2022年北航面向对象程序设计第四单元总结
作者:互联网
2022年北航面向对象程序设计第四单元总结
目录- 2022年北航面向对象程序设计第四单元总结
本学期的最后一次OO blog啦~
第四单元 homework
第一周的内容主要是类的查询命令,由于这三周的内容都是迭代开发的(且三周的内容在上一周的内容上近乎是完全隔离的,只是可能会因为前两周的实现导致第三周实现的简易度),因此这里就以第三周的架构来讲解
类图

(个人感觉Association关系的描述有点不太直接,这周博客没类图的要求,因此就直接摆Diagram,其实想摆官方的豪华版Diagram,无奈导出的太大,插件不支持了,悲)
内容概述
总的来看三周的内容的分配还算比较平均,第一周的任务是实现类图的查询指令,第一周的麻烦在于对第四单元整个工程项目和任务的理解(个人开始做的时候着实是一头雾水,看了半天代码才知道开发的部分),另外就是第一周各个类的架构的关联度还是挺大的吧(相比于二三周的内容),整体的实现的关联度很大,可能会因为一个实现不合理而改架构,还有会因为找到一个bug而被迫改架构,总之第一周的实现个人感觉挺痛苦的,第二周相对较好,内容是实现顺序图和状态图的查询指令,第二周麻烦点在于状态图割点的查找和顺序图题目的理解,相较之下不是很难,第三周的内容是UML的规则检查,也是很多指令都是非常简单的,麻烦点在于循环继承的判断和重复继承的判断,顺便复习了一下Tarjan算法,感觉熟悉Tarjan算法的话这一周非常简单,或者干脆不用算法优化,暴力dfs也是非常简单的
架构设计
第一周
用了MyClass, MyInterface, MyMethod三个交互类 + MyImplementation, Main, Debug三个运行类(Parser为第三周为了不丢CodeStyle分被迫把MyImplementation分开写的,可以看成一个)实现
指令 1:模型中一共有多少个类
输入指令格式:CLASS_COUNT
举例:CLASS_COUNT
输出:
Total class count is x.- 其中
x为模型中类的总数。
- 其中
指令1的实现只需要在MyImplementation里加一个class的容器来记录,执行该指令的时候返回size就可以
指令 2:类的子类数量
输入指令格式:CLASS_SUBCLASS_COUNT classname
举例:CLASS_SUBCLASS_COUNT Elevator
输出:
Ok, subclass count of class "classname" is x.- 其中
x为直接继承类classname的子类数量;
- 其中
Failed, class "classname" not found.- 不存在名为
classname的类时,输出上述内容;
- 不存在名为
Failed, duplicated class "classname".- 存在多个名为
classname的类时,输出上述内容。
- 存在多个名为
这一操作构建的执行构建在myClass类内,异常判断在执行指令段,由于以下还会会多次出现需要判断classname的异常,这里给个我的写法(比较无脑)
private final HashMap<String, MyClass> classMap;
public int getClassSubClassCount(String className)
throws ClassNotFoundException, ClassDuplicatedException {
int cnt = 0;
Iterator<Map.Entry<String, MyClass>> iterator = classMap.entrySet().iterator();
MyClass myClass = null;
while (iterator.hasNext()) {
Map.Entry<String, MyClass> entry = iterator.next();
if (entry.getValue().getName().equals(className)) {
myClass = entry.getValue();
cnt++;
}
}
if (cnt == 0) {
throw new ClassNotFoundException(className);
} else if (cnt > 1) {
throw new ClassDuplicatedException(className);
}
return myClass.getClassSubClassCount();
}
对于myClass内的getClassSubClassCount()方法,是在构造myClass时记录其加入的subClass,然后返回那一容器的size
指令 3:类中的操作有多少个
输入指令格式:CLASS_OPERATION_COUNT classname
举例:CLASS_OPERATION_COUNT Elevator
输出:
Ok, operation count of class "classname" is x.- 其中
x为类classname中的操作个数;
- 其中
Failed, class "classname" not found.- 不存在名为
classname的类时,输出上述内容;
- 不存在名为
Failed, duplicated class "classname".- 存在多个名为
classname的类时,输出上述内容。
- 存在多个名为
说明:
- 本指令中统计的一律为此类自己定义的操作,不包含继承自其各级父类所定义的操作;
- 本指令中统计的无需考虑重复操作带来的影响。若有多个操作为重复操作,则这些操作都需要分别计入答案。
这一指令的实现同指令2
指令 4:类的操作可见性
输入指令格式:CLASS_OPERATION_VISIBILITY classname methodname
举例:CLASS_OPERATION_VISIBILITY Taxi setStatus
输出:
Ok, operation visibility of method "methodname" in class "classname" is public: www, protected: xxx, private: yyy, package-private: zzz.- 其中
www/xxx/yyy/zzz分别表示类classname中,名为methodname且实际可见性分别为public/protected/private/package-private的操作个数; - 如果类中不存在名为
methodname的操作,则www/xxx/yyy/zzz全部设置为 0;
- 其中
Failed, class "classname" not found.- 不存在名为
classname的类时,输出上述内容;
- 不存在名为
Failed, duplicated class "classname".- 存在多个名为
classname的类时,输出上述内容。
- 存在多个名为
说明:
- 本指令中统计的一律为此类自己定义的操作,不包含继承自其各级父类所定义的操作;
- 在上一条的前提下,需要统计出全部的名为
methodname的操作的可见性信息。 - 本指令中统计的无需考虑重复操作带来的影响。若有多个操作为重复操作,则这些操作都需要分别计入答案。
这一指令的实现仅需要遍历MyClass内的method容器,然后开一个Map记录次数即可
指令 5:类的操作的耦合度
输入指令格式:CLASS_OPERATION_COUPLING_DEGREE classname methodname
举例:CLASS_OPERATION_COUPLING_DEGREE Taxi setStatus
输出:
Ok, method "methodname" in class "classname" has coupling degree: coupling_degree_1, coupling_degree_2, coupling_degree_3.- 此例中,类中名为
