使用 Python 运行随机
作者:互联网
路线图
在深入研究编程之前,重要的是要概述一个简洁的指南,以保持我们的专注。一旦我们确定了问题并选择了模型,以下步骤为任何机器学习工作流提供了基础:
- 清楚地陈述问题并确定必要的数据。
- 以易于访问的格式获取数据。
- 根据需要识别并解决任何缺失的数据点或异常。
- 准备适合机器学习模型的数据。
- 建立一个你打算超越的基线模型。
- 使用训练数据训练模型。
- 利用模型对测试数据进行预测。
- 将模型的预测与测试集中的已知目标进行比较,并计算性能指标。
- 如果模型的性能不令人满意,请考虑调整模型、获取更多数据或尝试不同的建模技术。
- 解释模型的结果,并以视觉和数字格式报告结果。
数据采集
首先,我们需要一个数据集。为了一个实际的例子,我使用NOAA气候数据在线工具获得了2016年华盛顿州西雅图的天气数据。通常,大约 80% 的数据分析时间涉及清理和检索数据。但是,可以通过识别高质量的数据源来最大程度地减少此工作负载。NOAA工具被证明是非常用户友好的,使我们能够以干净的CSV文件的形式下载温度数据,这些文件可以使用Python或R等编程语言进行分析。对于那些希望跟随的人,完整的数据文件可供下载。
以下 Python 代码加载 csv 数据并显示数据的结构:
# Pandas is used for data manipulation
import pandas as pd
# Read in data and display first 5 rows
features = pd.read_csv('temps.csv')
features.head(5)
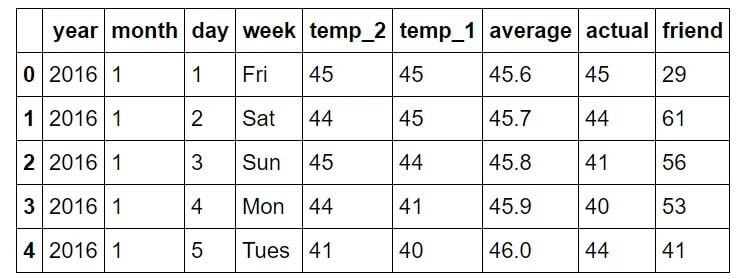
- 年份:年份,所有数据点在 2016 年保持一致。
- month:一年中月份的数字表示形式。
- day:一年中某一天的数字表示形式。
- 周:星期几,表示为字符串。
- temp_2:两天前记录的最高温度。
- temp_1:前一天记录的最高温度。
- 平均值:历史平均最高温度。
- 实际:实际测量的最高温度。
- friend:您朋友的预测,这是一个随机数,在比平均值低 20 到高于平均值 20 之间生成。
识别异常/缺失数据
在检查数据的维度后,我们观察到只有 348 行,这与 366 年的预期 2016 天不一致。在仔细检查NOAA数据后,我发现少了几天。这是一个很好的提醒,即现实世界的数据收集永远不会完美无缺。缺少数据以及不正确的数据或异常值可能会影响分析。但是,在这种情况下,丢失数据的影响预计很小,并且由于来源可靠,整体数据质量良好。
print('The shape of our features is:', features.shape)
The shape of our features is: (348, 9)
