Python字符串模糊匹配库FuzzyWuzzy
作者:互联网
Python字符串模糊匹配库FuzzyWuzzy
在计算机科学中,字符串模糊匹配(fuzzy string matching)是一种近似地(而不是精确地)查找与模式匹配的字符串的技术。换句话说,字符串模糊匹配是一种搜索,即使用户拼错单词或只输入部分单词进行搜索,也能够找到匹配项。因此,它也被称为字符串近似匹配。
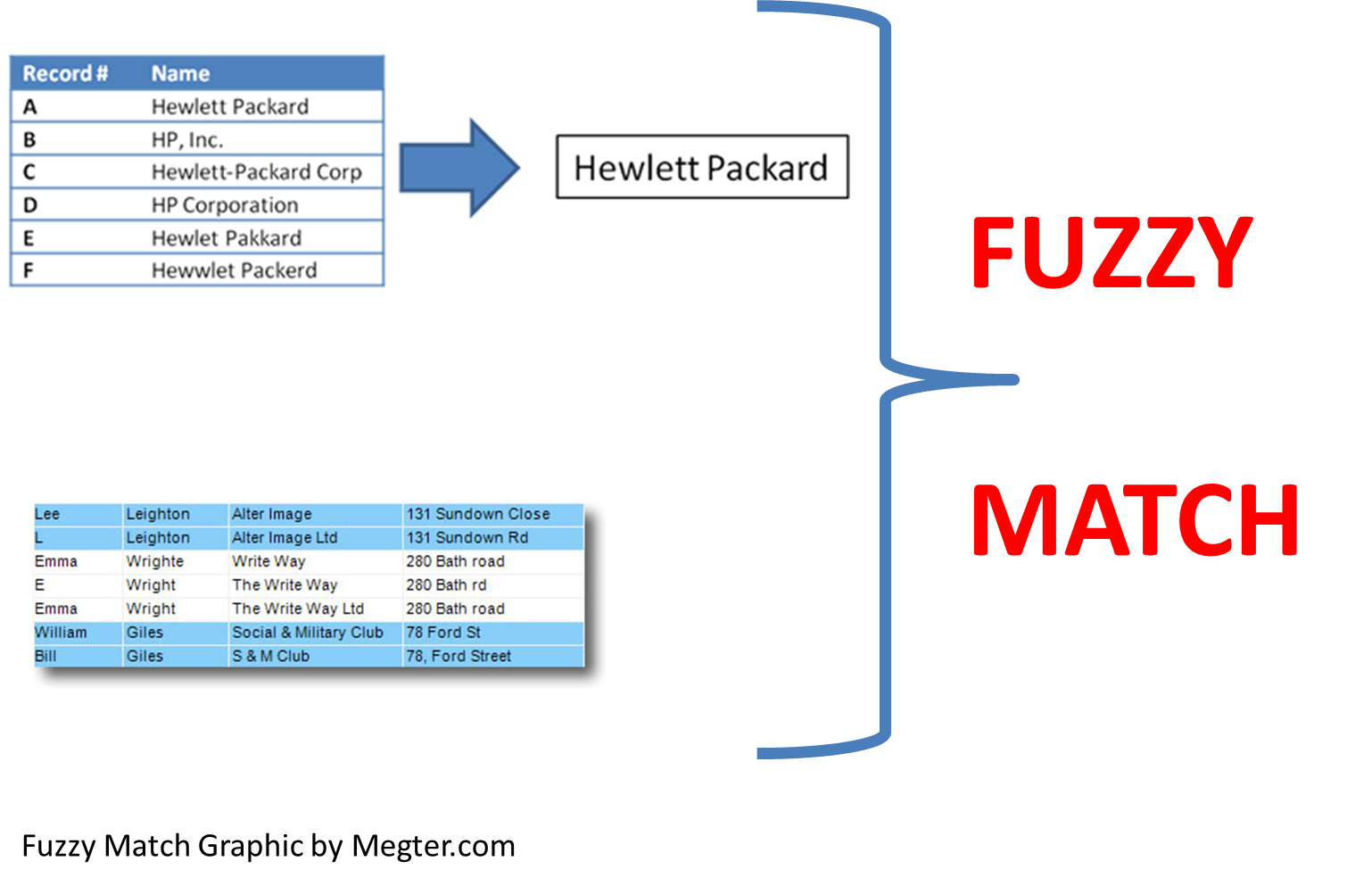
字符串模糊搜索可用于各种应用程序,例如:
- 拼写检查和拼写错误纠正程序。例如,用户在Google中键入“Missisaga”,将返回文字为“Showing results for mississauga”的点击列表。也就是说,即使用户输入缺少字符、有多余的字符或者有其他类型的拼写错误,搜索查询也会返回结果。
- 重复记录检查。例如,由于名称拼写不同(例如Abigail Martin和Abigail Martinez)在数据库中被多次列出。
这篇文章将解释字符串模糊匹配及其用例,并使用Python中Fuzzywuzzy库给出示例。
使用FuzzyWuzzy合并酒店房型
每个酒店都有自己的命名方法来命名它的房间,在线旅行社(OTA)也是如此。例如,同一家酒店的一间客房Expedia将之称为“Studio, 1 King Bed with Sofa Bed, Corner”,Booking.com(缤客)则简单地将其显示为“Corner King Studio”。不能说有谁错了,但是当我们想要比较OTA之间的房价时,或者一个OTA希望确保另一个OTA遵循费率平价协议时(rate parity agreement),这可能会导致混乱。换句话说,为了能够比较价格,我们必须确保我们进行比较的东西是同一类型的。对于价格比较网站和应用程序来说,最令人头条的问题之一就是试图弄清楚两个项目(比如酒店房间)是否是同一事物。
Fuzzywuzzy是一个Python库,使用编辑距离(Levenshtein Distance)来计算序列之间的差异。为了演示,我创建了自己的数据集,也就是说,对于同一酒店物业,我从Expedia拿一个房间类型,比如说“Suite, 1 King Bed (Parlor)”,然后我将它与Booking.com中的同类型房间匹配,即“King Parlor Suite”。只要有一点经验,大多数人都会知道他们是一样的。按照这种方法,我创建了一个包含100多对房间类型的小数据集,可以访问Github下载。
我们使用这个数据集测试Fuzzywuzzy的做法。换句话说,我们使用Fuzzywuzzy来匹配两个数据源之间的记录。
import pandas as pd df = pd. read_csv ( '../input/room_type.csv' ) df. head ( 10 ) import pandas as pddf = pd.read_csv(’…/input/room_type.csv’)
df.head(10)
import pandas as pd
df = pd.read_csv(’…/input/room_type.csv’)
df.head(10)
有几种方法可以比较Fuzzywuzzy中的两个字符串,让我们一个一个地进行尝试。
ratio ,按顺序比较整个字符串的相似度
from fuzzywuzzy import fuzz fuzz. ratio ( 'Deluxe Room, 1 King Bed' , 'Deluxe King Room' ) from fuzzywuzzy import fuzzfuzz.ratio(‘Deluxe Room, 1 King Bed’, ‘Deluxe King Room’)
from fuzzywuzzy import fuzz
fuzz.ratio(‘Deluxe Room, 1 King Bed’, ‘Deluxe King Room’)
返回结果时62,它告诉我们“Deluxe Room, 1 King Bed”和“Deluxe King Room”的相似度约62%。
fuzz. ratio ( 'Traditional Double Room, 2 Double Beds' , 'Double Room with Two Double Beds' ) fuzz. ratio ( 'Room, 2 Double Beds (19th to 25th Floors)' , 'Two Double Beds - Location Room (19th to 25th Floors)' ) fuzz.ratio('Traditional Double Room, 2 Double Beds','Double Room with Two Double Beds') fuzz.ratio('Room, 2 Double Beds (19th to 25th Floors)','Two Double Beds - Location Room (19th to 25th Floors)')fuzz.ratio('Traditional Double Room, 2 Double Beds','Double Room with Two Double Beds')