methodname的操作共有 3 个,它们的操作的耦合度分别为coupling_degree_1、coupling_degree_2、coupling_degree_3,且这些操作中不存在重复操作; - 传出列表时可以乱序,官方接口会自动进行排序(但是需要编写者自行保证不重不漏);
- 如果类中不存在名为
methodname的操作,则传出一个空列表;
- 此例中,类中名为
Failed, class "classname" not found.- 不存在名为
classname的类时,输出上述内容;
- 不存在名为
Failed, duplicated class "classname".- 存在多个名为
classname的类时,输出上述内容;
- 存在多个名为
Failed, wrong type of parameters or return value in method "methodname" of class "classname".- 类
classname中所有名为methodname的操作存在错误类型时,输出上述内容;
- 类
Failed, duplicated method "methodname" in class "classname".- 类
classname中所有名为methodname的操作存在重复操作时,输出上述内容。
- 类
说明:
- 本指令中统计的一律为此类自己定义的操作,不包含继承自其各级父类所定义的操作;
- 如果同时存在错误类型和重复操作两种异常,按错误类型异常处理。
这一指令的实现相较较为麻烦,最开始看的时候主要是理解任务说明的统计方式吧,然后就又是Map/Set集合的Compare了(然后我开始时竟然又一次因为重写equals出了bug)
我的实现方式是在MyClass中进行Method的重复判断和name的重复判断
private final String name;
private final HashMap<String, MyMethod> methods = new HashMap<>();
public List<Integer> getClassOperationCouplingDegree(String methodName)
throws MethodWrongTypeException, MethodDuplicatedException {
ArrayList<MyMethod> operations = new ArrayList<>();
for (Map.Entry<String, MyMethod> entry : methods.entrySet()) {
if (entry.getValue().getName().equals(methodName)) {
operations.add(entry.getValue());
}
}
boolean duplicatedFlag = false;
for (int i = 0; i < operations.size() - 1; i++) {
for (int j = i + 1; j < operations.size(); j++) {
HashMap<NameableType, Integer> parameterList1 = new HashMap<>();
HashMap<NameableType, Integer> parameterList2 = new HashMap<>();
for (UmlParameter umlParameter : operations.get(i).getParameters().values()) {
parameterList1.merge(umlParameter.getType(), 1, Integer::sum);
}
for (UmlParameter umlParameter : operations.get(j).getParameters().values()) {
parameterList2.merge(umlParameter.getType(), 1, Integer::sum);
}
if (parameterList1.equals(parameterList2)) {
duplicatedFlag = true;
}
}
}
ArrayList<Integer> returnList = new ArrayList<>();
for (MyMethod method : operations) {
returnList.add(method.getCouplingDegree(this));
}
if (duplicatedFlag) {
throw new MethodDuplicatedException(this.name, methodName);
}
return returnList;
}
然后再MyMethod下进行统计
private final String name;
private UmlParameter returnParameter;
private final Map<String, UmlParameter> parameters = new HashMap<>();
public int getCouplingDegree(MyClass myClass) throws MethodWrongTypeException {
ArrayList<String> hasAdd = new ArrayList<>();
int cnt = 0;
if (returnParameter != null && returnParameter.getType() instanceof NamedType) {
if (!type.contains(((NamedType) returnParameter.getType()).getName()) &&
!((NamedType) returnParameter.getType()).getName().equals("void")) {
throw new MethodWrongTypeException(myClass.getName(), this.name);
}
}
for (Map.Entry<String, UmlParameter> entry : parameters.entrySet()) {
if (entry.getValue().getType() instanceof NamedType) {
if (!type.contains(((NamedType)entry.getValue().getType()).getName())) {
throw new MethodWrongTypeException(myClass.getName(), this.name);
}
}
}
for (Map.Entry<String, UmlParameter> entry : parameters.entrySet()) {
if (entry.getValue().getType() instanceof ReferenceType) {
if (!((ReferenceType)entry.getValue().getType()).
getReferenceId().equals(myClass.getId())) {
if (!hasAdd.contains(((ReferenceType)entry.getValue().getType()).
getReferenceId())) {
cnt++;
hasAdd.add(((ReferenceType)entry.getValue().getType()).getReferenceId());
}
}
}
}
if (returnParameter != null && returnParameter.getType() instanceof ReferenceType) {
if (!((ReferenceType)returnParameter.getType()).getReferenceId().