为了识别异常,我们可以快速计算汇总统计数据。
# Descriptive statistics for each column
features.describe()

在初步检查时,似乎没有任何数据点立即作为异常突出显示,并且任何测量列中都没有零。评估数据质量的另一种有效方法是创建基本图。与单独分析数值相比,图形表示通常更容易识别异常。我在这里省略了实际的代码进行绘图,因为它在 Python 中可能不直观。但是,请随时参考笔记本以获取完整实现。作为一种好的做法,我必须承认,我主要利用Stack Overflow中的现有绘图代码,就像许多数据科学家一样。
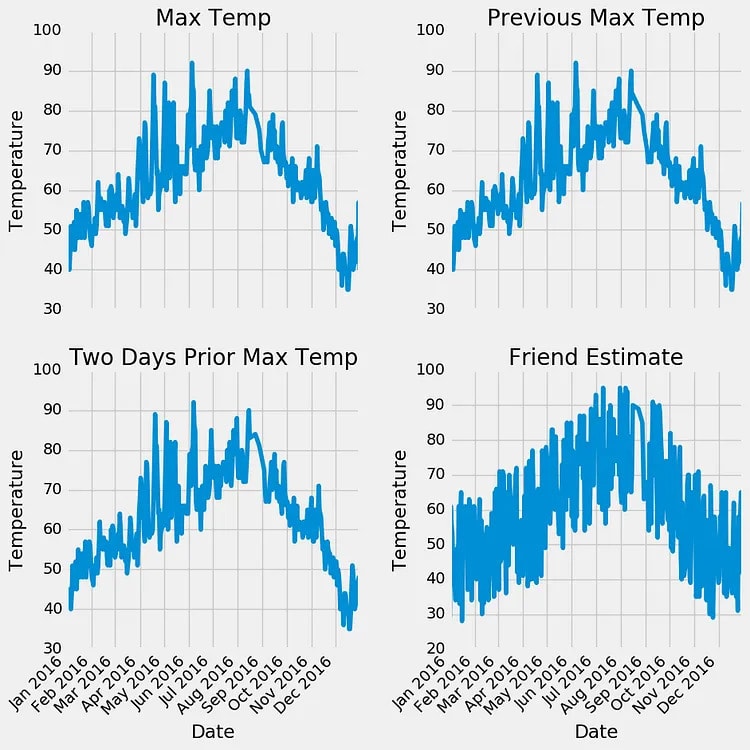
检查定量统计数据和图表,我们可以对高质量的数据充满信心。没有明显的异常值,虽然有一些遗漏点,但它们不会减损分析。
数据准备
然而,我们还没有达到可以直接将原始数据输入模型并期望它提供准确答案的阶段(尽管研究人员正在积极研究这一点!我们需要执行一些预处理,以使我们的数据可以通过机器学习算法理解。对于数据操作,我们将使用 Python 库 Pandas,它提供了一种称为数据帧的便捷数据结构,类似于带有行和列的 Excel 电子表格。
数据准备的具体步骤将根据所选模型和收集的数据而有所不同。但是,对于任何机器学习应用程序,通常都需要一定程度的数据操作。
在我们的案例中,一个重要的步骤被称为独热编码。此过程将分类变量(如星期几)转换为数字表示形式,无需任意排序。虽然我们直观地理解工作日的概念,但机器缺乏这种固有的知识。计算机主要理解数字,因此出于机器学习目的,适应它们至关重要。我们不是简单地将工作日映射到从 1 到 7 的数值,这可能会由于数字顺序而引入意外的偏差,而是采用一种称为独热编码的技术。这会将表示工作日的单个列转换为七个二进制列。让我直观地说明这一点:

and turns it into
So, if a data point is a Wednesday, it will have a 1 in the Wednesday column and a 0 in all other columns. This process can be done in pandas in a single line!
# One-hot encode the data using pandas get_dummies
features = pd.get_dummies(features)
# Display the first 5 rows of the last 12 columns
features.iloc[:,5:].head(5)
Snapshot of data after one-hot encoding:

我们数据的维度现在变成了 349 x 15,所有列都由数值组成,这对于我们的算法来说是理想的!
