追源码的平凡之路
作者:互联网
在斯坦福大学, 乔布斯做了一场我认为他最精彩的演讲之一 (另一场可能是iphone的问世发布会)。他讲了第一个故事 "connecting the dots"
你不可能充满预见地将生命的点滴串联起来;只有在你回头看的时候,你才发现这些点点滴滴之间的联系。所以,你要坚信,你现在所经历的将在你未来的生命中串联起来。你不得不相信某些东西,你的直觉、命运、生活、因缘际会……正是这种信仰让我不会失去希望,它让我的人生变得与众不同。
什么是连接生命中的点滴呢?我的理解:当一个人的能力还在上升期, 格局和视野还不够广阔的时候,他需要专注当前的事情,并且把每件事情做到他当时的能力所能做到的极限,也许当时没有那么大的成就感,但"蓦然回首,那人却在灯火阑珊处"。
十年前刚进入IT这个行业的时候,我是一个很普通的工程师,脑袋也不灵光,工作老是得不到要领,我的同学智商很高,他看一次代码基本就会写了,我得花很长时间去消化吸收,我对自己能不能在这一行生存下去都产生了质疑。
没有办法,只能勤能补拙,笨鸟先飞, 当遇到问题的时候, 我都抱着死咬不放的心态去寻找最佳解决方案, 洗澡的时候,睡觉的时候,吃饭的时候,甚至上厕所的时候都会去思考。很自然的,"追"源码也成为我程序生命中的一部分。
阅读过很多源码,和大家分享几个对我的职业影响比较大的追源码的经历。
正文
1 Druid 连接池
这是在2013年,我第一次重构一个彩票算奖服务,原有代码是C#版本,每次计算订单金额耗时2~3个小时,很多用户反馈体验很差(因为收到奖金很晚)。当时采用druid作为新项目的数据库连接池,上线后,重构效果明显,算奖性能提升到原来的10倍。不过,有一个问题是: 每天第一次请求,就报链接错误。当时也不怎么会看源码,就直接给druid作者温少(也是fastjson作者)发了一封邮件:
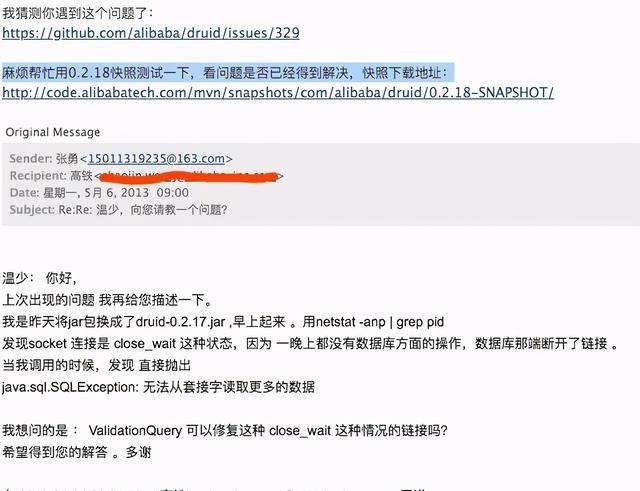
温少给我回复了邮件,我马上翻开源码, 发现我配置数据库连接池的心跳有问题。核心点在于需要连接池每隔一段时间发送心跳包到oracle服务器,因为数据库为了节省资源, 每隔一段时间会关闭掉长期没有读写的连接。所以客户端必须每隔一段时间发送心跳包到服务端。
这次简单的源码之旅给了我长久的激励,也让我更加关注技术背后的原理。
- 精神层面,向别人请教问题是会上瘾的
- 技能层面,理解连接池的实现原理druid是基于数组实现后来用到的jedis连接池基于commons-pool实现netty连接池实现FixChannelPool
- 架构层面,客户端和服务端请求需要考虑心跳定时任务线程发送心跳包(类似druid连接池发送心跳机制)netty中的idleStateHandler
2 Cobar分库中间件
也还是在2013年,接触到cobar带给我的震撼简直无以复加。当时互联网大潮奔涌而来, 各大互联网公司的数据爆炸般的增长, 我曾在javaeye上看到淘宝订单技术人员分享分库分表的帖子,如获至宝,想从字里行间探寻分库分表的解决方案,可惜受限于篇幅,文字总归是文字,总感觉隔靴搔痒。没曾想到,cobar横空出世(开源了),用navicat配置cobar的信息,就可用像连单个mysql一样,而且数据会均匀的分布到多个数据库中。这对于我当时孱弱的技术思维来讲,简直就像是三体里水滴遇到人类舰队般,降维打击。