equals(myClass.getId())) {
if (!hasAdd.contains(((ReferenceType)returnParameter.getType()).getReferenceId())) {
cnt++;
hasAdd.add(((ReferenceType)returnParameter.getType()).getReferenceId());
}
}
}
return cnt;
}
指令 6:类的属性的耦合度
输入指令格式:CLASS_ATTR_COUPLING_DEGREE classname
举例:CLASS_ATTR_COUPLING_DEGREE Taxi
输出:
Ok, attributes in class "classname" has coupling degree x.- 其中
x为类classname的属性的耦合度
- 其中
Failed, class "classname" not found.- 不存在名为
classname的类时,输出上述内容;
- 不存在名为
Failed, duplicated class "classname".- 存在多个名为
classname的类时,输出上述内容。
- 存在多个名为
说明:
- 本指令的查询需要考虑继承自其各级父类所定义的属性,但不需要考虑实现的接口所定义的属性(无论是直接实现还是通过父类或者接口继承等方式间接实现,都算做实现了接口);
- 本查询中忽略属性名称相同的错误。
这一操作相对较易,只需要开一个集合统计每个Attribute的ReferenceType情况即可
指令 7:类实现的全部接口
输入指令格式:CLASS_IMPLEMENT_INTERFACE_LIST classname
举例:CLASS_IMPLEMENT_INTERFACE_LIST Taxi
输出:
Ok, implement interfaces of class "classname" are (A, B, C).- 此例中,类
classname实现了A、B、C这 3 个接口; - 无论是直接实现还是通过父类或者接口继承等方式间接实现,都算做实现了接口;
- 传出列表时可以乱序,官方接口会自动进行排序(但是需要编写者自行保证不重不漏);
- 如果类
classname没有实现任何接口,则传出一个空列表;
- 此例中,类
Failed, class "classname" not found.- 不存在名为
classname的类时,输出上述内容;
- 不存在名为
Failed, duplicated class "classname".- 存在多个名为
classname的类时,输出上述内容。
- 存在多个名为
这一操作也仅需要在类内添加好其实现的接口即可,需要注意的是要先设置好接口的继承关系,然后再完成实现比较方便(不直接也行,只不过感觉相对会很麻烦),这一操作的关键其实也是接口上的递归继承关系和多继承关系
指令 8:类的继承深度
输入指令格式:CLASS_DEPTH_OF_INHERITANCE classname
举例:CLASS_DEPTH_OF_INHERITANCE AdvancedTaxi
输出:
Ok, depth of inheritance of class "classname" is x.- 其中
x为类classname的继承深度;
- 其中
Failed, class "classname" not found.- 不存在名为
classname的类时,输出上述内容;
- 不存在名为
Failed, duplicated class "classname".- 存在多个名为
classname的类时,输出上述内容。
- 存在多个名为
这一操作我的实现方式是每次处理继承时都从根类开始设置深度标志,也是一个简单的递归
第二周
顺序图
新增了MyInteraction, MyCollaboration, MyLifeLine实现,其中MyCollaboration在本周任务中并非必要,因为顺序图中的Represent的加入关系链,我添加这一个类相对比较易于实现这一要求(但实现后发现不是必需的,只不过阴差阳错刚好是下一周的一个指令,只能说是赚大了)
我的主要操作在Interaction中实现

(感觉对着这个比较方便阐述~)
指令 1:给定 UML 顺序图,一共有多少个参与对象
输入指令格式:PTCP_OBJ_COUNT umlinteraction_name
举例:PTCP_OBJ_COUNT normal
输出:
Ok, participant count of umlinteraction "umlinteraction_name" is x.- 其中
x为顺序图模型umlinteraction_name(UMLInteraction)中的参与对象(UMLLifeline)个数;
- 其中
Failed, umlinteraction "umlinteraction_name" not found.- 不存在名为
umlinteraction_name的顺序图模型时,输出上述内容;
- 不存在名为
Failed, duplicated umlinteraction "umlinteraction_name".- 存在多个名为
umlinteraction_name的顺序图模型时,输出上述内容。
- 存在多个名为
这里异常的判断同上周,调用直接return这里的lifeline的size
指令 2:给定 UML 顺序图和参与对象,找出能创建该参与对象的另一个参与对象
输入指令格式:PTCP_CREATOR umlinteraction_name lifeline_name
举例:PTCP_CREATOR normal door
输出:
Ok, lifeline "lifeline_name" in umlinteraction "umlinteraction_name" can be created by "creator_name".- 其中
creator_name为顺序图模型umlinteraction_name中能创建lifeline_name的参与对象;
- 其中
Failed, umlinteraction "umlinteraction_name" not found.- 不存在名为
umlinteraction_name的顺序图模型时,输出上述内容;
- 不存在名为
Failed, duplicated umlinteraction "umlinteraction_name".- 存在多个名为
umlinteraction_name的顺序图模型时,输出上述内容。
- 存在多个名为
Failed, lifeline "lifeline_name" in umlinteraction "umlinteraction_name" not found.- 顺序图模型
umlinteraction_name中不存在名为lifeline_name的参与对象时,输出上述内容;
- 顺序图模型
Failed, duplicated lifeline "lifeline_name" in umlinteraction "umlinteraction_name".- 顺序图模型
umlinteraction_name中存在多个名为lifeline_name的参与对象时,输出上述内容;
- 顺序图模型
Failed, lifeline "lifeline_name" in umlinteraction "umlinteraction_name" is never created.- 顺序图模型
