(事务启动时的快照),之所以有这样的效果,原因是快照隔离级别提供了一致性读。
从理论上来说,快照隔离SI要求满足以下两个规则:
Rule 1:事务T读取数据对象x,其中x是T启动前已提交事务产生的最新版本
Rule 2:并发事务的写集合之间不相交。使用形式化语言描述,定义wset(T)表示事务T的写集合,设有两个并发事务T1和T2,SI要求wset(T1) ∩ wset(T2) = ∅(空集合),否则会出现冲突,其中一个事务必须回滚。
出现冲突时,冲突处理常用的协议包括FCW(First Commit Wins,先提交者胜)和FUW(First Updater Wins,先更新者胜)。
FCW:事务Ti准备提交时,检查是否存在其他已提交的事务变更了数据对象x,如存在则回滚,否则提交
FUW:如事务Tj已持有数据对象x的锁,同时Ti希望变更x,则Ti必须等待直至Tj提交或回滚;如Tj提交,则Ti回滚,如Tj回滚,则Ti可以获取x的写锁,事务继续执行。 PostgreSQL在REPEATABLE READ级别使用FUW协议。
|
时间点 |
T1 |
T2 |
|
t1 |
START TRANSACTION ISOLATION LEVEL REPEATABLE READ; |
|
|
t2 |
START TRANSACTION ISOLATION LEVEL REPEATABLE READ; |
|
|
t3 |
update t1 set id = 1 where id = 5; |
|
|
t4 |
update t1 set id = 11 where id = 5; |
|
|
t5 |
commit; |
|
|
t6 |
提示出错 |
执行输出如下:
-- T1
[local]:5432 postgres@testdb=# START TRANSACTION ISOLATION LEVEL REPEATABLE READ;
START TRANSACTIONTime: 0.197 ms
-- T2
[local]:5432 postgres@testdb=# START TRANSACTION ISOLATION LEVEL REPEATABLE READ;
START TRANSACTIONTime: 0.181 ms
-- T1
[local]:5432 postgres@testdb=#* update t1 set id = 1 where id = 5;
UPDATE 1Time: 0.430 ms
-- T2
[local]:5432 postgres@testdb=#* update t1 set id = 11 where id = 5;
---------->等待T1
-- T1
[local]:5432 postgres@testdb=#* commit;
COMMITTime: 3.241 ms
-- T2
[local]:5432 postgres@testdb=#* update t1 set id = 11 where id = 5;
ERROR: could not serialize access due to concurrent updateTime: 3172.768 ms (00:03.173)
3、SERIALIZABLE
REPEATABLE READ隔离级别已然禁止了P3 Phantom幻读,PostgreSQL为何还提供SERIALIZABLE隔离级别?原因是SI不能实现可串行化,还存在不可串行化的写倾斜(Write Skew)现象。
写倾斜(Write Skew)
使用形式化语言来表示:设rset(Tn)是事务Tn读数据涉及的数据项集合,wset(Tn)是事务Tn写数据涉及的数据项集合。
现有两个并发事务Ti和Tj,
1. Ti和Tj执行前,rset(Ti)和rset(Tj)之间满足某种业务约束C
2. wset(Ti) ∩ rset(Tj) ≠ ∅ 且 rset(Ti) ∩ wset(Tj) ≠ ∅
3. Ti和Tj执行后,rset(Ti)和rset(Tj)之间不再满足业务约束C
以上现象,称为Write Skew现象。
一个经典的例子,现有数据表doctor,业务约束要求处于oncall状态(oncall值为true)的医生人数不能少于1人,但如果存在并发事务同时手机靓号卖号地图更新不同医生的状态,则可能会出现Write Skew现象。
下面是一个例子,测试数据如下:

测试脚本:
-- 创建数据表,插入数据
drop table if exists doctor;
create table doctor(name varchar,oncall boolean,remark varchar);
insert into doctor(name,oncall,remark) values('Alice',true,'');
insert into doctor(name,oncall,remark) values('Bob',true,'');
insert into doctor(name,oncall,remark) values('Jacky',false,'');
insert into doctor(name,oncall,remark) values('Susan',false,'');
-- 创建更改状态的函数
CREATE OR REPLACE FUNCTION change_doctor_status(pi_name in varchar)
RETURNS boolean AS
$$
declare
v_count int := ;
begin
-- 获取处于oncall状态的医生数量
