天猫召回推荐算法MIND模型——基于动态路由的用户多兴趣网络详解
作者:互联网
天猫召回推荐算法MIND模型——基于动态路由的用户多兴趣网络详解
创新点:
1、采用动态路由的机制来挖掘用户的多层次兴趣,丰富对于用户兴趣的表达
2、对于不同的用户兴趣采用label-aware attention layer来归纳兴趣的偏好
一、背景
在大规模推荐系统中,无论是在召回阶段还是在Rank阶段,对于用户兴趣的建模是很有必要的。搜索、推荐和广告最为核心的就是精准的捕捉用户的兴趣,为用户推荐他们真正感兴趣的内容(广告也是同理,需要将最优质的广告内容推荐给真正对其感兴趣的目标群体)。从用户历史的一些行为兴趣当中能够有效的获取用户的兴趣,而如何对用户行为兴趣进行有效的建模是非常值得思考的。本文对于单个用户采用多个向量表征其行为特征(label-aware attention);在召回阶段提出MIND模型来捕捉用户不同方面的兴趣(capsule routing)。
二、MIND模型详解
1、MIND核心问题
推荐系统召回模块的核心任务是从数以亿计的全量商品库中筛选出一部分用户感兴趣的候选集(数量远小于全部数据),线上系统通常会将请求的相关信息存储到日志中,日志中的每条样本主要包括以下的一些基本信息,(1)与用户产生交互的商品信息(2)用户本身的一些信息(如用户年龄、性别等)(3)目标商品的相关信息(如商品类别、商品id等)。MIND模型的核心任务就是学习一个映射函数,该函数将将原始的特征映射为用户表征向量,数学表述如下
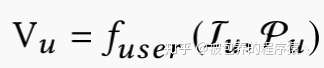
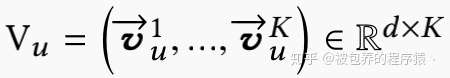
其中d为表征向量维度,K为表征向量的个数,当K为1的时候,就类似于YouTube的那篇论文一样。而同时也需要一个对商品进行映射的函数,具体如下
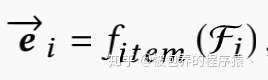
这里ei同样是一个d为的向量,这里只用一个向量来表征商品信息,因为商品信息相较于用户兴趣来说比较固定,所以单个向量足以表征商品的信息。当通过模型得到了用户的embedding向量和商品的embedding向量之后,通过如下的分数来求得topN形成所谓的候选集
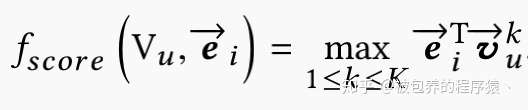
整个MIND模型的系统结构如下图所示
整个系统的流程大致如下:MIND模型的输入为用户相关的特征,输出是多个用户表征向量,主要用于召回阶段使用。输入的特征主要包括三部分,即用户自身相关特征、用户行为特征(如浏览过的商品id)和label特征。所有的id类特征都经过Embedding层,其中对于用户行为特征对应的Embedding向量进行average pooling操作,然后将用户行为Embedidng向量传递给Multi-Interest Extract layer(生成interest capsules),将生成的interest capsules与用户本身的Embedding concate起来经过几层全连接网络,就得到了多个用户表征向量,在模型的最后有一个label-aware attention层。在线上使用的时候同样应该采用类似向量化召回的思路,选取TopN