umlinteraction_name中的参与对象lifeline_name没有收到创建消息时,输出上述内容;
- 顺序图模型
Failed, lifeline "lifeline_name" in umlinteraction "umlinteraction_name" is created repeatedly.- 顺序图模型
umlinteraction_name中的参与对象lifeline_name收到多条创建消息时,输出上述内容。
- 顺序图模型
说明:
- 测试数据中不会出现 Endpoint 向 Lifeline 发送 Create Message 的情况。
这里只需要特判一下CreateMessage然后直接根据Create Message去Lifeline里找就可以了
指令 3:给定 UML 顺序图和参与对象,收到了多少个 Found 消息,发出了多少个 Lost 消息。
输入指令格式:PTCP_LOST_AND_FOUND umlinteraction_name lifeline_name
举例:PTCP_LOST_AND_FOUND normal door
输出:
Ok, incoming found message and outgoing lost message count of lifeline "lifeline_name" of umlinteraction "umlinteraction_name" is x and y.- 其中
x为顺序图模型umlinteraction_name(UMLInteraction)中lifeline_name收到的 Found 的消息个数,y为发送的 Lost 消息个数;
- 其中
Failed, umlinteraction "umlinteraction_name" not found.- 不存在名为
umlinteraction_name的顺序图模型时,输出上述内容;
- 不存在名为
Failed, duplicated umlinteraction "umlinteraction_name".- 存在多个名为
umlinteraction_name的顺序图模型时,输出上述内容。
- 存在多个名为
Failed, lifeline "lifeline_name" in umlinteraction "umlinteraction_name" not found.- 顺序图模型
umlinteraction_name中不存在名为lifeline_name的参与对象时,输出上述内容;
- 顺序图模型
Failed, duplicated lifeline "lifeline_name" in umlinteraction "umlinteraction_name".- 顺序图模型
umlinteraction_name中存在多个名为lifeline_name的参与对象时,输出上述内容;
- 顺序图模型
说明:
- Found 消息为来自 Endpoint 的消息,Lost 消息为发送至 Endpoint 的消息。
这里也是在加Message的时候特判一下来源或者是目标中包含Endpoint的情况然后对应去Lifeline中添加即可
状态图
这里新增了MyRegion, MyTransition, MyState, MyStateMachine(我的MyStateMachine类可有可无,直接用UMLStateMachine就可以的)
主要操作还是在MyRegion中实现(其实同顺序图一样,是顺序图包含Interaction,状态图包含Region,但是这两个都可以是一对多的关系,不像类图中的关系,因此这样通过Region和Interaction的方式集中实现更方便)
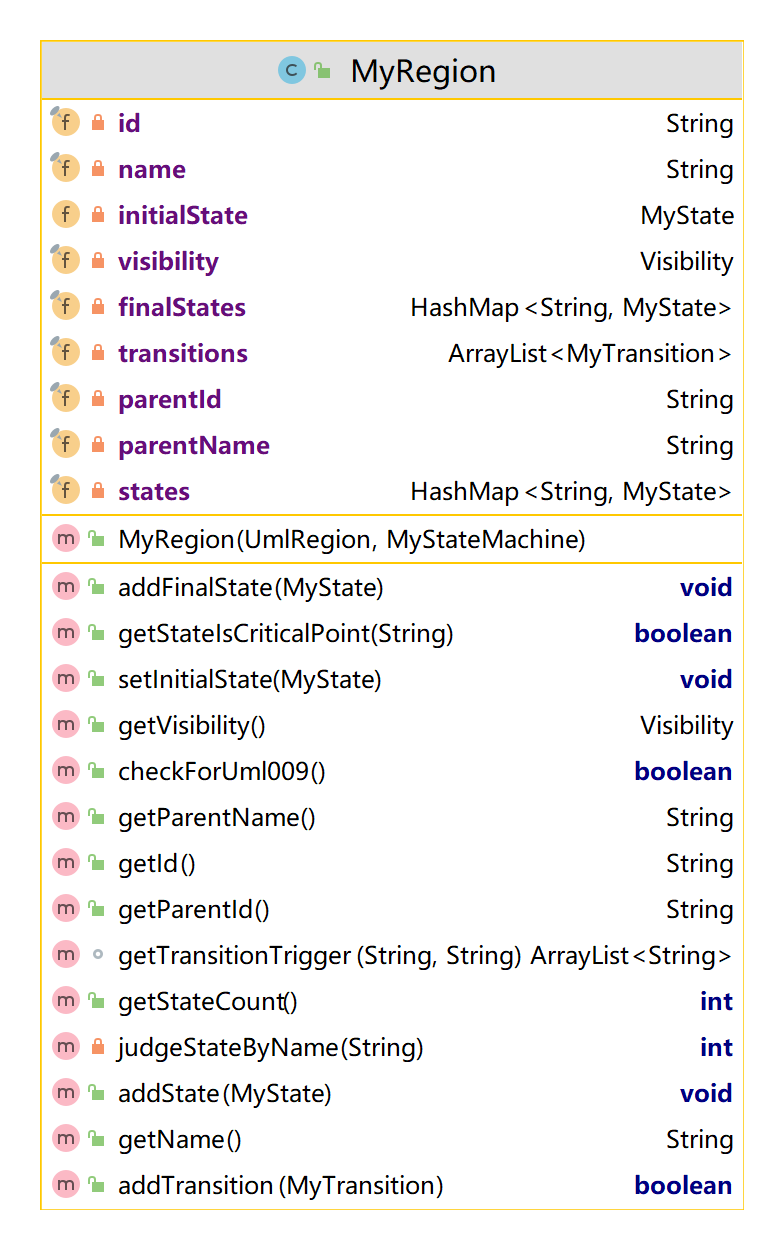
指令 1:给定状态机模型中一共有多少个状态
输入指令格式:STATE_COUNT statemachine_name
举例:STATE_COUNT complex_sm
输出:
Ok,state count of statemachine "statemachine_name" is x.- 其中
x为状态机模型statemachine_name(UMLStateMachine)中的状态个数;
- 其中
Failed, statemachine "statemachine_name" not found.- 不存在名为
statemachine_name的状态机模型时,输出上述内容;
- 不存在名为
Failed, duplicated statemachine "statemachine_name".- 存在多个名为
statemachine_name的状态机模型时,输出上述内容。
- 存在多个名为
说明:
- Initial State 和 Final State 均算作状态。
由于有仅有一个Initial State,这里直接return state的size + finalState的size + 1即可,异常处理同前面一样
指令 2:给定状态机模型和其中的一个状态,判断其是否是关键状态
输入指令格式:STATE_IS_CRITICAL_POINT statemachine_name statename
举例:STATE_IS_CRITICAL_POINT complex_sm open
输出:
Ok, state "statename" in statemachine "statemachine_name" is a critical point.- 状态机模型
statemachine_name中的statename状态是关键状态时,输出上述内容;
- 状态机模型
Ok, state "statename" in statemachine "statemachine_name" is not a critical point.- 状态机模型
statemachine_name中的statename状态不是关键状态时,输出上述内容;
- 状态机模型
Failed, statemachine "statemachine_name" not found.- 不存在名为
statemachine_name的状态机模型时,输出上述内容;
- 不存在名为
Failed, duplicated statemachine "statemachine_name".- 存在多个名为
statemachine_name的状态机模型时,输出上述内容;
- 存在多个名为
Failed, state "statename" in statemachine "statemachine_name" not found.- 状态机模型
statemachine_name中不存在名为statename的状态时,输出上述内容;
- 状态机模型
Failed, duplicated state "statename" in statemachine "statemachine_name".- 状态机模型
statemachine_name中存在多个名为statename的状态时,输出上述内容。
- 状态机模型
这里就是求割点了,我的做法是通过MyState类,在添加State转移的时候在State的nextState里面添加一个state作为后续bfs的遍历范围,然后删除前后做一个bfs,求遍历到的state的集合,进行两次集合的比对
这里就拿一下MyRegion里的方法吧
private final String parentName;
private MyState initialState;
