Python Scrapy突破反爬虫机制(项目实践)
作者:互联网
对于 BOSS 直聘这种网站,当程序请求网页后,服务器响应内容包含了整个页面的 HTML 源代码,这样就可以使用爬虫来爬取数据。但有些网站做了一些“反爬虫”处理,其网页内容不是静态的,而是使用 JavaScript 动态加载的,此时的爬虫程序也需要做相应的改进。
使用 shell 调试工具分析目标站点
本项目爬取的目标站点是 https://unsplash.com/,该网站包含了大量高清、优美的图片。本项目的目标是爬虫程序能自动识别并下载该网站上的所有图片。
在开发该项目之前,依然先使用 Firefox 浏览该网站,然后查看该网站的源代码,将会看到页面的 <body.../> 元素几乎是空的,并没有包含任何图片。
现在使用 Scrapy 的 shell 调试工具来看看该页面的内容。在控制台输入如下命令,启动 shell 调试:
scrapy shell https://unsplash.com/
执行上面命令,可以看到 Scrapy 成功下载了服务器响应数据。接下来,通过如下命令来尝试获取所有图片的 src 属性(图片都是 img 元素,src 属性指定了图片的 URL):
response.xpath('//img/@src').extract()
执行上面命令,将会看到返回一系列图片的URL,但它们都不是高清图片的 URL。
还是通过"Ctrl+Shift+I"快捷键打开 Firefox 的调试控制台,再次向 https://unsplash.com/ 网站发送请求,接下来可以在 Firefox 的调试控制台中看到如图 1 所示的请求。
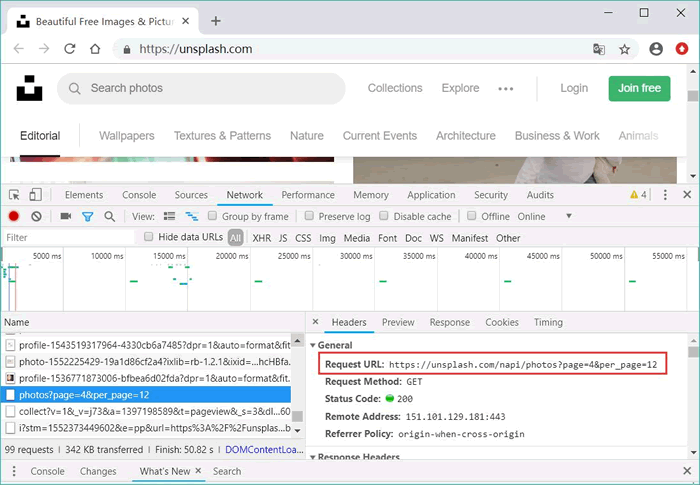
图 1 动态获取图片的请求
可见,该网页动态请求图片的 URL 如下:
https://unsplash.com/napi/photos?page=4&per_page=12
上面 URL 中的 page 代表第几页,per_page 代表每页加载的图片数。使用 Scrapy 的 shell 调试工具来调试该网址,输入如下命令:
scrapy shell https://unsplash.com/napi/photos?page=1&per_page=10
上面命令代表请求第 1 页,每页显示 10 张图片的响应数据。执行上面命令,服务器响应内容是一段 JSON 数据,接下来在 shell 调试工具中输入如下命令:
>>> import json
>>> len(json.loads(response.text))
10
从上面的调试结果可以看到,服务器响应内容是一个 JSON 数组(转换之后对应于 Python 的 list 列表),且该数组中包含 10 个元素。
使用 Firefox 直接请求 https://unsplash.com/napi/photos?page=1&per_page=12 地址(如果希望使用更专业的工具,则可选择 Postman),可以看到服务器响应内容如图 2 所示。
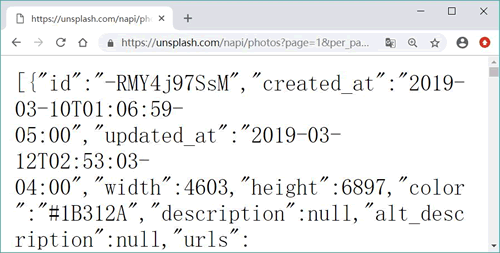
图 2 服务器响应的JSON 数据
在图 2 所示为所有图片的 JSON 数据,每张图片数据都包含 id、created_at(创建时间)、updated_at(更新时间)、width(图片宽度)、height(图片高度)等基本信息和一个 links 属性,该属性值是一个对象(转换之后对应于 Python 的 dict),它包含了 self、html、download、download_location 属性,其中 self 代表浏览网页时的图片的 URL;而 download 才是要下载的高清图片的 URL。
网络爬虫毕竟是针对别人的网站“爬取” 数据的,而目标网站的结构随时可能发生改变,读者应该学习这种分析方法,而不是“生搬硬套”照抄本节的分析结果。