2、Embedding&Pooling Layer
所有的id类特征都会经过embedding层得到相应的embedding向量,用户属性embedding特征拼接起来得到一个用户属性embedding向量,用户行为embedding经过pooling层之后进入Multi-interest Extract层,目标商品的Embedding向量经过pooling层之后得到其对应的embedding向量,所以上问提到的映射函数fitem()其实可以理解为embedding层+pooling层。
3、Multi-interest Extract Layer
本文最为核心的思想就是单一的向量无法充分的表征用户,所以本文采用多个向量来对一个用户进行表征,Multi-interest Extract层的主要任务就是得到多个用户表征向量。Multi-interest Extract层是基于动态路由实现的。动态路由主要用于胶囊网络,假设我们有两层的capsule leyers,其中第一层和第二层分别为低层级capsule和高层级capsule。动态路由的核心目标就是基于低层级的capsule通过迭代的方式求得高层级的capsule。首先约定两层capsule(i和j)之间的routing logit(bij)通过下式计算
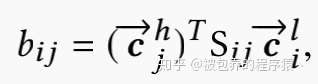
其中Sij为双线性映射矩阵,具体是由模型学习得到,而且每一对高低层级capsule对应一个单独的映射矩阵S。在计算得到routing logit的基础上,高层级capsule(j)对应的candidate向量如下所示
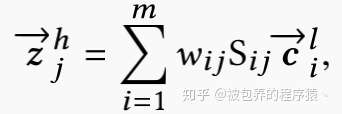
其中wij表示连接高低层级capsule之间的权重,具体由下式计算得到
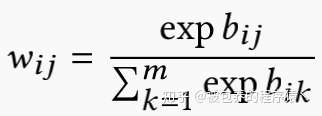
最终经过一个非线性映射函数得到高层级capsule的值,具体如下
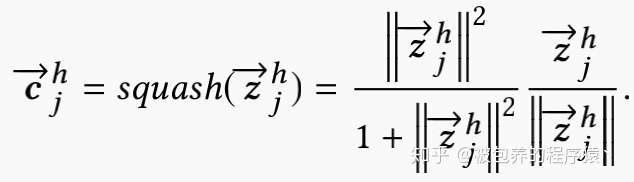
上述就完成了一次迭代计算过程,通常经过三轮迭代之后,高层级capsule的值将会收敛,具体的算法如下所示:
 B2I动态路由算法
B2I动态路由算法
本文正是借鉴了上面提到的动态路由的思想,本文的思路就是将用户不同方面的行为/兴趣表征理解为行为/兴趣capsule,主要目的就是学习从行为capsule映射到兴趣capsule的映射函数,而该映射函数就是multi-interest extract层。文章指出原始的动态路由无法直接应用到MIND模型中,所以文章主要做了以下几方面的改进:(1)不同行为/兴趣capsule之间共享双线性映射网络S(2)随机初始化routing logit(3)自适应调整用户兴趣表征向量的个数
4、Label-aware Attention Layer
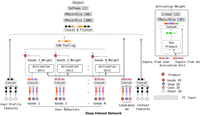
