Linear and Quadratic Discriminant Function代码实现(python)
作者:互联网
文章首发及后续更新:https://mwhls.top/2053.html
新的更新内容请到mwhls.top查看。
无图/无目录/格式错误/更多相关请到上方的文章首发页面查看。
写在前面
- 本篇代码基于上一篇文章LDA与QDA分类数据的简单应用实现的。
- 之前是使用sklearn库,直接调用QDA与LDA函数,对四个数据集进行分类的。
- 本篇文章不再调用sklearn库,直接使用python内置的numpy与math库实现。
- QDF与QDA似乎一样的,公式一样,我根据QDF公式写的分类器,效果与sklearn的QDA也极其相似。
- 因此LDF与LDA也应该是一样的,但我写的时候,LDF分类器的效果会比LDA库有所差别,不知是否是我对公式的理解错误导致的,这点后续会说明。
- 即,本篇文章的QDF大致是没问题的,但LDF可能有参数错误,仅供参考,后续可能会根据这个点对本文修改。
- 本文提到的QDF、LDF全称为Quadratic Discriminant Function、Linear Discriminant Function。
- 本文提到的QDA、LDA全称为Quadratic Discriminant Analysis、Linear Discriminant Analysis。
- QDF与LDF表示根据QDF、LDF公式代码写出来的分类器。
- QDA与LDA表示sklearn库提供的分类器。
相关公式

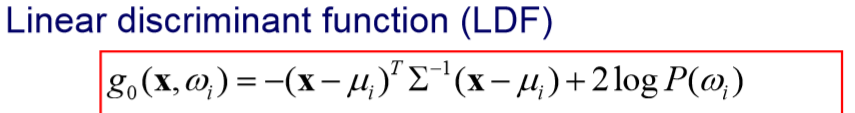
- 公式解释及示例参考:《模式识别导论》-齐敏、李大健、郝重阳编著-P92
数据集
| Dataset | #class | #feature | #train | #test |
| Letter | 26 | 16 | 16000 | 4000 |
| Opt-digits | 10 | 64 | 3823 | 1797 |
| Statlog-Satimage | 6 | 36 | 4435 | 2000 |
| Vowel | 11 | 10 | 528 | 462 |
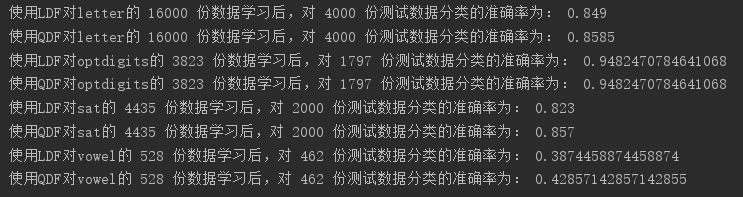
QDF/LDF与QDA/LDA对比
- 可以看出,QDF的效果与QDA效果相似。
- 注:optdigits数据集生成的协方差矩阵不可逆,导致QDF与LDF公式不适用。
- 对此,sklearn发出了警告,而本文的QDF与LDF使用伪逆解决了这个问题。
- 此外,矩阵不可逆还表示该矩阵的行列式为0,不能对其求对数,因此QDF公式的最后一项,用了LDF公式的最后一项,因此该数据集的QDF实际上是LDF实现的。
- 对于letter数据集,本文实现的LDF分类器比LDA分类器效果好,但对于vowel数据集,稍显劣势。
- 但在处理效率上,我写的和sklearn库差的不是一星半点。

难点及解决
- 公式的理解:
- 线性代数已经快忘光了,因此公式很难看懂,在讨论未果后,决定翻书。
- 在《模式识别导论》的第92页上找到了公式及例题。
- 并根据公式介绍及例题,推测了一下每项的含义,并利用python实现了出来。
- 在对QDF公式的实现时,与QDA的效果类似,但LDF与LDA有所不同。
- 可能是因为LDF最后一项的理解错误,我的代码将P(wi)解释成wi类在训练集发生的概率。
- 线性代数已经快忘光了,因此公式很难看懂,在讨论未果后,决定翻书。
- 实现公式:
- 基于面向过程的思想来实现公式,但分成多个函数后,函数间的参数传递比较麻烦。
- 主要因为开始的时候是直接将每项实现,但给的数据集实际上并不能直接传给函数。
- 因此设计了几个列表和字典作为桥梁,这里列出两个最重要的:
- sort_features{}:
- 键是类,值是按行保存特征的特征列表。
- 根据训练集的特征列表与类列表得出。
- 以类作为键,值为所有该类元素特征列表的列表。
- 因为后面使用的协方差与期望,传入参数是以特征数为行,以元素数为列,因此又对字典的键进行了转置。
- 返回该字典。
- param_list[]:
- [0]保存类,[1]保存特征列表的行列式,[2]保存特征列表的期望,[3]保存键是类,值是出现概率的字典。
- 这样,在对公式求解的时候,可以基于该列表获得不同类对应的参数。
- sort_features{}:
- 数据集不合适:
- 本次使用的optdigits数据集,其训练集生成的协方差矩阵是不可逆的,且行列式为0。
- 对此,在求协方差矩阵的逆时,改用了伪逆。
- 在因协方差矩阵行列式为0,而无法求其对数时,使用该类在训练集中出现概率的对数来代替。
- 即,在QDF分类器不使用的情况下,使用了LDF分类器来处理它。
- 本来是直接将该参数置0的,但后来觉得改用概率会更好,不过两者效果在optdigits数据集上效果一致。
代码
import numpy as np
import math
# 对letter数据集分类
def get_list_letter(char, features, path):
with open(path, 'r') as letter_train:
content_letter_train = letter_train.readlines()
for line in content_letter_train:
temp = line.split(',')
temp[-1] = list(temp[-1])[0]
char.append(temp[0])
features.append((temp[1::]))
# 对optdigits数据集分类
def get_list_optdigits(dig, features, path):
with open(path, 'r') as dig_train:
content_dig_train = dig_train.readlines()
for line in content_dig_train:
temp = line.split(',')
temp[-1] = list(temp[-1])[0]
dig.append(temp[-1])
features.append((temp[0:len(temp)-1:]))
# 对sat数据集分类
def get_list_sat(sat, features, path):
with open(path, 'r') as sat_train:
content_sat_train = sat_train.readlines()
for line in content_sat_train:
temp = line.split(' ')
temp[-1] = list(temp[-1])[0]
sat.append(temp[-1])
features.append((temp[0:len(temp)-1:]))
# 对vowel数据集分类
def get_list_vowel(vowel, features, path):
with open(path, 'r') as vowel_train:
content_vowel_train = vowel_train.readlines()
for line in content_vowel_train:
temp = line.split()
temp[-1] = list(temp[-1])[0]
vowel.append(temp[-1])
features.append((temp[3:len(temp)-1:]))
# 列表字符串元素转浮点型
def convert_float(str_list):
for row in range(0, len(str_list)):
for col in range(0, len(str_list[row])):
str_list[row][col] = float(str_list[row][col])
# 列表字符串元素转整型
def convert_int(str_list):
for row in range(0, len(str_list)):
for col in range(0, len(str_list[row])):
str_list[row][col] = int(str_list[row][col])
# 求期望
def get_expectation(features):
expectation = [0] * len(features)
for row in range(0, len(features)):
for col in range(0, len(features[0])):
expectation[row] += features[row][col]
for pos in range(0, len(expectation)):
expectation[pos] = expectation[pos] / len(features[0])
return expectation
# train_features_sort_by_class_with_same_feature:
# 将训练集的特征列表,按类保存成字典,即,键是类,值是特征列表的列表
# sort_features{}: { class, features_list[] }, 保存每个类对应的特征列表的列表,字典
# class: 类
# features_list[]: [ feature_list[] ], 保存所有特征列表,每个元素均是列表
# 注意,这里字典里保存的不再是特征列表的列表,而是特征的列表,即原本按类来排序的特征列表的列表,被转置了。
# 这样方便后续的求协方差。
def train_features_sort_by_class_with_same_feature(train_features, train_class):
sort_features = {}
for pos in range(0, len(train_class)):
if train_class[pos] not in sort_features:
sort_features[train_class[pos]] = []
sort_features[train_class[pos]].append(train_features[pos])
for clas in sort_features:
sort_features[clas] = np.array(sort_features[clas]).T
return sort_features
# get_param: 根据训练集特征与类,得到对应QDF的参数列表
# param_list[] : [ class[], cov[][][], expectation[][] ], 保存class对应的协方差矩阵cov与期望expectation
# class: 类别
# cov[][]: 由训练集特征得到的协方差矩阵
# expectation[]: 特征期望
def get_param(sort_features, train_class):
param_list = [[], [], []]
for clas in sort_features:
param_list[0].append(clas)
param_list[1].append(np.cov(sort_features[clas]))
param_list[2].append(np.array(get_expectation(sort_features[clas])))
param_list.append(get_char_probability(train_class))
return param_list
# 得到训练集中各类出现的可能性,返回可能性字典,键是类,值是可能性
def get_char_probability(train_class):
char_probability = {}
for chr in train_class:
if chr not in char_probability:
char_probability[chr] = 0
char_probability[chr] += 1
for chr in char_probability:
char_probability[chr] = char_probability[chr] / len(train_class)
return char_probability
# 以method方法预测test_features可能的类别,返回其类别
def predict(test_features, param_list, method):
max_probability = 0
max_char = ''
for pos in range(0, len(param_list[0])):
clas = param_list[0][pos]
cov = param_list[1][pos]
expectation = param_list[2][pos]
