PPO(Proximal Policy Optimization)近端策略优化算法
作者:互联网
强化学习可以按照方法学习策略来划分成基于值和基于策略两种。而在深度强化学习领域将深度学习与基于值的Q-Learning算法相结合产生了DQN算法,通过经验回放池与目标网络成功的将深度学习算法引入了强化学习算法。其中最具代表性分别是Q-Learning与Policy Gradient算法,将Q-Learning算法与深度学习相结合产生了Deep Q Network,而后又出现了将两种方式的优势结合在一起的更为优秀Actor Critic,DPG, DDPG,A3C,TRPO,PPO等算法。而本文所采用的是目前效果较好的近端策略优化算法PPO。
PPO算法思想
PPO算法是一种新型的Policy Gradient算法,Policy Gradient算法对步长十分敏感,但是又难以选择合适的步长,在训练过程中新旧策略的的变化差异如果过大则不利于学习。PPO提出了新的目标函数可以再多个训练步骤实现小批量的更新,解决了Policy Gradient算法中步长难以确定的问题。其实TRPO也是为了解决这个思想但是相比于TRPO算法PPO算法更容易求解。
PolicyGradient回顾
重新回顾一下PolicyGradient算法,Policy Gradient不通过误差反向传播,它通过观测信息选出一个行为直接进行反向传播,当然出人意料的是他并没有误差,而是利用reward奖励直接对选择行为的可能性进行增强和减弱,好的行为会被增加下一次被选中的概率,不好的行为会被减弱下次被选中的概率。
策略如下图方式定义,详细公式信息接下来会介绍。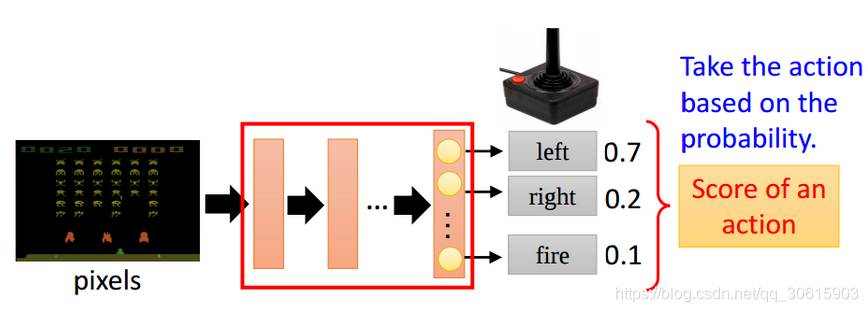
公式推导
PolicyGradient算法原来是On-Policy的,(感谢指正,更正:PPO也是on-policy)。
important sampling不能算是off-policy,PPO里面的 important sampling
采样的过程仍然是在同一个策略生成的样本,并未使用其他策略产生的样本,因此它是on-policy的。而DDPG这种使用其他策略产生的数据来更新另一个策略的方式才是off-policy
- On-Policy:只与相同的环境下进行交互学习