接下来,我们需要将数据拆分为特征和目标。目标,也称为标签,表示我们要预测的值,在本例中为实际最高温度。这些功能包含模型将用于进行预测的所有列。此外,我们将 Pandas 数据帧转换为 Numpy 数组,因为这是算法的预期格式。为了保留与功能名称对应的列标题,我们将将它们存储在列表中,以便稍后进行可视化。
# Use numpy to convert to arrays
import numpy as np
# Labels are the values we want to predict
labels = np.array(features['actual'])
# Remove the labels from the features
# axis 1 refers to the columns
features= features.drop('actual', axis = 1)
# Saving feature names for later use
feature_list = list(features.columns)
# Convert to numpy array
features = np.array(features)
数据准备的下一步涉及将数据拆分为训练集和测试集。在训练阶段,我们将模型暴露给答案(在本例中为实际温度),以便它可以学习如何根据给定的特征预测温度。我们预测特征和目标值之间的关系,模型的任务是在训练期间学习这种关系。在评估模型的性能时,我们要求它在单独的测试集上进行预测,在该测试集上,它只能访问特征(没有答案)。由于我们有测试集的实际答案,我们可以将模型的预测与真实值进行比较,以评估其准确性。
通常,在训练模型时,我们会将数据随机拆分为训练集和测试集,以确保所有数据点的代表性样本。如果我们仅根据一年前九个月的数据训练模型,然后使用最后三个月进行预测,则模型的性能将不是最佳的,因为它没有遇到过去三个月的任何数据。在本例中,我将随机状态设置为 42,这可确保拆分的结果在多次运行中保持一致,从而实现可重现的结果。
以下代码用另一行拆分数据集:
# Using Skicit-learn to split data into training and testing sets
from sklearn.model_selection import train_test_split
# Split the data into training and testing sets
train_features, test_features, train_labels, test_labels = train_test_split(features, labels, test_size = 0.25, random_state = 42)
我们可以查看所有数据的形状,以确保我们正确地完成了所有操作。我们希望训练特征的列数与测试特征的列数相匹配,并且与相应的训练和测试特征以及标签相匹配的行数:
print('Training Features Shape:', train_features.shape)
print('Training Labels Shape:', train_labels.shape)
print('Testing Features Shape:', test_features.shape)
print('Testing Labels Shape:', test_labels.shape)
Training Features Shape: (261, 14)
Training Labels Shape: (261,)
Testing Features Shape: (87, 14)
Testing Labels Shape: (87,)
看来一切都井井有条!让我们回顾一下我们为机器学习准备数据所采取的步骤:
- 独热编码分类变量。
- 将数据拆分为要素和标注。
- 将数据转换为数组。
- 将数据拆分为训练集和测试集。 根据初始数据集,可能涉及其他任务,例如处理异常值、插补缺失值或将时态变量转换为周期性表示。这些步骤最初可能看起来很随意,但一旦掌握了基本的工作流程,你会发现它在各种机器学习问题上基本保持一致。最终,目标是将人类可读的数据转换为机器学习模型可以理解的格式。
建立基线
在做出和评估预测之前,必须建立一个基线,即我们旨在通过我们的模型超越的合理基准。如果我们的模型未能改进基线,则表明我们应该探索替代模型,或者承认机器学习可能不适合我们的特定问题。在我们的例子中,基线预测可以从历史平均最高温度得出。简而言之,我们的基线表示如果我们要预测所有天的平均最高温度,我们将产生的误差。
# The baseline predictions are the historical averages
baseline_preds = test_features[:, feature_list.index('average')]
# Baseline errors, and display average baseline error
baseline_errors = abs(baseline_preds - test_labels)
print('Average baseline error: ', round(np.mean(baseline_errors), 2))
Average baseline error: 5.06 degrees.
我们现在有了我们的目标!如果我们不能击败5度的平均误差,那么我们需要重新考虑我们的方法。
训练模型
完成数据准备步骤后,使用Scikit-learn创建和训练模型的过程变得相对简单。我们可以通过从Scikit-learn导入随机森林回归模型,初始化模型的实例,并将模型与训练数据拟合(Scikit-learn的训练术语)来实现这一点。为了确保结果可重复,我们可以设置随机状态。值得注意的是,整个过程只需在Scikit-learn中的三行代码中即可实现!