private final HashMap<String, MyState> states = new HashMap<>();
private final HashMap<String, MyState> finalStates = new HashMap<>();
public boolean getStateIsCriticalPoint(String stateName)
throws StateNotFoundException, StateDuplicatedException {
if (judgeStateByName(stateName) == 0) {
throw new StateNotFoundException(this.parentName, stateName);
} else if (judgeStateByName(stateName) > 1) {
throw new StateDuplicatedException(this.parentName, stateName);
}
if (finalStates.size() == 0) {
return false;
}
HashSet<String> originalArrive = new HashSet<>();
originalArrive.addAll(states.keySet());
originalArrive.addAll(finalStates.keySet());
Queue<MyState> bfsQueue = new LinkedList<>();
bfsQueue.add(initialState);
while (!bfsQueue.isEmpty()) {
MyState peek = bfsQueue.poll();
HashMap<String, MyState> nextStates = peek.getNextStates();
for (String id : nextStates.keySet()) {
if (originalArrive.contains(id)) {
bfsQueue.add(nextStates.get(id));
originalArrive.remove(id);
}
}
}
boolean flag = false;
for (String finalStateId : finalStates.keySet()) {
if (!originalArrive.contains(finalStateId)) {
Debug.print(finalStateId);
flag = true;
break;
}
}
if (!flag) {
return false;
}
HashSet<String> deleteArrive = new HashSet<>();
deleteArrive.addAll(states.keySet());
deleteArrive.addAll(finalStates.keySet());
bfsQueue.add(initialState);
while (!bfsQueue.isEmpty()) {
MyState peek = bfsQueue.poll();
HashMap<String, MyState> nextStates = peek.getNextStates();
for (String id : nextStates.keySet()) {
if (deleteArrive.contains(id)) {
if (nextStates.get(id).getType() == 1 ||
!nextStates.get(id).getName().equals(stateName)) {
bfsQueue.add(nextStates.get(id));
deleteArrive.remove(id);
}
}
}
}
Debug.print(deleteArrive.toString());
for (String finalStateId : finalStates.keySet()) {
if (!deleteArrive.contains(finalStateId)) {
return false;
}
}
return true;
}
但是割点还是有更优的dfs方法的,只是我的架构下不是非常易于操作(操作起来感觉不像面向对象了),因此就暴力bfs了
指令 3:给定状态机模型和其中两个状态,引起状态迁移的所有触发事件
输入指令格式:TRANSITION_TRIGGER statemachine_name statename1 statename2
举例:TRANSITION_TRIGGER door_sm open close
输出:
Ok,triggers of transition from state "statename1" to state "statename2" in statemachine "statemachine_name" are (A, B, C).- 此例中,引起状态机模型
statemachine_name从statename1迁移到statename2的事件共有 3 个,分别为A、B、C; - 传出列表时可以乱序,官方接口会自动进行排序(但是需要编写者自行保证不重不漏);
- 此例中,引起状态机模型
Failed, statemachine "statemachine_name" not found.- 不存在名为
statemachine_name的状态机模型时,输出上述内容;
- 不存在名为
Failed, duplicated statemachine "statemachine_name".- 存在多个名为
statemachine_name的状态机模型时,输出上述内容;
- 存在多个名为
Failed, state "statename1" in statemachine "statemachine_name" not found.- 状态机模型
statemachine_name中不存在名为statename1的状态时,输出上述内容;
- 状态机模型
Failed, duplicated state "statename1" in statemachine "statemachine_name".- 状态机模型
statemachine_name中存在多个名为statename1的状态时,输出上述内容;
- 状态机模型
Failed, transition from state "statename1" to state "statename2" in statemachine "statemachine_name" not found.- 状态机模型
statemachine_name中未找到任何从状态statename1到状态statename2的迁移时,输出上述内容。
- 状态机模型
说明:
- 该询问考虑的迁移为状态间的直接迁移;
- 检测状态与迁移异常时,先检测起点状态是否存在异常,再检测终点状态是否存在异常,最后检查是否存在相应的迁移;
- 任意两个状态间有零个或多个迁移;
- 我们保证对于每个非 Initial State 到非 Initial State 的迁移,都至少有一个触发事件;
- 一个迁移上的所有触发事件名称两两不同,且不为空。本规则中的空是指该字段是空指针
null,或仅包含空白字符(空格和制表符\t)。
这里我的实现方式是自建一个MyTransition类,在这个类中添加一个events集合进行记录,在这种方式下这个指令较好实现,就不废话了
第三周