fuzz.ratio('Room, 2 Double Beds (19th to 25th Floors)','Two Double Beds - Location Room (19th to 25th Floors)')
“Traditional Double Room, 2 Double Beds”和“Double Room with Two Double Beds”的相似度约69%。“Room, 2 Double Beds (19th to 25th Floors)”和“Two Double Beds — Location Room (19th to 25th Floors)”相似度约74%。显然效果不怎么样。事实证明,简单的方法对于词序,缺失或多余词语以及其他类似问题的微小差异太过敏感。
partial_ratio,比较部分字符串的相似度
我们仍在使用相同的数据对:
fuzz. partial_ratio ( 'Deluxe Room, 1 King Bed' , 'Deluxe King Room' ) fuzz. partial_ratio ( 'Traditional Double Room, 2 Double Beds' , 'Double Room with Two Double Beds' ) fuzz. partial_ratio ( 'Room, 2 Double Beds (19th to 25th Floors)' , 'Two Double Beds - Location Room (19th to 25th Floors)' ) fuzz.partial_ratio('Deluxe Room, 1 King Bed','Deluxe King Room') fuzz.partial_ratio('Traditional Double Room, 2 Double Beds','Double Room with Two Double Beds') fuzz.partial_ratio('Room, 2 Double Beds (19th to 25th Floors)','Two Double Beds - Location Room (19th to 25th Floors)')fuzz.partial_ratio('Deluxe Room, 1 King Bed','Deluxe King Room')
fuzz.partial_ratio('Traditional Double Room, 2 Double Beds','Double Room with Two Double Beds')
fuzz.partial_ratio('Room, 2 Double Beds (19th to 25th Floors)','Two Double Beds - Location Room (19th to 25th Floors)')
返回依次69、83、63。对于我的数据集来说,比较部分字符串并不能带来更好的整体效果。让我们尝试下一个。
token_sort_ratio,忽略单词顺序
fuzz. token_sort_ratio ( 'Deluxe Room, 1 King Bed' , 'Deluxe King Room' ) fuzz. token_sort_ratio ( 'Traditional Double Room, 2 Double Beds' , 'Double Room with Two Double Beds' ) fuzz. token_sort_ratio ( 'Room, 2 Double Beds (19th to 25th Floors)' , 'Two Double Beds - Location Room (19th to 25th Floors)' ) fuzz.token_sort_ratio('Deluxe Room, 1 King Bed','Deluxe King Room') fuzz.token_sort_ratio('Traditional Double Room, 2 Double Beds','Double Room with Two Double Beds') fuzz.token_sort_ratio('Room, 2 Double Beds (19th to 25th Floors)','Two Double Beds - Location Room (19th to 25th Floors)')fuzz.token_sort_ratio('Deluxe Room, 1 King Bed','Deluxe King Room')
