K-means算法的改进:K-means++
作者:互联网
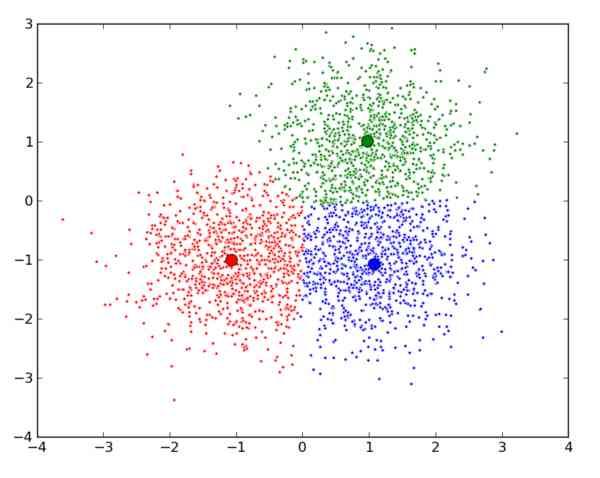
由于 K-means 算法的分类结果会受到初始点的选取而有所区别,因此有提出这种算法的改进: K-means++ 。
算法步骤
其实这个算法也只是对初始点的选择有改进而已,其他步骤都一样。初始质心选取的基本思路就是,初始的聚类中心之间的相互距离要尽可能的远。
算法描述如下:
- 步骤一:随机选取一个样本作为第一个聚类中心 c1;
- 步骤二:计算每个样本与当前已有类聚中心最短距离(即与最近一个聚类中心的距离),用
D(x)表示;这个值越大,表示被选取作为聚类中心的概率较大;最后,用轮盘法选出下一个聚类中心; - 步骤三:重复步骤二,知道选出 k 个聚类中心。
选出初始点后,就继续使用标准的 k-means 算法了。
效率
K-means++ 能显著的改善分类结果的最终误差。尽管计算初始点时花费了额外的时间,但是在迭代过程中,k-mean 本身能快速收敛,因此算法实际上降低了计算时间。网上有人使用真实和合成的数据集测试了他们的方法,速度通常提高了 2 倍,对于某些数据集,误差提高了近 1000 倍。
python实现
这里只说明初始点筛选的代码,因为其他步骤和k-means 一样,不再累赘:
# coding: utf-8
import math
import random
from sklearn import datasets
def euler_distance(point1: list, point2: list) -> float:
"""
计算两点之间的欧拉距离,支持多维
"""
distance = 0.0
for a, b in zip(point1, point2):
distance += math.pow(a - b, 2)
return math.sqrt(distance)
def get_closest_dist(point, centroids):
min_dist = math.inf # 初始设为无穷大
for i, centroid in enumerate(centroids):
dist = euler_distance(centroid, point)
if dist < min_dist:
min_dist = dist
return min_dist
def kpp_centers(data_set: list, k: int) -> list:
"""
从数据集中返回 k 个对象可作为质心
"""
cluster_centers = []
cluster_centers.append(random.choice(data_set))
d = [0 for _ in range(len(data_set))]
for _ in range(1, k):
total = 0.0
for i, point in enumerate(data_set):
d[i] = get_closest_dist(point, cluster_centers) # 与最近一个聚类中心的距离
total += d[i]
total *= random.random()
for i, di in enumerate(d): # 轮盘法选出下一个聚类中心;
total -= di
if total > 0:
continue
cluster_centers.append(data_set[i])
break
return cluster_centers
if __name__ == "__main__":
iris = datasets.load_iris()
print(kpp_centers(iris.data, 4))
标签:dist,means,++,算法,聚类,data,centers 来源: https://www.cnblogs.com/ai-ldj/p/14296138.html