第三周的任务是做模型的有效性检查,这一部分会在实例化完毕后自动按序触发执行,不需要通过指令的形式执行。执行中一旦发现不符合规则的情况,将直接退出,不进行后续有效性检查和指令查询。
或许这一周的任务最能体现第四单元的特色吧,这一单元的内容的细节非常多,需要整天的研究指导书 + 问助教,只要忽略了一点,或许实现起来并不难,但肯定会对应一个bug,这一周的内容更能体现这一点(就是那种不难,但是感觉一直在研究指导书 + 修bug)
对于这一周的测试,额外提的一点就是,建议单独设立异常检测模块,与构造过程分开,保证好异常出现的顺序,不然测试时同时出现多个异常(官方只有一个异常)的时候,可能几个人都是对的,但是报的顺序不一样也对不上拍
这一周整体的架构上没做什么改动(最大的架构改动是因为CodeStyle把上周卡了500行上限的MyImplementation拆出来了一个Parser)
R001: 类图元素名字不能为空(UML 001)
规则解释:
-
目前所有类图的元素中,除了以下元素之外,其余元素的
name字段均不能为空:direction为return的 UMLParameter- UMLAssociation
- UMLAssociationEnd
- UMLGeneralization
- UMLInterfaceRealization
输出:
Failed when check R001, a certain element doesn't have name.- 如未发现此问题,则不需要任何输出,否则输出上述内容。
这一个指令在建好图后实现非常容易,但是容易忽略的点在可能会有无ParentID的类图元素(官方的测试数据中肯定是不会出现的,是我们线下自己测实现这一功能比较方便),还有就是接口中的属性和方法也需要检查,但是其他地方的实现并不需要这些属性和方法,因此加到个人实现的MyInterface的意义不大,我个人建议的实现就是直接在MyImplementation里面建一个容器存储这些类图元素,然后遍历一下除了顺序图的Attribute,逐个判断一下是最直接的
R002:针对下面给定的模型元素容器,不能含有重名的成员(UML 002)
规则解释:
- 针对类图中的类(UMLClass),其成员属性(UMLAttribute)和关联的另一端所连接的 UMLAssociationEnd 这两者构成的整体中,不能有重名的成员。
输出:
Failed when check R002, "member" in "Container", "member2" in "AnotherContainer" has duplicated name.- 如未发现此问题,则不需要任何输出,否则输出上述内容;
- 需要输出所有重名的成员名,以及它们所在的类。此例中,一共有两个存在重名的成员,分别是
Container类中的member,与AnotherContainer类中的member2。
说明:
- 如果一个类中有多个同名的成员,则这些成员名只需要输出一次;
- 如果模型中有多个模型元素违背 R002,则依次输出,次序不敏感,接口会在输出前进行排序;
- 此规则无需考虑继承关系,也不需要考虑接口实现关系;
- 一个类下的属性和关联的另一端所连接的 UMLAssociationEnd 也不可出现重名。注意理解关联的另一端的意思;
- 特殊规定:若有两个 UMLAssociationEnd 的
name字段都为空,则规定这两个成员不是重名。
这里主要是对于这一功能的理解吧,Association在类图中相当于一个变量的引用,这些应当与原有类图中的Attribute的name不重复,从写程序的角度理解好这个问题,实现起这一规则还是挺容易的
R003:不能有循环继承(UML008)
规则解释:
-
该规则只考虑类的继承关系以及接口之间的继承关系。所谓循环继承,就是按照继承关系形成了环。
-
例如下面的场景:
interface A extends B { // something here } interface B extends A { // something here }这里就构成了一组最简单的循环继承。
输出:
-
Failed when check R003, class/interface (A, B, C, D) have circular inheritance.- 如未发现此问题,则不需要任何输出,否则输出上述内容;
- 需要列出所有在循环继承链中的类或接口名。此例中,一共有 4 个存在循环继承的类或接口,分别是 A、B、C、D。
说明:
- 对于同一个类和接口,只需要输出一次即可;
- 如果模型中有多个模型元素违背 R003,则依次输出,次序不敏感,接口会在输出前进行排序;
- 输出的集合中需要包含全部继承环上的类和接口。
这里我选择的是Tarjan算法进行判断,来找size大于1的SCC,由于以前写的比较多,这里基本上是用面向过程的方式写了个Tarjan(x
(注:这里由于自测的原因,class的多继承不易保证,且保证后的测试强度会差很多,因此在我们的数据实现中没有保证官方的多继承上的要求(其实是最开始做作业的时候没看到这周仍满足这一条件,这一规则检查的内容写的挺迷惑的(),当时由于太晚助教老师也没回,就按可以保证写的,不过测试效果倒是不错))
private int cnt1;
private int dfn1;
private int top1;
private int interfaceAmount = 0;
private final int[] low1 = new int[arraySize];
private final int[] num1 = new int[arraySize];
private final int[] sccno1 = new int[arraySize];
private final int[] stack1 = new int[arraySize];
private final ArrayList<ArrayList<Integer>> graph1 = new ArrayList<>();
private void dfs1(int u) {
stack1[top1++] = u;
low1[u] = num1[u] = ++dfn1;
for (int i = 0; i < graph1.get(u).size(); ++i) {
int v = graph1.get(u).get(i);
if (num1[v] == 0) {
dfs1(v);
low1[u] = Math.min(low1[v], low1[u]);
}
else if (sccno1[v] == 0) {
low1[u] = Math.min(low1[u], num1[v]);
}
}
if (low1[u] == num1[u]) {
cnt1++;
while (true) {
int v = stack1[--top1];
sccno1[v] = cnt1;
if (u == v) {
break;
}
}
}
}
private void tarjan() {
// interface
cnt1 = top1 = dfn1 = 0;
for (int i = 1; i <= interfaceAmount; i++) {
if (num1[i] == 0) {
dfs1(i);
}
}
// class
cnt2 = top2 = dfn2 = 0;
for (int i = 1; i <= classAmount; i++) {
if (num2[i] == 0) {
dfs2(i);
}
}
}