cov_det = np.linalg.det(cov)
ele1 = test_features - expectation
if cov_det == 0:
# 协方差矩阵不可逆,使用伪逆
ele2 = np.linalg.pinv(cov)
cov_reversible = False
else:
# 协方差矩阵可逆
ele2 = np.linalg.inv(cov)
cov_reversible = True
ele3 = ele1.T
if method == 'QDF':
if cov_reversible:
ele4 = - math.log(cov_det)
else:
ele4 = math.log(param_list[3][clas]) * 2
elif method == 'LDF':
ele4 = math.log(param_list[3][clas]) * 2
probability = np.matmul(ele1, ele2)
probability = np.matmul(probability, ele3)
probability = - probability + ele4
if probability > max_probability or max_char == '':
max_probability = probability
max_char = clas
return max_char
# 使用method方法对训练集进行训练,并测试测试集,返回每个测试特征可能的类别
def train_and_predict(train_features, train_class, test_features, method):
predict_class = []
sort_features = train_features_sort_by_class_with_same_feature(train_features, train_class)
param = get_param(sort_features, train_class)
for pos in range(0, len(test_features)):
predict_class.append(predict(test_features[pos], param, method))
return predict_class
# 分析方法精确度,返回精确度
def analysis_accuracy(judge_result, test_char):
sum = 0
right_num = 0
for pos in range(0, len(judge_result)):
sum += 1
if judge_result[pos] == test_char[pos]:
right_num += 1
return right_num / sum
# letter数据集初始化
letter_train_path = './dataset/letter.train'
letter_train_class = []
letter_train_features = []
letter_test_path = './dataset/letter.test'
letter_test_class = []
letter_test_features = []
get_list_letter(letter_train_class, letter_train_features, letter_train_path)
get_list_letter(letter_test_class, letter_test_features, letter_test_path)
convert_int(letter_train_features)
convert_int(letter_test_features)
# letter数据集训练及测试
letter_LDF_predict = train_and_predict(letter_train_features, letter_train_class, letter_test_features, 'LDF')
letter_LDF_accuracy = analysis_accuracy(letter_LDF_predict, letter_test_class)
print('使用LDF对letter的', len(letter_train_features), '份数据学习后,对',
len(letter_test_features), '份测试数据分类的准确率为:', letter_LDF_accuracy)
letter_QDF_predict = train_and_predict(letter_train_features, letter_train_class, letter_test_features, 'QDF')
letter_QDF_accuracy = analysis_accuracy(letter_QDF_predict, letter_test_class)
print('使用QDF对letter的', len(letter_train_features), '份数据学习后,对',
len(letter_test_features), '份测试数据分类的准确率为:', letter_QDF_accuracy)
# optdigits数据集初始化
optdigits_train_path = './dataset/optdigits.train'
optdigits_train_class = []
optdigits_train_features = []
optdigits_test_path = './dataset/optdigits.test'
optdigits_test_class = []
optdigits_test_features = []
get_list_optdigits(optdigits_train_class, optdigits_train_features, optdigits_train_path)
convert_int(optdigits_train_features)
get_list_optdigits(optdigits_test_class, optdigits_test_features, optdigits_test_path)
convert_int(optdigits_test_features)