尝试在 shell 调试工具中查看第一张图片的下载 URL,应该在 shell 调试工具中输入如下命令:
>>> json.loads(response.text)[0]['links']['download']
'https://unsplash.com/photos/-RMY4j97SsM/download'
与图 2 中 JSON 数据对比不难看出,shell 调试工具输出的第一张图片的下载 URL 与图 2 所显示的第一张图片的下载 URL 完全相同。
由此得到一个结论,该网页加载时会自动向 https://unsplash.com/napi/photos?age=N&per_page=N 发送请求,然后根据服务器响应的 JSON 数据来动态加载图片。
由于该网页是“瀑布流”设计(所谓“瀑布流”设计,就是网页没有传统的分页按钮,而是让用户通过滚动条来实现分页,当用户向下拖动滚动条时,程序会动态载入新的分页),当我们在 Firefox 中拖动滚动条时,可以在 Firefox 的调试控制台中看到再次向 https://unsplash.com/napi/photos?page=N&per_page=N 发送了请求,只是 page 参数发生了改变。可见,为了不断地加载新的图片,程序只要不断地向该 URL 发送请求,并改变 page 参数即可。
经过以上分析,下面我们开始正式使用 Scrapy 来实现爬取高清图片。
使用Scrapy 爬取高清图片
按照惯例,使用如下命令来创建一个 Scrapy 项目:
scrapy startproject UnsplashimageSpider
然后在命令行窗口中进入 UnsplashlmageSpider 所在的目录下(不要进入 UnsplashImageSpider\UnsplashImageSpider目录下),执行如下命令来生成 Spider 类:
scrapy genspider unsplash_image 'unsplash.com
上面两个命令执行完成之后,一个简单的 Scrapy 项目就创建好了。
接下来需要修改 UnsplashImageSpider\items.py、UnsplashImageSpider\pipelines.py、UnsplashImageSpider\spiders\unsplash_image.py、UnsplashImageSpider\settings.py 文件,将它们全部改为使用 UTF-8 字符集来保存。
现在按照如下步骤来开发该爬虫项目:
- 定义 Item 类。由于本项目的目标是爬取高清图片,因此其所使用的 Item 类比较简单,只要保存图片 id 和图片下载地址即可。
下面是该项目的 Item 类的代码:
import scrapy
'''
遇到不懂的问题?Python学习交流群:1004391443满足你的需求,资料都已经上传群文件,可以自行下载!
'''
class ImageItem(scrapy.Item):
# 保存图片id
image_id = scrapy.Field()
# 保存图片下载地址
download = scrapy.Field()
上面程序为 Item 类定义了两个变量,分别用于保存图片 id 和图片下载地址。
开发 Spider。开发 Spider 就是指定 Scrapy 发送请求的 URL,并实现 parse(self, response) 方法来解析服务器响应数据。
下面是该项目的 Spider 程序:
import scrapy, json
from UnsplashImageSpider.items import ImageItem
'''
遇到不懂的问题?Python学习交流群:1004391443满足你的需求,资料都已经上传群文件,可以自行下载!
