Python多线程threading
作者:互联网
介绍
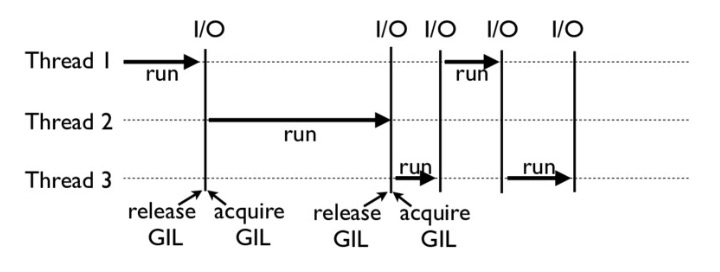
在Python中,使用多线程multi-threading可以『同时』执行多个任务,比如你需要一个线程来复制读取信息,另一个线程来解析。为什么这里的同时要加引号呢,这是由于Python中GIL,也就是全局锁,看似同时执行多个任务,实际上是分布执行的,只不过各自完成不同的任务会提高工作效率。如果你不了解GIL,请看下图
实例教程
实例1
import threading
def job():
info = "this is an added thread, which is %s" % threading.current_thread
print(info)
def main():
print(threading.active_count())
print(threading.enumerate())
#print(threading.current_thread())
# 创建一个Thread对象,让他来复制job任务
new_thread = threading.Thread(target=job)
# 执行线程任务
new_thread.start()
print(threading.active_count())
if __name__ == '__main__':
main()运行结果:
1
[<_MainThread(MainThread, started 140637982934784)>]
this is an added thread, which is <function current_thread at 0x7fe8cd92d378>
2解释一下:
- threading是线程模块,需要导入
- threading.active_count()方法会给出所有激活的线程数量
- threading.enumerate()方法会列举出存在的每一个线程
- threading.current_thread()方法会给出当前正在执行的线程
- 使用时需要先创建线程对象,并指定任务(target),然后用start方法来执行
实例2
import threading
import time
def job():
print('T1 start\n')
# 让任务延迟一下
for i in range(10):
time.sleep(0.1)
print('T1 finish\n')
def job2():
print('T2 start\n')
# 任务不延迟
print('T2 finish\n')
def main():
thread1 = threading.Thread(target=job,name='T1')
thread2 = threading.Thread(target=job2,name='T2')
thread1.start()
thread2.start()
#thread1.join()
print('all done')
if __name__ == '__main__':
main()运行结果:
T1 start
T2 start
T2 finish
all done
T1 finish会发现all done并不是在最后执行的,怎么办呢?试试把join方法解除封(注)印(释),请看结果:
T1 start
T2 start
T2 finish
T1 finish
all done解释一下:
- 多个线程是交叉进行的
- join方法可以用来等待该线程完成任务
实例3
import threading
from queue import Queue
import time
def job(l,q):
for i in range(len(l)):
l[i] = l[i]**2
q.put(l)
def multithreading(data):
q = Queue()
threads = []
THREAD_NUM = 4
for i in range(THREAD_NUM):
t = threading.Thread(target=job,args=(data[i],q))
t.start()
threads.append(t)
for t in threads:
t.join()
results = []
for _ in range(THREAD_NUM):
results.append(q.get())
print(results)
def unithreading(data):
for i in range(len(data)):
l = data[i]
for j in range(len(l)):
data[i][j] = data[i][j]**2
print(data)
if __name__ == '__main__':
data1 = [[1],[2,3],[4,5,6],[7,8,9,10]]
data2 = [[1],[2,3],[4,5,6],[7,8,9,10]]
time1 = time.clock()
unithreading(data1)
time2 = time.clock()
multithreading(data2)
time3 = time.clock()
runtime_uni = time2 - time1
runtime_multi = time3 - time2
print("Runtime for unithreading is %s seconds." % runtime_uni)
print("Runtime for multithreading is %s seconds." % runtime_multi)运行结果:
[[1], [4, 9], [16, 25, 36], [49, 64, 81, 100]]
[[1], [4, 9], [16, 25, 36], [49, 64, 81, 100]]
Runtime for unithreading is 4.300000000000137e-05 seconds.
Runtime for multithreading is 0.001118000000000001 seconds.解释一下:
- 这个例子主要是对比一下单线程是多线程的速度
- 这里演示了如何创建多个线程(此处为4个),并且分别执行任务
- 因为线程任务本身是没有return的,所以顺便学习一下队列queue的用法,以及put和get方法
实例4
import threading
def job1():
global A
#global A,lock
#lock.acquire()
for i in range(10):
A += 1
print('job1',A)
#lock.release()
def job2():
global A
#global A,lock
#lock.acquire()
for i in range(10):
A += 10
print('job2',A)
#lock.release()
if __name__ == '__main__':
lock = threading.Lock()
A = 0
t1 = threading.Thread(target=job1)
t2 = threading.Thread(target=job2)
t1.start()
t2.start()
t1.join()
t2.join()运行结果:
job1job2 111
job1job2 1222
job1job2 2333
job1job2 3444
job1job2 4555
job1job2 5666
job1job2 6777
job1job2 7888
job1job2 8999
job1job2 100110你会发现这打印得错乱了,这也是多个线程交替工作得原因,如果先想要规定一个线程工作的时候防止别的线程干扰,需要怎么做呢?试试使用lock(注释部分)吧,再运行一下:
job1 1
job1 2
job1 3
job1 4
job1 5
job1 6
job1 7
job1 8
job1 9
job1 10
job2 20
job2 30
job2 40
job2 50
job2 60
job2 70
job2 80
job2 90
job2 100
job2 110解释一下:
- lock可以用来锁住一个线程,放置别的线程干扰它
- acquire方法和release方法分别是用来加锁和解锁的
最后
多线程的简单应用就到这里,我们最开始说过由于GIL,Python得多线程并不是真正的去同时执行多个任务,那么有没有办法弥补呢?有,那就是多进程!你一定听说过多核吧,下次再讲:)
标签:__,job2,job1,Python,threading,线程,print,多线程 来源: https://www.cnblogs.com/mrdoghead/p/12121416.html