select count(*) from doctor into v_count where oncall = true;
-- 大于等于2,则设置医生oncall为false
if (v_count >= 2) then
update doctor
set oncall = false
where name = pi_name;
-- 成功返回t
return true;
end if;
-- 失败返回f
return false;
end;
$$ LANGUAGE plpgsql;
并发事务T1和T2的操作序列:
|
时间点 |
T1 |
T2 |
|
t1 |
START TRANSACTION ISOLATION LEVEL REPEATABLE READ; |
|
|
t2 |
START TRANSACTION ISOLATION LEVEL REPEATABLE READ; |
|
|
t3 |
select change_doctor_status('Alice'); |
|
|
t4 |
select change_doctor_status('Bob'); |
|
|
t5 |
commit; |
|
|
t6 |
commit; |
T1和T2完成后,数据如下:

T1和T2提交后,处于oncall状态的医生数变为0,违反了oncall状态医生人数不能少于1人的业务约束。
Serializable Snapshot Isolation
PostgreSQL在9.1之后实现了SSI,设置隔离级别为SERIALIZABLE可禁止Write Skew现象,并发事务之间出现冲突时遵循FCW协议。
沿用上例,重新初始化数据,仍然使用上述操作序列,隔离级别设置为SERIALIZABLE:
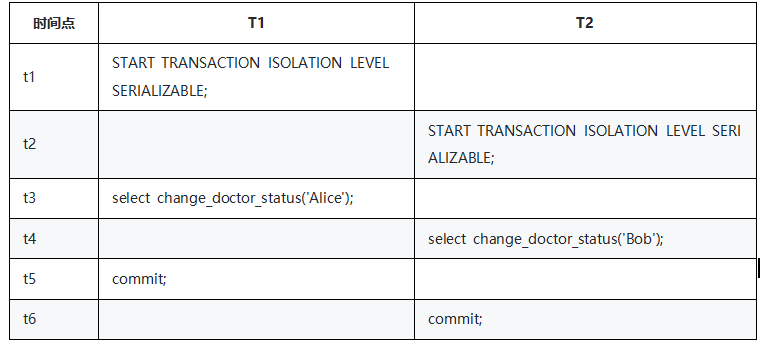
SERIALIZABLE隔离级别下,T2在执行commit的时候会报错:
-- T1
[local]:5432 postgres@testdb=# START TRANSACTION ISOLATION LEVEL SERIALIZABLE;
START TRANSACTION
-- T2
[local]:5432 postgres@testdb=# START TRANSACTION ISOLATION LEVEL SERIALIZABLE;
START TRANSACTION
-- T1
[local]:5432 postgres@testdb=#* select change_doctor_status('Alice');
change_doctor_status----------------------
t
(1 row)Time: 0.682 ms
-- T2
[local]:5432 postgres@testdb=#* select change_doctor_status('Bob');
change_doctor_status----------------------
t
(1 row)
-- T1
[local]:5432 postgres@testdb=#* commit;
COMMIT
-- T2
[local]:5432 postgres@testdb=#* commit;
ERROR: could not serialize access due to read/write dependencies among transactions
DETAIL: Reason code: Canceled on identification as a pivot, during commit attempt.
HINT: The transaction might succeed if retried.Time: 0.289 ms
SSI的实现原理,简单来说,PostgreSQL会在读操作时对读对象加SIReadLock(谓词锁),但该锁不会阻塞写也不会阻塞读仅用于判断是否会出现不可串行化的事务调度,通过该锁跟踪事务之间的冲突关系(rw依赖冲突),如侦测可能会出现环形结构导致不可串行化(如上例,T1 rw依赖 T2,T2 rw依赖 T1,形成环形),则终止其中一个事务。由于实现算法已超出本文的范畴,在此不再展开。
值得一提的是,如果数据表上没有索引,PostgreSQL会在整个relation上加SIReadLock,这意味着对relation的所有写操作事务之间只能串行执行,会极大降低系统并发。
|
时间点 |
T1 |
T2 |
|
t1 |
START TRANSACTION ISOLATION LEVEL SERIALIZABLE; |
|
|
t2 |
START TRANSACTION ISOLATION LEVEL SERIALIZABLE; |
|
|
t3 |
update tbl set c1 = 'x' where id = 1; |
|
|
t4 |
update tbl set c1 = 'x' where id = 50000; |
|
|
t5 |
commit; |
|
|
t6 |
commit;-- 报错 |
上例中的表tbl没有索引,有10万行数据,值为1和50000的tuple不在同一个page中,在t6时刻事务T2提交时会报错,虽然T1和T2之间的数据没有任何关系。
三、小结
本文简单介绍了PostgreSQL使用的MVCC多版本并发控制技术以及数据库提供四个事务隔离级别,并说明了PostgreSQL实现上与ANSI SQL标准的异同。
标签:事务,PostgreSQL,隔离,--,T2,T1,并发,testdb,t1 来源: https://www.cnblogs.com/ludongguoa/p/15334268.html