- off-Policy:可以与学习自己环境下的经验也可以获得其他环境下的经验
策略τ的回报期望如下
![]()
原来是使用 ![]() 与环境交互,当
与环境交互,当 ![]() 更新时就对训练数据重新采样,那要变成off-policy根据之前的经验就需要使用另外一个网络来帮助采样,就像DQN里的targetNet,现在目标是使用
更新时就对训练数据重新采样,那要变成off-policy根据之前的经验就需要使用另外一个网络来帮助采样,就像DQN里的targetNet,现在目标是使用![]() 采样来训练
采样来训练![]() 被固定所以重新使用采样数据。
被固定所以重新使用采样数据。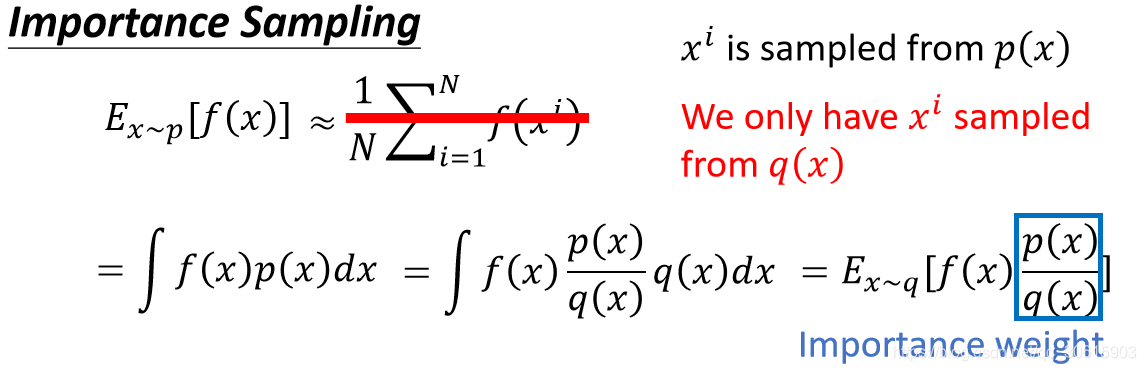
上图中所示,PolicyGradient是model-free的所以不知道模型的概率,所以只能通过与真实环境数据的分布P(x)中去采样加和平均求期望。但现在我们为了把它变成offpolicy,就不能直接从P(x)中去直接采样。这时候把期望等价写成![]() 然后引入新的采样分布q(x)进行变换
然后引入新的采样分布q(x)进行变换 ![]() ,这时候我们发现这和最大熵模型引入隐含变量的套路有点相似,然后就可以把原来x~p的期望改写成x~q的期望。所以最终可以得到
,这时候我们发现这和最大熵模型引入隐含变量的套路有点相似,然后就可以把原来x~p的期望改写成x~q的期望。所以最终可以得到
![]()
上述推导就是important sample的技巧。在这个式子中其中的![]() 就是important weight。通过这个公式我们也可以想象得到,如果采样的分布p与真实的分布q差得很多,那么肯定会导致两个期望不一致。下图通过举了一个例子来讲解
就是important weight。通过这个公式我们也可以想象得到,如果采样的分布p与真实的分布q差得很多,那么肯定会导致两个期望不一致。下图通过举了一个例子来讲解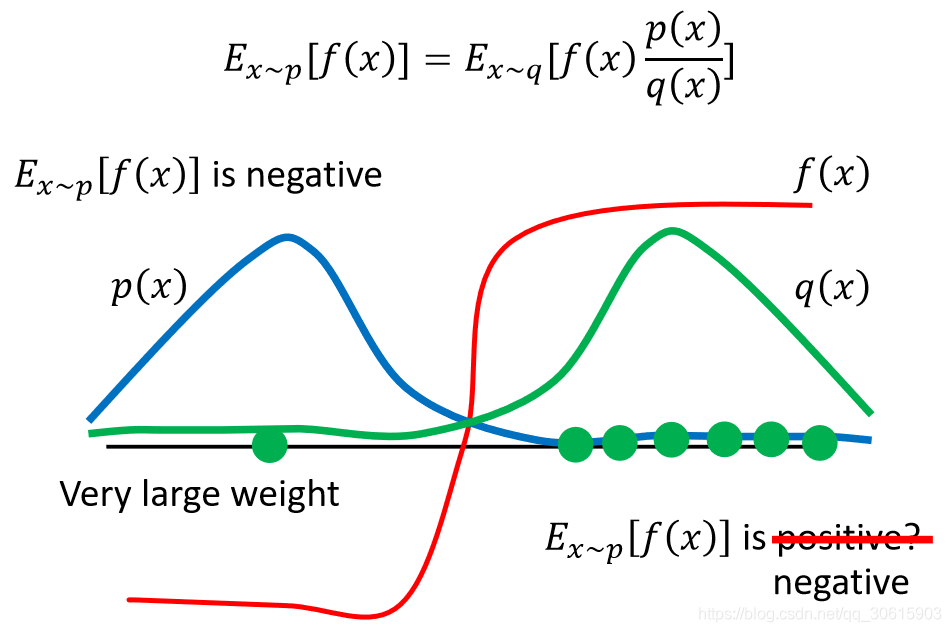
上图的p(x)与q(x)差异很大左边为负右边为正,当采样次数很少右边采样很多的情况,就会得出与右边为正的错误结果,但是如果在左边也被采样到一个样本时这个这个时候因为![]() 作为权重修正就相当于给左边的样本一个很大的权重,就可以将结果修正为负的。所以这就是 important weight的作用。但是我们也能看出来,采样次数要足够多,万一采样次数少只采到了一边那就凉凉了。