# optdigits数据集训练及测试
optdigits_LDF_predict = train_and_predict(optdigits_train_features, optdigits_train_class, optdigits_test_features, 'LDF')
optdigits_LDF_accuracy = analysis_accuracy(optdigits_LDF_predict, optdigits_test_class)
print('使用LDF对optdigits的', len(optdigits_train_features), '份数据学习后,对',
len(optdigits_test_features), '份测试数据分类的准确率为:', optdigits_LDF_accuracy)
optdigits_QDF_predict = train_and_predict(optdigits_train_features, optdigits_train_class, optdigits_test_features, 'QDF')
optdigits_QDF_accuracy = analysis_accuracy(optdigits_QDF_predict, optdigits_test_class)
print('使用QDF对optdigits的', len(optdigits_train_features), '份数据学习后,对',
len(optdigits_test_features), '份测试数据分类的准确率为:', optdigits_QDF_accuracy)
# sat数据集初始化
sat_train_path = './dataset/sat.train'
sat_train_class = []
sat_train_features = []
sat_test_path = './dataset/sat.test'
sat_test_class = []
sat_test_features = []
get_list_sat(sat_train_class, sat_train_features, sat_train_path)
convert_int(sat_train_features)
get_list_sat(sat_test_class, sat_test_features, sat_test_path)
convert_int(sat_test_features)
# sat数据集训练及测试
sat_LDF_predict = train_and_predict(sat_train_features, sat_train_class, sat_test_features, 'LDF')
sat_LDF_accuracy = analysis_accuracy(sat_LDF_predict, sat_test_class)
print('使用LDF对sat的', len(sat_train_features), '份数据学习后,对',
len(sat_test_features), '份测试数据分类的准确率为:', sat_LDF_accuracy)
sat_QDF_predict = train_and_predict(sat_train_features, sat_train_class, sat_test_features, 'QDF')
sat_QDF_accuracy = analysis_accuracy(sat_QDF_predict, sat_test_class)
print('使用QDF对sat的', len(sat_train_features), '份数据学习后,对',
len(sat_test_features), '份测试数据分类的准确率为:', sat_QDF_accuracy)
# vowel数据集初始化
vowel_train_path = './dataset/vowel.train'
vowel_train_class = []
vowel_train_features = []
vowel_test_path = './dataset/vowel.test'
vowel_test_class = []
vowel_test_features = []
get_list_vowel(vowel_train_class, vowel_train_features, vowel_train_path)
convert_float(vowel_train_features)
get_list_vowel(vowel_test_class, vowel_test_features, vowel_test_path)
convert_float(vowel_test_features)
# vowel数据集训练及测试
vowel_LDF_predict = train_and_predict(vowel_train_features, vowel_train_class, vowel_test_features, 'LDF')
vowel_LDF_accuracy = analysis_accuracy(vowel_LDF_predict, vowel_test_class)
print('使用LDF对vowel的', len(vowel_train_features), '份数据学习后,对',
len(vowel_test_features), '份测试数据分类的准确率为:', vowel_LDF_accuracy)
vowel_QDF_predict = train_and_predict(vowel_train_features, vowel_train_class, vowel_test_features, 'QDF')
vowel_QDF_accuracy = analysis_accuracy(vowel_QDF_predict, vowel_test_class)
print('使用QDF对vowel的', len(vowel_train_features), '份数据学习后,对',
len(vowel_test_features), '份测试数据分类的准确率为:', vowel_QDF_accuracy)
标签:Function,features,Discriminant,train,vowel,test,sat,class,Linear 来源: https://blog.csdn.net/asd123pwj/article/details/115603897