fuzz.token_sort_ratio('Traditional Double Room, 2 Double Beds','Double Room with Two Double Beds')
fuzz.token_sort_ratio('Room, 2 Double Beds (19th to 25th Floors)','Two Double Beds - Location Room (19th to 25th Floors)')
返回依次84、78、83。这是迄今为止最好的。
token_set_ratio,去重子集匹配
它与token_sort_ratio类似,但更加灵活。
fuzz. token_set_ratio ( 'Deluxe Room, 1 King Bed' , 'Deluxe King Room' ) fuzz. token_set_ratio ( 'Traditional Double Room, 2 Double Beds' , 'Double Room with Two Double Beds' ) fuzz. token_set_ratio ( 'Room, 2 Double Beds (19th to 25th Floors)' , 'Two Double Beds - Location Room (19th to 25th Floors)' ) fuzz.token_set_ratio('Deluxe Room, 1 King Bed','Deluxe King Room') fuzz.token_set_ratio('Traditional Double Room, 2 Double Beds','Double Room with Two Double Beds') fuzz.token_set_ratio('Room, 2 Double Beds (19th to 25th Floors)','Two Double Beds - Location Room (19th to 25th Floors)')fuzz.token_set_ratio('Deluxe Room, 1 King Bed','Deluxe King Room')
fuzz.token_set_ratio('Traditional Double Room, 2 Double Beds','Double Room with Two Double Beds')
fuzz.token_set_ratio('Room, 2 Double Beds (19th to 25th Floors)','Two Double Beds - Location Room (19th to 25th Floors)')
返回依次100、78、97。看来token_set_ratio最适合我的数据。根据这一发现,将token_set_ratio应用到整个数据集。
def get_ratio ( row ) : name1 = row [ 'Expedia' ] name2 = row [ 'Booking.com' ] return fuzz. token_set_ratio ( name1, name2 ) rated = df. apply ( get_ratio, axis= 1 ) rated. head ( 10 ) greater_than_70_percent = df [ rated > 70 ] greater_than_70_percent. count () len ( greater_than_70_percent ) / len ( df ) def get_ratio(row): name1 = row['Expedia'] name2 = row['Booking.com'] return fuzz.token_set_ratio(name1, name2)rated = df.apply(get_ratio, axis=1)
rated.head(10)
greater_than_70_percent = df[rated > 70]
greater_than_70_percent.count()
len(greater_than_70_percent) / len(df)
def get_ratio(row):
name1 = row[‘Expedia’]
name2 = row[‘Booking.com’]
return fuzz.token_set_ratio(name1, name2)
rated = df.apply(get_ratio, axis=1)
rated.head(10)
greater_than_70_percent = df[rated > 70]
greater_than_70_percent.count()
len(greater_than_70_percent) / len(df)