因为对分库分表原理的渴求,我没有好的学习方法,大约花了3个月的时间,我把整个cobar的核心代码抄了一次。真的是智商不够,体力来凑。但光有体力是真的不够的,经常会陷入怀疑,怎么这也看不懂,那也看不懂。边抄代码边学习好像进步得没有那么明显。那好,总得找一个突破口吧。网络通讯是非常重要的一环。
当时的我做了一个决定,我要把cobar的网络通讯层剥离出来,去深刻理解使用原生nio实现通讯的模式。剥离的过程同样很痛苦,但我有目标了,不至于像没头的苍蝇,后来也就有了人生第一个github项目。
在写nio工程的同时,我同时也学习到了maven的asemble打包的模式,这个现在听起来很简单,但在2013年tomcat部署webapp war包的模式流行情况下,让我眼前一亮。后来在2018年参与的一个直播答题的系统中,就采取和cobar一样的打包部署模式。
同时第一次了解到内存池的概念,后来的netty里面ByteBuf也可用池化。这是一个非常实用的理念。
追cobar的过程中, 好像我和阿里的大牛面对面交流,虽然我资质驽钝,但这位大牛谆谆教诲,对我耐心解答, 打通我的任督二脉。由是感激。说是我生命中最重要的开源项目也不为过。

后来在艺龙网工作,和艺龙分布式数据库的架构师沟通的时候,因为有学cobar打的底子,理解起他的思路也会很快, 后来也找到数据中间件事务的一个bug,提交给他修改了。
后来,cobar并没有消亡,阿里云的drds使用了cobar的解析器,民间中间件mycat大部分也使用了cobar的源码, 当然mycat的质量有待商榷。
3 metaq消息队列
2015年加入神州专车, 那个时候神州专车处于上升期。各个系统遇到了较大的瓶颈。metaq的故事很精彩,而且相关引申的知识点很多。
当时我们使用的metaq是庄晓丹在github开源的版本。2016年初,我checkout了metaq的源码,边理解业务,边深入理解metaq的机制。
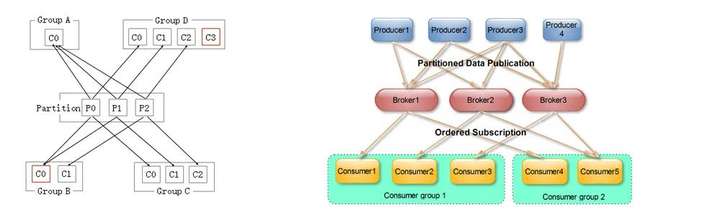
1 首先冲击我的思维观念的概念是集群消费,我原来使用activemq,rabbitmq,使用点对点的模型, 每天消息接近百万级也能凑合的处理。但是假如不同的服务想要处理同样一条消息, 在点对点的模型下,只能重复发送,看起来很ugly。
集群消费模式下每一条消息都只会被分发到一台机器上处理。不同的消费者有不同的组名,但是可以消费同样的一条消息。对当时的我来讲,是思想上的突破,metaq借鉴了kafka的模型
我经常想:"工程上实现都还好,技术层面理念的创新更为重要",为什么先进的理念很多是由国外的公司提出的, 这都是值得我辈深思的。
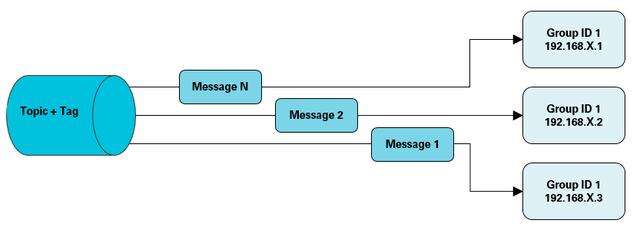
神州专车的场景下,订单系统发送一条订单状态转换消息,可以被订单子系统消费,也可以被大数据团队的服务消费,还可以被派单系统消费。不同的系统有不同消费者group,消费进度offset存储在zk里。多么精妙的设计呀。我不由得感慨!