# Import the model we are using
from sklearn.ensemble import RandomForestRegressor
# Instantiate model with 1000 decision trees
rf = RandomForestRegressor(n_estimators = 1000, random_state = 42)
# Train the model on training data
rf.fit(train_features, train_labels);
对测试集进行预测
现在,我们的模型已经过训练,可以学习特征和目标之间的关系,下一步是评估其性能。为了实现这一点,我们需要对测试特征进行预测(确保模型无法访问测试答案)。随后,我们将这些预测与已知答案进行比较。在回归任务中,使用绝对误差指标至关重要,因为我们在预测中预计会出现一系列低值和高值。我们主要感兴趣的是量化我们的预测和实际值之间的平均差异,因此使用绝对误差(就像我们在建立基线时所做的那样)。
在Scikit-learn中,使用我们的模型进行预测就像执行一行代码一样简单。
# Use the forest's predict method on the test data
predictions = rf.predict(test_features)
# Calculate the absolute errors
errors = abs(predictions - test_labels)
# Print out the mean absolute error (mae)
print('Mean Absolute Error:', round(np.mean(errors), 2), 'degrees.')
Mean Absolute Error: 3.83 degrees.
我们的平均估计偏差了3.83度。这比基线平均提高了1度以上。虽然这看起来并不重要,但它比基线好近 25%,根据领域和问题的不同,基线对公司来说可能意味着数百万美元。
确定性能指标
为了正确看待我们的预测,我们可以使用从 100% 中减去平均百分比误差来计算准确性。
# Calculate mean absolute percentage error (MAPE)
mape = 100 * (errors / test_labels)
# Calculate and display accuracy
accuracy = 100 - np.mean(mape)
print('Accuracy:', round(accuracy, 2), '%.')
Accuracy: 93.99 %.
这看起来还不错!我们的模型已经学会了如何以94%的准确率预测西雅图第二天的最高温度。
必要时改进模型
在典型的机器学习工作流程中,我们通常会继续进行超参数调优。此过程涉及调整模型的设置以增强其性能。这些设置称为超参数,将它们与训练期间学习的模型参数区分开来。最常见的超参数优化方法包括创建具有不同设置的多个模型,在同一验证集上评估所有模型,并确定哪种配置产生最佳性能。但是,手动执行此过程会很费力,因此Scikit-learn中提供了自动化方法来简化任务。重要的是要注意,超参数调优通常更像是一种工程实践,而不是基于理论的,我鼓励那些有兴趣的人探索文档并开始实验。对于此问题,达到 94% 的准确度被认为是令人满意的。但是,值得注意的是,构建的初始模型不太可能是将其投入生产的模型,因为模型改进是一个迭代过程。
解释模型和报告结果
在这一点上,我们知道我们的模型很好,但它几乎是一个黑匣子。我们输入一些 Numpy 数组进行训练,要求它做出预测,评估预测,并查看它们是合理的。问题是:这个模型是如何得出这些值的?有两种方法可以深入了解随机森林:首先,我们可以查看森林中的一棵树,其次,我们可以查看解释变量的特征重要性。
可视化单个决策树
Skicit-learn 中随机森林实现中最酷的部分之一是我们可以实际检查森林中的任何树。我们将选择一棵树,并将整棵树另存为图像。
以下代码从林中获取一棵树并将其另存为图像。
# Import tools needed for visualization
from sklearn.tree import export_graphviz
import pydot
# Pull out one tree from the forest
tree = rf.estimators_[5]
# Import tools needed for visualization
from sklearn.tree import export_graphviz
import pydot
# Pull out one tree from the forest
tree = rf.estimators_[5]
# Export the image to a dot file
export_graphviz(tree, out_file = 'tree.dot', feature_names = feature_list, rounded = True, precision = 1)
