Python常见的模块(知乎转载)
作者:互联网
核心库和统计
1. NumPy(提交:17911,贡献者:641)
首先介绍科学应用方面的库,其中NumPy是不可忽视的选择。NumPy用于处理大型多维数组和矩阵,并通过大量的高级数学函数和实现方法进行各种操作。在过去一年里NumPy进行了大量改进。除了bug修复和兼容性问题之外,还涉及到样式可能性,即NumPy对象的格式化打印。
推荐资源:
NumPy 数值计算基础课程_机器学习 - 实验楼www.shiyanlou.com
2. SciPy(提交:19150,贡献者:608)
科学计算方面的另一个核心库是SciPy。SciPy基于NumPy因此扩展了NumPy的功能。SciPy的主要数据结构是由Numpy实现的多维数组。当中包括许多解决线性代数、概率论、积分等任务的工具。SciPy的主要改进包括,持续集成到不同操作系统,以及添加的新功能和新方法。此外,还封装了许多新的BLAS和LAPACK函数。
推荐资源:
SciPy 科学计算基础课程_机器学习 - 实验楼www.shiyanlou.com
3. Pandas(提交:17144,贡献者:1165)
Pandas是一个Python库,提供高级数据结构和各种分析工具,主要特点是能够将相当复杂的数据操作转换为一两条命令。Pandas包含许多用于分组,过滤和组合数据的内置方法,以及时间序列功能。Pandas库已推出多个新版本其中包括数百个新功能、增强功能、bug修复和API改进。这些改进包括分类和排序数据方面,更适合应用方法的输出,以及执行自定义操作。
推荐资源:
Pandas 数据处理基础课程_机器学习 - 实验楼www.shiyanlou.com
4. StatsModels(提交:10067,贡献者:153)
Statsmodels是一个Python模块,用于统计模型估计、执行统计测试等统计数据分析。在它的帮助下,你可以使用机器学习方法,进行各种绘图尝试。Statsmodels在不断改进。今年加入了时间序列方面的改进和新的计数模型,即广义泊松、零膨胀模型和负二项。还包括新的多变量方法 ——因子分析、多元方差分析和方差分析中的重复测量。
可视化
5. Matplotlib(提交:25747,贡献者:725)
Matplotlib是用于创建二维图表和图形的低级库。使用Matplotlib,你可以构建直方图、散点图、非笛卡尔坐标图等图表。此外,许多热门的绘图库都能与Matplotlib结合使用Matplotlib在颜色、尺寸、字体、图例等方面都有一定改进。外观方面包括坐标轴图例的自动对齐;色彩方面也做出改进,对色盲更加友好。
推荐资源:
Matplotlib 数据绘图基础课程www.shiyanlou.com
6. Seaborn(提交:2044,贡献者:83)
Seaborn是基于matplotlib库更高级别的API。它包含更适合处理图表的默认设置。此外,还包括时间序列等丰富的可视化图库。Seaborn的更新包括bug修复。同时,还包括FacetGrid与PairGrid的兼容性,增强了matplotlib后端交互,并在可视化中添加了参数和选项。
推荐资源:
Seaborn 数据可视化基础课程www.shiyanlou.com
7. Plotly(提交:2906,贡献者:48)
Plotly能够让你轻松构建复杂的图形。Plotly适用于交互式Web应用程序。可视化方面包括等高线图、三元图和三维图。Plotly不断增加新的图像和功能,对动画等方面也提供了支持。
8. Bokeh(提交:16983,贡献者:294)
Bokeh库使用JavaScript小部件,在浏览器中创建交互式和可缩放的可视化。Bokeh提供了多种图形集合、样式,并通过链接图、添加小部件和定义回调等形式增强互动性。Bokeh在交互式功能的进行了改进,比如旋转分类标签、小型缩放工具和自定义工具提示字段的增强。
9. Pydot(提交:169,贡献者:12)
Pydot用于生成复杂的定向图和非定向图。它是用Python编写的Graphviz接口。使用Pydot能够显示图形结构,这经常用于构建神经网络和基于决策树的算法。
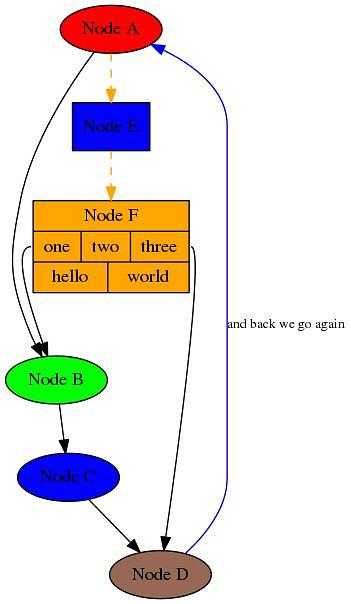
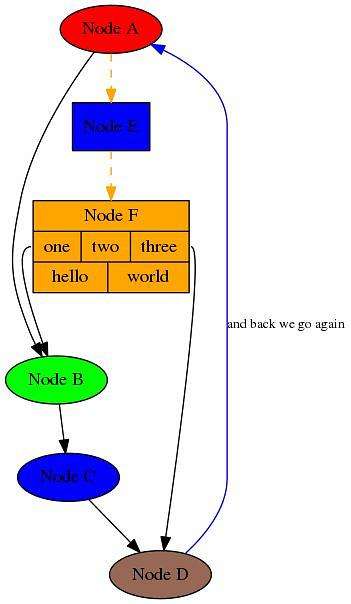
机器学习
10. Scikit-learn(提交:22753,贡献者:1084)
Scikit-learn是基于NumPy和SciPy的Python模块,并且是处理数据方面的不错选择。Scikit-learn为许多机器学习和数据挖掘任务提供算法,比如聚类、回归、分类、降维和模型选择。
Scikit-learn是基于NumPy和SciPy的Python模块,并且是处理数据方面的不错选择。Scikit-learn为许多机器学习和数据挖掘任务,提供算法,比如聚类、回归、分类、降维和模型选择。Scikit-learn已做出了许多改进改进包括交叉验证、使用多个指标,近邻取样和逻辑回归等训练方法也有小的改进。主要更新还包括完善常用术语和API元素的术语表,这能帮助用户熟悉Scikit-learn中的术语和规则。
11. XGBoost / LightGBM / CatBoost(提交:3277/1083/1509,贡献者:280/79/61)