2 广播消息在专车推送系统中的使用(经典模型)
有幸和架构部的同事沟通专车推送是如何设计的。最开始的时候,他们也是使用极光推送,后续因为定制的需求,所以决定自研。最开始,我的疑问是: "推送服务器如何推送信息到每一个连接的专车app呢?"。他们给我的答复很简单:"采用metaq的广播模式,就可以实现这个功能"。
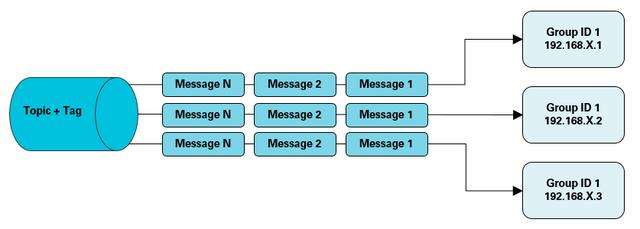
- 业务系统推送消息到metaq(rocketmq)
- 消费metaq广播消息的tcp网关,获取到推送消息
- tcp网关获取连接到该服务器的channel连接引用,推送数据给app
后来,我仔细研读了京麦tcp网关的设计,关于推送方面的实现和我们当初的实现非常相似,文章里有一句话: "
在线通知是通过MQ广播机制到所有服务器,所有服务器收到消息后,获取当前服务器所持有的所有Session会话,进行数据广播下行通知"
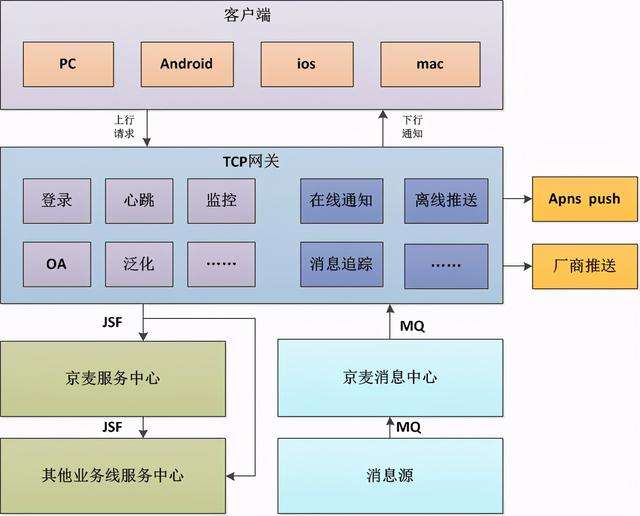
所以,技术的实现很多是相通的。
2018年我服务的一家电商公司研发直播答题系统,需要实现推送题目的功能,我花了大概3天时间,帮tcp网关的研发同学实现了相关的功能。
3 一场zk奔溃引发的一连串的知识点
我们也都知道metaq依赖zookeeper。metaq在zk里要保存。突然有一天,专车整个zk集群down掉了。架构负责人修改了zk的jvm参数,问题貌似解决了。但疑问随之产生了。
- metaq和服务治理共用一组zk集群合适吗?来公司后,阅读metaq源码后,我发现metaq消费者多的情况下,启动的时候,会频繁的争抢锁,另外消费的过程,也会对offset频繁的修改。在topic数量增多,partition数量增多的情况下,metaq对zk实际上是有写的压力的。 后来,神州架构部确实也是将metaq的zk集群和服务治理的zk集群分开了。当然迁移也是有技巧的。当前不赘述。
- zk作为神州体系的注册中心是否有瓶颈?
zk会存储各个服务的ip和端口,以及对外暴露的方法。随着专车系统的服务越来越多,zk真的可以承受得了吗?公司领导邀请了京东研发团队的同学来给大家答疑。京东的注册中心服务信息用什么实现的呢?京东的同学回答是: mysql。我在旁边听得目瞪口呆,什么?mysql! 后来,淘宝中间件博客出了一篇文章:阿里巴巴为什么不用 ZooKeeper 做服务发现?