'''
class UnsplashImageSpider(scrapy.Spider):
# 定义Spider的名称
name = 'unsplash_image'
allowed_domains = ['unsplash.com']
# 定义起始页面
start_urls = ['https://unsplash.com/napi/photos?page=1&per_page=12']
def __init__ (self):
self.page_index = 1
def parse(self, response):
# 解析服务器响应的JSON字符串
photo_list = json.loads(response.text) # ①
# 遍历每张图片
for photo in photo_list:
item = ImageItem()
item['image_id'] = photo['id']
item['download'] = photo['links']['download']
yield item
self.page_index += 1
# 获取下一页的链接
next_link = 'https://unsplash.com/napi/photos?page='\
+ str(self.page_index) + '&per_page=12'
# 继续获取下一页的图片
yield scrapy.Request(next_link, callback=self.parse)
上面程序中第 9 行代码指定的 URL 是本项目爬取的第一个页面,由于该页面的响应是一个 JSON 数据,因此程序无须使用 XPath 或 CSS 选择器来“提取”数据,而是直接使用 json 模块的 loads() 函数来加载该响应数据即可。
在获取 JSON 响应数据之后,程序同样将 JSON 数据封装成 Item 对象后返回给 Scrapy 引擎。
Spider 到底应该使用 XPath 或 CSS 选择器来提取响应数据,还是使用 JSON,完全取决于目标网站的响应内容,怎么方便怎么来!总之,提取到数据之后,将数据封装成 Item 对象后返回给 Scrapy 引擎就对了。
上面程序中倒数第 2 行代码定义了加载下一页数据的 URL,接下来使用 scrapy.Request 向该 URL 发送请求,并指定使用 self.parse 方法来处理服务器响应内容,这样程序就可以不断地请求下一页的图片数据。
开发 Pipeline。Pipeline 负责保存 Spider 返回的 Item 对象(封装了爬取到的数据)。本项目爬取的目标是图片,因此程序得到图片的 URL 之后,既可将这些 URL 地址导入专门的下载工具中批量下载,也可在 Python 程序中直接下载。
本项目的 Pipeline 将使用 urllib.request 包直接下载。下面是该项目的 Pipeline 程序:
from urllib.request import *
class UnsplashimagespiderPipeline(object):
def process_item(self, item, spider):
# 每个item代表一个要下载的图片
print('----------' + item['image_id'])
real_url = item['download'] + "?force=true"
try:
pass
# 打开URL对应的资源
with urlopen(real_url) as result:
# 读取图片数据
data = result.read()
# 打开图片文件
with open("images/" + item['image_id'] + '.jpg', 'wb+') as f:
# 写入读取的数据
f.write(data)
except:
print('下载图片出现错误' % item['image_id'])
上面程序中第 7 行代码用于拼接下载图片的完整地址。可能有读者会问,为何要在图片下载地址的后面追加“?force=true”?这并不是本项目所能决定的,读者可以把鼠标指针移动到 https://unsplash.com 网站中各图片右下角的下载按钮上,即可看到各图片的下载地址都会在 download 后追加“?force=true”,此处只是模拟这种行为而已。
程序中第 11 行代码使用 urlopen() 函数获取目标 URL 的数据,接下来即可读取图片数据,并将图片数据写入下载的目标文件中。
经过上面 3 步,基于 Scrapy 开发的高清图片爬取程序基本完成。接下来依然需要对 settings.py 文件进行修改,即增加一些自定义请求头(用于模拟浏览器),设置启用指定的 Pipeline。下面是本项目修改后的 settings.py 文件:
BOT_NAME = 'UnsplashImageSpider'
SPIDER_MODULES = ['UnsplashImageSpider.spiders']
NEWSPIDER_MODULE = 'UnsplashImageSpider.spiders'
ROBOTSTXT_OBEY = True
# 配置默认的请求头
DEFAULT_REQUEST_HEADERS = {
"User-Agent" : "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:61.0) Gecko/20100101 Firefox/61.0",
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8'
}
# 配置使用Pipeline
ITEM_PIPELINES = {
'UnsplashImageSpider.pipelines.UnsplashimagespiderPipeline': 300,
}
至此,这个可以爬取高清图片的爬虫项目开发完成,读者可以在 UnsplashlmageSpider 目录下执行如下命令来启动爬虫。
scrapy crawl unsplash_image
运行该爬虫程序之后,可以看到在项目的 images 目录下不断地增加新的高清图片(对图片的爬取速度在很大程度上取决于网络下载速度),这些高清图片正是 https://unsplash.com 网站中所展示的图片。
标签:unsplash,Python,爬虫,URL,Scrapy,https,com,page,图片 来源: https://blog.csdn.net/qq_40925239/article/details/94329024