作为权重修正就相当于给左边的样本一个很大的权重,就可以将结果修正为负的。所以这就是 important weight的作用。但是我们也能看出来,采样次数要足够多,万一采样次数少只采到了一边那就凉凉了。
所以有了上述的 Important Sampling的技巧我们就可以将原来的on-policy变成off-policy了。
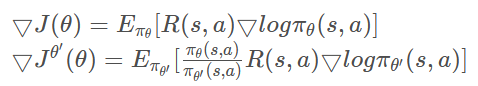
上文提到我们不希望![]() 与
与![]() 的差距过大,所以要想办法约束它。KL散度也叫相对熵,可以用来衡量两个分布之间的差异性。所以最直接的办法,就是对目标函数增加一个约束条件让他的KL散度小于
的差距过大,所以要想办法约束它。KL散度也叫相对熵,可以用来衡量两个分布之间的差异性。所以最直接的办法,就是对目标函数增加一个约束条件让他的KL散度小于![]() 。这个办法其实就TRPO的思想啦~
。这个办法其实就TRPO的思想啦~
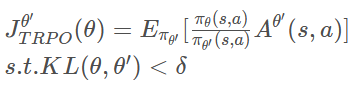
直接求解TRPO这种带约束的问题是十分复杂的,他与PPO算法的效果差不多,但是PPO将KL散度作为惩罚项,更加容易求解。
![]()
另外还有一种PPO2算法效果比PPO要好一些,如下图所示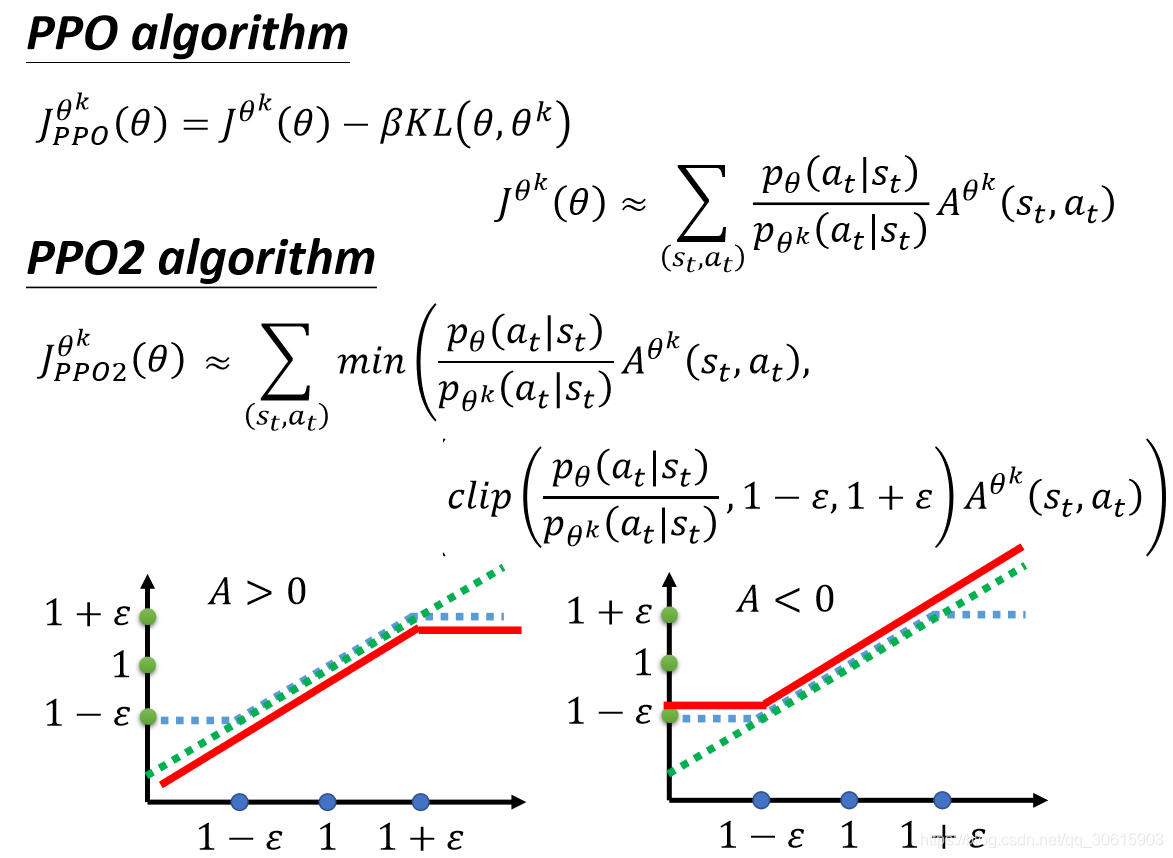 利用clip函数将其固定在了一定的范围之内,同样也可以起到限制约束
利用clip函数将其固定在了一定的范围之内,同样也可以起到限制约束![]() 的作用。
的作用。
承接Matlab、Python和C++的编程,机器学习、计算机视觉的理论实现及辅导,本科和硕士的均可,咸鱼交易,专业回答请走知乎,详谈请联系QQ号757160542,非诚勿扰。
本文同步分享在 博客“于小勇”(CSDN)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
标签:采样,Gradient,PPO,policy,算法,Optimization,Proximal,Policy 来源: https://www.cnblogs.com/0591jb/p/14326979.html