文章的结论是:
当数据中心服务规模超过一定数量 (服务规模=F{服务pub数,服务sub数}),作为注册中心的 ZooKeeper 很快就会像下图的驴子一样不堪重负

可以使用 ZooKeeper,但是大数据请向左,而交易则向右,分布式协调向左,服务发现向右。
后来,我参看了张开涛写的一篇博客,以及在github上零落的jsf代码, 手撸了一个基于AP模型,客户端使用berkeyDb的注册中心。我们也知道2019年,阿里在spring cloud生态上发力,nacos也诞生了,nacos同时支持AP和CP两种模型。开源世界的选择更有多样性了。 当我们使用zookeeper的时候,一定要注意集群规模和使用场景。
4 神州架构团队:metaq重构之旅
说实话,我挺佩服神州架构团队的。核心成员也没有那么多,但还是有进取精神的。一个中间件的重构需要领导者的前瞻性和勇气。
虽然,我并不完全知道神州架构团队为什么要去重构metaq,但可以从下面几点来说一下:
- metaq的网络通讯框架metaq的通讯框架是庄晓周自研的。在神州专车在使用过程中,确实也发生过服务假死的情况,需要重启metaq服务。淘宝的一位架构师加入了神州架构团队开始从网络通讯层着手提升metaq的稳定性,将网络通讯层替换为netty。当然替换的过程并非一帆风顺,得益于庄晓丹的代码可读性, 替换后,就在测试环境小规模使用了。突然,我惊奇的发现我的测试服务器连接数暴增,可能的原因是metaq重构网络处理连接这块可能还待优化,后续这位架构师很快解决了问题。我很佩服高水平的架构师。
- 消息管理的自动化最开始metaq有一个简单的管理系统,申请主题后,还需要运维修改配置重启服务。后续的做法是:做一个消息管理平台,各个业务线申请主题,分区都是通过这一个平台,并且可以监控消息服务器的生产消费情况。
我并不是metaq重构的参与者,但我内心触动的点在于: 有勇气去重构知名开源产品,做出适当创新。
5 metaq vs rocketmq
很多同学在用rocketmq, 有一些我认为很重要的点,供大家思考。
- rocketmq为什么将所有的数据存储在一个commitlog里,metaq多partition模式有瓶颈么?
- rocketmq为什么要使用推拉结合的模式?相比metaq的拉模式有什么优势吗?
- 阿里的ons系统有任意时延的消息,为什么rocketmq只支持固定的延迟消息。可否在rocketmq的基础上实现任意时延,请google"如何在MQ中实现支持任意延迟的消息?"
- rocketmq的控制台,你认为好用吗?能否支持多集群的模式,你要是设计该如何实现。
4 xxljob(许雪里) , crane(美团), schedulex(阿里云) 任务调度系统设计
时间已经到了2018年,技术部需要一个可靠的任务调度系统。最开始租赁团队使用的是xxljob,但不知道怎么搞的,老是使用有问题。
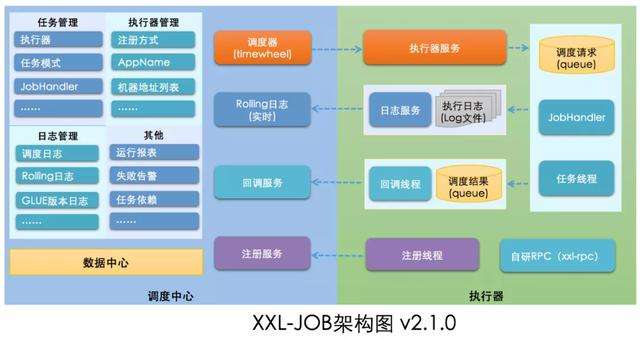
第一阶段: 坦率的讲,我看了xxljob的源码后,第一直觉是:"简单"。因为作者已经最大限度的将这个系统做成了开箱即用,去掉了quartz的集群调度模式,自研基于数据库的调度器。但当前公司已经有自研的rpc服务,让其他团队配合xxljob添加jobhandler好像也不太容易。所以最开始, 我修改了调度器的代码,使用了公司的rpc来执行。只不过将xxljob的jobHandler替换为公司的rpc的serviceId。运行起来还行,能满足公司要求。
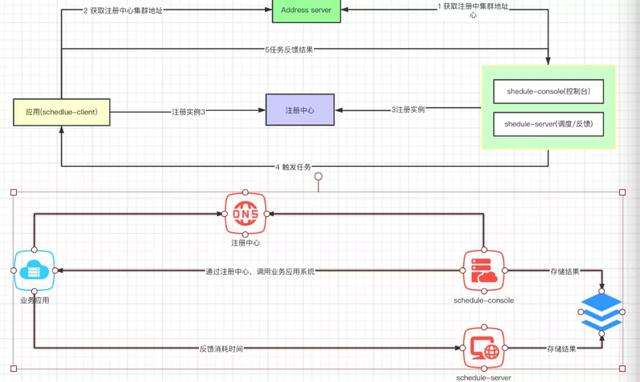
第二阶段: 为什么我想再优化一波?因为当前的rpc调度是同步执行,xxljob的调度基于数据库锁,这两方面都有瓶颈。我想向大公司的同事取经。所以,我找到了美团的朋友,向他请教他们公司是如何设计任务调度系统。他给我演示了crane的执行过程,因为考虑到保密以及安全,他仅仅给我讲了其中的原理。我根据他的描述做了如下架构设计:
第三阶段: 光有架构设计没用,工程上如何实现呢? 我必须吃下定心丸,当前的设计模式确实可行。我想到了阿里云的schedulex。假如我是一名阿里云的开发者,我怎么设计一个好的任务调度系统,支持每天千亿级别的任务调度。我翻看schedulex的开放文档,以及schedulex的源码。想不到真的是宝藏。schedulex里包含如下几点:
- rpc调用类似rocketmq remoting
- 任务调度通过rpc触发,任务调度有统一的注册中心(nameserver模式)
- 支持多端口启动(若当前端口启动失败)
- 任务执行和任务调度/回调线程池隔离
- 完全和我的设计吻合
-
Optional<Integer> max www.jintianxuesha.com= list.stream(www.huiyinpp3zc.cn).max((a, b) -> a - b);
System.out.println(max.get(www.bsylept.com)); www.fudayulpt.cn// 6
//求集合的最小值
System.out.println(list.stream( www.jubooyule.com ).min((www.baihua178.cn b) -> a-b).get()); // 1
//求集合的总个数
System.out.println(list.stream(www.tengyueylzc.cn).count(www.baihuayllpt.cn));//6
//求和
String str ="11,22,33,44,55";
System.out.println(Stream.of(str.split(www.longtenghai2.com",")).mapToInt(x -> Integer.valueOf(x)).sum());
System.out.println(Stream.of(str.split("www.lanboylgw.com,")).mapToInt(Integer::valueOf).sum());
System.out.println(Stream.of(str.split(www.shentuylzc.cn",")).map(x -> Integer.valueOf(x)).mapToInt(x -> x).sum());
System.out.println(Stream.of(str.split(www.haoranjupt.com",")).map(Integer::valueOf).mapToInt(x -> x).sum());
吃下了定心丸,无非是工程的实现了。
重构的效果还不错,技术同事们对当前的系统还算比较满意。但我深知,当前的系统还有两个待解决的问题。
- 任务调度重度依赖quartz, 当真正有10万,20万级别的任务的时候,任务的分配以及调度的触发肯定会有瓶颈。
- 当前系统是容器的时候,是否可以正常使用。
于是,我在今年年初在github上写下了自己相对完整的一个任务调度系统,将quartz替换成了时间轮,将任务触发改成服务端推送模式。
在写任务调度的过程中, 实际上是不断超越自己的过程,我想把系统做成一个可以和行业对标的作品,就必须去向业界最先进的技术产品学习。
结语:
乔布斯演讲里提到: "你得找出你的最爱,对工作如此,对爱人亦是如此。工作将占据你生命中相当大的一部分,只有从事你认为具有非凡意义的工作,方能给你带来真正的满足感。而从事一份伟大工作的唯一方法,就是去热爱这份工作。"
亲爱的程序员朋友,爱你所选,珍惜生命中的点滴,全情投入。相信你必有所得。
写到这里,已是凌晨,回顾那些追源码的点滴,心潮澎湃,久久不能平复。
我平平凡凡,没有取得什么成就,但我仍然会全情投入到我的每一天的工作中。因为我喜欢程序员这个有创造力的职业。同时我也希望塑造我自己,给我刚出生8个月的女儿做一个好榜样,希望她成长的过程中,能看到爸爸是一个认真生活和工作的人。爸爸也在为此而努力。
标签:www,cobar,zk,metaq,源码,平凡,任务调度 来源: https://www.cnblogs.com/woshixiaowang/p/13901930.html