# Use dot file to create a graph
(graph, ) = pydot.graph_from_dot_file('tree.dot')
# Write graph to a png file
graph.write_png('tree.png')
一起来看看:
哇!这看起来像一棵有 15 层的广阔树(实际上,与我见过的一些树相比,这是一棵相当小的树)。您可以自己下载此图像并对其进行更详细的检查,但为了使事情变得更容易,我将限制森林中树木的深度以生成易于理解的图像。
# Limit depth of tree to 3 levels
rf_small = RandomForestRegressor(n_estimators=10, max_depth = 3)
rf_small.fit(train_features, train_labels)
# Extract the small tree
tree_small = rf_small.estimators_[5]
# Save the tree as a png image
export_graphviz(tree_small, out_file = 'small_tree.dot', feature_names = feature_list, rounded = True, precision = 1)
(graph, ) = pydot.graph_from_dot_file('small_tree.dot')
graph.write_png('small_tree.png');
这是用标签注释的缩小大小的树
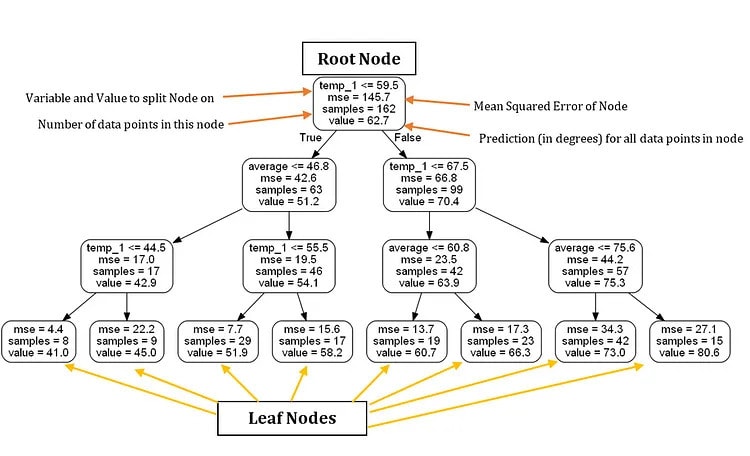
仅基于此决策树,我们可以对新数据点进行预测。让我们考虑一个预测 27 年 2017 月 2 日星期三最高温度的示例,其值如下:temp_39 = 1,temp_35 = 44,平均值 = 30,朋友 = <>。
从根节点开始,我们遇到第一个问题,答案为 True,因为temp_1 ≤ 59.5。我们继续向左走,遇到第二个问题,这也是正确的,因为平均≤ 46.8。继续向左走,我们到达第三个也是最后一个问题,由于 1.44 temp_5 ≤,它再次为 True。因此,我们得出结论,我们对最高温度的估计值为 41.0 度,如叶节点中的值所示。
一个有趣的观察结果是,尽管有 162 个训练数据点,但根节点仅包含 261 个样本。这是因为随机森林中的每棵树都是在数据点的随机子集上进行训练的,这种技术称为baging(引导聚合)。如果我们想使用所有数据点而不进行替换采样,我们可以通过在构建森林时设置 bootstrap = False 来禁用它。数据点的随机采样和每个节点的特征子集的组合是该模型被称为“随机”森林的原因。
此外,值得注意的是,在我们的决策树中,我们只利用两个变量进行预测。根据这棵特定的树,其余的特征,如一年中的月份、月份中的某一天和我们朋友的预测被认为与预测明天的最高温度无关。树的可视化表示增加了我们对问题域的理解,使我们能够在进行预测时辨别要考虑哪些数据。
可变重要性
为了评估随机森林中所有变量的显著性,我们可以检查它们的相对重要性。从Scikit-learn获得的重要性表明包含特定变量在多大程度上增强了预测。虽然重要性的精确计算超出了本文的范围,但我们可以利用这些值在变量之间进行相对比较。
提供的代码利用了 Python 语言中的几种有用技术,包括列表推导、zip、排序和参数解包。虽然理解这些技术目前并不重要,但如果您渴望提高对该语言的熟练程度,它们是您的 Python 曲目中的宝贵工具。
# Get numerical feature importances
importances = list(rf.feature_importances_)
# List of tuples with variable and importance
feature_importances = [(feature, round(importance, 2)) for feature, importance in zip(feature_list, importances)]
# Sort the feature importances by most important first
feature_importances = sorted(feature_importances, key = lambda x: x[1], reverse = True)
# Print out the feature and importances
[print('Variable: {:20} Importance: {}'.format(*pair)) for pair in feature_importances];
Variable: temp_1 Importance: 0.7