Tarjan算法的好处就是可以在一次dfs后便找到所有的scc,对于强连通的判断效率非常高
R004:任何一个类或接口不能重复继承另外一个类或接口(UML007)
规则解释:
-
该规则考虑类之间的继承关系、接口之间的继承关系,包括直接继承或间接继承。
-
例如下面的场景
interface A { // something here } interface B extends A { // something here } interface C extends A, B { // something here }接口 C 就重复继承了接口 A(一次直接继承,一次通过接口 B 间接继承)。
输出:
-
Failed when check R004, class/interface (A, B, C, D) have duplicated generalizations.- 如未发现此问题,则不需要任何输出,否则输出上述内容;
- 需要列出所有带有重复继承的类或者接口名。此例中,一共有 4 个存在重复继承的类或接口,分别是 A、B、C、D。
说明:
- 如果存在多个直接或间接重复继承了其他的类或接口的类或接口,则按照任意顺序传出即可,次序不敏感,接口会在输出前进行排序。
- 值得注意的是,本次作业的本条限制,同样也禁止了接口的重复继承。然而接口重复继承在 Java 8 中实际上是允许的,也就是说,这是 UML 本身的一条合法性规则,无关语言。请各位判断的时候务必注意这件事。
重复继承的判断,其实指导书中的叙述地不是那么地全面,实际上得从官方的数据中去猜,可以说是官方指导书的配套数据说的倒很有意义,且后来同学问后助教的回答也很准(总之指导书上确实不准 tao),实际上说的更准确的表述或者说实现方式,应当是,在类图的关系全部建好的基础上,把某一点作为起始点,只要图中其他任意一点满足,起始点到该点存在多条路径,那么起始点就是一个发生重复继承的点
可以观察到的就是,如果一个点已经是发生重复继承的点了,那么这一点的所有子类的点也是发生重复继承的点(利用这一关系可以更好地剪枝)
这里就列一下我的dfs方法吧
private boolean rule004Flag = false;
private final Set<MyInterface> rule004Set = new HashSet<>();
private final ArrayList<ArrayList<Integer>> graph = new ArrayList<>();
private final boolean[][] hasArrived = new boolean[arraySize][arraySize];
private final boolean[] isMultiTracesPoint = new boolean[arraySize];
private void dfs(int u, int c) {
if (isMultiTracesPoint[u]) {
isMultiTracesPoint[c] = true;
rule004Set.add(interfaces.get(num2Id1.get(c)));
rule004Flag = true;
return;
}
for (int i = 0; i < graph.get(u).size(); ++i) {
int v = graph.get(u).get(i);
if (!hasArrived[c][v]) {
hasArrived[c][v] = true;
dfs(v, c);
} else {
isMultiTracesPoint[c] = true;
rule004Set.add(interfaces.get(num2Id1.get(c)));
rule004Flag = true;
return;
}
}
}
private void multiTraces() {
for (int i = 1; i <= interfaceAmount; i++) {
dfs(i, i);
}
}
重复继承这里其实是可以跟上面的tarjan一块用一个dfs的,我本来也是合在一块写的(不要问为啥后来又分开了,问就是CodeStyle)
R005: 接口的所有属性均需要为 public(UML 011)
规则解释:
- 接口属性的可见性需要为
public。
输出:
Failed when check R005, all attributes and operations of interface must be public.- 如未发现此问题,则不需要任何输出,否则输出上述内容。
说明:
- 在我们的模型中,接口不会有方法,因此只需要检测属性。
这一指令就是名正言顺的好实现 + 没坑,直接检查parentId在接口中,就检查这一属性的可见性即可
R006:Lifeline 必须表示在同一 Sequence Diagram 中定义的 Attribute
规则解释:
- Lifeline 的
represent属性必须指向在同一 Sequence Diagram 下定义的Attribute。
输出:
Failed when check R006, each lifeline must represent an attribute.- 如未发现此问题,则不需要任何输出,否则输出上述内容。
这一操作我已经在第二周的任务中实现了,主要方式就是在MyCollaboration中加一个Represent的容器,然后先放入所有的Represent和Interaction,然后加Lifeline的时候向这一Interaction所在的Collaboration里查即可
R007:一个 Lifeline 在被销毁后不能再收到任何消息
规则解释:
- 一个
Lifeline是一个实例对象,在被销毁(即收到 Delete 消息)后再收到任何消息都是不合理的。
输出:
Failed when check R007, a lifeline receives messages after receiving a delete message.- 如未发现此问题,则不需要任何输出,否则输出上述内容。
说明:
- 在官方包导出的模型中,消息的顺序与输入的顺序相同。越早输入的 UMLMessage 元素,代表了越早的消息。
这里仅需要在原来的addMessage处加入一个对DeleteMessage的特判,并在LifeLine设置状态记录是否Delete即可
R008:所有 Final state 状态不能有任何迁出(UML 033)
规则解释:
- 所有 Final state 不能有任何迁出。
输出:
Failed when check R008, a final vertices has at least one outgoing transition.- 如未发现此问题,则不需要任何输出,否则输出上述内容。
这里既可以去State的连接情况处检查,也可以在加入Transition时检查Source,实现起来也很简单,就不多说了
R009:一个状态不能有两个条件相同的迁出
规则解释:
- 如果存在一个状态的所有的迁出 Transition 的所有触发事件(Trigger)中有两个相同的 Trigger,那么这两个 Trigger 所在的 Transition 必须拥有不为空且逻辑上不能同时成立的守护条件(Guard);
- 如果不满足这条规则,就会存在某种可能性,使得从这个状态开始不知道走哪一个转移。
输出:
Failed when check R009, a state has ambiguous outgoing transition.- 如未发现此问题,则不需要任何输出,否则输出上述内容。