在得到用户的多个表征向量之后(capsules),如何利用其与目标商品的embedding向量来进行召回呢,本文采用的attention layer主要用于解决这个问题。传统的向量化召回利用两个向量的点击形式获得相应的评分,选取top候选集。但是当其中一方的embedding为多个的时候如何进行召回呢,一种方式是将其中一方的embedding进行concate,然后与另一方的embedding向量算内积(例如可以将用户本身的embedding向量和用户行为embedding向量concate,然后与目标商品的embedding算内积进行召回,需要注意维度保持一致)。本文给出了另外一种方式,就是采用attention的方式,将多个用户表征向量进行加权得到多个向量,然后分别与目标商品的embedding向量进行内积运算,选取其中最大的内积作为该商品的得分,选取TopN即得到了候选商品集。具体attention网络结构如下
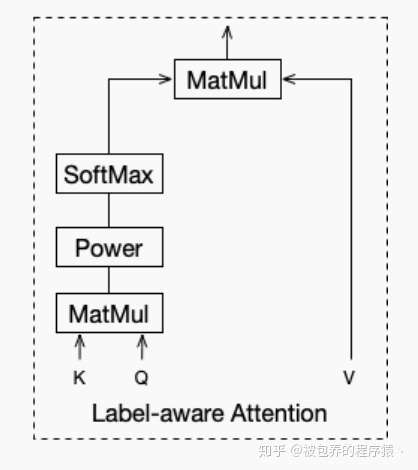 Lable-aware Attention结构
Lable-aware Attention结构
不同于上文提到的评分标准,上文的评分标准中选择K个用户表征向量中与目标商品Embedding向量内积最大的作为该商品的得分,显然这种评分标准损失了很多信息,采用Attention的方式能够在保证信息被充分利用的前提下更加充分的挖掘有用信息。
三、模型训练
在采用MIND模型得到用户兴趣的表征向量和商品的表征向量之后,通过下式可以计算得到用户对商品的交互概率
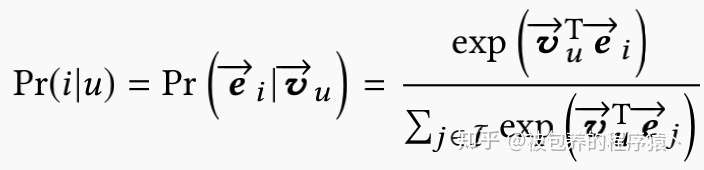
基于此概率,可以进一步得到MIND模型的目标函数,具体如下
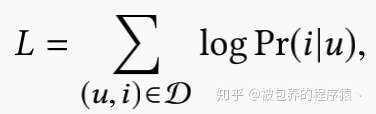
上式中的集合D为用户-商品交互数据集,通常数量是十分庞大的,而且目标函数中涉及到求和运算,这个计算开销是非常巨大的,所以文章考虑采用sampled softmax技术来训练MIND模型。
在线上使用的时候,通过模型可以预测得到用户的多维表征向量,利用多维表征向量和商品表征向量可以计算得到Top N的商品,为进一步降低计算的复杂度和开销,采用相应的最近邻检索方法,可以检索出近似Top N的商品。所以MIND模型可以看做是最原始向量化召回的改进,所以MIND模型可以用于线上实时的商品召回
四、实验结果
文章着重分析了模型超参数对于MIND模型的影响并展开了详细的讨论,具体细节可以参考原文。同时文章还给出了MIND模型与协同过滤和YouTubeDNN模型的线上对比分析,具体结果如下
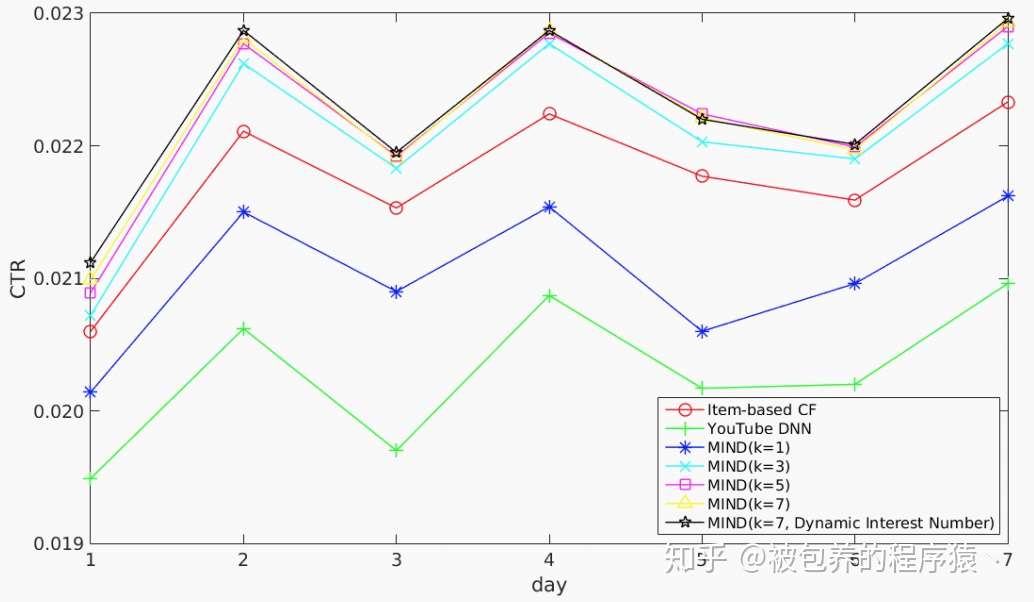 线上实验结果
线上实验结果
从上述结果可以发现,对于天猫场景下,最优的用户兴趣表征向量的个数为5-7个,这也从一定程度上反应了用户的平均兴趣多样性;除此之外文章指出自适应调节用户兴趣表征向量个数的机制并未明显提升线上系统的AUC,但是该机制有效降低了系统服务的开销。同时相较于Item-CF和YouTubeDNN模型,MIND模型对于系统的CTR的确有所提升
五、结论