Variable: average Importance: 0.19
Variable: day Importance: 0.03
Variable: temp_2 Importance: 0.02
Variable: friend Importance: 0.02
Variable: month Importance: 0.01
Variable: year Importance: 0.0
Variable: week_Fri Importance: 0.0
Variable: week_Mon Importance: 0.0
Variable: week_Sat Importance: 0.0
Variable: week_Sun Importance: 0.0
Variable: week_Thurs Importance: 0.0
Variable: week_Tues Importance: 0.0
Variable: week_Wed Importance: 0.0
重要性列表的顶部是“temp_1”,即前一天的最高温度。这一发现证实了给定日期最高温度的最佳预测指标是前一天记录的最高温度,这与我们的直觉一致。第二个最有影响力的因素是历史平均最高温度,这也是一个合乎逻辑的结果。令人惊讶的是,您朋友的预测以及两天前的星期几、年、月和温度等变量似乎对预测最高温度没有帮助。这些重要性是有道理的,因为我们不希望星期几对天气有任何影响。此外,所有数据点的年份保持不变,因此对于预测最高温度毫无用处。
在模型的未来实现中,我们可以排除这些变量,其重要性可以忽略不计,并且性能不会受到影响。此外,如果我们采用不同的模型,例如支持向量机,我们可以利用随机森林特征重要性作为特征选择的一种形式。为了证明这一点,我们可以仅使用两个最重要的变量(前一天的最高温度和历史平均值)快速构建一个随机森林,并将其性能与原始模型进行比较。
# New random forest with only the two most important variables
rf_most_important = RandomForestRegressor(n_estimators= 1000, random_state=42)
# Extract the two most important features
important_indices = [feature_list.index('temp_1'), feature_list.index('average')]
train_important = train_features[:, important_indices]
test_important = test_features[:, important_indices]
# Train the random forest
rf_most_important.fit(train_important, train_labels)
# Make predictions and determine the error
predictions = rf_most_important.predict(test_important)
errors = abs(predictions - test_labels)
# Display the performance metrics
print('Mean Absolute Error:', round(np.mean(errors), 2), 'degrees.')
mape = np.mean(100 * (errors / test_labels))
accuracy = 100 - mape
print('Accuracy:', round(accuracy, 2), '%.')
Mean Absolute Error: 3.9 degrees.
Accuracy: 93.8 %.
这一见解突出表明,我们不一定需要所有收集的数据来做出准确的预测。事实上,如果我们继续使用这个模型,我们可以将数据收集范围缩小到两个最重要的变量,并实现几乎相同的性能水平。但是,在生产环境中,我们需要考虑准确性降低与收集更多信息所需的额外时间和资源之间的权衡。在性能和成本之间取得适当的平衡是机器学习工程师的一项重要技能,最终将取决于手头的具体问题。
在此阶段,我们已经介绍了为监督回归问题实现随机森林模型的基础知识。我们可以确信,我们的模型可以利用一年的历史数据,以94%的准确率预测明天的最高温度。从这里开始,随意试验此示例或将模型应用于所选数据集。最后,我将深入研究一些可视化。作为一名数据科学家,我发现创建图形和模型非常快乐,可视化不仅提供了审美乐趣,而且还通过将丰富的数字信息浓缩成易于理解的图像来帮助我们诊断模型。
可视 化
为了可视化变量相对重要性的差异,我将创建特征重要性的简单条形图。在 Python 中绘图可能有点不直观,在创建图形时,我经常发现自己在 Stack Overflow 上寻找解决方案。如果提供的代码不完全有意义,请不要担心 - 有时,理解每一行代码对于实现预期结果并不重要!