当设定相似度> 70时,超过90%的房间对超过这个匹配分数。还很不错!上面只是做了2个文本间的相似度比较,如果存在多个如何处理?可以使用库中提供的 Process类:
用来返回模糊匹配的字符串和相似度。
>>> choices = ["Atlanta Falcons", "New York Jets", "New York Giants", "Dallas Cowboys"] >>> process.extract("new york jets", choices, limit=2) [('New York Jets', 100), ('New York Giants', 78)] >>> process.extractOne("cowboys", choices) ("Dallas Cowboys", 90) >>> choices = ["Atlanta Falcons", "New York Jets", "New York Giants", "Dallas Cowboys"] >>> process.extract("new york jets", choices, limit=2) [('New York Jets', 100), ('New York Giants', 78)] >>> process.extractOne("cowboys", choices) ("Dallas Cowboys", 90)>>> choices = ["Atlanta Falcons", "New York Jets", "New York Giants", "Dallas Cowboys"]
>>> process.extract("new york jets", choices, limit=2)
[('New York Jets', 100), ('New York Giants', 78)]
>>> process.extractOne("cowboys", choices)
("Dallas Cowboys", 90)
FuzzyWuzzy在中文场景下的使用
FuzzyWuzzy支持对中文进行比较:
from fuzzywuzzy import fuzz from fuzzywuzzy import process print ( fuzz. ratio ( "数据挖掘" , "数据挖掘工程师" )) title_list = [ "数据分析师" , "数据挖掘工程师" , "大数据开发工程师" , "机器学习工程师" , "算法工程师" , "数据库管理" , "商业分析师" , "数据科学家" , "首席数据官" , "数据产品经理" , "数据运营" , "大数据架构师" ] print ( process. extractOne ( "数据挖掘" , title_list )) from fuzzywuzzy import fuzz from fuzzywuzzy import processprint(fuzz.ratio(“数据挖掘”, “数据挖掘工程师”))
title_list = [“数据分析师”, “数据挖掘工程师”, “大数据开发工程师”, “机器学习工程师”,
“算法工程师”, “数据库管理”, “商业分析师”, “数据科学家”, “首席数据官”,
“数据产品经理”, “数据运营”, “大数据架构师”]
print(process.extractOne(“数据挖掘”, title_list))
from fuzzywuzzy import fuzz
from fuzzywuzzy import process
print(fuzz.ratio(“数据挖掘”, “数据挖掘工程师”))
title_list = [“数据分析师”, “数据挖掘工程师”, “大数据开发工程师”, “机器学习工程师”,
“算法工程师”, “数据库管理”, “商业分析师”, “数据科学家”, “首席数据官”,
“数据产品经理”, “数据运营”, “大数据架构师”]
print(process.extractOne(“数据挖掘”, title_list))
仔细查看代码,还是存在的问题:
- FuzzWuzzy并不会针对中文进行分词
- 也没有对中文的一些停用词进行过滤
改进方案,处理前进行中文处理:
- 繁简转换
- 中文分词
- 去除停用词
参考链接:
- https://github.com/seatgeek/fuzzywuzzy
- https://www.kaggle.com/leandrodoze/fuzzy-string-matching-with-hotel-rooms
相关文章:
python标签:King,FuzzyWuzzy,ratio,Room,Python,Double,Beds,fuzz,字符串 来源: https://blog.csdn.net/stay_foolish12/article/details/113109000