总的来说MIND模型是对向量召回模型的一次改进,不同于YouTubeDNN召回模型,MIND模型对于用户兴趣的建模引入了多维度的向量,能够更加细致的刻画用户的行为兴趣,线上实验结果也证明了MIND模型的有效性,由于笔者之前也做过向量化召回的相关工作,这篇论文的确给了我新的思路,感兴趣的小伙伴也可以参考我之前的文章 。
被包养的程序猿丶:向量化召回在360信息流广告的实践zhuanlan.zhihu.com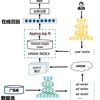
论文地址:
Multi-Interest Network with Dynamic Routing for Recommendation at Tmallarxiv.org欢迎爱分享的小伙伴向本专栏投稿
感兴趣的小伙伴可以关注微信公众号:独立团丶
编辑于 2019-12-27 推荐算法 个性化推荐 神经网络
文章被以下专栏收录
推荐阅读
推荐系统(7)---深度兴趣网络DIN
Micha...发表于推荐系统专...推荐算法——基于知识的推荐(KB)之DKN模型
比较典型的是构建领域本体,或是建立一定的规则,进行推荐。 DKN 知识图谱特征学习(Knowledge Graph Embedding)是最常见的与推荐系统结合的方式,知识图谱特征学习为知识图谱中的每个实体和…
大饼发表于人工智能与...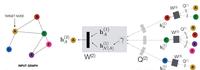
网络表示学习: 淘宝推荐系统&&GraphSAGE
于辰淼发表于Algor...
智能推荐算法在直播场景中的应用
Micro...发表于人工智能7 条评论
写下你的评论...-
 Bula2019-12-27
厉害 一直在看老哥的文章
Bula2019-12-27
厉害 一直在看老哥的文章
-
 Ohanawa2019-12-27
大佬大佬
Ohanawa2019-12-27
大佬大佬
-
 Old Zhu02-13
Old Zhu02-13
您好,请问这篇论文有代码吗
-
 西瓜皮03-10
西瓜皮03-10
一直有个疑问,不知道楼主有没有看法:B2I多轮迭代的时候,每一层的输入输出大小都不一样啊。第一轮的输入比如说lowcapsule长度是10,high_capsule长度是5,那到第二轮,low和high都应该是5了(因为K是固定的?),那每层对应的bij应该都不一样啊,这是怎么更新的
-
 张月鹏回复西瓜皮07-23
张月鹏回复西瓜皮07-23
每一轮的长度都是固定的啊
-
 「已注销」06-02
老哥能做内推么
「已注销」06-02
老哥能做内推么
-
 张月鹏07-23
张月鹏07-23
对其中Multi-Interest Extractor Layer后面如何与用户向量concat,并进行全连接存在疑惑,在全连接的时候会把一个Capsule的向量作为一个神经元共享一个权值,还是会展开拼接起来? 1)如果作为一个神经元,那用户向量是要和Capsule维度保持一致? 2)如果展开,最后全连接层无法表达用户的多个兴趣了吧?
标签:capsule,模型,MIND,用户,天猫,路由,表征,向量 来源: https://www.cnblogs.com/cx2016/p/13906749.html