说明:
- 为了简化问题,将“逻辑上不能同时成立的 Guard”解释为“字符串比较不相同”;
- 为了简化问题,将“两个 Trigger 相同”解释为“它们的
name字段字符串相同”。
这一规则检查实现起来不是很困难,但是要理解指导书中的守护条件的判定方式,其实仅有一个Trigger时,Guard可以为空,但是有两个(或多个)时,按照指导书中的说法应该理解成必须两个(全部)都不为空,且均不相同,换句话说,一个为空,一个为非空,这种情况也是不允许的,理解后实现起来还是不难的
测试与总结
这一单元的测试个人做的还算比较充分,虽然前两周还是在ddl前一天才开始写,但是这两周突然发现了肖哥哥跟我基本同步,两个人边写边讨论写的还是挺快的,基本晚7-早3就差不多写完了,到早6完成评测姬,早8初步测试,起来后再问问一文,再进一步测试一下,感觉时间还是挺充裕的,这一单元的强测也都是满分,还是挺开心的
不过也算是真的感受到了评测姬的意义,毕竟数据构造与程序的书写还是两个方向的思路,作为验证是完全没有问题的,这三周基本都是以为没bug,写完评测姬发现还有一堆bug(第一周2个大bug,接口继承和操作耦合度,第二周5个小bug,第三周是指导书理解的问题出现的bug,数据 + 程序一起修),以及在这里再次感谢岳哥哥和一文哥哥的帮助,and 肖哥哥的陪伴,第四单元总的还是非常满意的,而且很轻松hhh
架构设计思维和OO方法理解的演进
现在看来,OO整体这四个单元的进步还是很明显的,从预习单元开始,那时在抽象层的多态、向上向下转型以及接口等还是小心翼翼的,第一单元重写java方法、深克隆时感觉发现了新大陆,还有那会儿的迭代器 + remove的使用,都让我感觉心力憔悴,第二单元的时候,OO的架构已经非常了解了,那会儿最痛苦的就是造轮子的bug实在不好de,最后还是换用了look策略先完成作业,深刻体会到了\(架构≠性能/效率\)的道理,第三单元的时候,OO的架构就已经非常习惯啦,而且也没什么可以设计架构的地方,到了第四单元,类间的耦合度已经有非常完全的层次啦,而且第四单元的内容设计也是非常的体贴,一个单元比一个单元顺利。总的来看,OO架构设计是一个单元比一个单元优秀了,也算是从重构走上了迭代开发的正道吧(x,现在回头看预习时凌乱的代码已经非常滴羞愧了hhh
测试理解与实践的演进
在OO的四个单元的开发下,12次的编程作业,我个人书写了10次的评测机代码,另外两次是借用了一文同学的,以及记不清多少次借用了岳哥和一文gg的数据,也自己在他们的数据上迭代过了好几版(但有两版第三单元的和一版第四单元的,仅迭代了数据过滤),在此先再次感谢ywgg和ygg的无私帮助,个人在这12次的测试中深刻体会到了“测试”的意义,很多次(特别是第四单元)都是在评测姬搭出来后才发现了原设计中的bug,也是这样才是真正体会到了架构涵盖测试设计上的优势吧,特别是测试段也是由自己完成的时候,除了第二单元第一周的迷茫,后面便意识到这一点的重要性,非常确定的bug位置对于修复来说太重要了,测试去耦对于OO的设计来说也太重要了,and 高效的测试对于OO的互测环节也实在太重要了,快乐OO,从测试开始~
如果是理解与实践过程的话,我觉得三四单元的内容对于这一点的体现更加明显,三单元的JML上的理解,以及防范严格按照JML写导致的qgvs超时问题(x,四单元的内容理解 + 任务方向 + 数据范围,到官方数据的理解,感觉都是一个由需求决定设计的过程,如果需求理解出现偏差了,很大可能实践起来设计出来的代码在后来发现理解上出问题后便全部废掉,总之就是下手不能太早,即使ddl已在眼前(x,想清楚再动手
自己的课程收获
OO结束啦~,yysy,自从第二单元造轮子的尝试下,感觉OO项目从小到大全都经历个遍了(,体会最大的主要有以下三个点吧
- 能简单做的东西不要复杂做,能用简单架构解决的问题,不要完全地为了更OO而换复杂的架构
- 模块化应当不仅要考虑功能设计上的模块化,也要考虑测试设计上的模块化,甚至更好的模块化应当考虑到测试出现问题时出现的改进过程的模块化,能让所实现的每一个功能都能在功能设计、测试问题、出现问题时的修复均在其所在类中完成才是最成功的模块化
- 需要优化性能的地方一定要保证性能,没必要优化性能的地方在确定最终方案写完程序不需要进行性能优化
多么痛的领悟(x,除此之外感觉自己还发现了自己的问题就是不像那些综合性能很高的dl们和那些不灭金身的同学们那样始终如一的坚持,自己虽然好像很多次强测都很高,但是还有两次的摆烂估计整体成绩还会非常低,以及甚至有几次都是写完就开始放松,晚上才开始搭评测机,结果自己就轻松测出来自己的一堆bug,毫无疑问互测能Hack很多人,但是自己也寄的很惨(,9次作业进了2次B房1次C房(C房那次是第三单元评测机出问题,没检测出来没有一个异常输出没换行,报那个异常的就都烂了。。强测寄了一半),甚至自己都感觉自己的评测机不像别人那样是为了更好地完成自己的作业而生的,反而像是为了Hack而写的(x,我个人互测交数据还是比较保守的,但最后还是Hack了很多人,好像一共中了87刀,得益于我评测机写得慢导致的强测“优秀”发挥,感觉自己实在是应当从那种纠结要不要写评测机的心理中走出来,不是等作业截止了才纠结完写个评测机,实际上也是12次作业都搞了评测机。。。,或许自己该果断一点儿吧,不能总拖拖拉拉的,and 希望下一个学期就能改了这些毛病吧
OO结束了,真心感谢OO课程组提供这么好的课程,每周的OO感觉充实了整个学期的生活,甚至很多时候没有OO或者放假OO延期都会感到很空虚,有时甚至感觉面向对象对于我们这种面向不了对象的人是一件非常好滴替代奥,OO总让我感到我现在的面向对象水平还不足以让我面向对象,and 希望以后可以继续为面向对象而面向对象~
最后再次感谢ywgg和ygg在本学期对我的无私帮助,嘿嘿(*^▽^*)
给课程的三个改进建议
第一单元对于第二周到第三周的过渡实在太小,应该适当扩充一些实验内容,至少可以添加一些在实现上较易在优化上较难的内容,让同学们有更多的发挥机会,还有重写java内置函数的想法 and 深克隆感觉可以在课程中讲一讲?感觉同学们的讨论和在第一单元中应用的意义非常大,特别同学们刚开始写java程序的时候,感觉挺有必要补充一下的
第二单元对于生产者消费者模型的考察无可厚非,但不应当连续多年如此偏袒LOOK + 自由竞争策略的性能,或者说,个人感觉不应当在如今课程继承状态如此好的当下,出一道仅用LOOK + 自由竞争策略的思想便贯穿整个多线程的最优性能测试的题目,个人尝试了Master-Worker策略,感觉二者在本学年课程多线程题目下的实现复杂度实在过大,而且当讨论区 + 学长往期经验 + 同学对于额外开发和优化的需求,几乎所有人都使用了LOOK + 自由竞争策略完成电梯的作业,相信课程组也非常了解电梯单元如果不加调度算法下的仅LOOK + 自由竞争实现的难度有多么小,个人感觉对于学生们在多线程的认识上不利
第三单元的内容相较之下过于少且易,感觉可以紧缩一下,比如两周完成?或者是丰富一下内容,原本两周的内容感觉一周完成都很轻松,或许三周的内容一周内完成也不是不可能,然后再扩充一下社交网络的其他内容?比如博客作业中提到的售卖等,对社交网络的模拟进一步扩充一下,不然以当前的第三单元JML中的内容量实在难以和其他几个单元的任务量相匹配
标签:输出,name,statemachine,Failed,umlinteraction,北航,classname,面向对象,2022 来源: https://www.cnblogs.com/oh-so-many-sheep/p/16421917.html