# Import matplotlib for plotting and use magic command for Jupyter Notebooks
import matplotlib.pyplot as plt
%matplotlib inline
# Set the style
plt.style.use('fivethirtyeight')
# list of x locations for plotting
x_values = list(range(len(importances)))
# Make a bar chart
plt.bar(x_values, importances, orientation = 'vertical')
# Tick labels for x axis
plt.xticks(x_values, feature_list, rotation='vertical')
# Axis labels and title
plt.ylabel('Importance'); plt.xlabel('Variable'); plt.title('Variable Importances');

接下来,我们可以绘制整个数据集,突出显示预测。这需要一点数据操作,但并不太困难。我们可以使用此图来确定数据或预测中是否存在任何异常值。
# Use datetime for creating date objects for plotting
import datetime
# Dates of training values
months = features[:, feature_list.index('month')]
days = features[:, feature_list.index('day')]
years = features[:, feature_list.index('year')]
# List and then convert to datetime object
dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in zip(years, months, days)]
dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in dates]
# Dataframe with true values and dates
true_data = pd.DataFrame(data = {'date': dates, 'actual': labels})
# Dates of predictions
months = test_features[:, feature_list.index('month')]
days = test_features[:, feature_list.index('day')]
years = test_features[:, feature_list.index('year')]
# Column of dates
test_dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in zip(years, months, days)]
# Convert to datetime objects
test_dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in test_dates]
# Dataframe with predictions and dates
predictions_data = pd.DataFrame(data = {'date': test_dates, 'prediction': predictions})
# Plot the actual values
plt.plot(true_data['date'], true_data['actual'], 'b-', label = 'actual')
# Plot the predicted values
plt.plot(predictions_data['date'], predictions_data['prediction'], 'ro', label = 'prediction')
plt.xticks(rotation = '60');
plt.legend()
# Graph labels
plt.xlabel('Date'); plt.ylabel('Maximum Temperature (F)'); plt.title('Actual and Predicted Values');
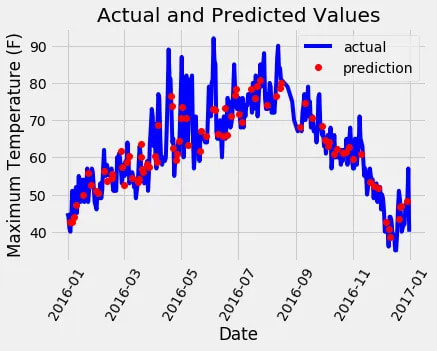
创建一个视觉上吸引人的图表确实需要一些努力,但最终结果是值得的!从数据来看,我们似乎没有任何明显的异常值需要解决。为了进一步了解模型的性能,我们可以绘制残差(即误差)以确定模型是倾向于高预测还是预测不足。此外,检查残差的分布有助于评估它们是否服从正态分布。但是,出于最终图表的目的,我将专注于可视化实际值、前一天的温度、历史平均值和我们朋友的预测。这种可视化将帮助我们辨别有用变量和提供价值较低的信息变量之间的区别。
# Make the data accessible for plotting
true_data['temp_1'] = features[:, feature_list.index('temp_1')]
true_data['average'] = features[:, feature_list.index('average')]
true_data['friend'] = features[:, feature_list.index('friend')]
# Plot all the data as lines
plt.plot(true_data['date'], true_data['actual'], 'b-', label = 'actual', alpha = 1.0)
plt.plot(true_data['date'], true_data['temp_1'], 'y-', label = 'temp_1', alpha = 1.0)
plt.plot(true_data['date'], true_data['average'], 'k-', label = 'average', alpha = 0.8)
plt.plot(true_data['date'], true_data['friend'], 'r-', label = 'friend', alpha = 0.3)
# Formatting plot
plt.legend(); plt.xticks(rotation = '60');
# Lables and title
plt.xlabel('Date'); plt.ylabel('Maximum Temperature (F)'); plt.title('Actual Max Temp and Variables');

图表上的线条可能看起来有点拥挤,但我们仍然可以观察到为什么前一天的最高温度和历史平均最高温度对于预测最高温度很有价值。相反,很明显,我们朋友的预测并没有提供显着的预测能力(但我们不要完全忽视我们朋友的输入,尽管我们应该谨慎地严重依赖他们的估计)。提前创建这样的图形可以帮助我们选择要包含在模型中的适当变量,它们也可以作为有价值的诊断工具。就像安斯科姆的四重奏一样,图表经常揭示出仅靠定量数字可能忽略的见解。强烈建议将可视化作为任何机器学习工作流的一部分。