梯度提升(gradient boosting)是最流行的机器学习算法之一,这在决策树模型中是至关重要的,因此我们需要重视XGBoost、LightGBM和CatBoost。这几个库都用相同的方式解决常见问题。这些库能够更优化、扩展且快速地实现梯度提升,从而它们在数据科学家和Kaggle竞争中备受追捧,其中许多人在这些算法的帮助下赢得了比赛。
12. Eli5(提交:922,贡献者:6)
通常机器学习模型预测的结果并不特别清晰,这时就需要用到eli5了。它可以用于可视化和调试机器学习模型,并逐步跟踪算法运行情况。同时eli5能为scikit-learn,XGBoost,LightGBM,lightning和sklearn-crfsuite库提供支持。
深度学习
13. TensorFlow(提交:33339,贡献者:1469)
TensorFlow是用于深度学习和机器学习的热门框架,由谷歌大脑开发。TensorFlow能够用于多个数据集的人工神经网络。TensorFlow的主要应用包括对象识别、语音识别等等。新版本中加入了新的功能。最新的改进包括修复安全漏洞,以及改进TensorFlow和GPU集成,比如能在一台机器上的多个GPU上运行评估器模型。
推荐资源:
TensorFlow 深度学习基础课程www.shiyanlou.com
14. PyTorch(提交:11306,贡献者:635)
PyTorch是一个大型框架能通过GPU加速执行tensor计算,创建动态计算图并自动计算梯度。此外,PyTorch为解决神经网络相关的应用提供了丰富的API。PyTorch基于Torch,它是用C语言实现的开源的深度学习库。Python API于2017年推出,从此之后该框架,越来越受欢迎,并吸引了大量数据科学家。
推荐资源:
PyTorch 深度学习基础课程www.shiyanlou.com
15. Keras(提交:4539,贡献者:671)
Keras是用于神经网络的高级库,可运行与TensorFlow和Theano。现在由于推出新版本,还可以使用CNTK和MxNet作为后端。它简化了许多任务,并大大减少了代码数量。但缺点是不适合处理复杂任务。Keras在性能、可用性、文档即API方面都有改进。新功能包括Conv3DTranspose层、新的MobileNet应用等。
推荐资源:
使用 Keras 预训练模型实现迁移学习www.shiyanlou.com
分布式深度学习
16. Dist-keras / elephas / spark-deep-learning(提交:1125/170/67,贡献者:5/13/11)
由于越来越多的用例,需要大量的精力和时间深度学习问题变得更为重要。但是,使用Apache Spark之类的分布式计算系统,能够更容易处理大量数据这又扩展了深度学习的可能性。因此dist-keras、elephas、和spark-deep-learning变得更为普及由于它们有能用于解决相同任务,因此很难从中取舍,这些包能够让你在Apache Spark的帮助下,直接通过Keras库训练神经网络。Spark-deep-learning还提供了使用Python神经网络创建管道的工具。
自然语言处理
17. NLTK(提交:13041,贡献者:236)
NLTK是一组库,是进行自然语言处理的平台。在NLTK的帮助下,你可以通过多种方式处理和分析文本,对其进行标记和提取信息。NLTK还可用于原型设计和构建研究系统。NLTK的改进包括API和兼容性的小改动,以及CoreNLP的新接口。
18. SpaCy(提交:8623,贡献者:215)
SpaCy是自然语言处理库具有出色的示例、API文档和演示应用。该库用Cython编写Cython是C语言在Python的扩展。它支持将近30种语言,提供简单的深度学习集成,并能确保稳定性和高准确性。SpaCy的另一个强大功能是无需将文档分解,整体处理整个文档。
19. Gensim(提交:3603,贡献者:273)
Gensim是Python库,用于语义分析、主题建模和矢量空间建模建立在Numpy和Scipy之上。它提供了word2vec等NLP算法实现。尽管gensim拥有自己的models.wrappers.fasttext实现,但fasttext库也可用于词语表示的高效学习。
数据抓取
20. Scrapy(提交:6625,贡献者:281)
Scrapy可用于创建扫描页面和收集结构化数据。另外,Scrapy还可以从API中提取数据。由于其可扩展性和便携性,Scrapy非常好用。今年Scrapy的更新包括代理服务器升级,以及错误通知和问题识别系统。这也为使用scrapy解析机械能元数据设置提供了新的方法。
作者:实验楼在线教育
链接:https://www.zhihu.com/question/322291562/answer/818168087
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
标签:贡献者,知乎,模块,Python,com,学习,提交,NumPy 来源: https://www.cnblogs.com/Timeouting-Study/p/12447721.html